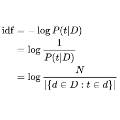强烈推荐十大NLP主流经典项目:预训练BERT、知识图谱、智能问答、机器翻译、文本自动生成等
我们罗列了一些常见的大厂NLP项目深度考察问题:
BERT模型太大了,而且效果发现不那么好比如next sentence prediction, 怎么办?
文本生成评估指标,BLUE的缺点
loss设计 triplet loss和交叉熵loss各自的优缺点,怎么选择
attention机制
ernie模型
-
介绍一下flat及对于嵌套式语料的融合方式 为什么使用lightGBM,比起xgboost的优点是什么
样本不均衡问题的解决办法有哪些?具体项目中怎么做的?
长文本的处理
引入词向量的相似性对于结果有什么不好的影响
如何引入知识图谱
词向量中很稀疏和出现未登录词,如何处理
kmeans的k怎么选择
新词发现怎么做
模型选取、数据增强
从数据标注的制定标准,到选取模型,再到改进模型、错误分析
NER数据中没有实体标注的句子过多解决方式
同一句话两个一样字符串如何消岐
模型好坏的评估,如何衡量模型的性能
方面级情感分析的模型结构
模型学习中,正负样本的训练方式不同有什么影响
减轻特征工程的手段
你如果是一位面试候选人,上述问题你会“倒”在哪一关?
“实践出真知”,只有动手实践具体的项目,以解决问题为导向,在项目中理解技术本身,才能得到更深层次的理解。
你也许会在网络中找到很多资源和论文、但我们面临的问题并不是缺资源,而是找准资源并高效学习。很多时候你会发现,花费大量的时间在零零散散的内容上,但最后发现效率极低,浪费了很多宝贵的时间。
为了给初学者创造项目实践的需求,我们向你推荐业界口碑俱佳的“NLP工程师培养计划”的《自然语言处理项目集训营》第22期。

实践项目介绍

本课程以实⽤为原则,通过10个产业级应用项目,知识覆盖了预训练、词法分析、信息抽取等基础知识,情感分析、知识图谱与智能问答、机器翻译、对话、文本自动生成等NLP应⽤技术和系统,掌握产业实践中的模型部署等。
本课程将带你全面掌握自然语言处理技术,以期更好地帮助各位同学学以致用。通过完成一系列项目课题任务,也有可能成为一个创业项目或者帮助你完成一次重要的技术转型。


项目学习目标:

项目学习重点:
l 数据清洗、分词、数据降噪
l 机器学习:TF-IDF/CounterVector
l 深度学习:Word2vec、Word Embedding、ELMo
l 机器学习:朴素贝叶斯/SVM
l 深度学习:TextCNN/TextRNN

项目学习目标:
项目学习重点:
l Jieba中文分词处理
l 词频统计Wordcloud构建词云
l TF-IDF/TextRank关键词提取
l LDA主题模型建模
l 中文分类机器学习模型
BOW/N-gram/TF-IDF/Word2vec文本表示
Word Embedding/ELMo文本表示
NB/LR/SVM等机器学习分类模型
l Spark:使用pyspark解决分类问题
l TextRNN、TextCNN、FastText
l TextBiRNN、TextRCNN、TextAttBiLSTM
l 深度学习文本分类HAN实战
l Tensorflow深度学习文本分类模型部署
可求职岗位:

《自然语言处理项目集训营》第22期

☑ 智能客服 ☑ 知识图谱 ☑ 文本生成
☑ 文本分类 ☑ 情感分析 ☑ 金融法律
10大项目,助你成长为优秀的NLP工程师


项目学习目标:
学习NLP在用户情感分析应用中的解决方案,具体掌握:文本读取与清洗、关键词抽取(TF-IDF、TextRank)、中文分词、文本表示(Word2vec、Word Embedding、ELMo)、机器学习建模(LR、SVM、朴素贝叶斯、Fast Text)、深度学习建模(TextCNN、TextRNN、Aattention Model)
情感分析常应用于电商数据分析、市场分析、选举预测、消费分析以及可视化分析等领域
项目学习重点:
l 自定义ELMo网络结构完成分类
l Bert模型训练
l Tensorflow serveringinxing部署
l TextCNN、Tide&textCNN以及Textdensenet模型融合
l Fast Text、TextCNN、TextRCNN、TextRNN模型融合
l 采用机器学习stacking方式:
构造TF-IDF Stacking及统计特征
训练Doc2Vec模型
构造Doc2Vec-DBOW stacking特征、Doc2Vec-DM stacking特征
训练Word2vec模型、构造Word2vec特征
使用XGBoost结合特征进行交叉验证
可求职岗位:

项目学习目标:
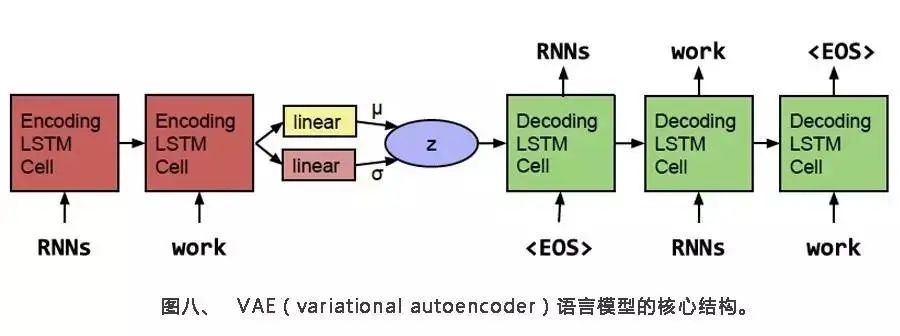
以不同场景的文本生成(诗词小说文本生成、对联生成、摘要生成等)为例,学习文本读取与清洗、语言模型、seq2seq模型、注意力机制、自注意力机制与Transformer在文本生成中的作用。
项目学习重点:
Part1:诗歌生成
l 使用Tensorflow框架,自定义LSTM网络结构
l 谷歌开源、自定义seq2seq模型
l 双向RNN, Attention注意力机制的解码器
可求职岗位:

项目学习目标:
项目学习重点:
l 查看并清洗掉无关数据
l 理解数据与任务之间的联系
l 选择合适的机器学习算法进行建模
l 定义baseline模型、深度学习模型训练
l 添加人工特征进行最终优化
l 复盘整个项目
可求职岗位:

项目学习目标:
项目学习重点:
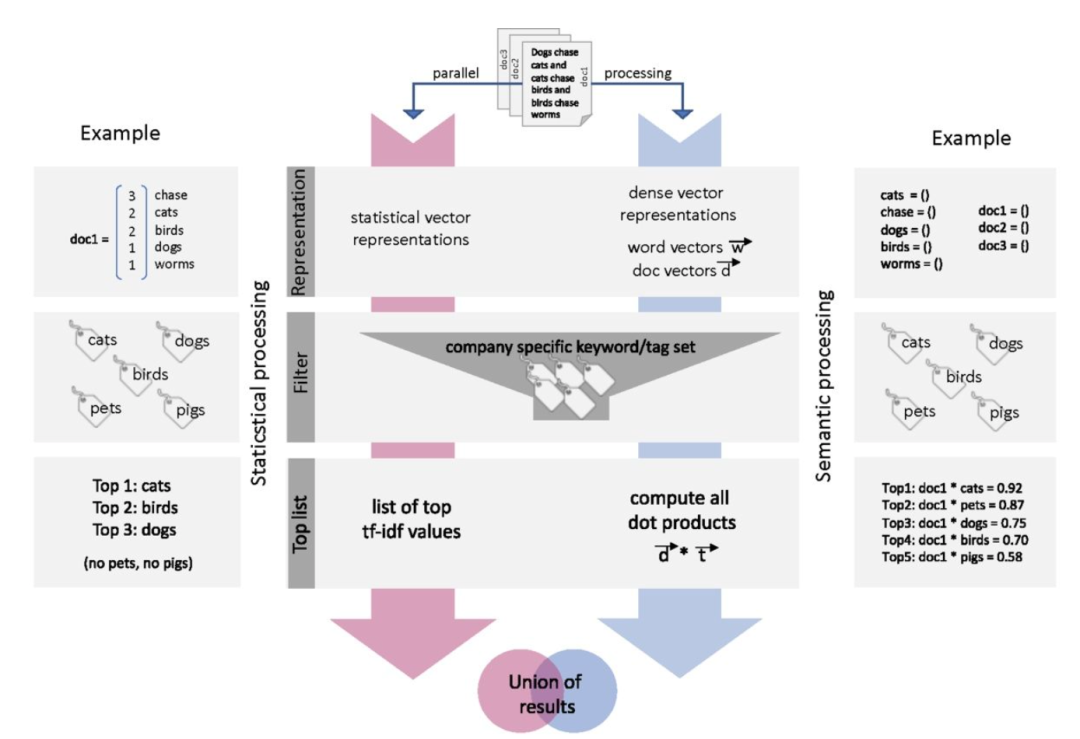
Part1:智能问答系统构建
l Jieba分词
l Mysql数据库存储
l TF-IDF检索模型
l 使用Doc2Vec模型进行问题匹配
l 深度语义匹配模型:DSSM、CDSSM、MV-DSSM
l 单语义文档表达的深度学习模型ARC-I
l 多语义文档表达的深度学习模型MV-LSTM
l 交互的文本相似度模型k-nrm
可求职岗位:
《自然语言处理项目集训营》第22期
☑ 智能客服 ☑ 知识图谱 ☑ 文本生成
☑ 文本分类 ☑ 情感分析 ☑ 金融法律
10大项目,助你成长为优秀的NLP工程师

