TensorFlow学习笔记1:入门
TensorFlow 简介
TensorFlow是Google在2015年11月份开源的人工智能系统(Github项目地址),是之前所开发的深度学习基础架构DistBelief的改进版本,该系统可以被用于语音识别、图片识别等多个领域。
官网上对TensorFlow的介绍是,一个使用数据流图(data flow graphs)技术来进行数值计算的开源软件库。数据流图中的节点,代表数值运算;节点节点之间的边,代表多维数据(tensors)之间的某种联系。你可以在多种设备(含有CPU或GPU)上通过简单的API调用来使用该系统的功能。TensorFlow是由Google Brain团队的研发人员负责的项目。
什么是数据流图(Data Flow Graph)
数据流图是描述有向图中的数值计算过程。有向图中的节点通常代表数学运算,但也可以表示数据的输入、输出和读写等操作;有向图中的边表示节点之间的某种联系,它负责传输多维数据(Tensors)。图中这些tensors的flow也就是TensorFlow的命名来源。
节点可以被分配到多个计算设备上,可以异步和并行地执行操作。因为是有向图,所以只有等到之前的入度节点们的计算状态完成后,当前节点才能执行操作。
TensorFlow的特性
1 灵活性
TensorFlow不是一个严格的神经网络工具包,只要你可以使用数据流图来描述你的计算过程,你可以使用TensorFlow做任何事情。你还可以方便地根据需要来构建数据流图,用简单的Python语言来实现高层次的功能。
2 可移植性
TensorFlow可以在任意具备CPU或者GPU的设备上运行,你可以专注于实现你的想法,而不用去考虑硬件环境问题,你甚至可以利用Docker技术来实现相关的云服务。
3 提高开发效率
TensorFlow可以提升你所研究的东西产品化的效率,并且可以方便与同行们共享代码。
4 支持语言选项
目前TensorFlow支持Python和C++语言。(但是你可以自己编写喜爱语言的SWIG接口)
5 充分利用硬件资源,最大化计算性能
基本使用
你需要理解在TensorFlow中,是如何:
将计算流程表示成图;
通过
Sessions来执行图计算;将数据表示为
tensors;使用
Variables来保持状态信息;分别使用
feeds和fetches来填充数据和抓取任意的操作结果;
概览
TensorFlow是一种将计算表示为图的编程系统。图中的节点称为ops(operation的简称)。一个ops使用0个或以上的Tensors,通过执行某些运算,产生0个或以上的Tensors。一个Tensor是一个多维数组,例如,你可以将一批图像表示为一个四维的数组[batch, height, width, channels],数组中的值均为浮点数。
TensorFlow中的图描述了计算过程,图通过Session的运行而执行计算。Session将图的节点们(即ops)放置到计算设备(如CPUs和GPUs)上,然后通过方法执行它们;这些方法执行完成后,将返回tensors。在Python中的tensor的形式是numpy ndarray对象,而在C/C++中则是tensorflow::Tensor.
图计算
TensorFlow程序中图的创建类似于一个 [施工阶段],而在 [执行阶段] 则利用一个session来执行图中的节点。很常见的情况是,在 [施工阶段] 创建一个图来表示和训练神经网络,而在 [执行阶段] 在图中重复执行一系列的训练操作。
创建图
在TensorFlow中,Constant是一种没有输入的ops,但是你可以将它作为其他ops的输入。Python库中的ops构造器将返回构造器的输出。TensorFlow的Python库中有一个默认的图,将ops构造器作为节点,更多可了解Graph Class文档。
见下面的示例代码:
import tensorflow as tf# Create a Constant op that produces a 1x2 matrix. The op is# added as a node to the default graph.## The value returned by the constructor represents the output# of the Constant op.matrix1 = tf.constant([[3., 3.]])# Create another Constant that produces a 2x1 matrix.matrix2 = tf.constant([[2.],[2.]])# Create a Matmul op that takes 'matrix1' and 'matrix2' as inputs.# The returned value, 'product', represents the result of the matrix# multiplication.product = tf.matmul(matrix1, matrix2)默认的图(Default Graph)现在有了三个节点:两个 Constant()ops和一个matmul()op。为了得到这两个矩阵的乘积结果,还需要在一个session中启动图计算。
