CIFAR-10上做NAS,仅需单卡半天!华为提出基于进化算法和权值共享CARS模型

作者 | VincentLee
编辑 | 贾伟
CVPR 2020 已经公布录用结果,其中有效投稿 6656 篇,最终录用 1470 篇,接收率 22.1 % 。CVPR 2020 将于6月14日-6月19日在美国西雅图举办。 虽然在近三年来,CVPR 的论文投稿量都在持续大涨(CVPR 2018有 3300 篇有效投稿、CVPR 2019有 5160 篇有效投稿、CVPR 2020有效投稿达6656),然而在接收率方面,已是“二连降”(CVPR 2018 收录论文 979 篇、接收率为 29%左右;CVPR 2019 收录论文 1300 篇,接收率为25%左右;CVPR 2020 收录论文 1470篇、接收率为 22%左右)。
本文转载自微信公众号:晓飞的算法工程笔记

一、方法
 ,
,
 为种群大小。在结构优化阶段,种群内的结构根据论文提出的pNSGA-III方法逐步更新。为了加速,使用一个超网
为种群大小。在结构优化阶段,种群内的结构根据论文提出的pNSGA-III方法逐步更新。为了加速,使用一个超网
 用来为不同的结构共享权重
用来为不同的结构共享权重
 ,能够极大地降低个体训练的计算量。
,能够极大地降低个体训练的计算量。
Supernet of CARS
中采样不同的网络,每个网络
 可以表示为浮点参数集合
可以表示为浮点参数集合
 以及二值连接参数集合
以及二值连接参数集合
 ,其中0值表示网络不包含此连接,1值则表示使用该连接,即每个网络
可表示为
,其中0值表示网络不包含此连接,1值则表示使用该连接,即每个网络
可表示为
 对。
是在网络集合中共享,如果这些网络结构是固定的,最优的
可通过标准反向传播进行优化,优化的参数
适用于所有网络
以提高识别性能。在参数收敛后,通过基因算法优化二值连接
对。
是在网络集合中共享,如果这些网络结构是固定的,最优的
可通过标准反向传播进行优化,优化的参数
适用于所有网络
以提高识别性能。在参数收敛后,通过基因算法优化二值连接
 ,参数优化阶段和结构优化阶段是CARS的主要核心。
,参数优化阶段和结构优化阶段是CARS的主要核心。
Parameter Optimization
为网络中的所有参数,参数
 ,
,
 为mask操作,只保留
为mask操作,只保留
 对应位置的参数。对于输入
对应位置的参数。对于输入
 ,网络的结果为
,网络的结果为
 ,
为
,
为
 -th个网络,
为其参数
-th个网络,
为其参数
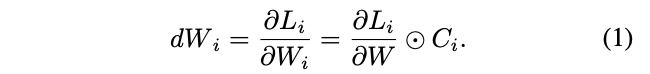
 ,预测的损失为
,预测的损失为
 ,则
的梯度计算如公式1。
,则
的梯度计算如公式1。
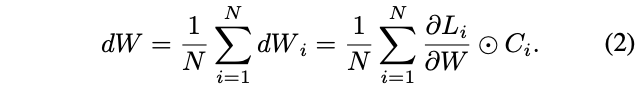 应该适用于所有个体,因此使用所有个体的梯度来计算
的梯度,计算如公式2,最终配合SGD进行更新,
应该适用于所有个体,因此使用所有个体的梯度来计算
的梯度,计算如公式2,最终配合SGD进行更新,
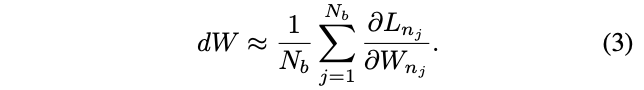
 个不同的网络进行参数更新,编号为
个不同的网络进行参数更新,编号为
 。计算如公式3,使用小批量网络来接近所有网络的梯度,能够极大地减少优化时间,做到效果和性能间的平衡。
。计算如公式3,使用小批量网络来接近所有网络的梯度,能够极大地减少优化时间,做到效果和性能间的平衡。
Architecture Optimization
 为
个不同的网络,
为
个不同的网络,
 为希望优化的
为希望优化的
 个指标,一般这些指标都是有冲突的,例如参数量、浮点运算量、推理时延和准确率,导致同时优化这些指标会比较难。
个指标,一般这些指标都是有冲突的,例如参数量、浮点运算量、推理时延和准确率,导致同时优化这些指标会比较难。
 的准确率大于等于网络
的准确率大于等于网络
 ,并且有一个其它指标优于网络
,则称网络
支配网络
,在进化过程网络
可被网络
代替。利用这个方法,可以在种群中挑选到一系列优秀的结构,然后使用这些网络来优化超网对应部分的参数。
,并且有一个其它指标优于网络
,则称网络
支配网络
,在进化过程网络
可被网络
代替。利用这个方法,可以在种群中挑选到一系列优秀的结构,然后使用这些网络来优化超网对应部分的参数。
Continuous Evolution for CARS

