
WWW2020 | 一种未来数据辅助训练的会话推荐方法
来源 | 知乎


前言


摘要

1.背景介绍
基于会话的推荐系统(SRS)已经成为推荐领域中一个新兴的主题,它的目标是根据用户会话中交互项的有序历史来预测下一项。虽然深度神经网络的最新进展在建模用户短期兴趣转移方面是有效的,但捕获长期会话中的顺序依赖关系仍然是一个基本挑战。
在实践中,长期的用户会话广泛存在于微视频和新闻推荐等场景中。例如,TikTok上的用户可以在30分钟内观看100个微视频,因为每个视频的平均播放时间只有15秒。
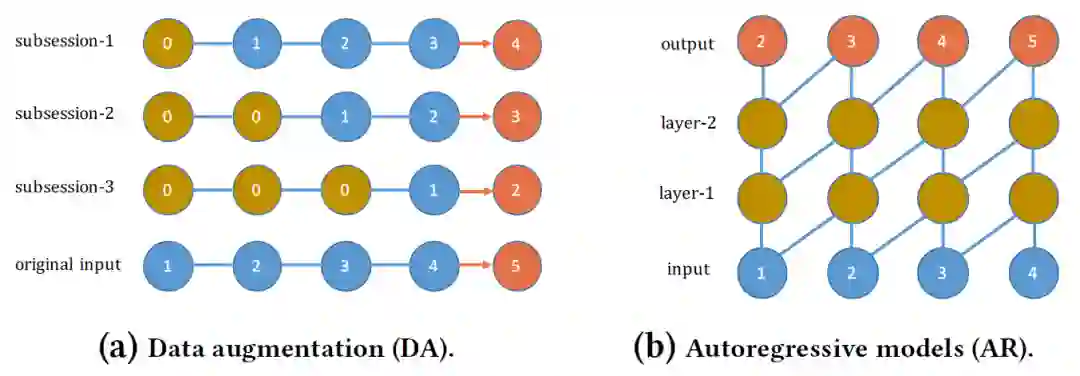
一般来说,从序列数据中训练推荐模型有两种常用的策略:数据扩充和自回归训练。
具体来说,数据扩充方法,如改进后的GRU4Rec,利用目标序列的前缀进行数据预处理,生成新的训练子会话,然后由推荐者预测序列中的最后一项。自回归方法以端到端方式对整个序列的分布建模,而不是只对最后一项建模。这个想法导致了一个典型的从左到右风格的单向生成模型,称为NextItNet 。这两种策略具有相似的直觉,即在构建目标交互的预测函数时,只考虑其过去的用户行为(本文也称之为“上下文”)。
在标准的顺序数据预测中,根据过去的数据预测目标item是一种简单而合理的选择。然而,在顺序性推荐中,我们认为这样的选择可能会限制模型的能力。关键原因是,虽然用户行为是以顺序数据的形式出现的,但顺序依赖关系可能并没有严格地保持。例如,用户在购买手机后,可能会在会话中点击手机套、耳机和屏幕保护器,但三者之间不存在顺序依赖关系,换句话说,用户很可能会按任意顺序点击这三者。
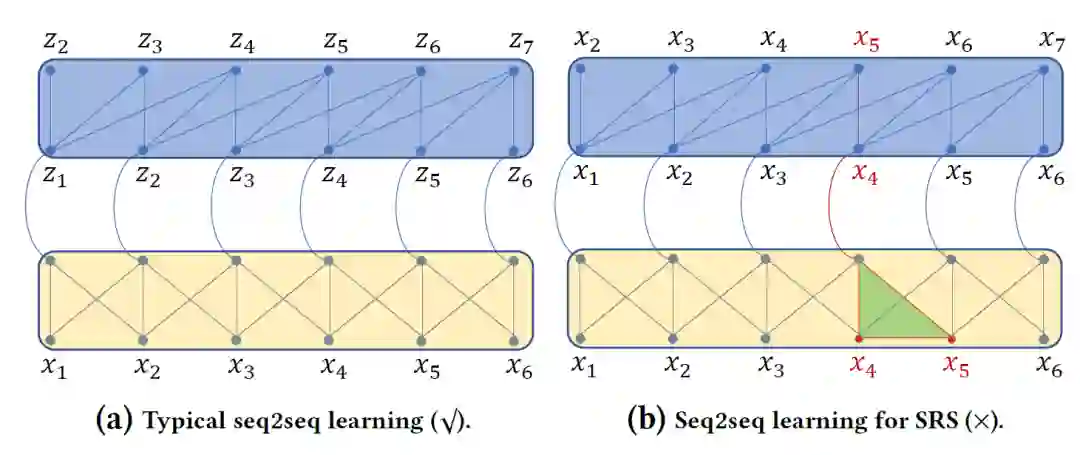
