风靡全球的GANs:一文看尽这“混世魔王”的“三生三世”

新智元报道
【新智元导读】GANs是人工智能研究中最为前沿和活跃的领域之一,其强大的特技与广泛的应用使其在全球范围内广为流传!那么这风靡全球的GANs,其前世、今生、来世又是如何呢?在2020年开年之际,我们来谈一谈。戳右边链接上 新智元小程序 了解更多!

1959年Arthur Samuel曾经这样定义机器学习:“Field of study that gives computers the ability to learn without being explicitly programmed.”(使计算机在没有明确编程的情况下进行学习)。在IBM工作期间,他设计了一款西洋棋游戏——“塞缪尔跳棋游戏”( the Samuel Checkers-Playing Program),这是最早成功自学的程序之一。

如果Samuel是GANs的“爷爷”,那么前Google Brain研究科学家(现在苹果公司任职)Ian Goodfellow可能就是GANs的“父亲”。2014年,Goodfellow及其同事在题为“Generative Adversarial Nets”的研究论文中,描述了基于对抗网络的生成模型的首次实现。

Ian Goodfellow与“深度学习圣经”
Goodfellow并非唯一从事对抗性AI模型设计的人。Dalle Molle人工智能研究所负责人Juergen Schmidhuber提倡可预测性最小化(Predictability Minimization),通过编码器将被预测器最小化的目标函数(指定系统要解决的问题)最大化,对分布进行建模。

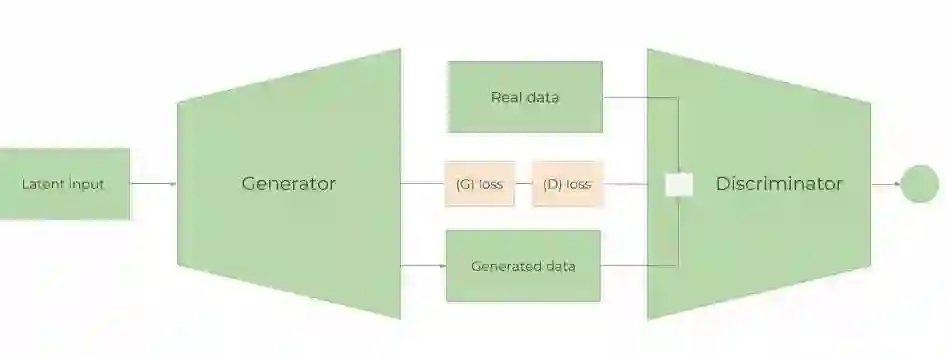
观摩GANs的架构,方知其中精妙绝伦之处
GANs是由2部分组成:生成样本的生成器、试图区分生成的样本与真实样本的鉴别器。生成器模型从使用分布对随机噪声的采样中生成合成示例(如图像),并将这些示例与来自训练数据集的真实示例一起“喂”给鉴别器,鉴别器试图在这两者之间进行区分。生成器和鉴别器的能力都得到提高,直到鉴别器无法从合成示例中分辨出真实示例的准确率超过预期的50%。
这种独特的结构,使得GANs能够实现令人叹为观止的媒体合成特技;但同时又可能被用于生成有问题的内容,如Deepfake可以将人们带入现有媒体并用其他人的肖像代替自己的!这个结构巧妙否?!
GANs应用场景广阔而悠远,“海纳百川,有容乃大”
GANs可能是以合成图像而风靡全球的!Nvidia开发的StyleGAN,通过学习面部姿势、皮肤与头发等属性,生成虚构人物的高清头像。新版本StyleGAN 2在架构与训练方法方面均有提高,重新定义了感知品质方面的最新水平,生成图像逼真到吓人!

使用StyleGAN合成的图像
2019年6月,Microsoft研究人员详细介绍了ObjGAN——一款新颖的GAN,可以理解一段文字说明、生成草图,并根据确切描述完善图像细节。

Obj-GAN的实例
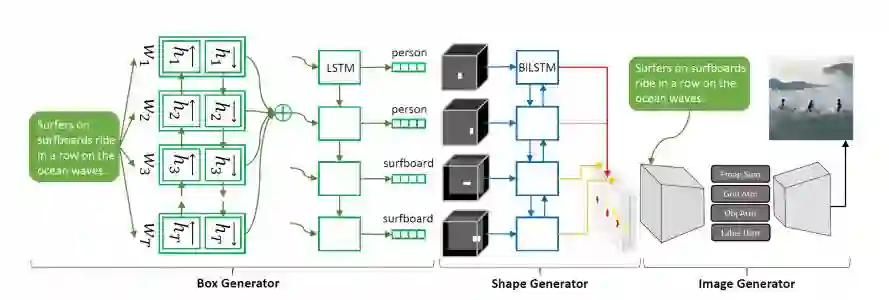
微软发布的另一款StoryGAN,可以实现“故事可视化”——给定一个包含多个句子的段落,通过生成一个图像序列(每个句子对应一个图像)来使故事可视化。StoryGAN同样基于GAN构建,但它包含上下文编码器(可动态跟踪故事流)与两个鉴别器(故事和图像级别),以提高生成的序列的质量和一致性。