在Session中执行图计算
见下面的示例代码,更多可了解Session Class:
# Launch the default graph.sess = tf.Session()# To run the matmul op we call the session 'run()' method, passing 'product'# which represents the output of the matmul op. This indicates to the call# that we want to get the output of the matmul op back.## All inputs needed by the op are run automatically by the session. They# typically are run in parallel.## The call 'run(product)' thus causes the execution of threes ops in the# graph: the two constants and matmul.## The output of the op is returned in 'result' as a numpy `ndarray` object.result = sess.run(product) print(result)# ==> [[ 12.]]# Close the Session when we're done.sess.close()Sessions最后需要关闭,以释放相关的资源;你也可以使用with模块,session在with模块中自动会关闭:
with tf.Session() as sess: result = sess.run([product]) print(result)TensorFlow的这些节点最终将在计算设备(CPUs,GPus)上执行运算。如果是使用GPU,默认会在第一块GPU上执行,如果你想在第二块多余的GPU上执行:
with tf.Session() as sess: with tf.device("/gpu:1"): matrix1 = tf.constant([[3., 3.]]) matrix2 = tf.constant([[2.],[2.]]) product = tf.matmul(matrix1, matrix2) ...device中的各个字符串含义如下:
"/cpu:0": 你机器的CPU;"/gpu:0": 你机器的第一个GPU;"/gpu:1": 你机器的第二个GPU;
关于TensorFlow中GPU的使用见这里。
交互环境下的使用
以上的python示例中,使用了Session和Session.run()来执行图计算。然而,在一些Python的交互环境下(如IPython中),你可以使用InteractiveSession类,以及Tensor.eval()、Operation.run()等方法。例如,在交互的Python环境下执行以下代码:
# Enter an interactive TensorFlow Session. import tensorflow as tf sess = tf.InteractiveSession() x = tf.Variable([1.0, 2.0]) a = tf.constant([3.0, 3.0]) # Initialize 'x' using the run() method of its initializer op.x.initializer.run()# Add an op to subtract 'a' from 'x'. Run it and print the resultsub = tf.sub(x, a)print(sub.eval()) # ==> [-2. -1.] # Close the Session when we're done.sess.close()Tensors
TensorFlow中使用tensor数据结构(实际上就是一个多维数据)表示所有的数据,并在图计算中的节点之间传递数据。一个tensor具有固定的类型、级别和大小,更加深入理解这些概念可参考Rank, Shape, and Type。
