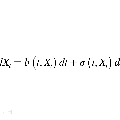7 Papers & Radios | 几分钟说话视频实现虚拟数字人复刻;ICLR 2021八篇杰出论文
参与:杜伟、楚航、罗若天
本周的重要论文包括斯坦福大学和谷歌大脑的研究者提出了基于随机微分方程(SDE)的分数生成式建模、DeepMind 的研究者提出的使用图神经网络来学习网格模拟的模型 MeshGraphNets等。
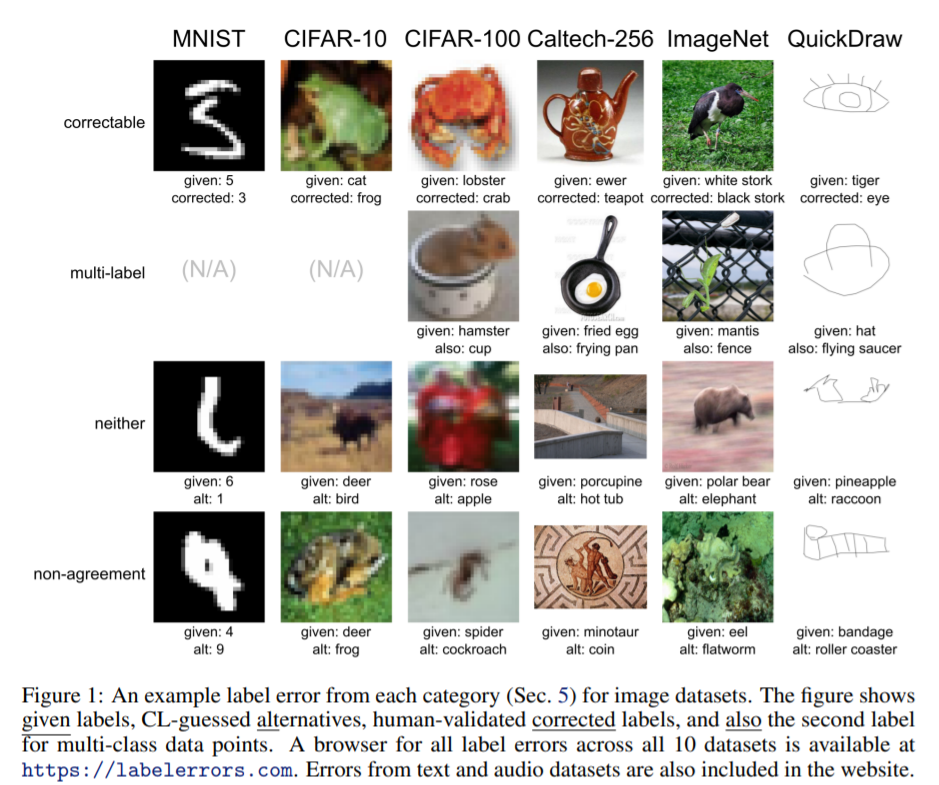
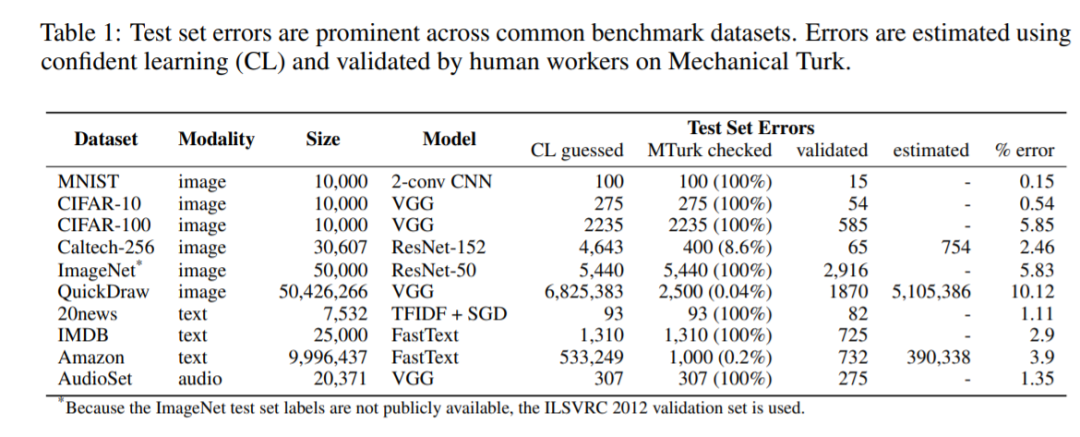
Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks
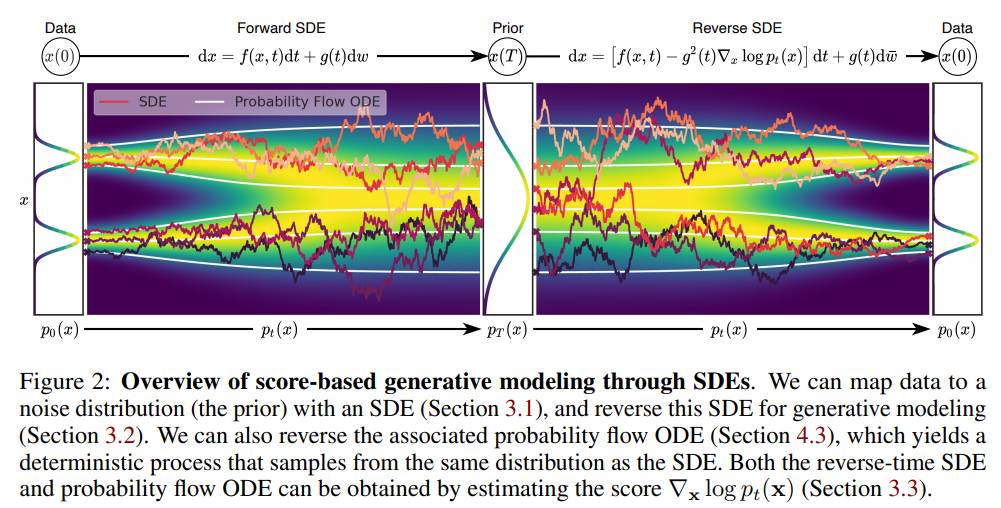
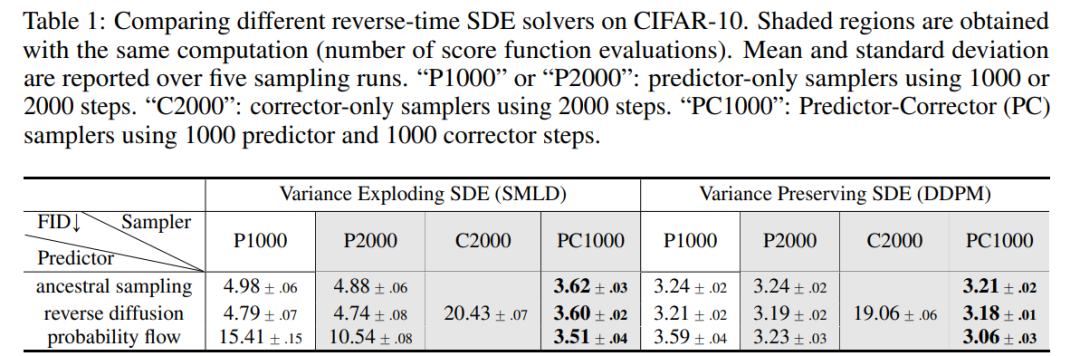
Score-Based Generative Modeling through Stochastic Differential Equations
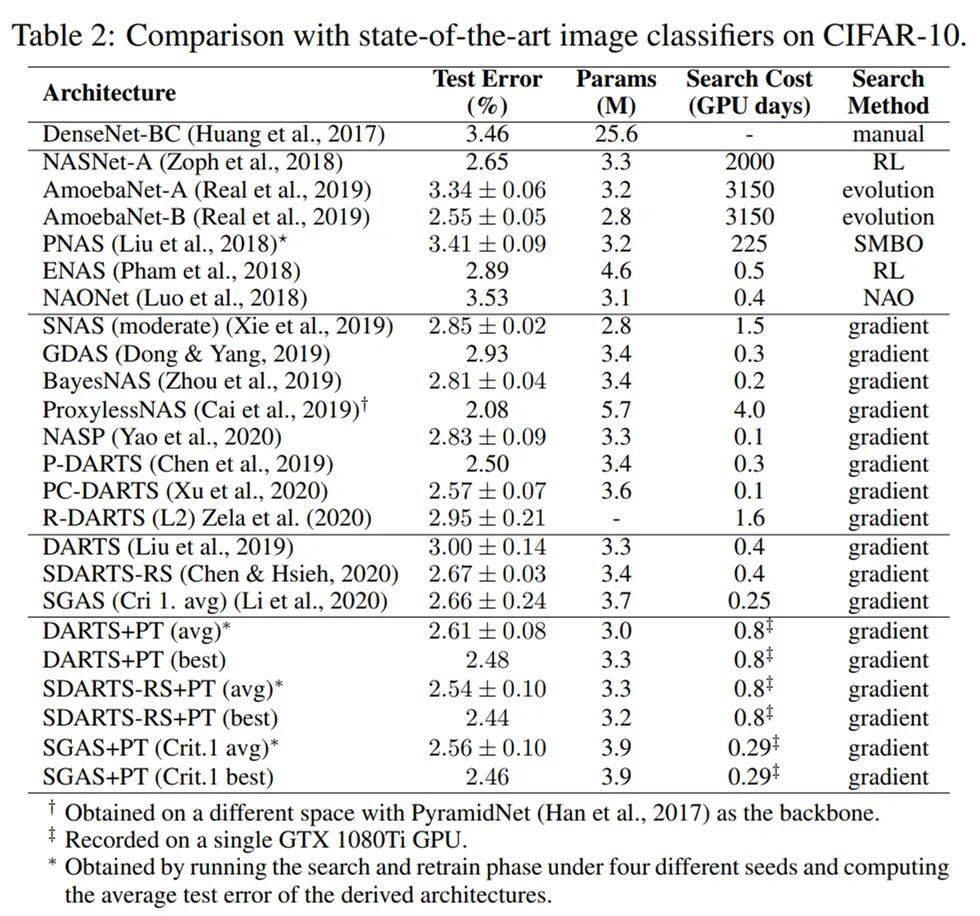
Rethinking Architecture Selection in Differentiable NAS
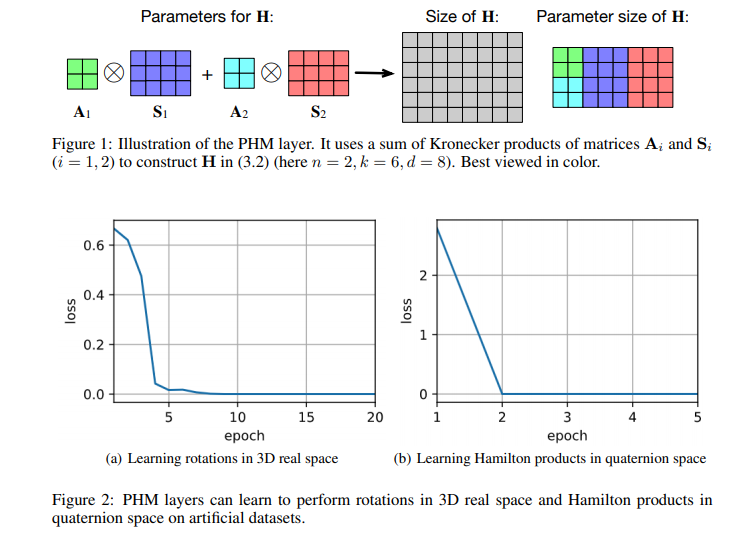
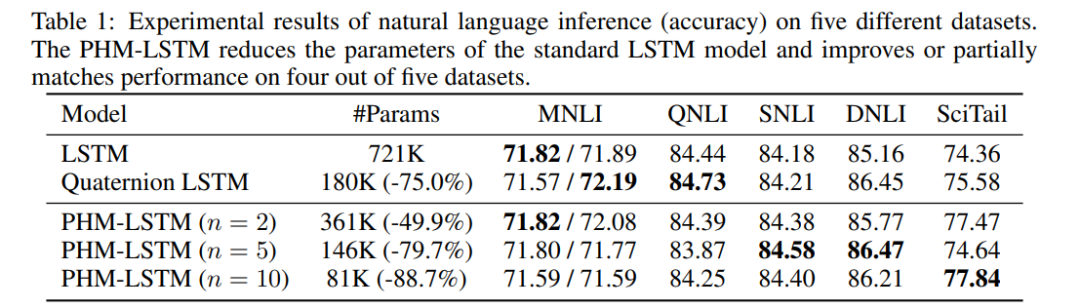
