【布道师系列】杨健——30天到3分钟的改变!
点击蓝字关注DataCanvas

DataCanvas布道师
杨 健
据统计,一个机器学习建模项目从立项到上线通常要花费6-18月的时间,在客户需求瞬息万变的今天,这样漫长的交付周期完全无法跟上企业发展的要求。敏捷开发、快速迭代、持续集成这些提高软件工程效率、缩短开发周期的最佳实践,同样也在影响着机器学习工程领域。工程化的思想、完整的工具链支撑以及自动化建模技术正在大幅缩短机器学习项目的交付周期。
以往需要30天以上的建模工作,今天在DataCanvas APS中3分钟就可以完成一个模型的训练和上线过程。
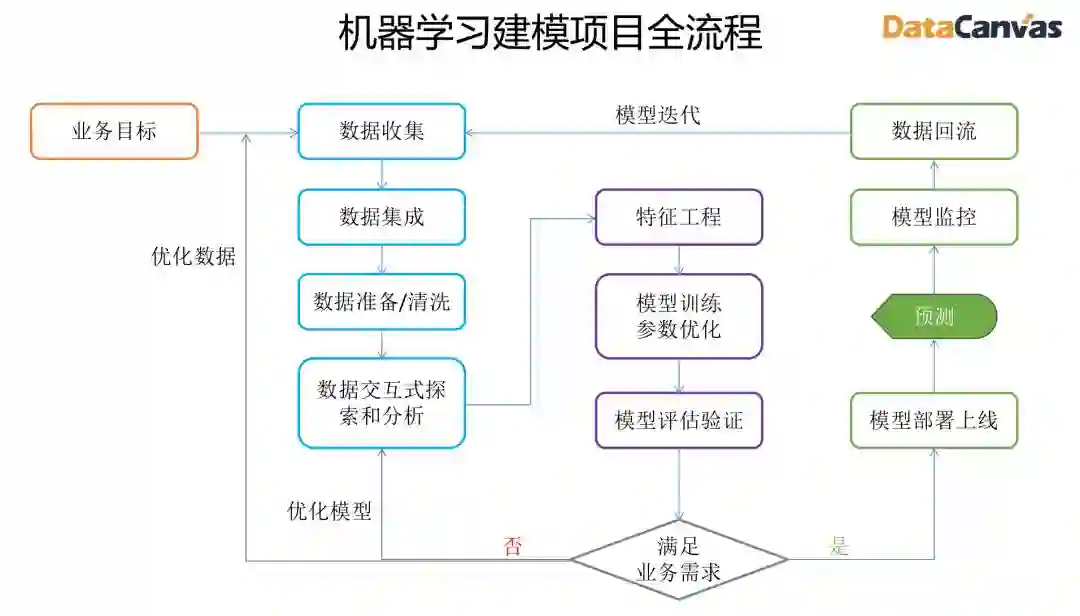
从上图看,机器学习建模流程基本可以分为三个阶段:
数据获取和处理
模型训练和评估
模型部署和迭代
一个完整的机器学习平台必须能够满足以上三个阶段全流程的功能需求,下面我们就从机器学习平台的工具属性方面讨论一下机器学习平台需要具备的几个关键能力以及DataCanvas APS产品的相关特性。
数据获取和处理阶段
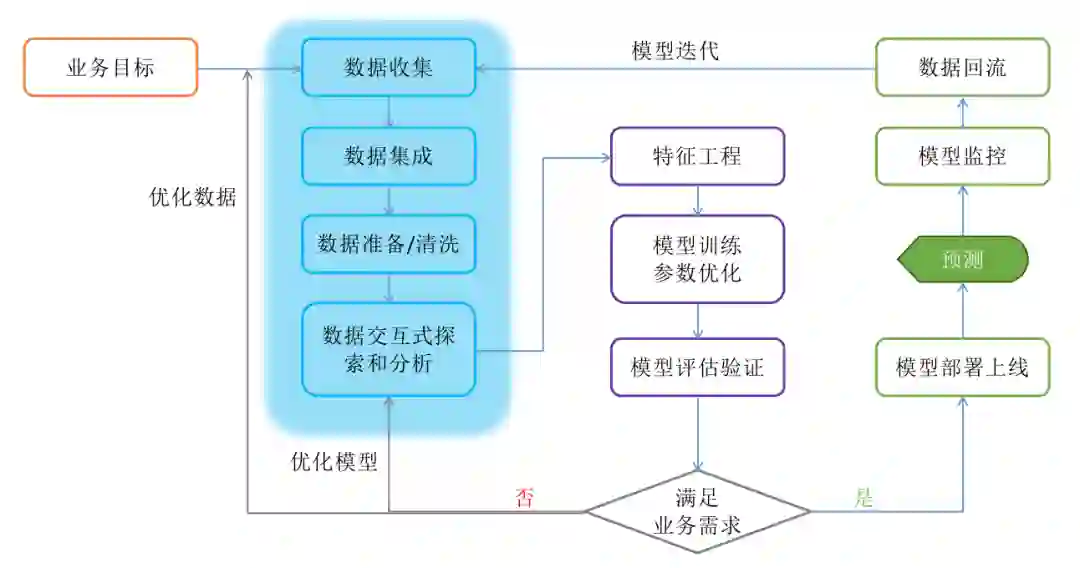
1
数据接入能力
数据访问(Data access)要求平台能够快速访问和接入各种不同来源和不同类型的数据。现实中企业使用的数据库系统五花八门,对各种类型数据源的接入能力是平台的入门门槛,同时也是在项目实施过程中经常遇到的一个挑战。平台在对接数据时难免会遇到在产品上无法直接支持的数据源类型,因此在数据接入层面是否具有足够的开放性是一个考验。
DataCanvas APS可以通过两种手段扩展数据接入方式:
1、OpenAPI,DataCanvas APS提供了专用于数据集管理的完整API,可以实现任意数据来源的导入、更新和管理。
2、分析模块,通过分析模块可以实现任意数据源的连接,再结合RuntimeAPI可以进一步完成对托管数据集的落地和更新操作,或者直接通过非托管方式引入到工作流中完成数据接入。
APS产品已经支持的数据源类型:
2
数据准备能力
数据准备(Data preparation)也就是我们平时所说的加工宽表的过程。很多企业是由数据部门在数据平台上通过开发ETL脚本完成宽表加工,当然数据科学家会首先根据业务目标向数据部门提需求再走工单流程,经过漫长的等待才能看到需要的数据,数据如果不能满足需求还要反复执行这个繁琐的流程,大部分项目前期数据准备阶段耗费大量的时间也是这个原因。当然由数据部门完成ETL的好处是:
但随着项目交付周期的时间要求越来越短,很多用户希望能够在机器学习平台上由项目组内的数据工程师完成宽表的加工,提高整个迭代过程的速度。因此需要机器学习平台具备完成数据准备的能力:
以上需求在DataCanvas APS中是基本特性。DataCanvas APS提供可视化交互式、脚本交互式、拖拽式工作流三种方式完成数据准备工作。同时可视化交互式数据处理最终可以导出成工作流,工作流可以导出到生产环境完成生产化。数据处理工作流底层采用Spark引擎,可以满足大规模数据处理的需求。
3
数据探索和可视化能力
探索性数据分析EDA(Exploratory Data Analysis)是建模的关键环节,也是建模过程中非常考验数据科学家经验和能力的一个部分。我们一起来看一下EDA阶段的主要工作内容:
Kaggle竞赛中可以看到很多非常精彩的EDA过程,有兴趣的可以研究一下 Home Credit Default Risk 案例。下面我们展示几个EDA过程中常用的可视化分析图表:
相关性热力图
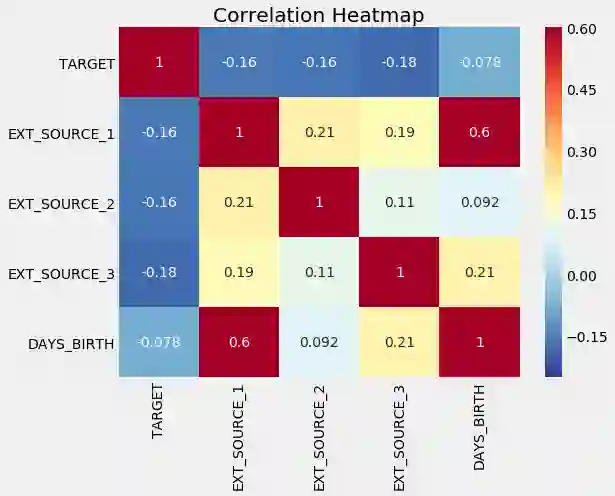
分析特征和目标变量的数据分布之间的关系
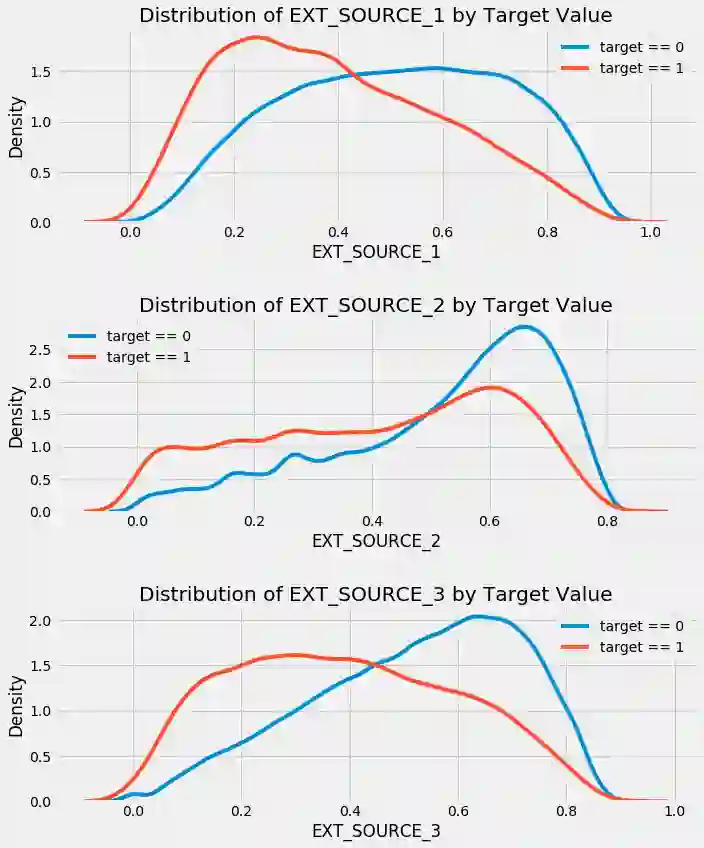
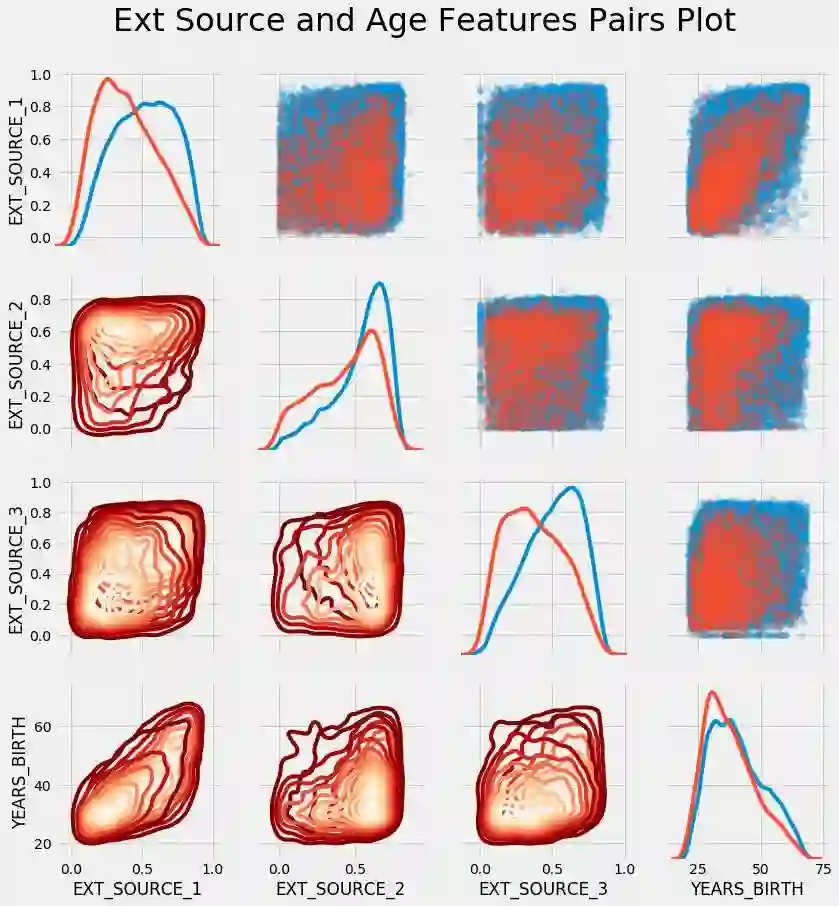
成对变量之间的关系以及单个变量的分布
EDA的工作需要强大的可视化工具才能够高效完成,R语言广受数据科学家欢迎的主要原因就是其可视化方面的超强能力大大节省了数据分析的时间成本。对于数据探索和可视化的能力方面对平台有以下要求:
1、能够自动完成通用、基础的数据探查和可视化分析,节省体力性的重复劳动
2、数据科学领域存在这各种不同的技术栈和工具包,因此平台必须具备很强的开放性。
3、提供交互式的探索工具,目前比较流行的有Jupyter Notebook、Jupyter Lab、Zepplin。同时交互式探索工具能够和平台很好的整合,比如:
DataCanvas APS可以很好的满足以上需求。DataCanvas APS在探索空间中提供了Jupyter Lab,和数据集、分析模块无缝集成,同时RuntimeAPI提供了统一的数据集访问接口。探索空间中可以使用Python、R、PySpark三种语言,可以导入任何需要的工具包。Jupyter和APS的自动化分析工具无缝集成,实现自动化的数据可视化分析。
小结
了解更多DataCanvas
DataCanvas入选中国大数据行业应用TOP Choice 2019
九章云极周晓凌:金融数据科学平台建设的思考

DataCanvas
数据科学赋能企业AI