开源sk-dist,超参数调优仅需3.4秒,sk-learn训练速度提升100倍

【导语】这篇文章为大家介绍了一个开源项目——sk-dist。在一台没有并行化的单机上进行超参数调优,需要 7.2 分钟,而在一百多个核心的 Spark 群集上用它进行超参数调优,只需要 3.4 秒,把训练 sk-learn 的速度提升了 100 倍。
sk-dist 简介

使用 sk-dist 的例子
import timefrom sklearn import datasets, svmfrom skdist.distribute.search import DistGridSearchCVfrom pyspark.sql import SparkSession# instantiate spark sessionspark = ( SparkSession .builder .getOrCreate() )sc = spark.sparkContext# the digits datasetdigits = datasets.load_digits()X = digits["data"]y = digits["target"]# create a classifier: a support vector classifierclassifier = svm.SVC()param_grid = { "C": [0.01, 0.01, 0.1, 1.0, 10.0, 20.0, 50.0], "gamma": ["scale", "auto", 0.001, 0.01, 0.1], "kernel": ["rbf", "poly", "sigmoid"] }scoring = "f1_weighted"cv = 10# hyperparameter optimizationstart = time.time()model = DistGridSearchCV( classifier, param_grid, sc=sc, cv=cv, scoring=scoring, verbose=True )model.fit(X,y)print("Train time: {0}".format(time.time() - start))print("Best score: {0}".format(model.best_score_))------------------------------Spark context found; running with sparkFitting 10 folds for each of 105 candidates, totalling 1050 fitsTrain time: 3.380601406097412Best score: 0.981450024203508
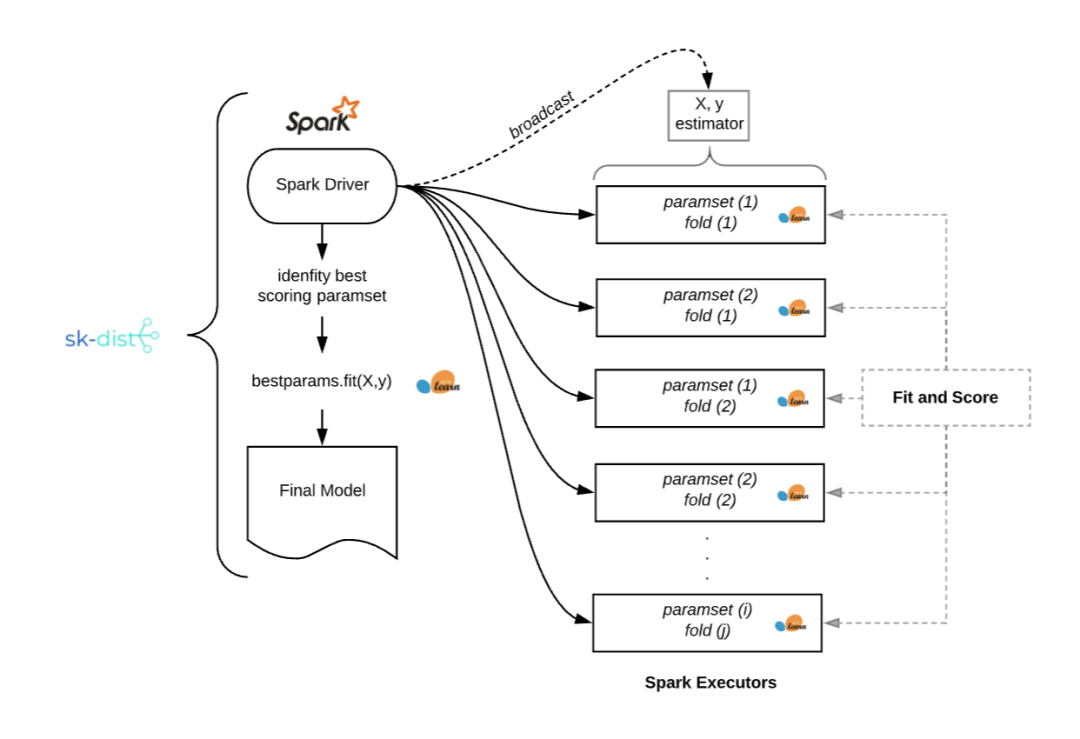
目前的解决方案
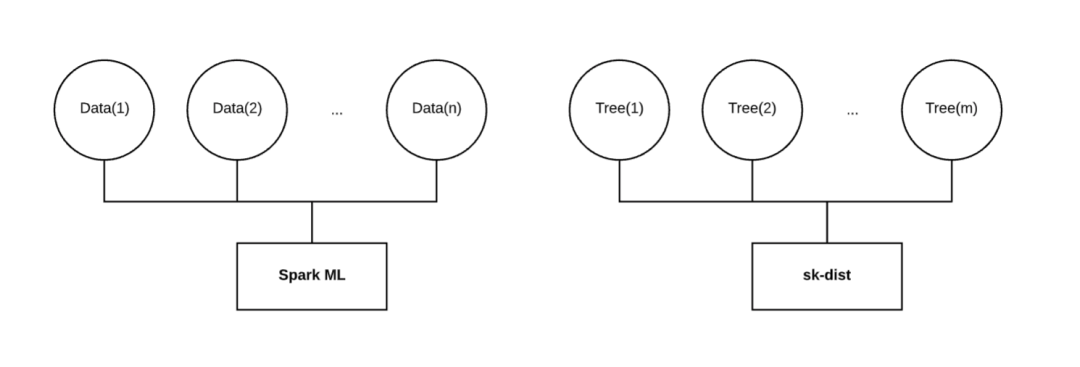
sk-dist 的特点
-
分布式训练:使用 Spark 分发元估计器训练。支持以下算法:使用网格搜索和随机搜索的超参数调优,使用随机森林的树集成,其他树和随机树嵌入,以及一对多、一对一的多类别问题策略。 -
分布式预测:使用 Spark DataFrames 分配拟合后的 scikit-learn 估计器进行预测。通过便携式的 scikit-learn 估计器,该方法使得大尺度的分布式预测成为可能。这些估计器可以与 Spark 一起使用,也可以不与 Spark 一起使用。 -
特征编码:使用 Encoderizer 对特征进行灵活编码。 Encoderizer 可以使用或不使用Spark 并行化。它将推断数据类型和形状,自动选择并应用最佳的默认特征变换器,对数据进行编码。作为一个完全可定制的特征联合编码器,它还具有使用 Spark 进行分布式变换的附加优势。
sk-dist 的适用情形
-
传统的机器学习: 广义线性模型,随机梯度下降,最近邻,决策树和朴素贝叶斯等方法与 sk-dist 配合良好。这些模型都已在 scikit-learn 中集成,用户可以使用 sk-dist 元估计器直接实现。 -
中小型数据:大数据无法与 sk-dist 一起使用。值得注意的是,训练分布的维度是沿着模型的轴,而不是数据。数据不仅需要适合每个执行器的内存,还要小到可以广播。根据 Spark 的配置,最大广播量可能会受到限制。 -
Spark 的使用:sk-dist 的核心功能需要运行Spark。对于个人或小型数据科学团队而言,从经济上来讲可能并不可行。此外,为了以经济有效的方式充分利用 sk-dist,需要对 Spark 进行一些调整和配置,这要求使用者具备一些 Spark 的基础知识。
(*本文为AI科技大本营原创文章,转载请联系微信 1092722531)
推荐阅读
六大主题报告,四大技术专题,AI开发者大会首日精华内容全回顾
AI ProCon圆满落幕,五大技术专场精彩瞬间不容错过
CSDN“2019 优秀AI、IoT应用案例TOP 30+”正式发布
如何打造高质量的机器学习数据集?
从模型到应用,一文读懂因子分解机
用Python爬取淘宝2000款套套
7段代码带你玩转Python条件语句
高级软件工程师教会小白的那些事!
谁说 C++ 的强制类型转换很难懂?

登录查看更多
相关内容
专知会员服务
34+阅读 · 2020年2月27日




相关VIP内容
专知会员服务
34+阅读 · 2020年2月27日
相关资讯
相关论文