因此,并不一定要将用户会话建模为严格的序列。其次,推荐的目的是准确地估计用户的偏好,使用更多的数据有利于偏好的估计。由于目标交互后的未来数据也证明了用户的偏好,因此有理由相信对未来数据进行建模可以帮助建立更好的目标交互预测模型。然而,未来的数据建模是一个挑战,因为它违背了机器学习的原则,如果处理不当会导致数据泄漏。以编码器-解码器(ED)神经结构为例,在序列数据建模中得到了广泛的应用。如图1(a)所示,在机器翻译中,当按顺序预测一个目标词时(也就是 句子),编码器将两边的单词作为输入源。由于源词和目标词来自不同的领域,因此不存在数据泄漏问题。但是,如果我们将相同的ED体系结构应用于用户会话建模,如下面所示图1 (b),数据泄漏问题不可避免。这是因为源项和目标项来自相同的域,因此目标项(由解码器预测)恰好出现在的输入中。
本文强调了在基于会话的推荐系统中建模未来上下文的必要性,并开发了一个通用的没有数据泄漏的神经网络框架GRec。
本文使用具有稀疏内核的卷积神经网络来指定GRec,统一了序列生成的自回归机制和编码的双边上下文的优点。
本文提出了一种解码器中具有倒置瓶颈架构的投影神经网络,它可以增强编码器和解码器之间的表示带宽。
本文在两个真实的数据集上进行了大量的实验,证明了GRec在利用基于会话的推荐系统的未来上下文方面的有效性。
2.相关论文介绍
1.基于会话推荐的Top-N问题
在SRS中,“session”这个概念被定义为在某一时间或某一时间段内发生的item集合(指任何对象,如视频、歌曲或查询)。例如,在一个小时或一天内浏览的网页列表和观看的视频集合都可以视为一个会话。
形式上,让 






