Michael Brostein 最新几何深度学习综述:超越 WL 和原始消息传递的 GNN
编译丨OGAI
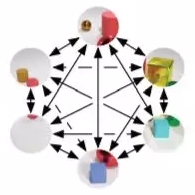
图可以方便地抽象关系和交互的复杂系统。社交网络、高能物理、化学等研究领域都涉及相互作用的对象(无论是人、粒子还是原子)。在这些场景下,图结构数据的重要性日渐凸显,相关方法取得了一系列初步成功,而一系列工业应用使得图深度学习成为机器学习方向的热门研究话题之一。
图注:通过图对复杂系统的关系、交互进行抽象。例如,「分子图」中构成分子的原子至今的化学键,「社交网络」中用户之间的关系和交互,「推荐系统」中用户和商品之间的联系。
受物理启发的图上的持续学习模型可以克服传统 GNN 的局限性。多年来,消息传递一直是图深度学习领域的主流范式,使图神经网络(GNN)在粒子物理到蛋白质设计的广泛应用中取得了巨大成功。
从理论角度来看,它建立了与 Weisfeiler-Lehman(WL)层次结构的联系,我们可以以此分析 GNN 的表达能力。但是在 Michael Brostein 看来,当前图深度学习方案「以节点和边为中心」的思维方式带来了无法克服的局限性,阻碍了该领域未来的发展。
另一方面,在关于几何深度学习的最新综述中,Brostein 提出了受物理启发的持续学习模型,从微分几何、代数拓扑和微分方程等领域出发开启了一系列新工具的研究。到目前为止,图机器学习领域中还鲜有此类研究。
针对Bronstein的最新思考,AI科技评论做了不改原意的整理与编译:
GNN 的输入为具有节点和边特征的图,计算一个既依赖于特征又依赖于图结构的函数。消息传递类的 GNN(即 MPNN)通过交换相邻节点之间的信息在图上传播特征。典型的 MPNN 架构由几个传播层组成,基于邻居特征的聚合函数对每个节点进行更新。根据聚合函数的不同,我们可以将 MPNN分为:卷积(邻居特征的线性组合,权值仅依赖于图的结构)、注意力(线性组合,权值依赖于图结构和特征)和消息传递(广义的非线性函数)。消息传递 GNN 是最常见的,而前者可以视为消息传递 GNN 的特殊情况。
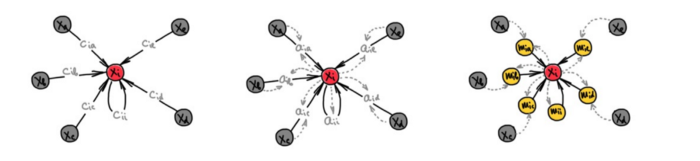
图注:GNN 的三种风格——卷积、注意力和广义非线性信息传递风格,它们都是消息传递的表现形式。
传播层由基于下游任务学习的参数构成,典型的用例包括:节点嵌入(每个节点表示为向量空间中的一个点,通过点之间的距离恢复出原始图的连通性,此类任务被称为「链接预测」),节点级的分类或回归(如推断社交网络用户的属性),或者通过进一步聚合节点的特征进行图级别的预测(例如,预测分子图的化学性质)。
GNN 在多个方面都取得了令人印象深刻的成功,最近的相关研究也具有相当的广度和深度。但是,当下的图深度学习范式的主流模型是:对于构建好的图,通过消息传递的方式沿着图的边传播节点信息。Michael Brostein 认为,正是这种以节点和边为中心的思维方式,为该领域进一步发展带来了主要的障碍。