https://www.microsoft.com/en-us/research/uploads/prod/2019/06/1812.02784.pdf
创业公司Vue.ai的GAN通过分析服装的特征,学会了制作逼真的姿势、肤色和其它特征。从服装的快照中,它可以生成各种尺寸的模型图像,比传统的照片拍摄速度快5倍!

Vue.ai正在引领新的潮流
卡内基梅隆大学(Carnegie Mellon)的科学家们演绎了Recycle-GAN,一种数据驱动的方法,用于将一个视频或照片的内容传输到另一个视频或照片。在对人体的镜头进行训练时,GAN生成的剪辑捕获了微妙的表情,如人物微笑和张开嘴巴时形成的酒窝和线条。

花儿正在绽放
位于首尔的Hyperconnect发布了MarioNETte,它在保留脸的外貌的同时,合成通过人的动作动画制作的重新生成的面孔。

MarioNETte的结果与基准的比较
借助GANs这“混世魔王”和新颖数据集这股“东风,现在仅需几个视频帧就能预测未来的事件——曾经被认为是不可能完成的任务!
DeepMind的一篇最新论文详细介绍了人工智能剪辑生成这一新兴领域的最新进展。得益于“计算效率”的组件和技术,以及一套新的定制数据集,他们的最佳性能模型——双视频鉴别器GAN (DVD-GAN)——可以生成256 x 256像素、长达48帧的“高保真”连贯视频。

https://arxiv.org/pdf/1907.06571.pdf

Cambridge的顾问们演示了一种名为DeepRay的模型,该模型发明了视频帧以减轻由于雨水、灰尘、烟雾和其他碎屑而引起的失真。

当GANs在合适的数据集上训练后,还能创作出新的艺术作品。印度理工学院(Indian institute of technology)与萨西萨伊高等学院(Sri Sathya Sai Institute of Higher Learning)的研究员设计了一种称为SkeGAN的GAN,可以生成基于笔触的猫、消防车、蚊子和瑜伽姿势的矢量速写。

该模型的应用实例
荷兰马斯特里赫特大学(Maastricht University)的科学家发明了一种GAN,它可以从12种不同颜色中的一种生成logo。

卡内基梅隆大学毕业生Victor Dibia训练了一个GAN来合成非洲部落面具。

爱丁堡大学(University of Edinburgh)感知研究所和天文学研究所的一个团队设计了一个模型,可以生成与真实星系的分布密切相关的虚构星系图像。

Nvidia在GTC(GPU Technology Conference)上揭开了GauGAN的面纱(GauGAN的名字来自后印象派画家Paul Gauguin),它是一种生成对抗人工智能生成系统,可让用户创建栩栩如生的风景图像。

支撑GauGAN的机器学习模型在来自Flickr的100多万张照片中被训练,让它对180多个对象的关系进行了深入的了解,包括雪、树、水、花、灌木、山丘和山脉。
在去年8月的一篇论文中,来自东京国立情报学研究所(National Institute of Informatics)的研究员研发了一个系统,能通过音节和音符之间的习得关系生成“以歌词为条件”的旋律。

https://arxiv.org/pdf/1908.05551.pdf
去年12月,Amazon Web Services推出了DeepComposer——一款基于云计算的服务,利用GAN来填补歌曲中的创作空白。
Google和伦敦帝国理工学院(Imperial College London)的研究员最近着手创建了一个基于GAN的文本到语音系统,能够达到(或优于)最先进的方法。他们提出的系统GAN-TTS由一个神经网络组成,该网络通过训练一个包含567个编码语音、时长和音调数据的语音语料库来学习产生原始音频。
GANs的未来会如何发展?尽管过去十年的研究已经取得了长足进步,但现在还尚处于早期阶段。
当下GANs仍缺少非常细致的控制,这是一个巨大的挑战。由GAN生成的内容将越来越难以与真实内容区分开来;这个领域未来会有很大改善,将2014年的图像生成与今天的图像进行比较,我们都没想到它的质量会变得那么好。如果按照这种进展继续下去,GANs将仍然是一个非常重要的研究项目。
诚然,由于编者水平有限,尚无法将这“混世魔王”的来世一一道尽。如果您有更好的想法或者观点,不妨且来小程序里与我们探讨一二,不胜感激!