项目学习目标:
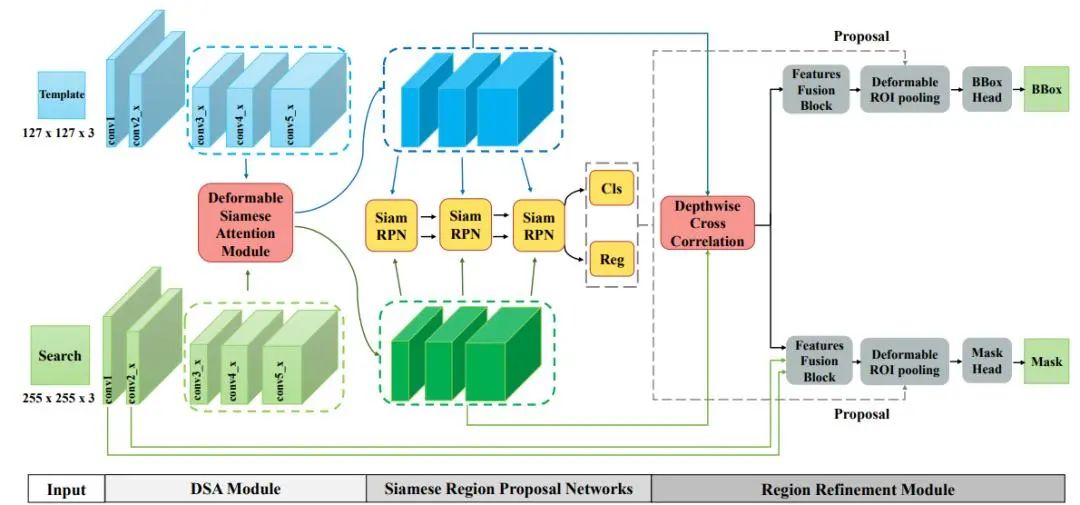
深度学习领域中端到端方式构建并改进的一系列NLP新模型应用,如Transformer、Bert、ELECTRA等模型结合各大比赛案例进行讲解如何应用这些模型解决典型的分类任务、句对建模任务、知识抽取任务等。具体落地应用场景一般有海量文本去重、推荐系统等。
项目学习重点:
Part1:经典深度学习NLP建模
l 句子相似度判定Siamese Network
l 从神经语言模型到预训练语言模型发展史
l 基于Transformer的文本分类
l Bert及其变种在情感分析中的应用
l 新型模型ELECTRA及知识抽取案例讲解
可求职岗位:
深度学习算法工程师、NLP算法工程师

项目学习目标:
以NLP中最重要的语义匹配建模为学习任务,结合通用场景、金融领域场景、医疗领域场景,讲解深度学习的各种模型在文本语义匹配建模任务中的解决方案。并结合场景数据讲解在金融与医疗的垂直NLP应用领域(如智能客服)中对应的模型应用方法。
项目学习重点:
l 文本匹配问题
l 问答、对话与信息检索NLP核心技术
l 文本语义匹配场景:金融问答、闲聊、客服、问诊等
l fancy-nlp、bert4keras工具库
l 语义相似度建模场景数据格式介绍
l 孪生网络结构分析与网络搭建
l 孪生网络相似度建模解决方案
预处理、数据预处理与分析、数据增强
Word2vec、Word-embedding构建
语义抽取子网络搭建
孪生双塔结构搭建、不同损失函数构建
模型训练与优化、语义相似度度量与预估
l BERT句对建模网络搭建与解决方案
l 平安医疗、支付宝/微信的金融语义匹配建模
预处理、数据预处理与分析、数据增强
NLP特征与业务文本特征
SiameseCNN、SiameseRNN模型搭建
Albert、SiameseBert句对建模方案与应用
可求职岗位:

项目学习目标:
项目学习重点:
l 基于规则、特征模板、神经网络的NER方法
l 基于字的BiLSTM-CRF模型
l TextCNN
l PCNN抽取
结合Multi-Instance Learning
结合Sentence-Level Attention
l TextCNN+Position Enbedding
l 深度学习端到端的NER及关系抽取
l BiLSTM+CRF,Tree-LSTM
l 基于N-gram的匹配
l Mysql进行标注,neo4j进行全量查询,
l Odps做持久化数据版本管理
面向岗位:

项目学习目标:
本项目学习知识图谱构建与应用全过程,包括数据采集、知识存储、知识抽取、知识计算、知识应用,还基于知识图谱构建了交互问答系统。整个过程使用到了多种NLP技术,从文本数据抽取与清洗、命名实体识别到用户意图识别,到实体关系抽取的系列模型,到问答与匹配技术,以及neo4j工具的使用和图挖掘的一些算法。
项目学习重点:
l 项目背景与项目内容
l 数据采集与信息抽取
l 实体提取、实体关系抽取
l neo4j工具与图数据库进行图计算
l 基于RDF三元组数据库Apache Jena进行知识存储
l Cypher语法与查询语句知识
l 数值、类别、时序特征构建与特征选择
l 图挖掘与图谱知识挖掘
l Pyhanlp进行分词与实体识别
l Feedforward-network意图识别
l TextCNN/TextRNN/TextRCNN意图识别
l 使用字典形式进行槽填充(slot filling)
l 网络分析与路径查询
l 图计算与社区发现
l 知识图谱交互与可视化
l 实体与关系查询功能页面实现
l 基于图谱的问答系统实现
面向岗位:
《自然语言处理项目集训营》第22期
☑ 智能客服 ☑ 知识图谱 ☑ 文本生成
☑ 文本分类 ☑ 情感分析 ☑ 金融法律
10大项目,助你成长为优秀的NLP工程师
业界独创的服务模式

-
尊享8对1的VIP服务 每一位学员都会配置独享服务群,配置8位专属服务老师全程陪伴 包括: -
2位工业专家讲师、1位全职助教、1位工业助教、 -
2位就业指导老师、1位督学班主任、1位课程顾问
全天答疑,保证有问必答,作业1对1批改,考试1对1批改
免费提供GPU&CPU云平台(GPU有额度免费时长)
作业和练习
课程每个重要的知识点后都配置了对应的作业和练习,作业会得到助教的1V1批改反馈
-
阶段考试
每个学习阶段安排了考试,通过考核才能进入下一个阶段,对阶段性学习效果达成自检
-
课程直播和录播相结合,学员可以灵活安排学习计划和进度
学员收获的offer
自本课程开设以来,已经有一大批毕业学员入职NLP领域的互联网公司、金融行业、科研院所、创业公司,甚至越来越的的传统行业也开始注重AI技术的应用如何在本行业中创造新的价值。下面是一部分学员的offer情况:



……左右滑动,观看更多……
《自然语言处理项目集训营》第22期
☑ 智能客服 ☑ 知识图谱 ☑ 文本生成
☑ 文本分类 ☑ 情感分析 ☑ 金融法律
10大项目,助你成长为优秀的NLP工程师
适合什么样的人?
机器学习或深度学习领域自学一段时间,停留在使用模型/工具上,有一定的算法理论基础,但非常缺乏NLP项目经验;
有一定的编程经验,想通过技术转型进入NLP算法领域求职的,缺乏系统性学习;
非CS专业出身的本科或硕士生,希望获得算法岗实习或校招岗位的,缺乏计算机编程经验和算法理论知识学习
科学的课程进度
为满足不同基础的学员可以循序渐进的系统化学习,本课程可以根据学员自身的知识储备条件,选择从哪个阶段开始学习。完整的课程安排可以满足没有编程经验和算法基础的学员通过5-6个月的高强度学习入门NLP技术。
阶段一
Week1 |Python编程基础

Week2-3 |Python数据分析

Week4 | 人工智能的数统概基础

阶段二
Week5-6 | 大数据技术

Week7-9|机器学习与深度学习的算法基础与应用

阶段三
Week10-12|自然语言处理的算法基础

阶段四
Week13|项目1——语种识别器
Week13|项目2—新闻文本挖掘和分类(ML/DL)
Week14|项目3—ELMo、BERT情感分析与法律NLP应用
Week15|项目4—文本自动生成
Week16|项目5—搜索引擎用户画像项目
阶段五
Week17|项目6—智能客服与聊天机器人
Week18|项目7—最新深度学习NLP模型案例应用
Week19|项目8—金融与医疗场景的语义匹配建模应用项目
Week20|项目9—知识图谱的实体与关系抽取
Week21|项目10—知识图谱构建与知识挖掘及问答系统
阶段六
就业推荐与面试辅导
报名须知
本课程为收费教学。
本期招收学员名额有限。
品质保障!学习不满意,可在开课后7天内,无条件全额退款
《自然语言处理项目集训营》第22期
☑ 智能客服 ☑ 知识图谱 ☑ 文本生成
☑ 文本分类 ☑ 情感分析 ☑ 金融法律
10大项目,助你成长为优秀的NLP工程师