Jurgen Schmidhuber新论文:我的就是我的,你的GAN还是我的
机器之心报道
机器之心编辑部
Jurgen 一直认为 GAN 是其 PM 模型(1992)的变体,他与 Goodfellow 从邮件到演讲也有多次公开交流。然而最近,Jurgen 独立发表了一篇综述论文,再一次概览了极小极大博弈,及 PM 模型与 GAN 之间的强烈联系。
生成对抗网络(GAN)通过两个无监督神经网络学习建模数据分布,这两个神经网络互相拉锯,每一个都试图最小化对方试图最大化的目标函数。最近 LSTM 之父 Jürgen Schmidhuber 在一篇综述论文中,将 GAN 这一博弈策略与应用无监督极小极大博弈的早期神经网络关联起来。而这篇论文中提到的早期神经网络 Adversarial Curiosity、PM 模型均出自 Jürgen Schmidhuber。
他认为:GAN 可以看作是 Adversarial Curiosity (1990) 的特例,Adversarial Curiosity 基于两个网络之间的极小极大博弈,其中一个网络通过其概率动作生成数据,而另一个网络预测输出的结果。
另外,Jürgen 之前曾表示 PM(Predictability Minimization)模型(Jürgen 于 1992 年提出)并非基于极小极大博弈,现在他对此说法予以否认,认为 PM 模型通过神经编码器建模数据分布,而该编码器最大化神经预测器试图最小化的目标函数。

Jürgen 在 NIPS 2016 打断 Goodfellow 关于 GAN 的教程,并提问 PM 模型与 GAN 之间有什么不同。
谷歌大脑研究科学家 David Ha 在 Twitter 上转发了这篇论文,并赞扬 Jürgen Schmidhuber 雄心依旧。去年,David Ha 与 Jürgen 合作了论文《World Models》;近日 David Ha 发表论文,提出不需要权重训练的神经网络。
Jürgen Schmidhuber 是这篇 GAN 综述论文的唯一作者,详细介绍了 GAN 与早期使用极小极大博弈的神经网络之间的关系。接下来我们来一探究竟。
无监督极小极大博弈在计算机科学中的应用
计算机科学历史上,通过最小化另一个程序最大化的目标函数来求解问题的做法有很多。1990 年后,对抗技术应用于无监督人工神经网络领域。在该环境中,单个智能体拥有两个独立的学习神经网络。第一个神经网络在没有教师也没有外部奖励满足用户定义目标的情况下,生成数据。第二个神经网络学习预测输出结果的属性,以最小化误差。第一个神经网络最大化第二个神经网络最小化的目标函数,从而生成能让第二个神经网络学到更多的数据。
近期应用无监督极小极大博弈的例子即生成对抗网络(GAN)。GAN 一词最早出现在 Ian Goodfellow 等人的论文中,而 GAN 的基本思想最早由 Olli Niemitalo 于 2010 年提出(未经同行评审)。
GAN 是 Adversarial Curiosity (1990) 的一个特例
1990 年出现了第一个无监督对抗神经网络 Adversarial Curiosity,它尝试在强化学习探索环境中实现好奇心(curiosity)(Adversarial Curiosity 以下简称 AC1990)。Jürgen 认为 GAN 与 AC1990 有很大关联。
在 AC1990 中,第一个神经网络通常称为控制器 C。C 可以通过一系列互动(叫做「试验」或「事件(episode)」)与环境进行交互。在任意试验中执行一次交互时,控制器 C 生成输出向量 x ∈ R^n。该输出向量可能会影响环境,环境输出对 x 的回应:y ∈ R^q。同样地,y 可能影响 C 在下一次迭代中的输入。
在 AC1990 的第一个变体中,C 是循环神经网络,因此它是一种通用目的的计算方式。C 的一些适应性循环单元是生成均值和方差的高斯单元,因此 C 就变成了生成模型(Jürgen 在「Explicit Random Actions versus Imported Randomness」章节有提及)。这些随机单元所做的事情等同于让 C 感知伪随机数字或噪声所完成的事情,这与 GAN 中的生成器类似。
AC1990 中的第二个神经网络是世界模型 M。在 AC1990 的第一个变体中,出于通用性的原因,M 也是循环的。M 以 C 的输出 x ∈ R^n 为输入,并预测其对环境的影响或后果 y ∈ R^q。
根据 AC1990,M 最小化其预测误差,从而变成更好的预测器。在没有外部奖励的情况下,对抗模型 C 尝试找到能够最大化 M 误差的动作:M 的误差是 C 的本质奖励。因此,C 最大化 M 试图最小化的误差。M 的损失就是 C 的收益。
在没有外部奖励的情况下,C 本质上被驱动去创建新的动作序列或试验,以得到令 M「吃惊」的数据,直到 M 对数据熟悉并最终厌倦。
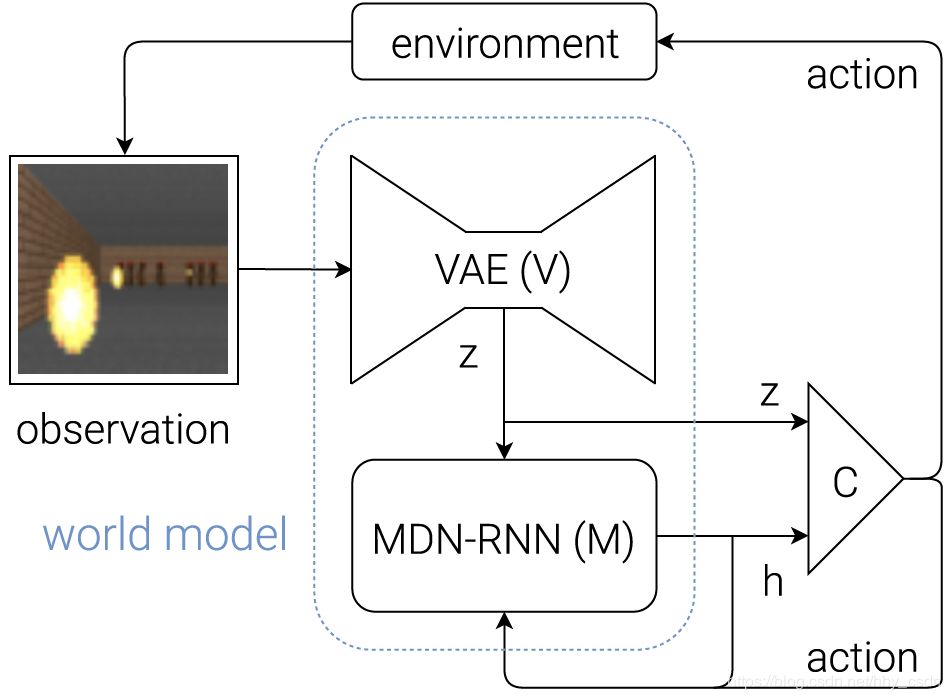
世界模型的结构图。该模型常用于智能体相关的学习。
什么样的环境使 AC1990 成为 GAN?
哪一种部分可观测环境会使 AC1990 成为生成图像的 GAN 呢?这个环境一定包含用户给定「真实」图像训练集 X ={x^1, x^2, . . . , x^k ∈ R^n} 的表征。X 对 C 和 M 不是直接可见的,但是其属性由 AC1990 以类似 GAN 的动作或试验进行探测。
在任意给定试验开始时,C 和 M 中所有单元的激活函数都是重新设置的。C 什么都看不见(因为没有来自环境的输入)。使用内部随机单元后,C 可以计算单个输出 x ∈ R^n,即「假」图像。在所有试验的 pre-wired 部分中,x 都被从训练集 X 中随机选取的「真实」图像所替代(传统强化学习默认的这一简单探索策略可以在所有试验的固定部分中选择随机动作)。这确保了 M 能够看到真假图像。
环境将对输出动作 x 给出回应,将 x 对环境的影响返回为二元观测结果 y ∈ R,如果图像为真,则 y = 1,反之则 y = 0。
在类似 AC1990 的系统中,M 将 C 的输出 x 作为输入,并预测其对环境的影响 y。通常,M 通过最小化其预测误差来学习。但是,在没有外部奖励的情况下,对抗网络 C 希望能最大化 M 想最小化的误差,从而学习生成数据。M 的损失即 C 的负损失(negative loss)。也就是说,M 的行为本质上类似于 GAN 中的判别器,C 类似于 GAN 中的生成器。
AC1990 的改进
1991 年,AC1990 出现了第一次重大改进。AC1990 中 M 的误差(需要被最小化)是 C 的奖励(需要被最大化)。这有利于在很多确定性环境中找到好的探索策略。但是,在随机环境中,这种做法可能失败。C 可能集中于学习环境的某些部分,而由于随机性或计算限制,M 在这些部分中总是产生较高的预测误差。例如,由 C 控制的智能体可能会停留在只有高度不可预测白噪音前。
因此,1991 版本的 AC 指出,在随机环境中,C 的奖励不应该是 M 的误差,而应该是后续训练迭代中 M 误差的一阶导数的近似,即 M 得到了改进。因此,即使 M 在有噪音的电视屏幕前出现高误差,C 也不会因为智能体停留在电视前面而得到奖励,因此 M 的误差没有得到改进。完全可预测和基本不可预测都会令 C 感到无聊。
对抗大脑将赌注押在概率规划的结果上
本文特别感兴趣的一点是以一种更高级的对抗性方法用于 1997 年提出的好奇心探索,被称为 AC 1997。
在 AC 1997 中,单个智能体有两种对抗性的奖励最大化策略,被称为左脑和右脑。每种策略都是对通用目标计算机运行程序的可修正概率分布。实验是以一种协作方式进行采样的程序,这种协作方式受左右脑的影响。通过执行由实验触发的观察序列的可计算函数(可能导致内部二元 yes/no 分类),每个实验详细说明如何执行指令序列(可能影响两个环境以及智能体的内部状态)以及如何计算实验结果。左右脑的可修正参数是指令概率。通过包含特殊自我参照策略修正指令序列的程序,可以访问和操作这些参数。
左右脑也可能触发某些下注(bet)指令的执行,这些指令是为了在它们被观察到之前预测实验结果。如果它们的预测或假设结果不同,则同意执行实验,以确定哪个大脑是正确的,并且出乎意料的失败者会在零和博弈中向获胜者支付内在奖励(实值的赌注,如 1.0)。
也就是说,一个大脑本能地通过实验来欺骗另一个大脑或使其惊讶,这样以来,另一个大脑虽然同意实验方案但不同意预期结果,这通常是复杂时空事件(通过执行自我发明的实验生成)的内在可计算抽象化。
这促使两个无监督的大脑系统着重于「有趣的」计算问题,而对左右脑能够一致性地预测结果的「无聊」计算(可能包含环境)以及当前任何大脑依然很难预测结果的计算失去了兴趣。此外,在缺少外部奖励的情况下,一个大脑将另一个大脑最小化的价值函数最大化。
AC 1997 如何与生成对抗网络产生关系呢?AC 1997 类似于标准的生成对抗网络,从某种意义上来说,两者都是无监督的生成对抗极小极大参与者,并着重于二元结果实验:1 或 0、yes 或 no、假设正确或错误。但是,对于生成对抗网络来说,实验方案是预先安排好的,并且常常是相同的:只是简单地测试最近生成的模式是否在给定的训练集中。
通过限制 AC 1997 的域以及相应编程语言中的指令属性,人们可以将其局限于上述简单的设定,这样以来,左右脑的可能下注就局限于类 GAN 实验的二元 yes/no 结果。但一般来说,AC 1997 的对抗大脑实际上可以自己创建任意的计算问题,生成的程序也能以任何可计算的方式与环境进行交互,从而输出左右脑都可以下注的二元结果。这有点像一个纯粹科学家从发明实验中汲取内在快乐信号,实验中的发现最开始令人惊讶但可学习,之后能够进行可靠的重复性预测。
GAN 和 PM 模型的对比
神经网络的一个重要的任务是从给定数据,如图片中学习统计特征。为了实现这个目标,不使用梯度下降/上升的策略,而是另一种非监督的极小极大博弈。这种博弈中,一个网络极小化被另一个网络极大化的目标函数。这种在两个非监督对抗网络的方式已经在上世纪 90 年代的多篇论文中被介绍。它被称为 PM 网络(Predictability Minimization)。
PM 的目标是实现无监督学习中最重要的任务,一个理想的、解耦的、针对给定数据的特征编码,即使编码的元素之间是统计学意义上互相独立的。也就是说,编码的分布类似于数据,同时给定数据模式的概率也是编码元素概率的产物。这样的编码可以协助完成降采样。
PM 网络需要随机初始化一个编码器的权重。它映射了数据样本 x ∈ Rn(比如图片)到编码 y ∈ [0, 1]^m,m 指的是 m 个所谓的编码单元。在编码单元中,整数编码 i,j,的取值范围是从 1 到 m。对于第 i 个 y 中的元素可以表示为 y_i ∈ [0, 1]。另外有一个独立的预测网络,使用梯度下降的方法进行训练,用于预测从剩余的元素 y_j 取的每一个 y_i(j ≠ i)。