选择头N个(例如,N = 10)item,称为Top-N个基于会话的推荐。
模型算法
在介绍最终的解决方案之前,首先需要研究一些结合未来上下文的传统方法。然后,我们阐明了这些方法在用于生成任务时的潜在缺陷。在分析的基础上,我们提出了基于间隙填充(或填空)的编码器-解码器生成框架,即GRec。下面,我们将使用NextItNet中使用的扩展卷积神经网络实例化所提出的方法,同时考虑准确性和效率。
利用未来数据的一种直接方法是反转原始用户输入序列,并通过同时输入和反转输出来训练推荐模型。这种类型的双向数据扩充方法已经在几个NLP任务中得到了有效的验证。基于数据扩充和增强现实方法的推荐模型无需修改即可直接应用。例如,我们通过使用NextItNet(用NextItNet+表示)来展示这个方法,如下所示:
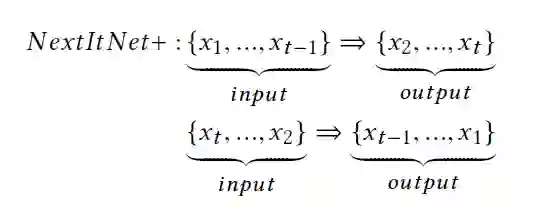
 的左右上下文是由相同的一组参数或相同的NextitNet卷积内核建模的。而在实践中,左右上下文对
的影响可能非常不同。也就是说,从这个角度来看,相同的参数表示并不准确。
的左右上下文是由相同的一组参数或相同的NextitNet卷积内核建模的。而在实践中,左右上下文对
的影响可能非常不同。也就是说,从这个角度来看,相同的参数表示并不准确。
-
单个优化目标同时包含左右上下文 -
左右上下文由不同的模型参数集表示
在这里,我们引入了双向NextItNets,它在向前方向建模过去的上下文,在向后方向建模未来的上下文。与前向NextItNet类似,后向NextItNet以反向的方式运行一个用户会话,根据未来的上下文来预测前一项。我们要做的是保证被预测的item不会被高层神经元访问。
 前向和后向NextItNets都会在每个卷积层为一个用户会话生成一个隐藏矩阵。让
前向和后向NextItNets都会在每个卷积层为一个用户会话生成一个隐藏矩阵。让
 和
和
 为顶层NexitItNet分别从正向和反向计算得到的item隐藏向量
。为了形成双向NextItNets,我们将
和
串联起来,即,
为顶层NexitItNet分别从正向和反向计算得到的item隐藏向量
。为了形成双向NextItNets,我们将
和
串联起来,即,
 。为了在目标函数中结合两个方向,我们最大化了两个方向的联合对数似然。
。为了在目标函数中结合两个方向,我们最大化了两个方向的联合对数似然。
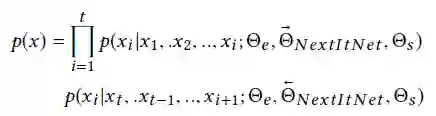
 ,卷积的内核NextItNet
,卷积的内核NextItNet
 , 它包括
, 它包括
 和
和softmax层的权重
和
和softmax层的权重
 。这里的思想与最近的deep context - alized word representation (ELMo)模型具有类似的想法,除了ELMo是通过Bi-RNN编码器来设计单词理解或特征提取任务,而我们使用双向NextItNets来解决生成任务。
。这里的思想与最近的deep context - alized word representation (ELMo)模型具有类似的想法,除了ELMo是通过Bi-RNN编码器来设计单词理解或特征提取任务,而我们使用双向NextItNets来解决生成任务。
虽然tNextItNets可以解决双向数据扩充提到的训练问题,但是在生成阶段,未来的环境实际上是不可接近的。也就是说,后向NextItNet在用于推理时是无用的。训练和预测之间的差异可能会严重影响最终的推荐性能,因为为双向NextItNets学习的最优参数可能在很大程度上对于单向NextItNets是次优的NextItNet。另一个缺点是,双向NextItNets本质上是独立训练的从左到右和从右到左的模型的浅层连接,在建模复杂的上下文表示时,它们的表现力有限。因此,尽管推荐的双向NextItNet利用了更多的上下文,但它是否比NextItNet表现得更好还是未知的。
在本小节中,我们介绍GRec的一般框架和神经结构。
首先,我们介绍SRS的seq2seq学习的基本概念。定义 