变量(Variables)
变量在图执行的过程中,保持着自己的状态信息。下面代码中的变量充当了一个简单的计数器角色:
# Create a Variable, that will be initialized to the scalar value 0.state = tf.Variable(0, name="counter")# Create an Op to add one to `state`.one = tf.constant(1) new_value = tf.add(state, one) update = tf.assign(state, new_value)# Variables must be initialized by running an `init` Op after having# launched the graph. We first have to add the `init` Op to the graph.init_op = tf.initialize_all_variables()# Launch the graph and run the ops.with tf.Session() as sess: # Run the 'init' op sess.run(init_op) # Print the initial value of 'state' print(sess.run(state)) # Run the op that updates 'state' and print 'state'. for _ in range(3): sess.run(update) print(sess.run(state))# output:# 0# 1# 2# 3赋值函数assign()和add()函数类似,直到session的run()之后才会执行操作。与之类似的,一般我们会将神经网络模型中的参数表示为一系列的变量,在模型的训练过程中对变量进行更新操作。
抓取(Fetches)
为了抓取ops的输出,需要先执行session的run函数。然后,通过print函数打印状态信息。
input1 = tf.constant(3.0) input2 = tf.constant(2.0) input3 = tf.constant(5.0) intermed = tf.add(input2, input3) mul = tf.mul(input1, intermed)with tf.Session() as sess: result = sess.run([mul, intermed]) print(result)# output:# [array([ 21.], dtype=float32), array([ 7.], dtype=float32)]所有tensors的输出都是一次性 [连贯] 执行的。
填充(Feeds)
TensorFlow也提供这样的机制:先创建特定数据类型的占位符(placeholder),之后再进行数据的填充。例如下面的程序:
input1 = tf.placeholder(tf.float32) input2 = tf.placeholder(tf.float32) output = tf.mul(input1, input2)with tf.Session() as sess: print(sess.run([output], feed_dict={input1:[7.], input2:[2.]}))# output:# [array([ 14.], dtype=float32)]如果不对placeholder()的变量进行数据填充,将会引发错误,更多的例子可参考MNIST fully-connected feed tutorial (source code)。
示例:曲线拟合
下面是一段使用Python写的,曲线拟合计算。官网将此作为刚开始介绍的示例程序。
