让机器认知中文实体 — 复旦大学知识工场发布中文实体识别与链接服务
一、什么是实体识别与链接
近年来,如何通过知识图谱让机器实现自然语言理解受到越来越多的关注。其中,识别文本中的实体,并将它们链接到知识库中,是让机器理解自然语言的第一步,也是至关重要的一步。比如,当智能问答系统在回答“李娜在哪一年拿到澳网冠军?”这一问题时,第一步就是识别并在知识库中找到网球运动员李娜这一实体,才能继续从知识库中找到相关信息并作出回答。如果识别出错或者没有将“李娜”正确链接到网球运动员李娜这一实体的话,系统对于这个问题的回答必然出错。根据我们的调研,目前面向通用领域的中文实体识别与链接服务,能够公开可用且取得满意效果的还不多见。
实体识别与链接的问题定义如下:给定一个知识库K,其包含一个实体集合E以及相应已知的实体同义词集合M;对于一段输入文本t,识别t中的所有指代实体的字段m∈M,并将它们链接到正确的知识库中的实体e∈E。
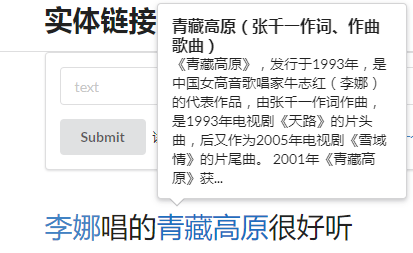
图1 实体链接示例
图1是一个例子,给定知识库CN-DBpedia,对于输入文本“李娜唱的青藏高原很好听”,可以识别出文本中指代实体的字段“李娜”和“青藏高原”,然后分别把他们链接到CN-DBpedia中的实体“李娜(流行歌手、佛门女弟子)”和“青藏高原(张千一作词、作曲歌曲)”。
相对于其他的实体识别与链接,这个任务有如下特点:首先,知识库K为通用知识库,即其实体集合E很大(数量为千万级),并且包含来自各个领域的实体。其次,输入文本t通常为短文本,大多数只包含一个实体。
二、实体识别与链接的技术挑战
1、实体识别和链接的基本挑战
实体识别需要识别文本中指代的实体的片段。通常有两种解决方案,第一种是利用知识库的同义词库识别所有可能为实体的字段,然后进行筛选判断;第二种是对文本做语法分析,通过词本身及其语法特征识别实体。对于第一种方案,需要均衡考虑候选片段为实体的可能性和片段之间相互覆盖与选择的问题,比如“吴彦祖国籍是什么”,应该正确地识别“吴彦祖”和“国籍”,而不是识别“祖国”;对于第二种方案,若要达到很好的效,合适的特征提取以及足够的训练样本是必不可少的。
实体识别出来的实体名通常是有歧义的,也就是说一个实体名通常会指代知识库中的多个实体,比如之前提到的“李娜”。如何将实体名链接到知识库中的正确实体是实体链接需要解决的问题。解决这个问题的关键在于如何有效地利用实体本身的属性以及实体名出现时上下文的信息。
以上为通用实体识别与实体链接共同的挑战。这个任务具有的一些特点,还导致了一些额外的挑战。