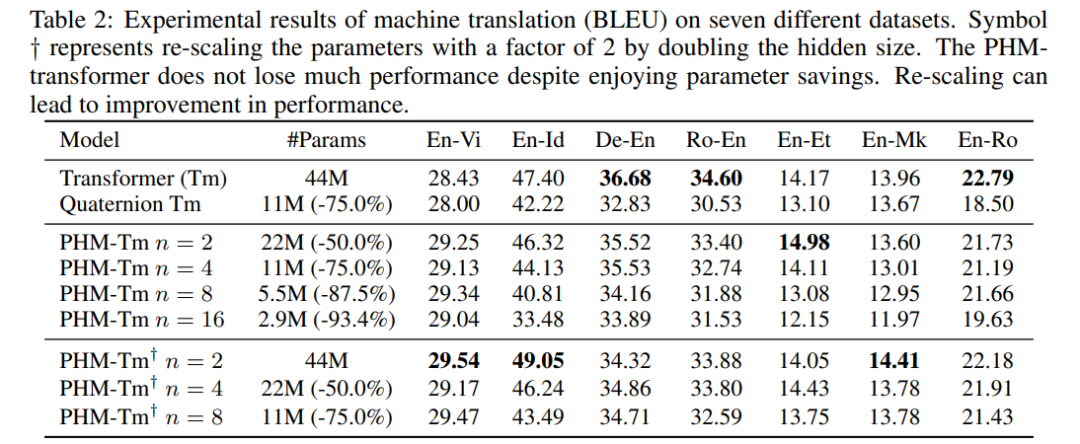
Beyond Fully-Connected Layers with Quaternions: Parameterization of Hypercomplex Multiplications with 1/n Parameters
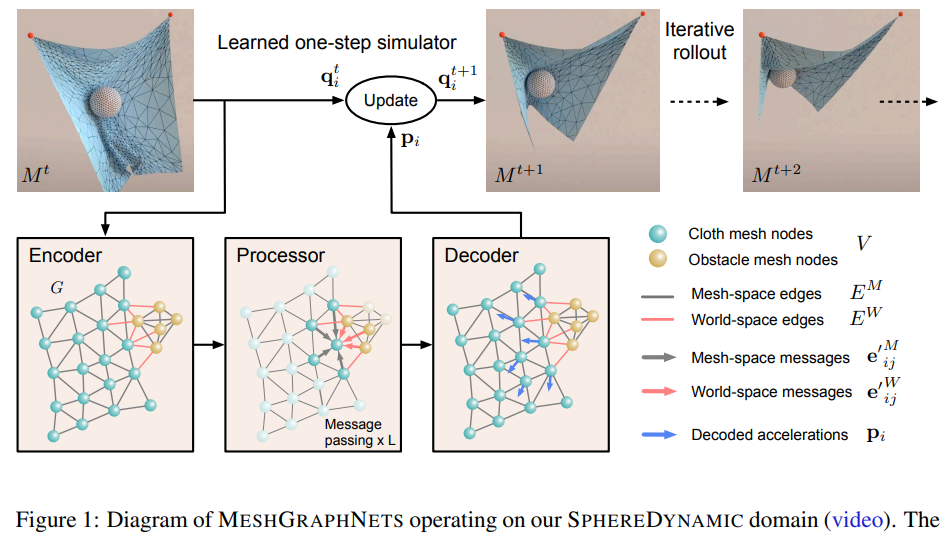
Learning Mesh-Based Simulation with Graph NetworksLearning Mesh-Based Simulation with Graph Networks