# 简化调用库名import tensorflow as tf import numpy as np# 模拟生成100对数据对, 对应的函数为y = x * 0.1 + 0.3x_data = np.random.rand(100).astype("float32") y_data = x_data * 0.1 + 0.3# 指定w和b变量的取值范围(注意我们要利用TensorFlow来得到w和b的值)W = tf.Variable(tf.random_uniform([1], -1.0, 1.0)) b = tf.Variable(tf.zeros([1])) y = W * x_data + b# 最小化均方误差loss = tf.reduce_mean(tf.square(y - y_data)) optimizer = tf.train.GradientDescentOptimizer(0.5) train = optimizer.minimize(loss)# 初始化TensorFlow参数init = tf.initialize_all_variables()# 运行数据流图(注意在这一步才开始执行计算过程)sess = tf.Session() sess.run(init)# 观察多次迭代计算时,w和b的拟合值for step in xrange(201): sess.run(train) if step % 20 == 0: print(step, sess.run(W), sess.run(b))# 最好的情况是w和b分别接近甚至等于0.1和0.3MNIST手写体识别任务
下面我们介绍一个神经网络中的经典示例,MNIST手写体识别。这个任务相当于是机器学习中的HelloWorld程序。
MNIST数据集介绍
MNIST是一个简单的图片数据集(数据集下载地址),包含了大量的数字手写体图片。下面是一些示例图片:
MNIST数据集是含标注信息的,以上图片分别代表5, 0, 4和1。
由于MNIST数据集是TensorFlow的示例数据,所以我们不必下载。只需要下面两行代码,即可实现数据集的读取工作:
from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) MNIST数据集一共包含三个部分:训练数据集(55,000份,mnist.train)、测试数据集(10,000份,mnist.test)和验证数据集(5,000份,mnist.validation)。一般来说,训练数据集是用来训练模型,验证数据集可以检验所训练出来的模型的正确性和是否过拟合,测试集是不可见的(相当于一个黑盒),但我们最终的目的是使得所训练出来的模型在测试集上的效果(这里是准确性)达到最佳。
MNIST中的一个数据样本包含两块:手写体图片和对于的label。这里我们用xs和ys分别代表图片和对应的label,训练数据集和测试数据集都有xs和ys,我们使用 mnist.train.images 和 mnist.train.labels 表示训练数据集中图片数据和对于的label数据。
一张图片是一个28*28的像素点矩阵,我们可以用一个同大小的二维整数矩阵来表示。如下:
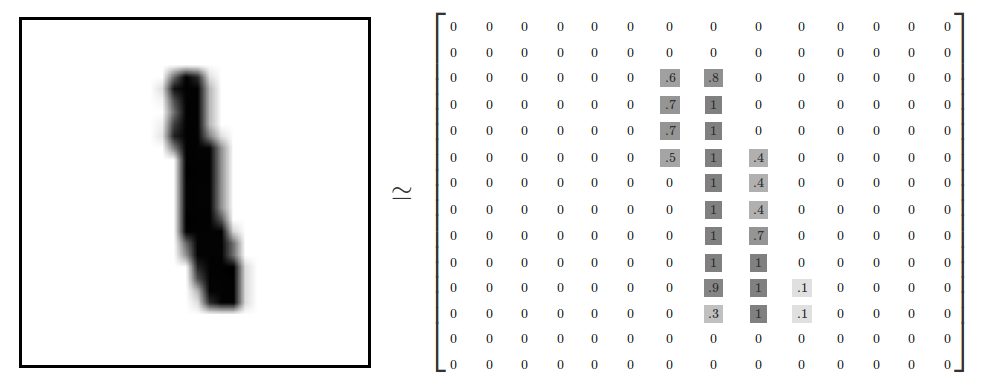
但是,这里我们可以先简单地使用一个长度为28 * 28 = 784的一维数组来表示图像,因为下面仅仅使用softmax regression来对图片进行识别分类(尽管这样做会损失图片的二维空间信息,所以实际上最好的计算机视觉算法是会利用图片的二维信息的)。
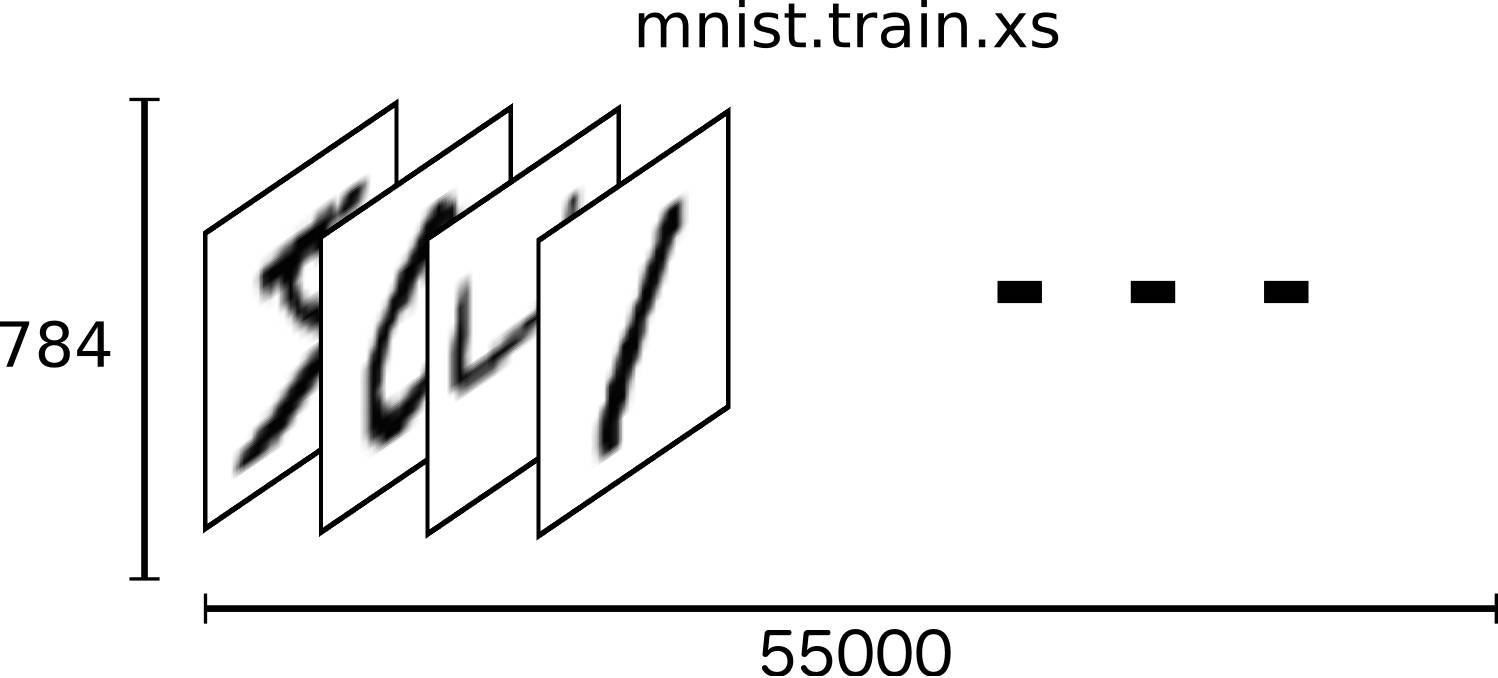
所以MNIST的训练数据集可以是一个形状为55000 * 784位的tensor,也就是一个多维数组,第一维表示图片的索引,第二维表示图片中像素的索引(”tensor”中的像素值在0到1之间)。如下图:
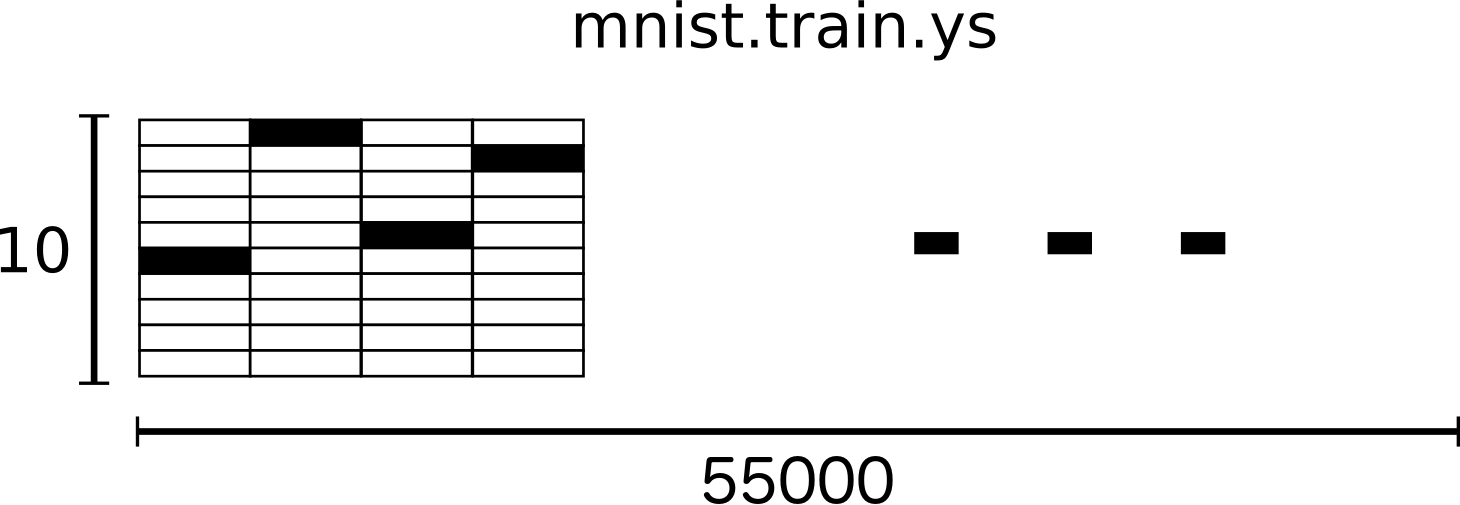
MNIST中的数字手写体图片的label值在1到9之间,是图片所表示的真实数字。这里用One-hot vector来表述label值,vector的长度为label值的数目,vector中有且只有一位为1,其他为0.为了方便,我们表示某个数字时在vector中所对应的索引位置设置1,其他位置元素为0. 例如用[0,0,0,1,0,0,0,0,0,0]来表示3。所以,mnist.train.labels是一个55000 * 10的二维数组。如下:
以上是MNIST数据集的描述及TensorFlow中表示。下面介绍Softmax Regression模型。
Softmax Regression模型
数字手写体图片的识别,实际上可以转化成一个概率问题,如果我们知道一张图片表示9的概率为80%,而剩下的20%概率分布在8,6和其他数字上,那么从概率的角度上,我们可以大致推断该图片表示的是9.