图2 在通用领域的知识库CN-DBpedia里,实体的歧义性很大
2、通用领域的实体识别与链接的挑战
以通用领域的知识库CN-DBpedia为知识库进行的实体链接会带来额外的挑战。通用领域的实体识别与链接具有两个主要特点:第一个特点是实体量巨大。这不仅对候选实体增加了大量噪音,而且也需要对实体进行相关领域判断,这样一来,实体识别与链接就需要更多的考虑,如图2所示,在CN-DBpedia里,“北京”除了中国首都之外,还能指代一首歌、一张专辑、一首诗、一部小说和一个小行星的名字。第二个特点是实体界限模糊。通用知识库几乎包含了所有词,包括一些平凡的实体,比如“图片”、“钢笔”,还有一些成语俗语,比如“危言耸听”、“厚德载物”等等。但这些实体在实际应用中通常是不希望被识别和链接出来的,这对实体词的判断带来了很大的难度。
3、短文本的实体识别与链接的挑战
短文本输入进行的实体链接也会带来额外的挑战。在大多数情况下,输入文本只是输入一个句子,有时候甚至是一个词组。与针对长文本或者文档的实体识别与链接方法不同的是,短文本输入的上下文信息非常缺乏,并且几乎没有共现实体的信息。比如“冰与火之歌有多少卷”,在上下文无其他实体的语境中要识别并将“冰与火之歌”链接到小说而不是电视剧。但是现实生活中,大部分的文本信息都是以短文本的方式存在,这就需要着重发掘词语与实体的关系,从而从极少的文本中提取到语义信息。
4、中文实体识别与链接的挑战
现有的大量实体识别与链接工作是基于英文的,把基于英文的方法应用到中文中是有很大难度的。首先,在特征提取方面,中文实体在字面上缺少很多英文实体具有的明显特征,比如大写、缩写等。其次,处理中文文本需要处理分词问题。不同的分词结果影响着句子的语义表达结果,而且现在的分词技术也存在着许多缺陷,分词的错误会对实体名边界的确认造成影响。此外,中文实体识别还缺少训练数据。现在命名实体识别的主流方法是机器学习,在机器学习中,训练数据是至关重要的。因此缺少训练数据对中文实体识别造成了很大的困难。最后,中文知识图谱并不如英文知识图谱那么完善,缺少很多实体关系,多了不少噪音,这就导致很多利用实体关系解决问题的方法难以达到效果。
三、主要应用场景
1、信息抽取
信息抽取系统提取的实体和关系通常是不明确的,将它们与知识库链接起来是消除歧义和精化输入的好方法,这对于它们的进一步发展至关重要。
信息抽取的一个重要任务就是关系抽取。知识图谱中除了实体之外,还有许多关系和属性。CN-DBpedia中的关系如图3所示,这样的关系通常是不完整的,需要从大量的自由文本中抽取。比如,若需要从文本“乔治.马丁写了冰与火之歌”中抽取关系,第一步则是将“乔治.马丁”和“冰与火之歌”从文本中识别并分别链接到正确的人和书名之中,然后才能根据其余文本抽取出<乔治•雷蒙德•理查德•马丁,作者,冰与火之歌(乔治•r•r•马丁所著小说)>这样的关系。
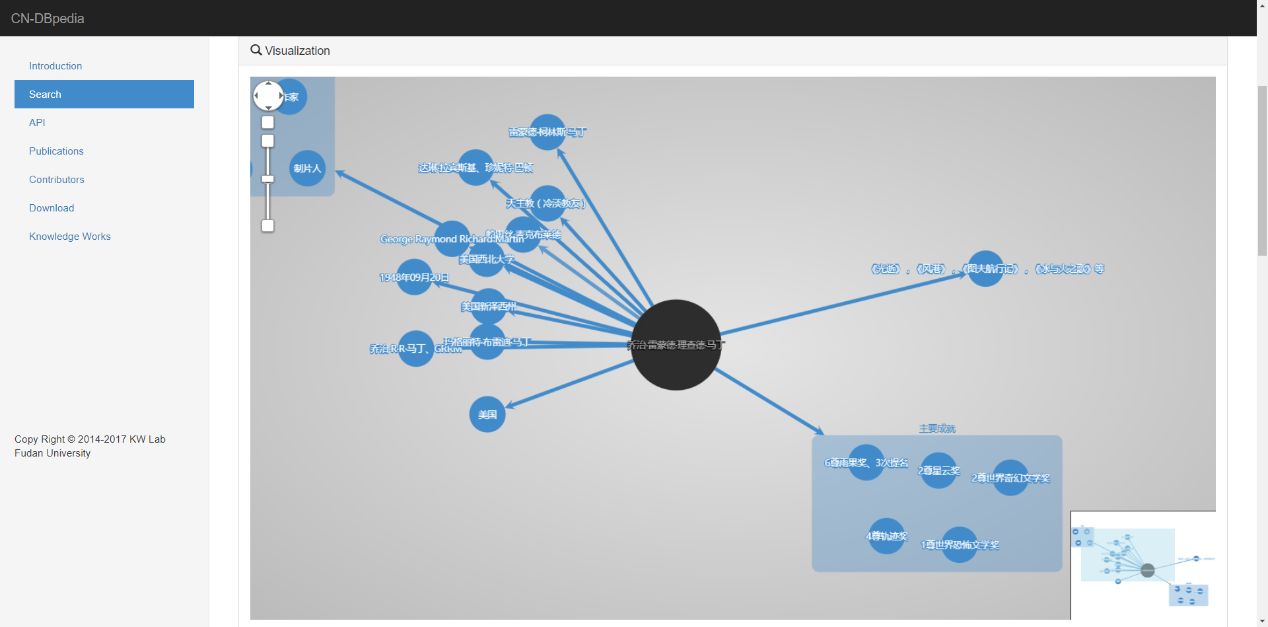
图3 CN-DBpedia中的实体关系与属性
2、信息检索
由传统的基于关键字的搜索推进到基于语义实体的搜索的这一趋势,近年来引起了很多关注。基于语义实体的搜索可以受益于实体链接,因为它本质上需要在网络文本中出现消除歧义的实体名,以便更精确地处理实体和Web文档的语义。 另外,歧义查询也会影响搜索结果质量,有歧义的实体出现在搜索查询中,给信息检索系统理解查询带来了巨大挑战,因此实体识别与链接至关重要。
比如实体名“红楼梦”出现在查询语句中可能有很多不同的意思,有可能指的是名著《红楼梦》,也有可能是某部改编的电视剧或者电影。将这些有歧义的实体名进行识别和链接无疑能提高返回搜索结果的质量。
3、主题分析
主题分析是指从文本内容中分析出主题,主旨及其分类等信息,这也需要利用实体识别与链接。将文章中的实体链接到知识库,可以通过实体的类别和关系等信息更好地进行主题分析。如今,微博已经成为重要的信息来源,可以通过发现特定微博用户感兴趣的主题推荐和搜索其他微博用户。比如在一个用户的微博中识别出了“成龙”,另一个用户的微博识别出了“李连杰”,那么可以通过这两个实体在知识库的关联来对微博用户进行关联和推荐。
4、智能问答
大多数智能问答系统利用其支持的知识库来回答用户的问题。为了回答“青藏高原是谁唱的?”这个问题,系统可以通过实体识别和链接,消除实体名“青藏高原”的实体歧义,然后从知识库中直接找到唱这首歌的歌手来作为用户问题的回答。
5、知识库扩充
随着世界的发展,新的事实在网络上产生并被数字化表达。利用新提取的事实自动填充和丰富已有的知识库,已成为语义Web和知识管理技术的关键问题。 实体链接本质上是知识库扩充的一个重要的子任务。给定一个需要扩充知识库的关系或事实,如果与该关系相关的实体在知识库中有其相应的实体记录,则应该进行实体关联任务,将该实体名与其对应的实体相关联,因此,实体识别与链接能够帮助知识库扩充。
四、实体识别与链接服务
知识工场提供实体识别与链接的服务,包括DEMO和API。
1、DEMO
地址为 http://shuyantech.com/api/entitylinking/
在输入框输入文本,输出经过实体识别与链接后的文本,其中被识别的实体会链接到CN-DBpedia知识库中。如图4所示。
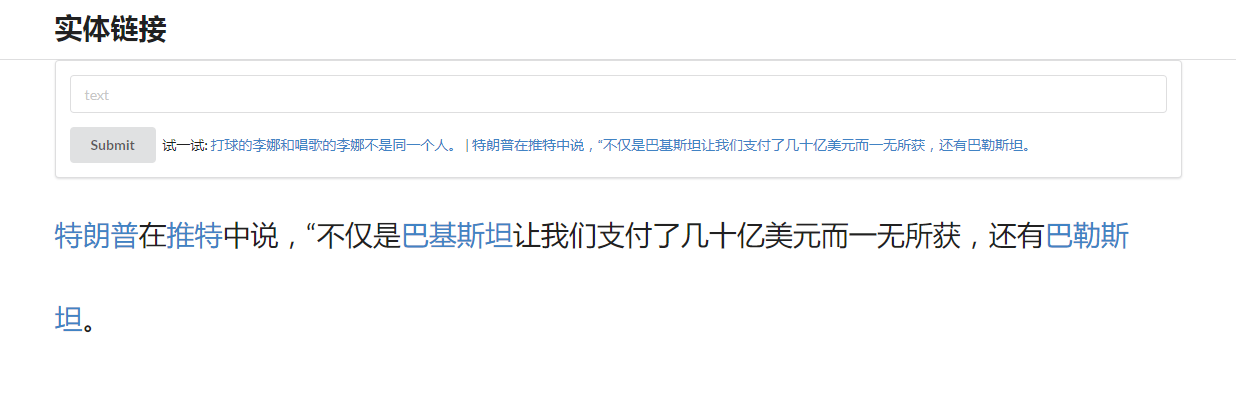
图4 实体链接demo
2、API
地址为 http://shuyantech.com/api/entitylinking/cutsegment
输入参数q,表示输入的文本
输出为包含两个域的json字典。其中键“cut”表示将输入文本的分词结果,值为字符串列表;键“entities”表示输入文本中链接的实体,值为一个列表,列表的每个元素表示一个链接的实体,表示为一个长度为2的列表,列表第一个元素是实体在输入文本中出现的位置,第二个元素为实体在CN-DBpedia中的名字。
使用示例:
输入:
http://shuyantech.com/api/entitylinking/cutsegment?q=打球的李娜和唱歌的李娜不是同一个人
输出:
{"cuts": ["打球", "的", "李娜", "和", "唱歌", "的", "李娜", "不是", "同一个", "人"], "entities": [[[3, 5], "李娜(中国女子网球名将)"], [[9, 11], "李娜(流行歌手、佛门女弟子)"]]}
五、实体识别与链接数据集
知识工场提供实体识别与链接的数据集。
数据集的文本由1037条人工标注的短文本语料组成。其中大约70%来自新闻语料,包括新闻标题和内容,比如“英超-桑切斯4分钟内梅开二度阿森纳3-2五轮不败”,大约20%来自人工构建的基于歧义实体的语料,比如“红楼梦的演员有哪些?”,其余的大约10%来自问答语料中的简单问句,比如“岳阳有哪些旅游景点?”。
数据标注的格式如下。每个样本的标注格式包括3个部分:语料,mention和实体。用制表符‘\t’分隔,其中mention为语料中指代实体的字段,多段用“|||”分隔,实体部分为各mention对应的实体,多个用“|||”分隔,数量应与mention一致。比如“李娜拿过澳网冠军吗\t李娜|||澳网\t李娜(中国女子网球名将)|||澳大利亚网球公开赛”。
目前,我们的实体识别与链接技术在该数据集上达到很好的效果。在没有任何背景主题信息,无论是短语还是长句,均达到90%以上准确率。其中实体识别部分的准确率为91.0%,实体链接部分的准确率为94.5%。更多详细指标见技术报告。
知识工场提供实体识别与链接的数据集。链接如下:
https://github.com/chenlihan240/chinese_entity_linking/blob/master/data/test.txt
- The End -
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