-
Parameter Warmup,由于超网的共享权重是随机初始化的,如果结构集合也是随机初始化,那么出现最多的block的训练次数会多于其它block。因此,使用均分抽样策略来初始化超网的参数,公平地覆盖所有可能的网络,每条路径都有平等地出现概率,每种层操作也是平等概率,在最初几轮使用这种策略来初始化超网的权重; -
Architecture Optimization,在完成超网初始化后,随机采样 个不同的结构作为父代,
为超参数,后面pNSGA-III的筛选也使用。在进化过程中生成
个子代,
是用于控制子代数的超参,最后使用pNSGA-III从
中选取
个网络用于参数更新;
-
Parameter Optimization,给予网络结构合集,使用公式3进行小批量梯度更新。



Search Time Analysis
 ,验证耗时
,验证耗时
 ,warmup共
,warmup共
 周期,共需要
周期,共需要
 时间来初始化超网
的参数。假设进化共
时间来初始化超网
的参数。假设进化共
 轮,每轮参数优化阶段对超网训练
轮,每轮参数优化阶段对超网训练
 周期,所以每轮进化的参数优化耗时
周期,所以每轮进化的参数优化耗时
 ,
,
 为mini-batch大小。结构优化阶段,所有个体是并行的,所以搜索耗时为
为mini-batch大小。结构优化阶段,所有个体是并行的,所以搜索耗时为
 。CARS的总耗时如公式5:
。CARS的总耗时如公式5:
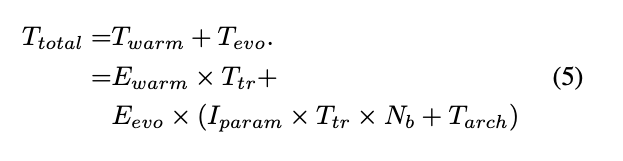
二、实验
实验设置
在CIFAR-10的实验
