刘群:预训练语言模型研究进展和趋势展望


1
自然语言处理的预训练方法的背景
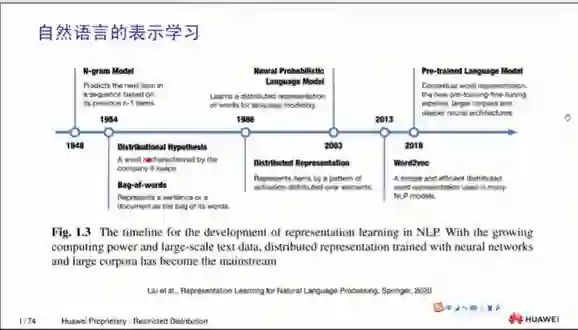


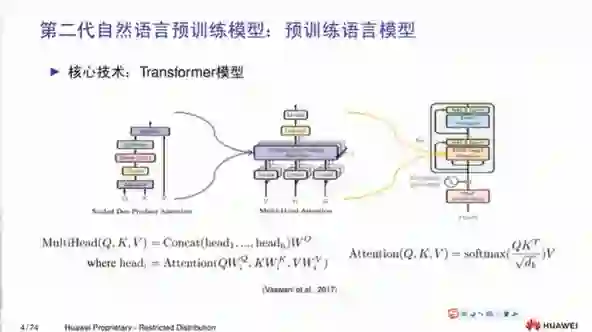

2
预训练语言模型的近期进展
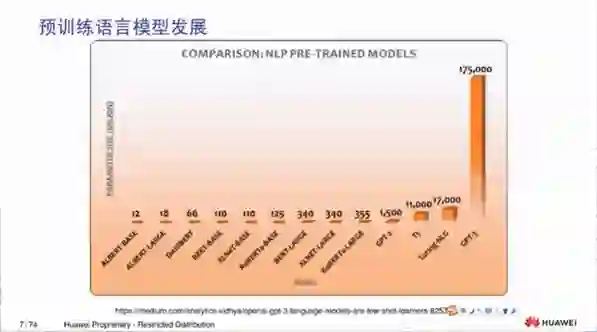





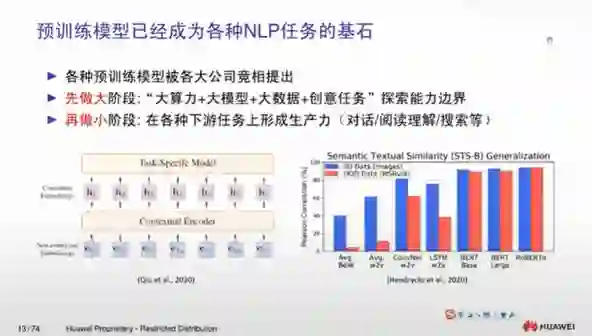



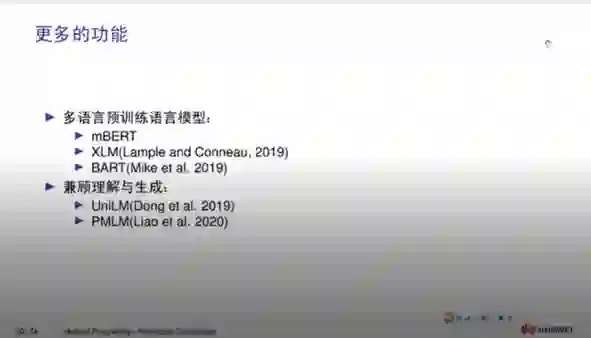
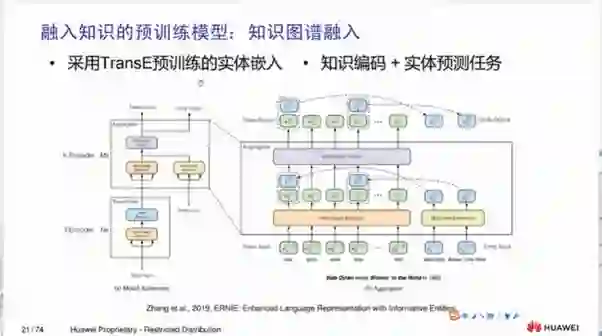

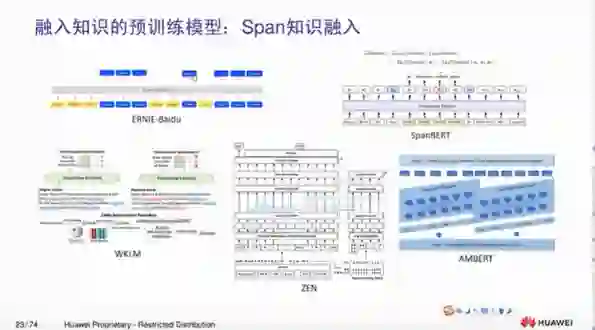
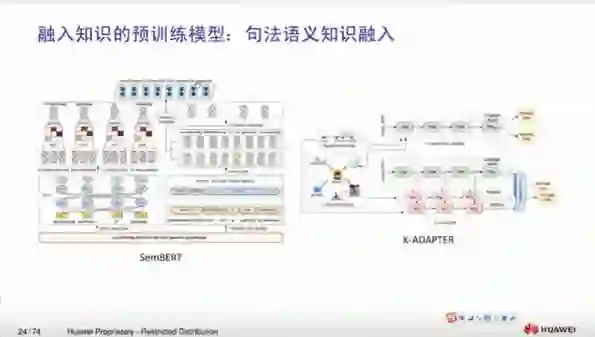




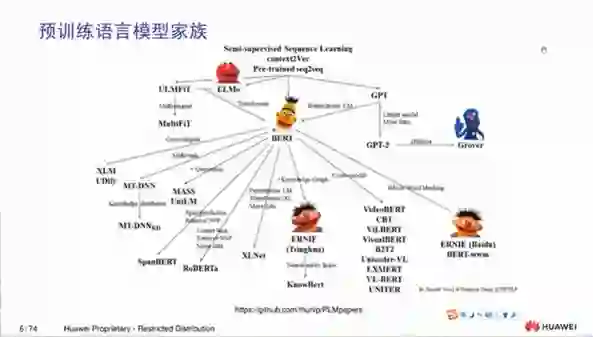
3
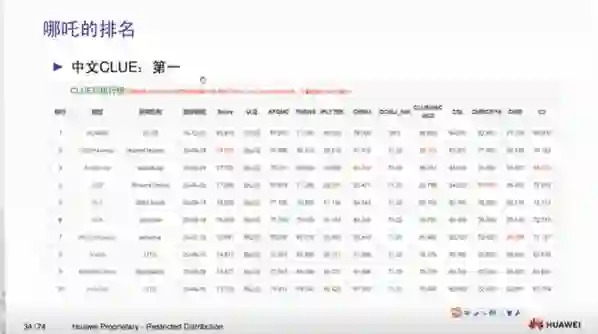
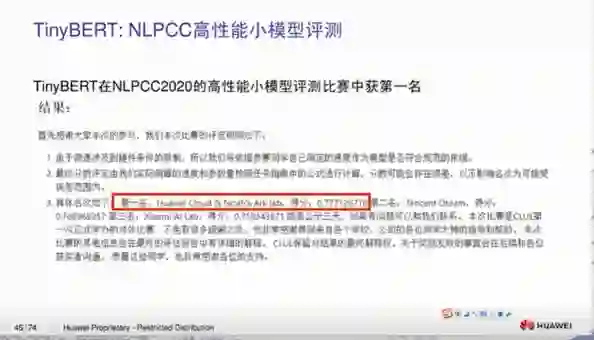
我们的工作


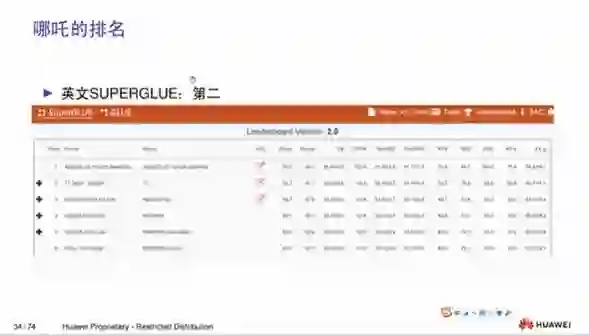 另外在英文的排行榜SUPERGLUE,我们现在已经排到第二名,第一名的是目前在规模上大哪吒十倍的T5模型。
另外在英文的排行榜SUPERGLUE,我们现在已经排到第二名,第一名的是目前在规模上大哪吒十倍的T5模型。






4
总结与展望



点击阅读原文,直达EMNLP小组!
登录查看更多
相关内容





相关VIP内容
相关资讯
相关论文