然而,编码器是通过极大化预测器用于最小化的那个目标函数(例如,均方误差函数)。在 1996 年的论文(Semilinear predictability minimization produces well-known feature detectors)说明,「内在的含义是,编码单元是被训练(在我们的实验中是在线反向传播)用来最大化和预测器用于最小化的同一个目标函数」,或者 1999 年的论文(Neural predictors for detecting and removing redundant information)中提到,「但是编码单元尝试最大化预测器用来最小化的同一个目标函数」。
为什么这场预测器和编码器的博弈的结果是解耦的特征码?通过使用梯度下降用于最大化预测误差,编码单元使 y_j 从真正的 [0,1] 预测中偏离,即他们被逼向单元内部的角落,并倾向于二元化,要么是 0,要么是 1。同时,根据 1992 年论文的证明,当最大化第 i 个编码单元的方差时,编码器的目标函数也被最大化,因此最大化了输入数据所表达的信息。于此同时,相对于其他编码单元而言,它的(非条件的)期望 E(y_i) 和建模预测器的条件期望 E (y_i | {y_j , j ≠ i}) 的偏移被最小化。也就是说,编码单元被鼓励去从数据中提取有意义的,但是互相独立的二元信息。
PM 内在的概率分布是一个多元二项式分布。在理想状态下,PM 确实学习从数据中创建二元特征编码。也就是说,相对于一些输入特征,每个 y_i 是 0 或者 1,而预测器学习了条件预期值 E (y_i | {y_j , j≠ i})。因为编码既是二元的也是有特征的,其值和编码单元的非条件的概率 P (y_i = 1) 是等价的。例如,如果一些编码单元的预测是 0.25,则该编码单元为真的概率是 1/4。
第一个 PM 网络的尝试实验是在大约 30 年前。那时候,计算成本比现在要昂贵百万倍。当 5 年后,计算成本降低 10 倍时,有了简单的用于图片的类线性 PM 网络自动生成特征检测器。这些检测器被神经科学所熟知,如从中心到周围检测器(on-center-off-surround detectors),从周围到中心检测器(off-center-on-surround detectors),方向敏感的棒状检测器(orientation-sensitive bar detectors)等。
PM 真的不是一个最小化最大目标函数的策略吗?
NIPS2014 的 GAN 论文中,论文认为 PM 和 GAN 是不同的,因为 PM 不是基于极小极大博弈的。在极小极大博弈中,其有一个值函数(value function),其中一个智能体尝试最大化而另一个智能体尝试最小化(它)。论文宣称,对于 GAN 来说,「网络之间的对抗是唯一的训练标准,并且网络可以自给自足的训练」。但是对于 PM 来说,「(它)只是一个正则化器,用于鼓励神经网络的隐藏单元在完成其他任务时在统计学上保持独立,这不是一个基本的训练标准」。
但是这一论点是不正确的,因为 PM 的确是一个纯粹的极小极大博弈。并不存在所谓的「其他任务」。特别的,PM 也是被训练的,而且其训练过程是「网络之间的对抗是唯一的训练标准,并且网络可以自给自足的训练」。
通过 PM 变体学习生成模型
在第一个同行审阅的 PM 论文中,有一个 PM 变体网络,其中有一个可选的解码器(被称为重建器),这个重建器可以基于编码重建数据。假设 PM 确实发现了数据中理想的特征编码。因为编码的分布和数据相似,有了解码器,我们可以立刻将系统作为生成模型使用,只需要根据非条件概率随机激活每个二元编码单元,并用解码器从输出数据中采样。有了精确的解码器,采样数据必须根据特征编码遵守原始分布的统计特征
然而,在研究者的印象中,这种直接的生成模型的应用从来没有在任何一个 PM 论文中被提及。同时解码器(也被认为是额外的、可选的编码单元的局部方差最大化方法)实际上被一些 1993 年后的 PM 论文忽略了。这些论文关注于解耦内部表示的非监督学习,用于辅助降采样学习。
尽管如此,1990 年和 2014 年就提到了使用极小极大训练的随机输出并用于产生数据生成模型。
从 GAN 学习特征编码
PM 的变体可以很容易用作类似 GAN 的生成模型。相对的,GAN 的变体可以很容易像 PM 那样用来学习特征编码。如果我们将一个从随机输入编码中训练的 GAN 生成器视为一个独立组件,并在其输出层添加一个传统的编码器网络,并训练这个编码器将输出特征映射到原始的随机编码,那么在理想的情况下,这个编码器会成为一个针对其原始数据的特征编码生成器。
PM 模型和 GAN 及其变体的关系
PM 和 GAN 都是对数据的统计特征进行非监督学习的方法。两者都采用了基于梯度的对抗网络,并通过极小极大博弈实现目标。
PM 尝试产生容易解码、看似随机、具有特征编码的数据,而 GAN 尝试从随机编码中产生解码数据。从这个角度来说,PM 的编码器输入更像是生成对抗网络的解码器输出,而前者的编码器输出更像是后者解码器的输入。从另一角度来说,PM 编码器的输出类似于 GAN 解码器的输出,因为两者都是随着对抗损失的变化而变化。
GAN 尝试从其他数据分布(高斯分布、二项式分布等)中拟合真实的数据分布。类似的,PM 尝试从提前给定的多元因子二项式分布中拟合真实的数据分布。许多后 PM 方法,比如信息瓶颈法基于的是率扭曲理论(rate distortion theory),变分自编码器,噪声对比估计(Noise-Contrastive Estimation)和自监督提升方法(Self- Supervised Boosting)方法都和 PM 有着特定的关系,尽管以上的模型都没有采用像 PM 那样的基于梯度的极小极大博弈的对抗网络策略。但是,GAN 采用了。
PM 及其变体的解码器和 GAM 及其变体的编码器可以通过以下的管道流程说明(可以把它们看成是非常相似的有四个步骤的循环):
有着标准解码器的 PM 变体流程:
数据→ 极小极大化目标函数训练后的数据→ 编码→ 传统解码器(经常被忽略)→ 数据
有标准编码器的 GAN 变体流程(相比较于 InfoGAN):
编码→ 极小极大化目标函数训练的解码器→ 数据→ 标准编码器→ 编码
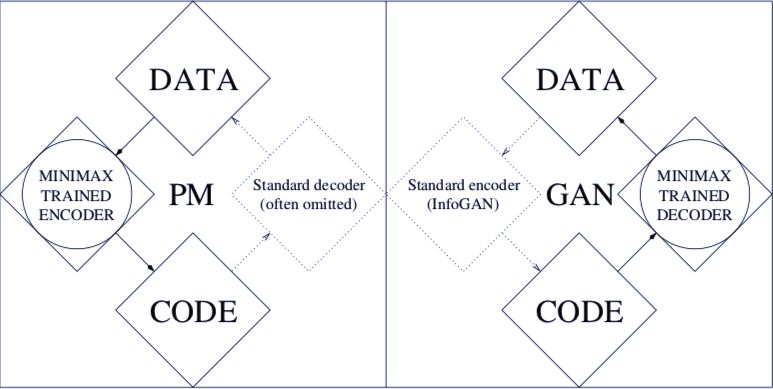
PM 和 GAN 的对比。
如果能够实验研究以上的 GAN 的管道可以比 PM 更好的训练和编码,或者在这之后可以更有效的拟合将是非常有趣的事情。

深度Pro
理论详解 | 工程实践 | 产业分析 | 行研报告
机器之心最新上线深度内容栏目,汇总AI深度好文,详解理论、工程、产业与应用。这里的每一篇文章,都需要深度阅读15分钟。
今日深度推荐

点击图片,进入小程序深度Pro栏目
PC点击阅读原文,访问官网
更适合深度阅读
www.jiqizhixin.com/insight
每日重要论文、教程、资讯、报告也不想错过?