Softmax Regression是一个简单的模型,很适合用来处理得到一个待分类对象在多个类别上的概率分布。所以,这个模型通常是很多高级模型的最后一步。
Softmax Regression大致分为两步(暂时不知道如何合理翻译,转原话):
Step 1: add up the evidence of our input being in certain classes;
Step 2: convert that evidence into probabilities.
为了利用图片中各个像素点的信息,我们将图片中的各个像素点的值与一定的权值相乘并累加,权值的正负是有意义的,如果是正的,那么表示对应像素值(不为0的话)对表示该数字类别是积极的;否则,对应像素值(不为0的话)对表示该数字类别是起负面作用的。下面是一个直观的例子,图片中蓝色表示正值,红色表示负值(蓝色区域的形状趋向于数字形状):
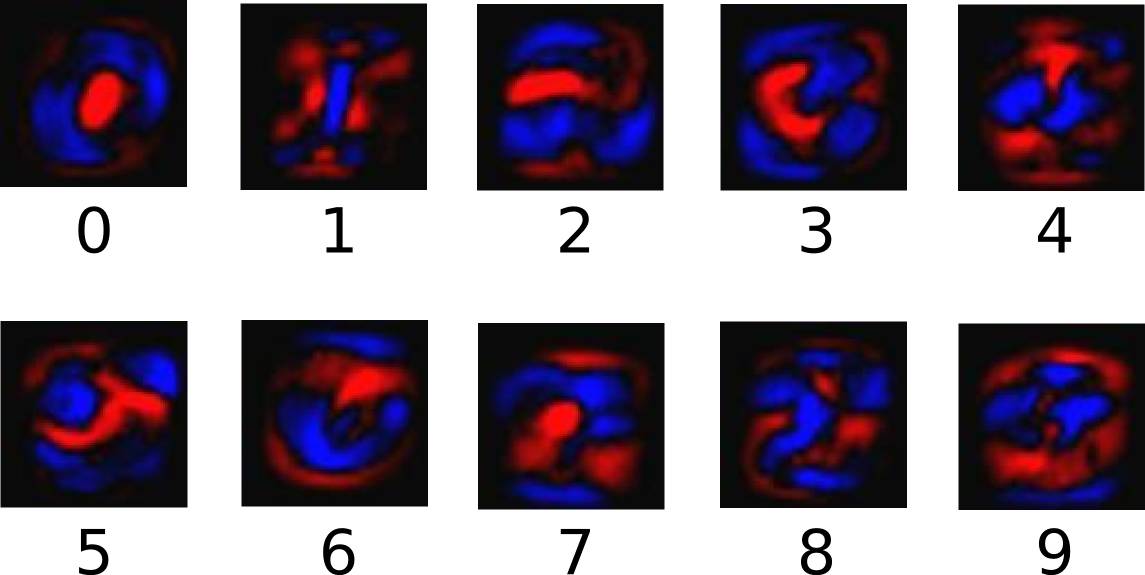
最后,我们在一个图片类别的evidence(不知如何翻译..)中加入偏置(bias),加入偏置的目的是加入一些与输入独立无关的信息。所以图片类别的evidence可表示为
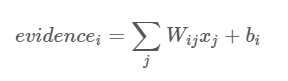
其中,w_i 和 b_i 分别为类别i的权值和偏置,j是输入图片 x的像素索引。然后,我们将得到的evidence值通过一个”softmax”函数转化为概率值y:
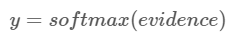
这里softmax函数的作用相当于是一个转换函数,它的作用是将原始的线性函数输出结果以某种方式转换为我们需要的值,这里我们需要0-9十个类别上的概率分布。softmax函数的定义如下:

具体计算方式如下
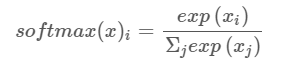
这里的softmax函数能够得到类别上的概率值分布,并保证所有类别上的概率值之和为1. 下面的图示将有助于你理解softmax函数的计算过程:
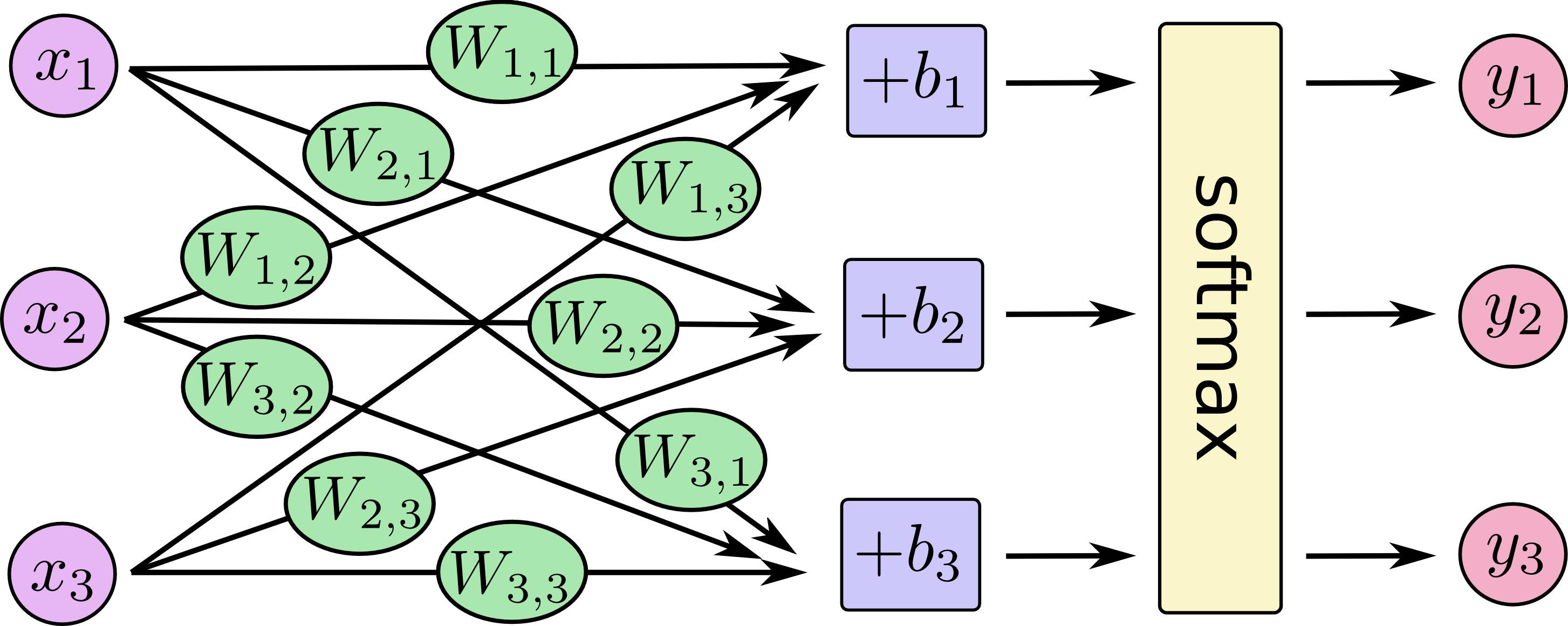
如果我们将这个过程公式化,将得到
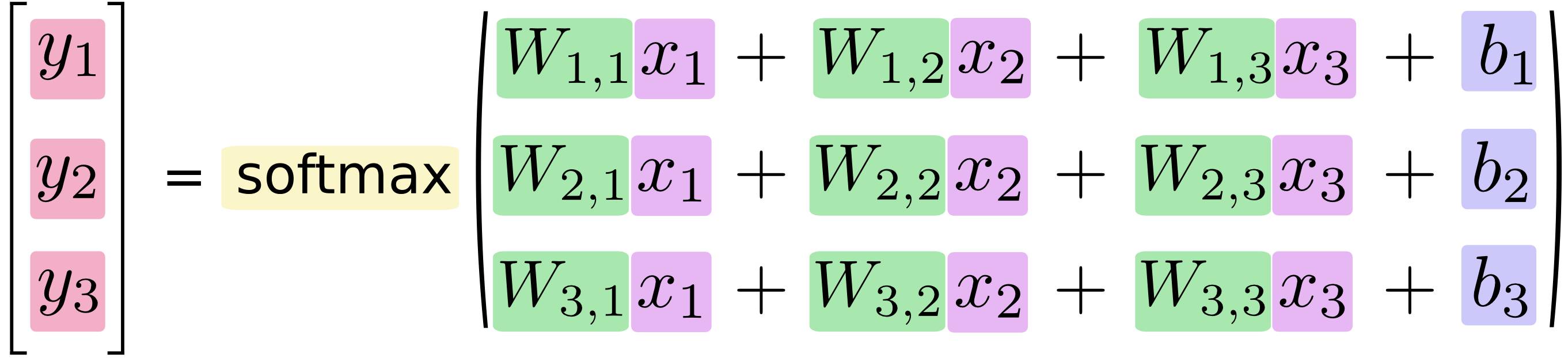
实际的计算中,我们通常采用矢量计算的方式,如下
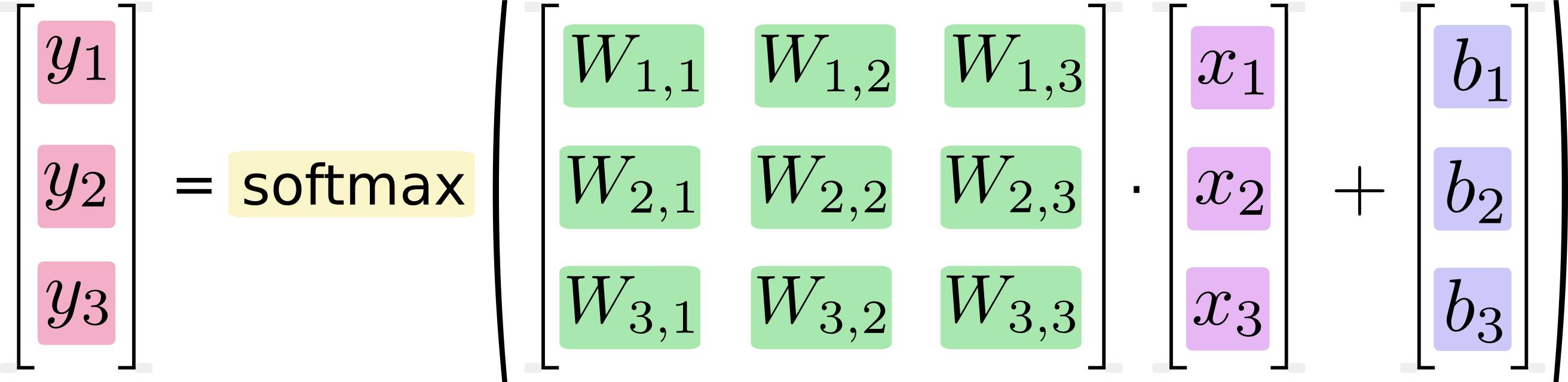
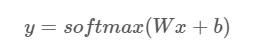
Softmax Regression的程序实现
为了在Python中进行科学计算工作,我们常常使用一些独立库函数包,例如NumPy来实现复杂的矩阵计算。但是由于Python的运行效率并不够快,所以常常用一些更加高效的语言来实现。但是,这样做会带来语言转换(例如转换回python操作)的开销。TensorFlow在这方面做了一些优化,可以对你所描述的一系列的交互计算的流程完全独立于Python之外,从而避免了语言切换的开销。
为了使用TensorFlow,我们需要引用该库函数
import tensorflow as tf我们利用一些符号变量来描述交互计算的过程,创建如下
x = tf.placeholder(tf.float32, [None, 784])这里的
x 不是一个特定的值,而是一个占位符,即需要时指定。如前所述,我们用一个1 * 784维的向量来表示一张MNIST中的图片。我们用[None, 784]这样一个二维的tensor来表示整个MNIST数据集,其中None表示可以为任意值。
我们使用Variable(变量)来表示模型中的权值和偏置,这些参数是可变的。如下,
W = tf.Variable(tf.zeros([784, 10]))b = tf.Variable(tf.zeros([10]))这里的W和b均被初始化为0值矩阵。W的维数为784 * 10,是因为我们需要将一个784维的像素值经过相应的权值之乘转化为10个类别上的evidence值;b是十个类别上累加的偏置值。
实现softmax regression模型仅需要一行代码,如下
y = tf.nn.softmax(tf.matmul(x, W) + b)其中,matmul函数实现了 x 和 W 的乘积,这里 x 为二维矩阵,所以放在前面。可以看出,在TensorFlow中实现softmax regression模型是很简单的。
模型的训练
在机器学习中,通常需要选择一个代价函数(或者损失函数),来指示训练模型的好坏。这里,我们使用交叉熵函数(cross-entropy)作为代价函数,交叉熵是一个源于信息论中信息压缩领域的概念,但是现在已经应用在多个领域。它的定义如下:
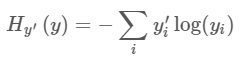
这里y是所预测的概率分布,而y'是真实的分布(one-hot vector表示的图片label)。直观上,交叉熵函数的输出值表示了预测的概率分布与真实的分布的符合程度。更加深入地理解交叉熵函数,可参考这篇博文http://colah.github.io/posts/2015-09-Visual-Information/。
为了实现交叉熵函数,我们需要先设置一个占位符在存放图片的正确label值,
y_ = tf.placeholder(tf.float32, [None, 10])然后得到交叉熵,即 −∑y′log(y):
cross_entropy = -tf.reduce_sum(y_*tf.log(y))注意,以上的交叉熵不是局限于一张图片,而是整个可用的数据集。
接下来我们以代价函数最小化为目标,来训练模型以得到相应的参数值(即权值和偏置)。TensorFlow知道你的计算过程,它会自动利用后向传播算法来得到相应的参数变化,对代价函数最小化的影响作用。然后,你可以选择一个优化算法来决定如何最小化代价函数。如下,
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)在这里,我们使用了一个学习率为0.01的梯度下降算法来最小化代价函数。梯度下降是一个简单的计算方式,即使得变量值朝着减小代价函数值的方向变化。TensorFlow也提供了许多其他的优化算法,仅需要一行代码即可实现调用。
TensorFlow提供了以上简单抽象的函数调用功能,你不需要关心其底层实现,可以更加专心于整个计算流程。在模型训练之前,还需要对所有的参数进行初始化:
init = tf.initialize_all_variables()我们可以在一个Session里面运行模型,并且进行初始化:
sess = tf.Session()sess.run(init) 接下来,进行模型的训练
for i in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})每一次的循环中,我们取训练数据中的100个随机数据,这种操作成为批处理(batch)。然后,每次运行train_step时,将之前所选择的数据,填充至所设置的占位符中,作为模型的输入。
以上过程成为随机梯度下降,在这里使用它是非常合适的。因为它既能保证运行效率,也能一定程度上保证程序运行的正确性。(理论上,我们应该在每一次循环过程中,利用所有的训练数据来得到正确的梯度下降方向,但这样将非常耗时)。
模型的评价
怎样评价所训练出来的模型?显然,我们可以用图片预测类别的准确率。
首先,利用tf.argmax()函数来得到预测和实际的图片label值,再用一个tf.equal()函数来判断预测值和真实值是否一致。如下:
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))correct_prediction是一个布尔值的列表,例如 [True, False, True, True]。可以使用tf.cast()函数将其转换为[1, 0, 1, 1],以方便准确率的计算(以上的是准确率为0.75)。
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))最后,我们来获取模型在测试集上的准确率,
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))Softmax regression模型由于模型较简单,所以在测试集上的准确率在91%左右,这个结果并不算太好。通过一些简单的优化,准确率可以达到97%,目前最好的模型的准确率为99.7%。(这里http://rodrigob.github.io/are_we_there_yet/build/classification_datasets_results.html有众多模型在MNIST数据集上的运行结果)。
完整代码及运行结果
利用Softmax模型实现手写体识别的完整代码如下:
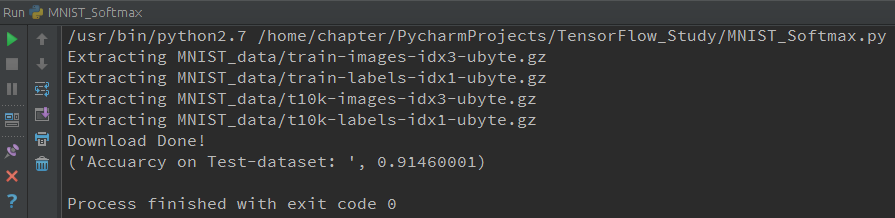
__author__ = 'chapter'import tensorflow as tffrom tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) print("Download Done!") x = tf.placeholder(tf.float32, [None, 784])# parasW = tf.Variable(tf.zeros([784, 10])) b = tf.Variable(tf.zeros([10])) y = tf.nn.softmax(tf.matmul(x, W) + b) y_ = tf.placeholder(tf.float32, [None, 10])# loss funccross_entropy = -tf.reduce_sum(y_ * tf.log(y)) train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)# initinit = tf.initialize_all_variables() sess = tf.Session() sess.run(init)# trainfor i in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys}) correct_prediction = tf.equal(tf.arg_max(y, 1), tf.arg_max(y_, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) print("Accuarcy on Test-dataset: ", sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))运行结果如下图:
本文转自:http://www.jeyzhang.com/tensorflow-learning-notes.html