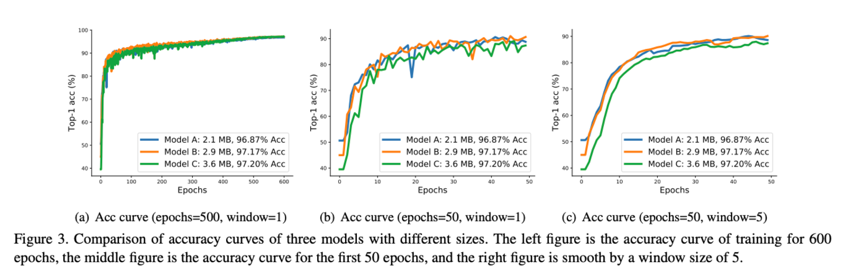 为1分钟,测试时间
为5秒,warmup阶段共50轮,大约耗费1小时。而连续进化算法共
轮,对于每轮结构优化阶段,并行测试时间为
,对于每轮的参数优化阶段,设定
为1分钟,测试时间
为5秒,warmup阶段共50轮,大约耗费1小时。而连续进化算法共
轮,对于每轮结构优化阶段,并行测试时间为
,对于每轮的参数优化阶段,设定
 ,
,
 大约为10分钟,
大约为10分钟,
 大约为9小时,所以
大约为9小时,所以
 为0.4 GPU day,考虑结构优化同时要计算时延,最终时间大约为0.5 GPU day。
为0.4 GPU day,考虑结构优化同时要计算时延,最终时间大约为0.5 GPU day。
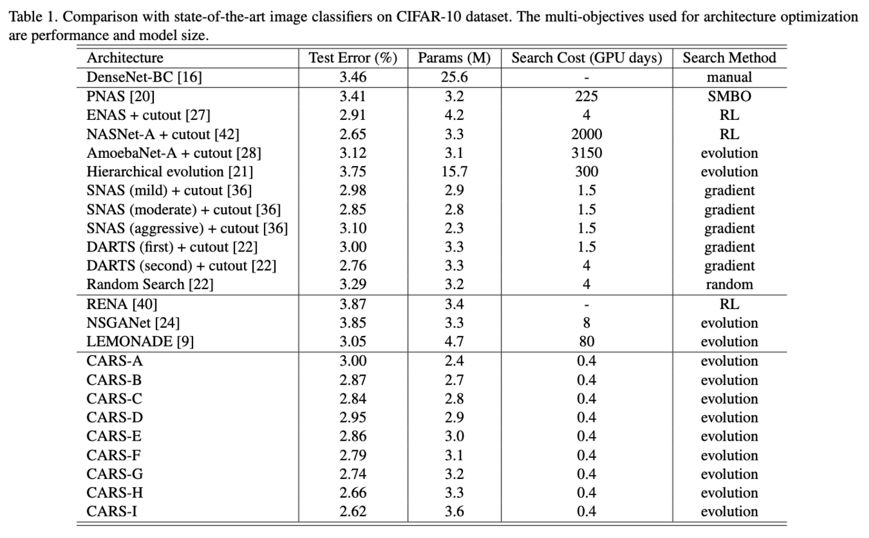
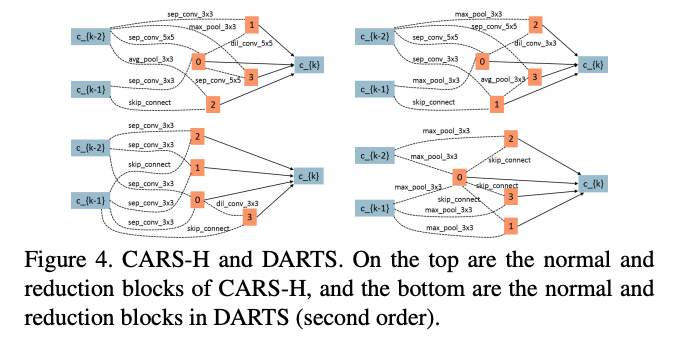
CARS-H与DARTS参数相似,但准确率更高,CARS-H的reduction block包含更多的参数,而normal block包含更少的参数,大概由于EA有更大的搜索空间,而基因操作能更有效地跳出局部最优解,这是EA的优势。
在 ILSVRC2012 上进行评估
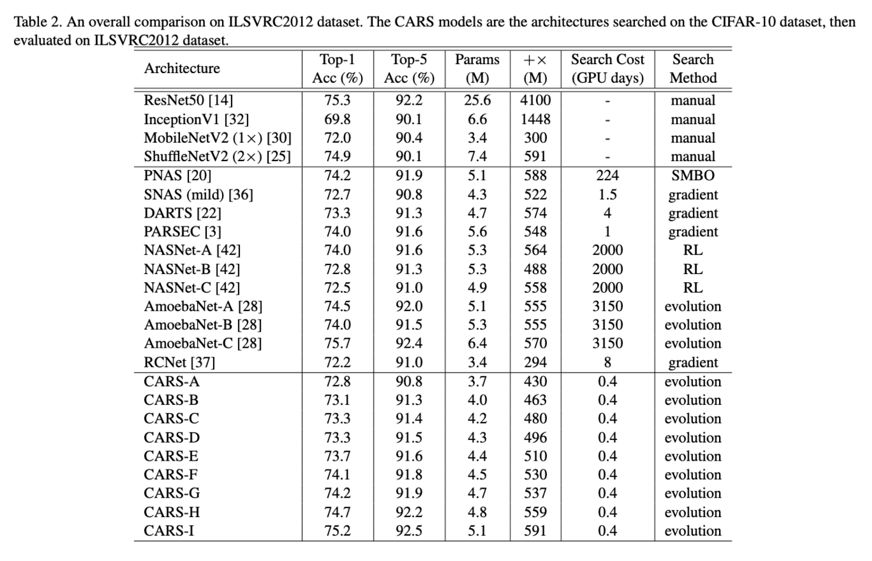
三、结论
登录查看更多
相关内容
专知会员服务
17+阅读 · 2019年11月17日


相关VIP内容
专知会员服务
17+阅读 · 2019年11月17日
相关资讯
相关论文