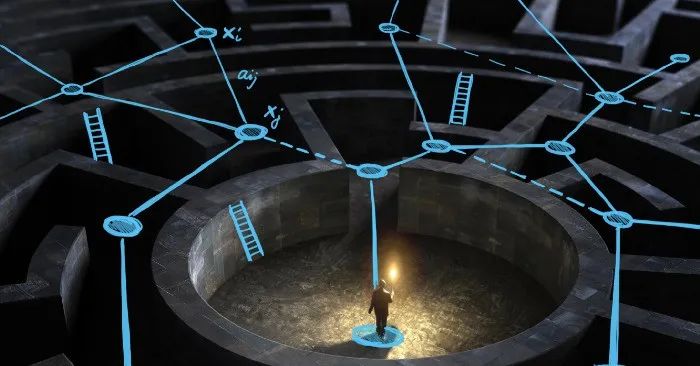
WL 的类比能力有限。适当选择像「求和」这样的局部聚合函数,可以使消息传递等价于 WL 图同构测试,使图神经网络能够根据信息在图上的传播方式发现某些图结构。通过这种与图论的重要联系,研究人员提出了多种分析 GNN 表达能力的理论结果,决定了图上的某些函数是否可以通过消息传递来计算。然而,这种类型的分析结果通常不能说明表征的效率(即需要多少层来计算某个函数),也不能说明 GNN 的泛化能力。
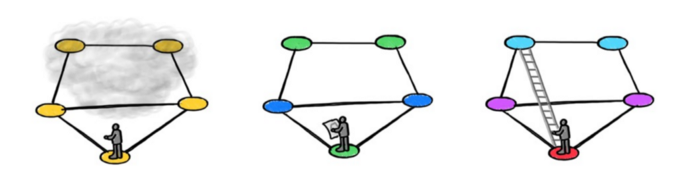
图注:WL 测试就好比在没有地图的情况下走进迷宫,并试图理解迷宫的结构。位置编码提供了迷宫的地图,而重连则提供了一个越过「墙壁」的梯子。
即使是对于三角形这种简单的图结构,有时 WL 算法也无法将它们检测出来,这让试图将信息传递神经网络用于分子图的从业者非常失望。例如,在有机化学中,像环这样的结构非常普遍,并且对分子的性质十分重要(例如,萘等芳香环之所以被称为芳香环,是因为它们主要存在于具有强烈气味的化合物中)。

图注:十氢化萘(左)和二环戊基(右)有不同的结构,但我们无法通过 WL 测试区分它们。
近年来,研究者们已经提出了一些构建表达能力更强的 GNN 模型的方法。例如,WL 层次结构中的高维同构测试(以更高的计算和内存复杂度以及缺乏局域性为代价),将 WL 测试应用于子图集合;位置或结构编码,为图中的节点着色,以这种方式帮助打破迷惑 WL 算法的规律。位置编码目前在 Transformer 模型中是最常见的技术,在 GNN 中也广为使用。虽然存在多种位置编码方法,但具体的选择还取决于目标应用,要求使用者有一定经验。
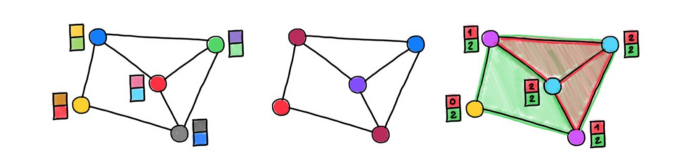
图注:位置编码示例:随机特征、拉普拉斯特征向量(类似于 Transformer 中的正弦曲线)、结构特征(三角形和矩形的个数)。
「图重连」突破了 GNN 的理论基础。GNN 和卷积神经网络(CNN)之间的一个重要且微妙的区别是:图既是输入的一部分,也是计算结构的一部分。传统的 GNN 使用输入的图结构来传播信息,通过这种方式获得既反映图结构又反映图上特征的表示。然而,由于某些结构特征(「瓶颈」),一些图在信息传播方面的性能较差,导致来自太多节点的信息被压缩到一个节点彪悍尊能中,即「过压缩」。
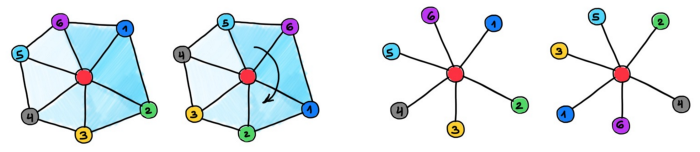
现代 GNN 实现通过将输入图与计算图解耦(或为计算目的优化输入图)来处理这种现象,这种技术称为「图重连」。重连可以采取以下形式:邻域采样、虚拟节点、连通性扩散或演化,或节点和边的 Dropout 机制。Transformer 和像 GAT 这类基于注意力的 GNN 通过为每条边分配不同的权重来有效地学习新的图,这也可以理解为一种「软性」的重接。最后,潜图学习方法也可以归入这一类,它可以构建针对特定任务的图,并在每一层中更新它(初始状态下有位置编码、初始图,或有时根本没有图)。很少有现代 GNN 模型在原始输入图上传播信息。

