10 分钟,带你了解 3 篇 SIGMOD、WWW 等数据库顶会论文的研究成果 | Q推荐
俗话说得好,内行看门道,外行看热闹。那么,如何才能快速达成从“看热闹”到“看门道”这一身份的转换?
答:读论文,尤其是读顶尖论文!一篇顶尖论文,要么代表在全球范围内对其研究领域的实验性、理论性或预测性有新的科研成果或创新见解,要么就是某种已知原理在应用上取得了新突破。
但是,想要读懂一篇论文却是一件十分艰难的事,不仅有语言上的障碍,还会产生应用实践上的困惑。好不容易读完全文,却依然不知所云。
呕心沥血完成的论文不应明珠蒙尘,同时为了帮助我国广大数据库领域开发者了解当下最前沿的技术,6 月 21 日,腾讯云数据库举办 DBTalk 论文在线解读会,针对 3 篇近期被 SIGMOD、WWW 等数据库顶会收录的论文展开深度解读。除此之外,腾讯云数据库还举办了一场圆桌会议,邀请业内专家对数据库的现状、未来挑战、经验、产学研协同等议题进行深度探讨。
“数据库是一个综合系统,其背后是发展了几十年的数据库理论。作为一名开发者来说,无论是为了克服工作上源源不断的挑战,还是为了跟上时代最前沿的技术,想要持续进步,就需要掌握数据库的基本原理和底层逻辑,对新技术永远抱有好奇心,学以致用并将在实践中收获的经验进行反哺。只有这样,才能不被时代甩下车。”腾讯云副总裁、腾讯云数据库负责人林晓斌说。
在数据压缩的情况下直接对数据进行计算,这个想法的提出最初来源于对节省时间、空间双重维度的迫切需求。
面对这种需求,中国人民大学数据工程与知识工程教育部重点实验室提出了压缩数据直接计算技术,并在论文《CompressDB: Enabling Efficient Compressed Data Direct Processing for Various Databases》中,详细讲述了如何将该项技术与数据库做一个很好的融合,达到对多种数据库产品进行支撑的目的。
要想使这项技术支持多种类型的数据库,一种方案就是将该项技术集成到底层的存储系统中,但是,这会产生三个技术壁垒:第一,在存储系统中会面临对数据块的处理,复杂程度大大提升;第二,对于频繁的增删改查等操作,无法确保高效性;第三,如何利用磁盘和内存特性上的差距也是一个挑战。
基于上述挑战,本研究开发了一个新的存储引擎 CompressDB,其采用基于规则的压缩技术并限制其规则生成深度,支持直接对压缩数据进行数据查询和数据操作。与之前相比,这项系统从元素、规则和 DAG 三个维度都进行了探索:在元素级别,实现了一种新的数据结构——数据洞;在规则级别,为随机更新启用了有效的规则定位和规则拆分方案,可以实现快速确定数据的位置以及进行拆分;在 DAG 级别,通过降低规则的层次以提高更新效率。
CompressDB 系统包含三个模块,分别是数据结构模块、压缩模块以及运算模块。
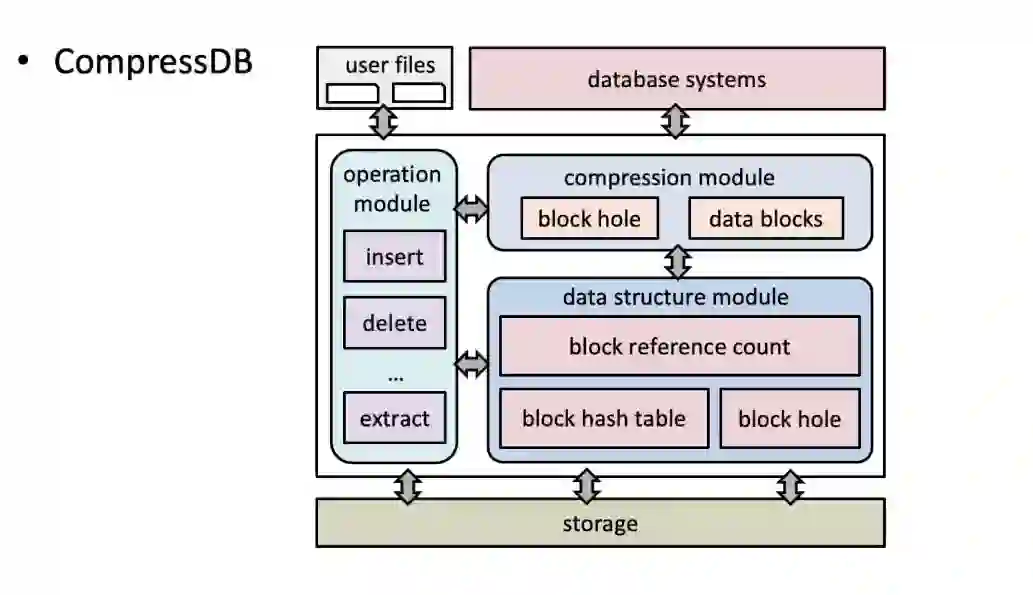
其中,数据结构模块包含三种数据结构:blockHashTable 表示数据内容到块位置的映射关系,帮助系统快速定位到具体的数据块;blockRefCount 记录块被引用次数;blockHole 是更新操作引起的存储空洞,当数据块周围有 blockHole 时可进行合并。至于压缩模块,它支持文件系统中的分层压缩,能够做到在压缩数据上插入一条数据,可以快速将其合并到压缩文件里;最后是运算模块,可以将操作下推到文件系统,对于一些系统没有的 API ,可通过该模块进行开发、实现。
通过测试不同数据模型的数据库,实验结果表明:CompressDB 系统在吞吐率和延迟上都能有 40% 左右的性能提升,在节省空间方面,CompressDB 系统可达到 1.81 倍的压缩率。
“在数据库领域,数据库管理系统是美国对中国禁运 35 项“卡脖子”技术之一,如果我们想要弯道超车,可以在被誉为数据库管理系统皇冠上的明珠——数据库运维上,占据一些技术竞争战略上的制高点。”华中科技大学副研究员刘渝说。
作为数据库运维主要工作之一的数据库调参,在以往,需要由经验特别丰富的数据库管理员来完成。但随着数字设备的发展,数据库实际的增长速度已经远远超过了对数据库管理员的培养速度,这意味着很多数据管理处于一种失控的状态。因此,求助人工智能,采用智能运维的方式是数据库调参领域必然的发展趋势。
在这篇被 SIGMOD 录取的论文《HUNTER: An Online Cloud Database Hybrid Tuning System for Personalized Requirements》中,其针对核心问题“如何在保证调优效果的前提下显著减少调优时间,尤其是在线训练时间”提出了混合调优系统 Hunter。
Hunter 包括控制器、样本工厂、空间优化器以及推荐器这四个模块。
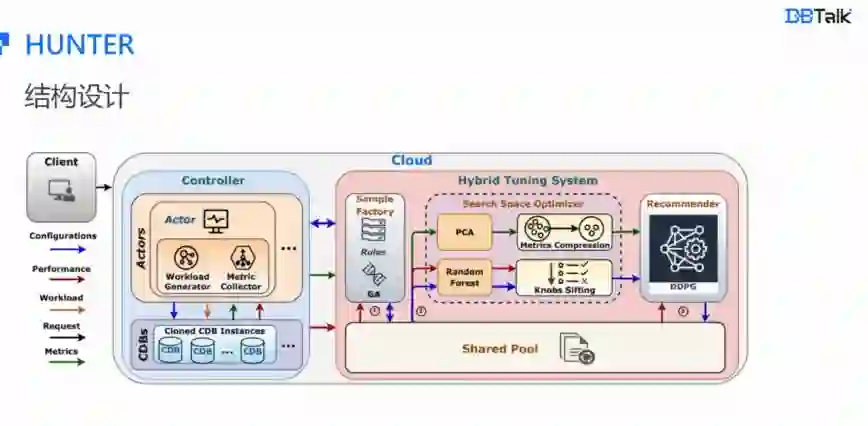
首先,在控制器这一模块,其主要的工作是克隆 CDB 实例,目的在于真实地反应负载和性能之间的变化关系;其次,Hunter 的样本工厂通过 Rules 模块满足用户的调参需求从而定制专属的训练样本,并利用遗传算法 GA,短时间内就能收集到相对优秀的训练样本;第三,通过在空间优化器中进行指标压缩和旋钮筛选,减少输入,也就是训练数据的维度;最后,采用逐步放宽只压测最优配置的方式,拓展最优解的寻找范围,尽可能寻找全局最优解。
经实际的对比效果,可以看出 Hunter 在获得更优吞吐量和延迟的基础上,在所需时间上取得了近乎碾压的效果,其在 20 个克隆实例的并发场景下,调优时间仅需 2 小时。
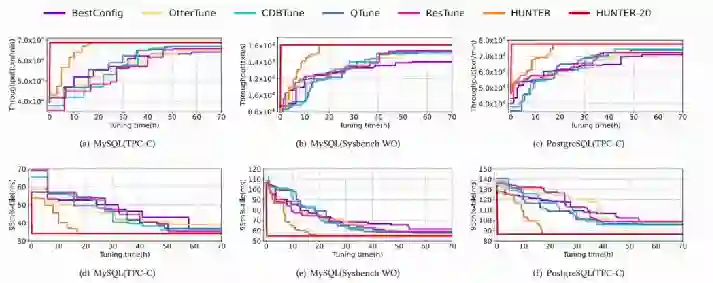
作为一个真正可以落地的数据库调参系统,Hunter 不仅可以适应用户的个性化需求,还可以进行在线训练,并有着极高的效率与可信赖的结果。可以说它的出现,对我国自治数据库的发展,将产生极大的推力。
目前,很多数据都是以图结构数据的形式存在,而图神经网络(GNN)是一种利用深度学习直接对图结构数据进行学习的框架,它被广泛用于多个场景,如推荐系统、异常检测、数据库诊断、蛋白质结构预测等等。
然而,现有的图神经网络系统存在着两个技术瓶颈:一方面,传统的图神经网络模型遵循 NMP 消息传递机制,可扩展性较低。这是因为学术届在设计这种执行网络结构时,更加关注这种模型的性能,以及在分布式场景下的计算或者通信;但当这种机制面临工业级大规模的图数据的时候,分布式的方式就会导致数据存储于不同的机器上。当其通信时,频繁的聚合操作会产生非常高昂的通讯开销。
另一方面,现有的图神经网络系统需要用户针对特定图数据和图任务编写代码和训练流程,这就需要经验丰富的专家来设计网络结构,门槛相对来说较高。
那么,如何在兼顾 GNN 可扩展性的同时,设计出使用门槛低的图神经网络系统,是该领域当下需要迫切解决的问题。
在论文《PaSca: a Graph Neural Architecture Search System under the Scalable Paradigm》中,腾讯 TEG 机器学习平台部 Angel Graph 团队应用研究员、北京大学计算机系张文涛博士提出了一个端到端的大规模图神经结构搜索系统,它不需要人为定义网络结构和训练流程,当接收到数据和优化目标之后,系统能够自动完成数据的处理、建模、以及训练流程,极大地降低了图神经网络的使用门槛。

其次,该论文又提出了一个新的图神经网络建模范式——SGAP 建模范式。区别于现有的消息传递机制,SGAP 把建模的过程拆分成三个阶段:前处理—训练—后处理,其中,消息聚合操作只存在于前处理和后处理中,大幅度降低了分布式场景下的通信开销。

在系统设计上,本文还提出了一个名为 PaSca 自动化搜索系统,来支持更简单和更高效的大规模图学习。其包含了两个模块,分别是自动化的搜索引擎以及分布式的评估引擎,前者的主要目标是找到在 SGAP 建模范式下能同时兼容多个搜索目标的可扩展图神经网络结构;后者则主要是用来高效评估被推荐的网络结构性能。
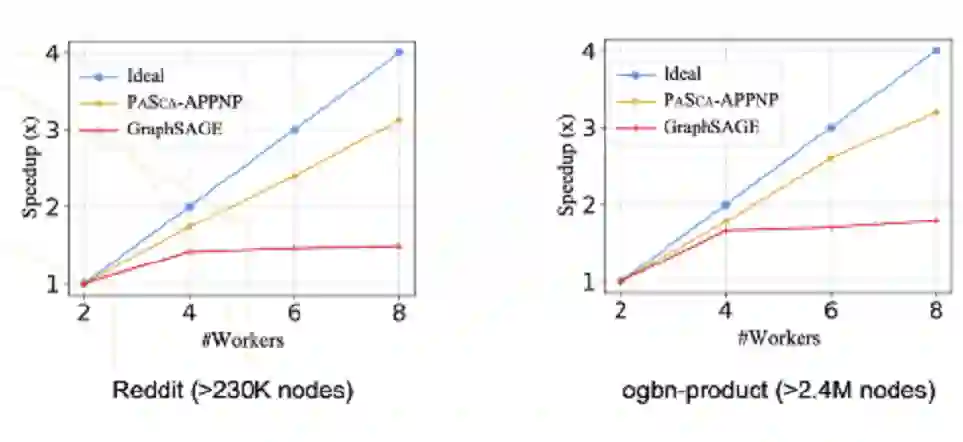
最后在多个数据集上的实验结果表明,在分布式场景下的可扩展性上,基于 SGAP 范式建模的 PaSca-APPNP 模型相比于基于 NMP 范式建模的 GraphSAGE 模型,能取得接近线性并且更加接近理想的加速比。
通过上文的图神经网络系统可以看出,工业界、学术界若互相割裂,必然会导致技术发展的落后。在对以上 3 篇论文进行详细的深度解读后,几位老师又聚在一起,共同探讨数据库领域未来的发展,其中就包括产学研协同问题。
对此,刘渝老师认为:从企业的角度看,更在乎的是当下能够为用户带来哪些利益;而从学术的角度来看,他们关注的可能是更长远的问题,两者之间是有一些矛盾的。所以要想把产学研协同这件事情做好,需要双方相互理解,求同存异,共同进步。
而张文涛老师则以自身举例,他说,“一方面,我在做学术研究的时候,可以近距离接触公司内部真实的数据以及业务的需求,会发现很多之前在实验室想象不到的新的问题。另一方面,我们将最新的技术研究带到公司,帮助腾讯实际业务场景落地,不管是提升影响力,还是解决一些实际的业务问题,都给公司创造了效益。这是一个合作双赢的良性循环的过程。“
最后,张峰老师补充道,“数据库技术发展要想做到产学研结合,一个很好的方式是联合实验室,比如中国人民大学和腾讯公司,在 2019 年就签订了中国人民大学—腾讯联合协同创新实验室。人民大学在国产数据库基础研究方面有着丰富的积累经验,而腾讯数据库团队在应用实践上有丰富的经验。在产学研的过程中,企业、高校是一个互相支撑的总体,在人才培养中,人民大学和腾讯公司联手合作,采用校企联合培养的机制培养数据库的顶尖研发人员。”
写在最后
本次 DBTalk 的圆满结束,除了让更多开发者跨越语言障碍,学习顶尖数据库技术外,还让人看到了我国学者的实力。
曾几何时,中国学者的论文在 SIGMOD 等顶会所占的比例不足 1%,而现在,随着我国技术逐渐走出国门,我国学者也逐渐在各种国际数据库顶会上大放异彩,比如今年,也是腾讯云数据库的科研成果入选 SIGMOD、VLDB、ICDE 等数据库国际顶会的第六年。相信经过不断的技术创新和理论证明,中国数据库界会在 SIGMOD 等会议上发表更多的好文章。

