高效使用众包平台帮助解决实体对齐问题
论文信息:

链接:http://dbgroup.cs.tsinghua.edu.cn/ligl/crowdalign.pdf
CIKM 2017 best full paper
作者:Yan Zhuang, Guoliang Li, Zhuojian Zhong, Yudian Zheng, Jianhua Feng
简介
本文针对知识图谱的融合问题的关键问题:实体对齐,提出了一种混合了众包和机器学习的对齐方法,该方法适用于大规模复杂的知识图谱融合,本文还提出了策略来帮助减少众包的费用相关工作
SiGMa: Simple Greedy Matching
基于贪心的算法得到一个对全局匹配的估价函数的最大值。
估价函数考虑匹配的实体对的匹配度:对于两个知识库中的两个实体对,考虑其在知识图谱中的相似度(有匹配的邻居,随全部匹配的变化而变化),属性上的相似度(有相似的属性值,静态的)计算一个匹配度。 求解时每次贪心地选取一堆实体度匹配使得估价函数增长最大。 需要人工标注两个数据库的那些关系(属性)是一样的。
VMI: Large Scale Instance Matching via Multiple Indexes andCandidate Selection
同样是基于实体名字生成候选匹配对,利用名字,关系,属性,描述和邻居的名字和描述来计算相似度。
利用倒排索引加速
需要人工标注两个数据库的那些关系(属性)是一样的。
Cost-Effective Crowdsourced Entity Resolution:A Partial-Order Approach
基于众包的方法解决实体消岐问题。首先自动计算所有候选实体对的分数,然后基于一个询问的策略(某个候选实体对是否真的匹配)来推断出其它未询问的实体对的正确性。
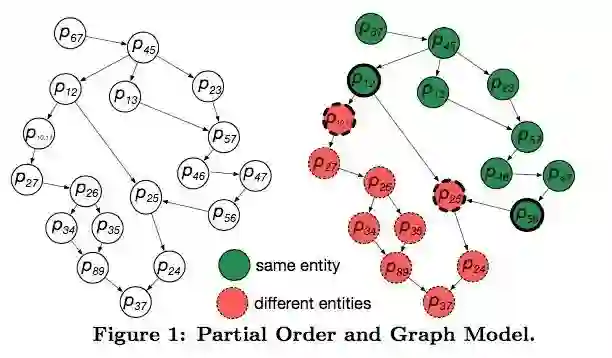
首先建立偏序关系。设Pi,j表示候选实体对(i,j)。如果实体对(i,j)在任一一个属性上的相似度都大于等于(i’,j’),那么就认为Pij >= Pi’j’。那么如果标注(i,j)不匹配,就有(i’,j')不匹配。如果(i’,j’)匹配,那么(i,j)就是匹配的。
为了加速运算,对相似的节点合并到一起。对于一个从小到大的有序序列P,通过二分的方法可以在log(p)的众包次数内得到所有实体对的答案。论文利用二分图匹配的方法找到最少的有序序列数量包含所有未决定的实体对,然后众包询问其中最长的一条序列,然后不断二分匹配+众包查询直到所以节点都被询问了或者推断了。
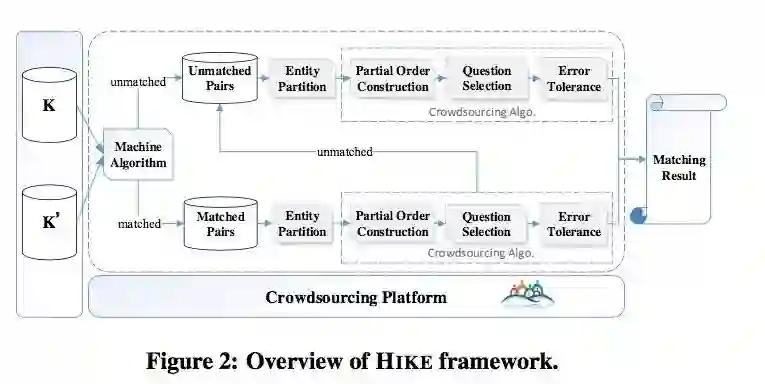
HIKE框架
基于实体谓词的实体块划分, 将类型相关的实体划分到一个集合中,然后只在集合中寻找对齐实体对可以有效地减少实体对齐的复杂度。HIKE基于实体所拥有的谓词来对实体进行划分。
拥有相同谓词的实体类型是相同的(如关系BirthDate对应人)。
共现较多的谓词可能描述的实体类型是相关的(如BirthPlace和BirthDate都描述人)。
HIKE的实体划分阶段基于一些已经匹配的实体对,生成两个数据库中匹配的谓词对,同时合并那些谓词主语共现重合度较大的谓词对,最后生成一系列的谓词集合。然后一个谓词的集合(包含多个谓词对),其谓词的主语就对应了一个实体的划分。实体对的偏序:类似之前的Partial-Order方法,不同点在于在考虑相似度的时候只用考虑当前集合的那些谓词对即可。
众包问题选择: 若使用之前类似的方法,在实际操作时会相当麻烦(后续的问题选择依赖与之前的询问的问题的答案)。
所以本文提出了两种贪心的方法进行选择,一是每次选择期望推断值的进行询问,即每次只问一个问题。二是贪心地选择若干个问题一起进行询问,贪心的方法就是每次选择一个能使当前问题集的期望推断值提升最大的问题加入到问题中。实验证明两种方法的效果相差不大
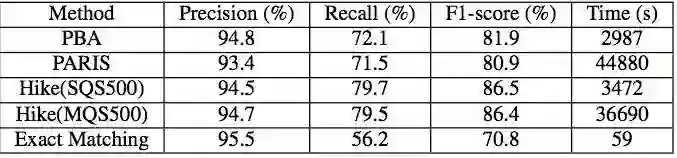
实验结果
论文在DBPedia和YAGO这两个知识图谱上进行了实验。结果相较于之前的方法,准确率保证的情况下,提升了大约7%的召回率。
总结
论文通过基于谓词的实体块划分,完善了基于Partial-order的众包方法在实体对齐领域和针对复杂的大知识图谱下的应用。