 来描述条件概率
来描述条件概率
 ,
,
 通常采用对数似然作为目标函数,在链式法则分解之后,概率可以进一步表示为自回归方式:
通常采用对数似然作为目标函数,在链式法则分解之后,概率可以进一步表示为自回归方式:
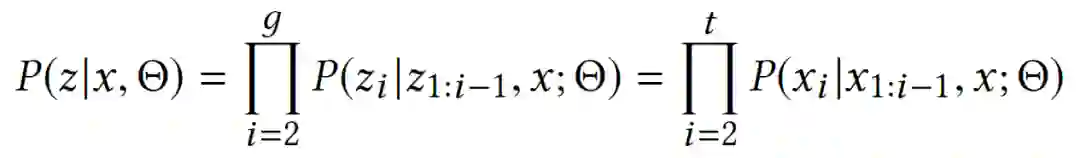 ,可以通过
,可以通过
 从编码器网络中间接看到。
从编码器网络中间接看到。
形式上,给定一个用户会话序列 


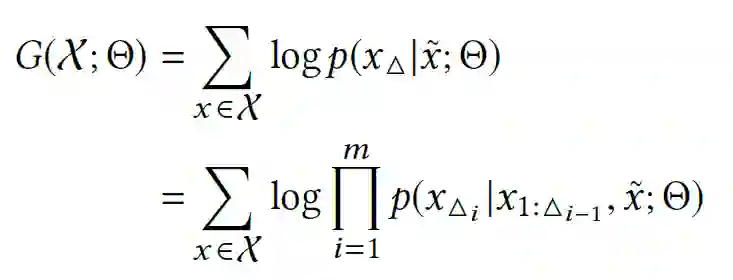





 )在编码器部分被屏蔽。如图3所示,GRec需要一个输入序列
)在编码器部分被屏蔽。如图3所示,GRec需要一个输入序列
 ,出数和产生
,出数和产生
 作为输出序列。
作为输出序列。
 为例,预测,GRec可以利用部分序列的因果关系
为例,预测,GRec可以利用部分序列的因果关系
 ,同时通过编码器利用item
,同时通过编码器利用item
 的表征,其中,
的表征,其中,
 是
的上下文。为清晰起见,我们将NextItNet (seq2seq)和GRec (pseq2pseq)在模型生成方面的比较如下:
是
的上下文。为清晰起见,我们将NextItNet (seq2seq)和GRec (pseq2pseq)在模型生成方面的比较如下:

 和解码器嵌入矩阵
和解码器嵌入矩阵
 ,其中,
,其中,
 是item的数量,
是item的数量,
 是嵌入维度。具体地说,GRec的编码器嵌入了通过查找来自
是嵌入维度。具体地说,GRec的编码器嵌入了通过查找来自
 中的被mask的用户输入序列
,由
中的被mask的用户输入序列
,由
 表示,而解码器嵌入了来自
表示,而解码器嵌入了来自
 原始输入序列
,被
原始输入序列
,被
 。
。

 表示
表示
 用户序列,
用户序列,
 表示空白符号的嵌入向量,也就是在编码器嵌入“___”。
表示空白符号的嵌入向量,也就是在编码器嵌入“___”。
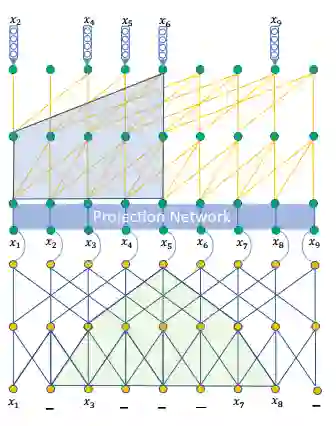
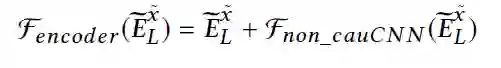
其中, 


 ,投影模块和因果卷积模块组成。CNN组件严格遵循NextItNet,只是允许它估计编码器中屏蔽item的概率,而不是NextItNet中的整个序列。同时,在执行因果CNN操作之前,我们需要将编码器的最终输出矩阵和解码器的嵌入矩阵进行汇总,然后将其传递到投影模块网络中。在形式上,解码器的最后一个隐含层(在softmax层之前)可以表示为:
,投影模块和因果卷积模块组成。CNN组件严格遵循NextItNet,只是允许它估计编码器中屏蔽item的概率,而不是NextItNet中的整个序列。同时,在执行因果CNN操作之前,我们需要将编码器的最终输出矩阵和解码器的嵌入矩阵进行汇总,然后将其传递到投影模块网络中。在形式上,解码器的最后一个隐含层(在softmax层之前)可以表示为:
其中,
 (本文中
(本文中
 )卷积运算将原始的
维通道投影到更大的维度上。然后利用非线性将
)卷积运算将原始的
维通道投影到更大的维度上。然后利用非线性将
 通道投影到原
维上,并进行
通道投影到原
维上,并进行
 卷积运算。投影器的输出是这样的:
卷积运算。投影器的输出是这样的:
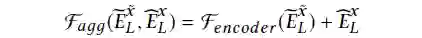
 表示代表上映射和下映射射操作。
表示代表上映射和下映射射操作。
 检索掩蔽位置的隐藏向量来执行查找表。然后,我们将这些向量输入到一个全连通的神经网络层中,该神经网络层将这些向量从三维潜在空间投射到三维软极大空间中。计算得到的掩蔽项
的概率为
检索掩蔽位置的隐藏向量来执行查找表。然后,我们将这些向量输入到一个全连通的神经网络层中,该神经网络层将这些向量从三维潜在空间投射到三维软极大空间中。计算得到的掩蔽项
的概率为
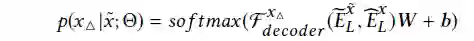
推荐阅读

登录查看更多
相关内容

Arxiv
4+阅读 · 2018年6月11日



相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2018年6月11日