Optimal Rates for Averaged Stochastic Gradient Descent under Neural Tangent Kernel Regime
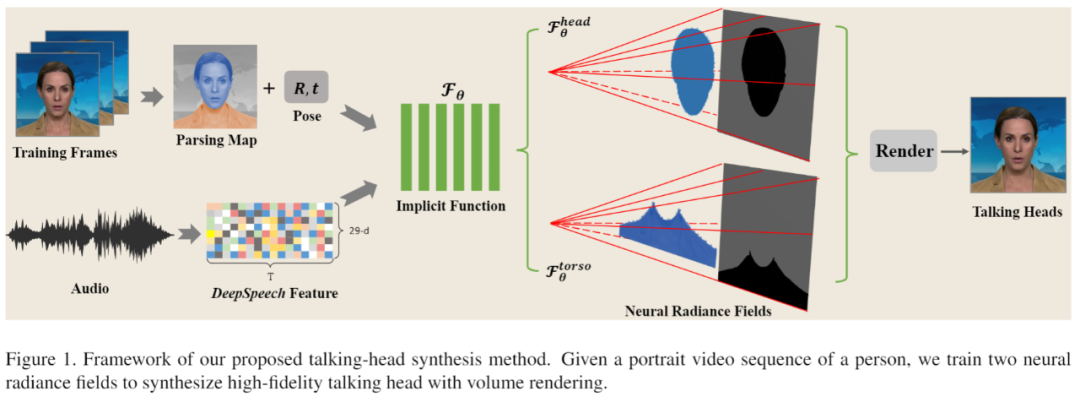
AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
作者:Curtis G. Northcutt、Anish Athalye、Jonas Mueller
论文链接:https://arxiv.org/pdf/2103.14749.pdf

作者:Yang Song、Jascha Sohl-Dickstein、Diederik P. Kingma 等