图注:GNN 中使用的各种图重连技术——原始图、邻域采样(例如,GraphSAGE)、注意力机制(例如,GAT)、连通性演化(例如,DIGL)。
WL 测试根据信息在图上的传播方式来描述图。重连突破了这种理论上的联系,但又让我们陷入机器学习领域常见的问题中:学术界从理论上分析的模型与实践中使用的模型并不相同。
有时,图的「几何特性」不足。GNN 是几何深度学习宏伟蓝图中的一个实例。几何深度学习是一个「群论框架」,使我们可以根据数据底层的域的对称性设计深度学习架构。由于图没有规范的节点顺序,在图的场景下,这种对称性指的是节点排列。由于这种结构特性,局部作用图上的 MPNN 必须依赖于满足排列不变性的特征聚合函数,这意味着图上没有「方向」的概念,信息的传播是各向同性的。这种情况与在连续域、网格上的学习有着显著的不同,并且是 GNN 的缺点之一,人们认为各向同性滤波器的作用有限。
图注:网格是具有局部欧氏结构的离散流形。我们根据旋转来定义邻居节点,从而形成了「方向」的概念。图的结构较少,它根据排列来定义邻居节点。
有时,图的「几何特性」又过多。距离与方向的差异在某种程度上也与构建节点嵌入时遇到的问题有关。在某些空间中节点表征之间的距离被用来捕获图的联通性。我们大致可以将嵌入空间中接近的节点通过图中的一条边连接起来。在推荐系统中,图嵌入被用来在节点所代表的实体之间创建关联(边)。
图嵌入的质量及其表达图结构的能力,在很大程度上取决于嵌入空间的几何性质及其与图的几何性质的兼容性。欧氏空间在表示学习中有重要的地位,也是目前最简单、最方便的表征空间,但对于许多自然中的图来说,欧氏空间并不理想,原因之一是:欧几里德度规球的体积随半径以多项式形式增长,而随维数指数增长,而现实世界中许多图的体积增长是指数的。因此,嵌入变得「过于拥挤」,我们被迫使用高维空间,从而导致较高的计算复杂度和空间复杂度。
最近流行的一种替代方法是使用负曲率(双曲)空间,它具有与图更兼容的指数体积增长。双曲几何的使用通常会使嵌入维数更低,使节点表示更加紧凑。然而,图往往是异质的(例如,有些部分看起来像树,其它部分看起来像团,具有非常不同的体积增长特性),而双曲嵌入空间是同质的(每个点都有相同的几何性质)。
此外,即使嵌入空间具有非欧几何性质,但通常不可能在该空间中准确地表示通用的图的度量结构。因此,图的嵌入不可避免地是近似的。然而,更糟糕的是,由于嵌入是在考虑链接预测标准的情况下构建的,高阶结构(三角形、矩形等)的畸变可能会大到无法控制的。在社会和生物网络等应用场景下,这样的结构扮演着重要的角色,因为它们可以捕获更复杂的非成对的相互作用和模体。
图注:图的模体是一种高阶的结构。在对许多生物现象建模的图中可以观察到这种结构。
当数据的结构与底层图的结构不兼容时,GNN 的性能就会受到挑战。许多图学习数据集和对比基准都默认假设数据是同质性的(即相邻节点的特征或标签是相似的,或者说是平滑的)。在这种情况下,即使是对图进行简单的低通滤波(例如,取邻接平均值)也能起到很好的效果。早期的对比基准测试(例如,Cora),都是在具有高度同质性的图上进行的,这使得 GNN 的评估过于容易。
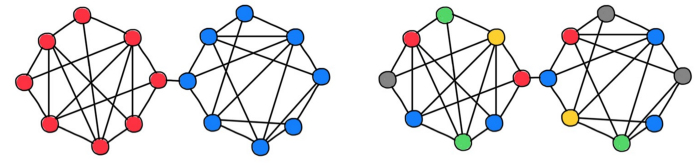
图注:同构和异构数据集。在同构图中,节点特征或标签的结构与图是兼容的(即节点与其邻居节点相似)。
然而,在处理亲异(heterophilic)数据时,许多模型显示出令人失望的结果,在这种情况下,必须使用更精细的聚合方式。我们不妨考虑两种典型的情况:(1)模型完全避免使用邻居信息(GNN 退化为节点级的多层感知机)(2)出现「过平滑」现象,即节点的表征在经过 GNN 的各层后变得更加平滑,最终「坍塌」为一个点。亲同数据集中也存在「过平滑」现象,对于某些 MPNN 来说是一个更为本质的缺陷,使深度图学习模型难以实现。
我们通常很难理解 GNN 学到了什么,GNN 往往是难以解释的黑盒模型。虽然可解释性的定义在很大程度上还较为模糊,但在大多数情况下,我们确实并不真正理解 GNN 学习了什么。最近的一些工作试图通过以紧凑的子图结构和在 GNN 预测中起关键作用的节点特征子集的形式来解释基于 GNN 的模型,从而缓解可解释性的缺陷。通过潜图学习架构学习的图也可以看作提供「解释」的一种形式。
约束通用的消息传递函数有助于排除不合理的输出,确保 GNN 学到的东西有意义,并且在特定领域的应用程序中可以更好地理解 GNN。具体而言,这样做可以为消息传递赋予额外的「内部」数据对称性,从而更好地理解底层的问题。例如,E(3)-等变消息传递能够正确地处理分子图中的原子坐标,最近对 AlphaFold 和 RosettaFold 等蛋白质结构预测架构的成功作出了贡献。
在 Miles Cranmer 和 Kyle Cranmer 合著的论文“Discovering symbolic models from deep learning with inductive biases”中,作者用符号公式取代了多体动力系统上学习的消息传递函数,从而可以「学习物理方程」。还有的研究者试图将 GNN 与因果推理联系起来,试图构建一个图来解释不同变量之间的因果关系。总的来说,这仍然是一个处于起步阶段的研究方向。
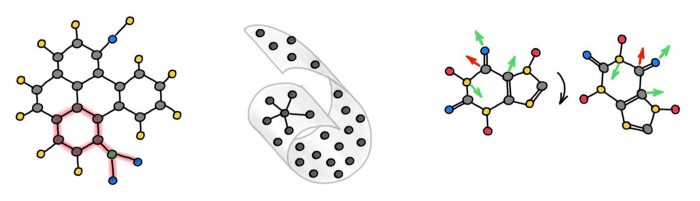
图注:不同的「可解释」GNN 模型——图解释器、潜图学习、等变消息传递。
大多数 GNN 的实现是与硬件无关的。目前大多数 GNN 依赖于 GPU 实现,并默认数据可以装入内存。然而,在处理大规模图(如生物网络和社交网络)时,这往往是一种一厢情愿的想法。在这种情况下,理解底层硬件的局限性(如不同的带宽和内存层次结构的延迟),并方便地使用硬件是至关重要的。大体来说,在相同物理内存中的两个节点和不同芯片上的两个节点之间,消息传递的成本可能存在一个数量级的差异。「使 GNN 对现有硬件友好」是一个重要而又经常被忽视的问题。考虑到设计新芯片所需的时间和精力,以及机器学习的发展速度,开发以图为中心的新型硬件是一个更大的挑战。
「持续」学习模型是一个取代离散 GNN 的新兴的、希望的方案。「受到物理系统启发的持续学习」从微分几何、代数拓扑和微分方程等领域出发开辟了一系列新的工具,迄今为止在图机器学习中还尚未被探索。
将 GNN 重新想象为连续的物理过程。与在图上传递多层消息不同,我们可以考虑在连续的时间维度上发生在某个域(可以是流形等连续的域,并将其转化为离散图)上的物理过程。该过程在空间和时间上的某个点的状态取代了一层 GNN 生成的图中某个节点的潜在特征。该过程由一组参数(表示底层物理系统的属性)控制,这些参数取代了消息传递层的可学习权值。
我们可以根据经典系统和量子系统构造出大量不同的物理过程。研究者们在一系列论文中证明,许多现有的 GNN 可能与扩散过程有关,这可能最自然的传播信息方式。也可能存在一些更奇特的方式(如耦合振荡系统),它们可能具备某些优势。
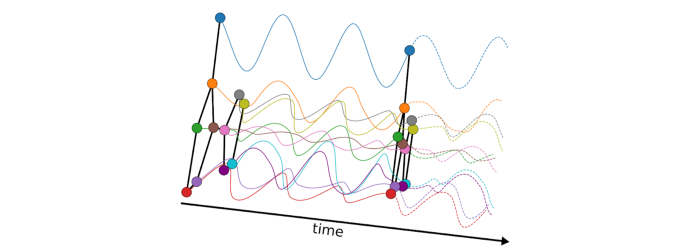
图注:图耦合振荡系统的动力学。
连续系统在时间和空间上可以是离散的。空间离散化指的是:以图的形式在连续域上连接附近的点,它可以随时间和空间变化。这种学习范式与传统的 WL 测试截然不同,后者严格地受底层输入图假设的约束。更重要的是,空间离散化思想启发了一系列新的工具的诞生。至少从原则上说,它让我们可以解决一些重要的问题,这些问题是现有的图论技术所无法解决的。
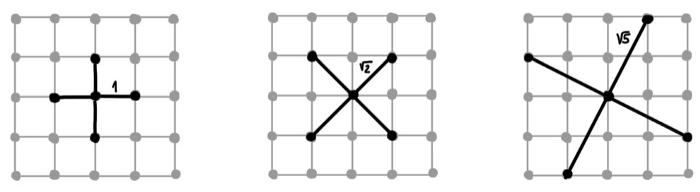
图注:2D 拉普拉斯算子的不同离散化结果。
学习是一个最优控制问题。在给定的时间内,过程的所有可能状态的空间可以被看作是一个可以表示的函数的「假设类」。这种学习方式可以看作一个最优控制问题,即是否可以控制过程(通过在参数空间中选择一条轨迹)使其达到某种理想状态。我们可以将表示能力定义为:是否可以通过在参数空间中选择适当的轨迹来控制过程,从而实现某种给定的功能(可达性);效率与达到某一状态所需的时间有关;而泛化性则与该过程的稳定性有关。
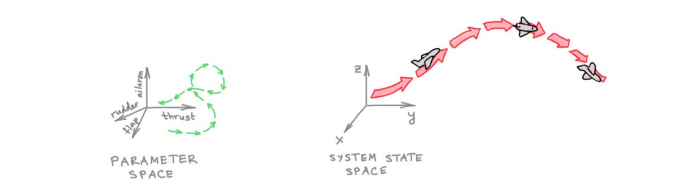
图注:将学习作为控制问题。通过飞机来比喻物理系统,其 xyz 坐标(系统状态)是通过操纵推理、副翼、和方向舵(参数空间)来控制的。
可以由离散微分方程推导出 GNN。物理系统的行为通常可由微分方程控制,其解产生系统的状态。在某些情况下,这样的解可以是闭式解。但在更普遍的情况下,必须依靠基于适当离散化的数值解。经过一个多世纪的研究,数值分析领域出现了各种各样的迭代求解器,为图上的深度学习提供了可能的全新架构。
GNN 中的注意力机制可以解释为具有可学习扩散系数的离散扩散偏微分方程,使用显式数值方法求解。此时,求解器的每一步迭代对应于 GNN 的一个层。目前还没有 GNN 架构能够直接类比于更复杂的求解器(例如,使用自适应步长或多步方案),该方向的研究可能催生出新的架构。另一方面,隐式的方案则需要在每次迭代时求解一个线性系统,可以将其解释为「多跳」滤波器。此外,数值方法具有稳定性和收敛性的保证,为它们能够工作提供了条件,也为失效情况提供了解释。
数值求解器应该对硬件友好。迭代求解器比数字计算机更古老,从数字计算机诞生之日起,它就必须知道自己拥有底层硬件,并有效地利用它们。科学计算中的大规模问题通常必须在计算机集群上解决,而这些问题是至关重要的。
在图上进行「持续」深度学习的方式,使我们以与模拟它们的硬件兼容的方式对底层微分方程进行离散化。这里可能用到超级计算研究社区的大量成果(如域分解技术)。具体而言,图重连和自适应迭代求解器考虑了内存的层次结构,例如:在不同物理位置的节点上执行很少的信息传递步骤,而在相同物理内存中的节点上执行更频繁的步骤。
将演化方程解释为与物理系统相关的能量函数的梯度流,有助于理解学习模型。许多物理系统都有一个相关的能量泛函(有时也包含某些对称或守恒定律),其中控制系统动力学的微分方程是一个最小化的梯度流。例如,扩散方程使狄利克雷能量最小化,而它的非欧版本(Beltrami 流)使 Polyakov 泛函最小化,从而直观地理解了学习模型。利用最小作用原理,某些能量泛函可以导出双曲方程(如波动方程)。这些方程的解是波动的(振荡的),与典型的 GNN 动力学有很大的不同。
分析这种流的极限情况提供了对模型表现的深刻理解,而这是很难通过其它方法获得的。例如,在论文“Neural Sheaf Diffusion: A Topological Perspective on Heterophily and Oversmoothing in GNNs”中,Michael 等人证明了传统的 GNN 必然会导致过平滑,并且只有在同质性假设下才具有分离的能力;在使用图上的额外结构可以获得更好的分离能力。在论文“Graph-Coupled Oscillator Networks”中,Michael 等人证明了振动系统在极限下可避免过平滑。这些结果可以解释为什么在某些 GNN 架构中会产生某些不良现象,以及如何设计架构来避免它们。此外,将流的极限情况与分离联系起来,揭示了模型表达能力的界限。
可以在图中使用更丰富的结构。如前文所述,有时图的几何性质可能「不足」(无法捕获更复杂的现象,如非成对关系),也可能「过剩」(即难以在同质空间中表示)。我们可以通过使用额外的结构使图更丰富,从而处理图几何性质不足的问题。例如,分子包含环,化学家认为环是单一的实体,而不是原子和键(节点和边)的集合。
Michael 等人的研究指出,图可以被「提升」为「简单元胞复合体」(simplicial- and cellular complexes)的高维拓扑结构。我们可以设计一个更复杂的消息传递机制,使信息不仅可以像在 GNN 中那样在节点之间传播,还可以在环这样的结构之间传播。恰当地构造这类「提升」操作使这些模型比传统的 WL 测试具有更强的表达能力。
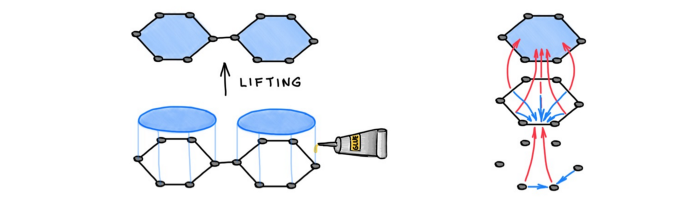
图注:将图「提升」为元胞复合体,元胞消息传递。
在论文“Neural Sheaf Diffusion: A Topological Perspective on Heterophily and Oversmoothing in GNNs”中,Michael 等人证明了,通过给节点和边分配向量空间和线性映射,可以给图配备一种额外的几何结构,即「元胞束」。传统的 GNN 隐式地假设图具有简单的底层束结构,这反映在相关扩散方程的性质和图拉普拉斯算子的结构上。与传统的 GNN 相比,使用复杂的「束」可以产生更丰富的扩散过程,有利于对其渐近行为。例如,在选择出的恰当的束结构上的扩散方程可以在极限的多个类中分离,即使在亲异环境中也是如此。
从几何的观点来看,束结构类似于连接,这是微分几何中描述流形上向量的平行传输的概念。从这个意义上说,我们可以把束的学习看作是一种取决于下游任务演化图的几何结构的方法。Michaedl 等人证明,通过限制束的结构群(例如,限制为特殊的正交群),可以使节点特征向量只旋转,这样可以获得一些有趣的发现。

图注:建立在图上的元胞束由附加在每个节点上的向量空间和连接它们的线性约束映射组成。这可以被认为是赋予图几何性质,约束映射与连接类似。
「离散曲率类比」是另一种图几何结构的例子,这是微分几何领域用来描述流形局部性质的标准方法。在论文“Understanding over-squashing and bottlenecks on graphs via curvature”中,Michael 等人证明了负图 Ricci 曲率会对图上的信息流产生瓶颈,从而导致 GNN 中的过压缩现象。离散 Ricci 曲率可以被应用于高阶结构(三角形和矩形),这在许多应用中都很重要。这种结构对于传统的图嵌入来说有些「过剩」,因为图是异构的(非常曲率)。对于通常用于嵌入的空间,即使是非欧空间,也是同构的(常曲率)。
在论文“Heterogeneous manifolds for curvature-aware graph embedding”中,Michael 等人展示了一种具有可控 Ricci 曲率的异构嵌入空间的构造,可以选择与图的曲率匹配的 Ricci 曲率,不仅可以更好地表示邻域(距离)结构,而且可以更好地表示三角形和矩形等高阶结构。这些空间被构造成同构、对旋转对称的流形的乘积,可以使用标准黎曼梯度下降方法进行有效优化。
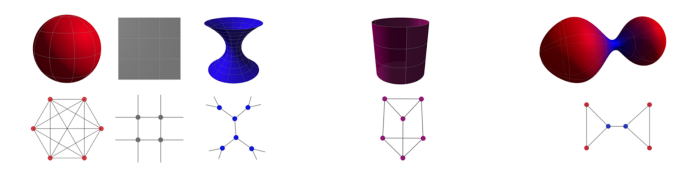
图注:(左)空间形式(球体、平面和双曲面)具有常的正的、零的和负的Ricci曲率,下方为它们与相应的离散的 Forman 曲率的图的类比(团、网格和树)。(中)积流形(圆柱可以被认为是圆和线的乘积)。(右)具有变曲率的异质流形及其图的类比。
位置编码可以看作是域的一部分。将图看作连续流形的离散化,可以将节点位置坐标和特征坐标视为同一空间的不同维度。在这种情况下,图可以用来表示由这种嵌入引出的黎曼度规的离散类比,与嵌入相关的谐波能量是狄利克雷能量的非欧扩展,在弦论中称为 Polyakov 泛函。这种能量的梯度流是一个扩散型方程,它演化了位置坐标和特征坐标。在节点的位置上构建图是一种针对特定任务的图重连的形式,它也会在扩散的迭代层中发生变化。
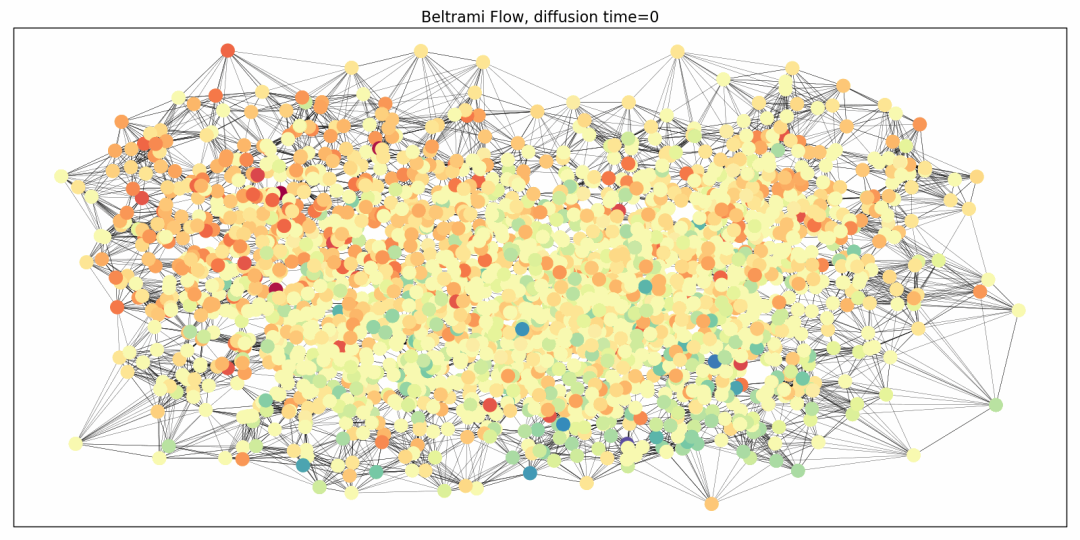
图注:通过带有重连的 Beltrami 流对 Cora 图的位置和特征分量进行演化的结果。
域的演化可替代图重连。作为一个预处理步骤,扩散方程也可以应用于图的连通性,旨在改善信息流和避免过压缩。Klicpera 等人提出了一种基于个性化 Page Rank 的算法,这是一种图扩散嵌入。在论文“Understanding over-squashing and bottlenecks on graphs via curvature”中,我们分析了这个过程,指出了它在异构设定下的缺陷,并提出了一个受 Ricci 流启发的过程的图重接的替代方案。这样的重连减少了负曲率造成的图瓶颈的影响。Ricci 流是流形的几何演化方程,非常类似于用于黎曼度规的扩散方程,是微分几何中类流行且强大的技术(包括著名的 Poincaré 猜想的证明)。更广义地说,与其将图重连作为预处理步骤,还不如考虑一个演化过程的耦合系统:一个演化特征,另一个演领域。
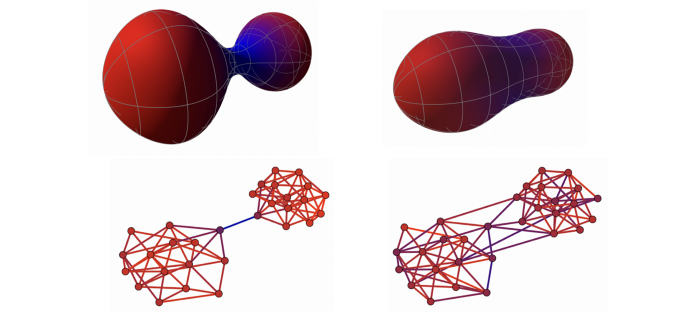
图注:(上)具有负曲率的瓶颈的哑铃形黎曼流形,经过基于曲率的度规演化,变得更圆,瓶颈更不明显。(下)一个类似的基于曲率的图重连过程,减少了瓶颈,使图对消息传递更友好。
新的理论框架能让我们走多远,是否能够解决该领域目前尚未解决的问题,仍然是一个悬而未决的问题。
这些方法真的会在实践中被使用吗?对于实践者来说,一个关键的问题是,这些方法是否会催生新的更好的架构,或者仍然是一个脱离实际应用的理论工具。Michael Brostein 相信,这个领域的研究将是实用的,通过拓扑和几何工具获得的理论成果将使我们对现有 GNN 架构做出更好的选择。例如,如何约束消息传递函数,以及何时使用这些特定的选择。
我们是否已经超越了消息传递的范畴?从广义上讲,数字计算机上的任何计算都是一种消息传递形式。然而,在严格意义上的 GNN 中,消息传递是一个计算概念,它通过将信息从一个节点发送到另一个节点来实现,这是一个内在的离散过程。另一方面,所描述的物理模型以连续的方式在节点之间共享信息(例如,在一个图耦合振荡系统中,一个节点的动力学依赖于它的邻居在每个时间点上的动力学)。在对描述该系统的微分方程进行离散化和数值求解时,所对应的迭代确实是通过消息传递实现的。
然而,人们可以假设使用这些物理系统的实际实现或其他计算范式(例如,模拟电子学或光子学)。在数学上,底层的微分方程的解有时可能以封闭形式给出:例如,各向同性扩散方程的解是一个高斯核卷积。在这种情况下,邻居的影响被吸收到核的结构中,没有发生实际的消息传递。
图注:基于反向传播的深度学习在真实物理系统中的应用。