论文链接:https://openreview.net/pdf?id=PxTIG12RRHS

作者:Ruochen Wang、 Minhao Cheng、 Xiangning Chen 等
论文链接:https://openreview.net/pdf?id=PKubaeJkw3
作者:Aston Zhang、Yi Tay、Shuai Zhang 等
论文链接:https://openreview.net/pdf?id=rcQdycl0zyk
作者:Tobias Pfaff、Meire Fortunato、Alvaro Sanchez-Gonzalez 等
论文链接:https://openreview.net/pdf?id=roNqYL0_XP
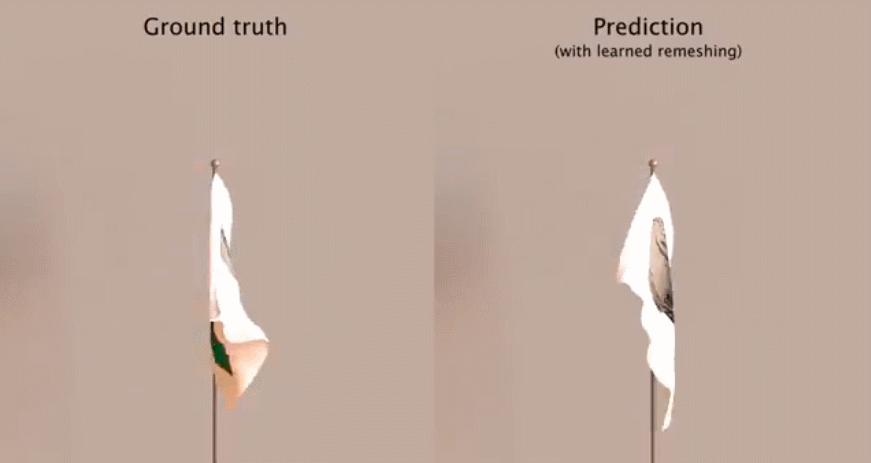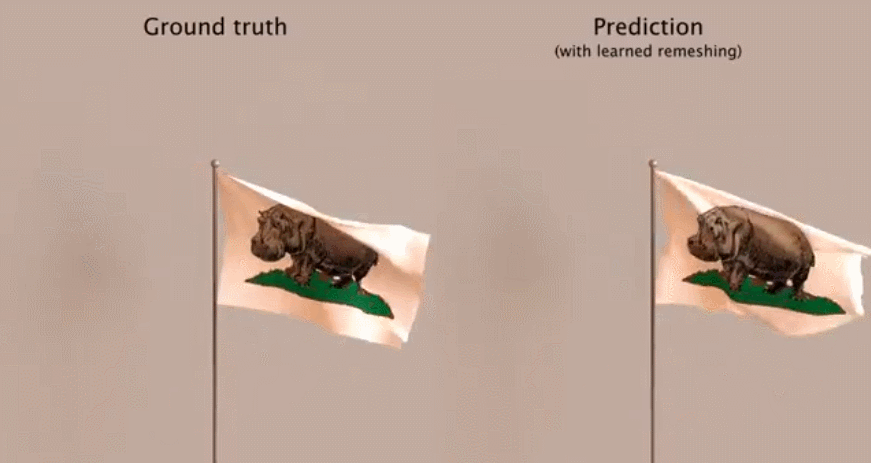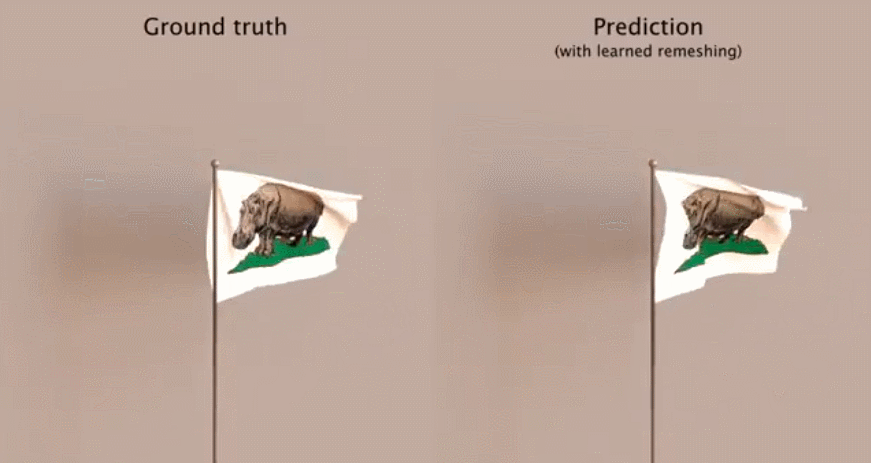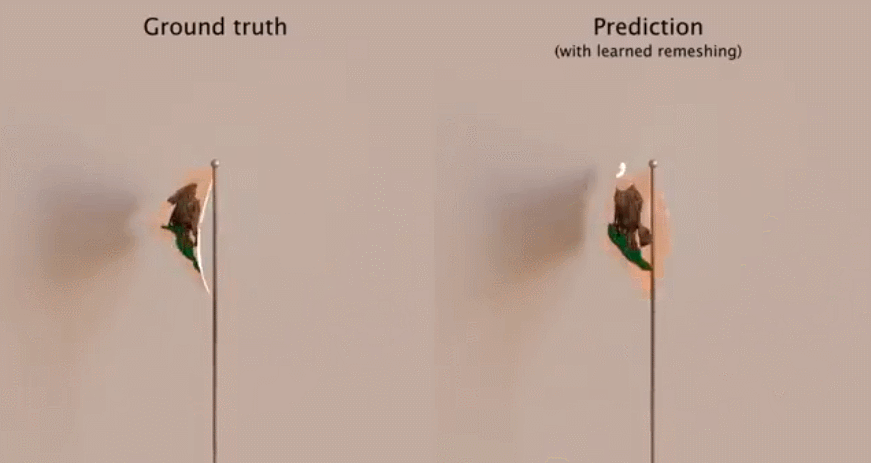

作者:Atsushi Nitanda、 Taiji Suzuki
论文链接:https://openreview.net/pdf?id=PULSD5qI2N1


作者:Yudong Guo、Keyu Chen、Sen Liang 等
论文链接:https://arxiv.org/pdf/2103.11078.pdf


本周 10 篇 ML 精选论文是: