在这篇论文SVCCA: Singular Vector Canonical Correlation Analysis for Deep Learning Dynamics and Interpretability中,研究人员提出了一种简单可扩展的方法来解决这些问题。他们正在做的是两个具体的应用:一是对比两个从不同网络学习的表征,另一种是解释从DNN隐藏层中学习的表征。另外,该项目正在开源代码,将来可供大家尝试。后台回复“svcca”获取PDF版论文。
这一系统的关键是将DNN中的每个神经元解释为激活向量。如下图所示,神经元的激活向量是它在输入数据上产生的标量输出。例如,输入50张图像,DNN中的神经元将输出50个标量值,将每个值对应输入的响应程度进行编码。这50个标量值组成了神经元的激活向量。
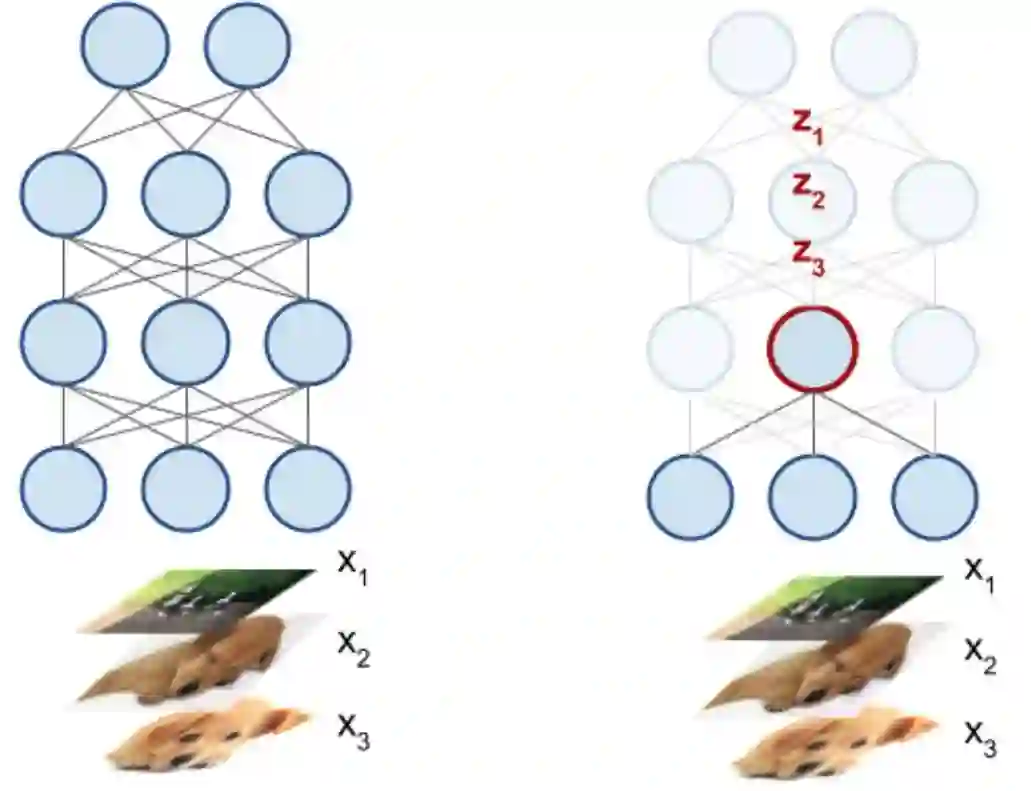
通过基本观察和其他计算,谷歌引入了Singular Vector Canonical Correlation Analysis(SVCCA),该方法采用两组神经元,同时学习后输出对齐的特征映射。重要的是,这一技术解释了细微的差异,比如神经元顺序的排列,这对于不同的神经网络至关重要。同时该技术还能检测相似性,这一点比其他更直接的工具都优秀。
这里有一个例子,加入在CIFAR-10上训练两个卷积神经网络(net1和net2),让它们完成一个中等规模的图像分类任务。为了实现结果可视化,研究人员比较了神经元的激活向量与SVCCA输出的对其特征。记住,神经元的激活向量是输入图像上的原始标量输出。下图中的x轴表示不同类别的图像(灰色虚线表示类别的边界),y轴代表神经元的输出值。
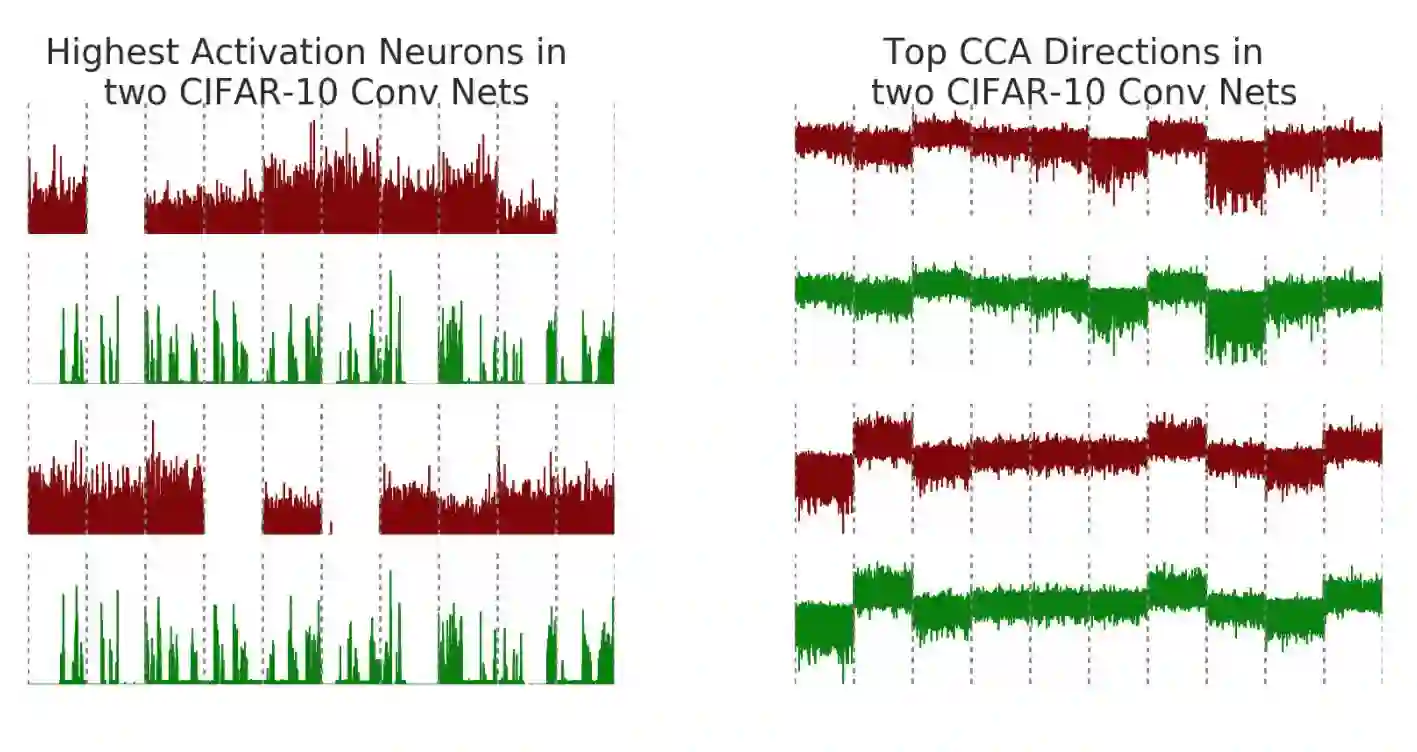
左图展示了net1(绿色)和net2(红色)中两种最高激活(最大欧式范数)神经元。检查最高激活神经元一直是计算机视觉中解释DNN的常用方法之一,但是在这种情况下,net1和net2中最高的激活神经元没有明确的对应关系,虽然二者都是在同一个任务上训练。然而,在应用了SVCCA后,即右图,两个网络学习到的潜在表征确实有一些非常相似的特征。注意最上面两行代表对齐特征的形状非常相似,下面两行也同样如此。而且右图中的对齐映射也能反应出与不同类别之间的关系。例如上面两行中第8组的输出均为负,而下面两行第2组和第7组均为正。
你可以在多个网络中应用SVCCA,也可以用于一个网络的不同时间段中。随着时间的推移,可以研究网络中的不同层次如何收敛到最终表征的。下图展示了在训练期间net1中的图层表征(y轴)与训练结束时的图层(x轴)的比较。例如,在左上图中,x轴表示net1完成训练后图层的增加数,而y轴表示还未训练时增加的深度。每个小方块(i,j)代表层i在完成训练后的表征与层j未训练时的表征的相似度是多少。左下图为输入层,在0%和100%的训练下表征相同。我们在CIFAR-10上对卷积网络(第一行)和残差网络(第二行)的0%、35%、75%和100%这四个点上进行了比较。
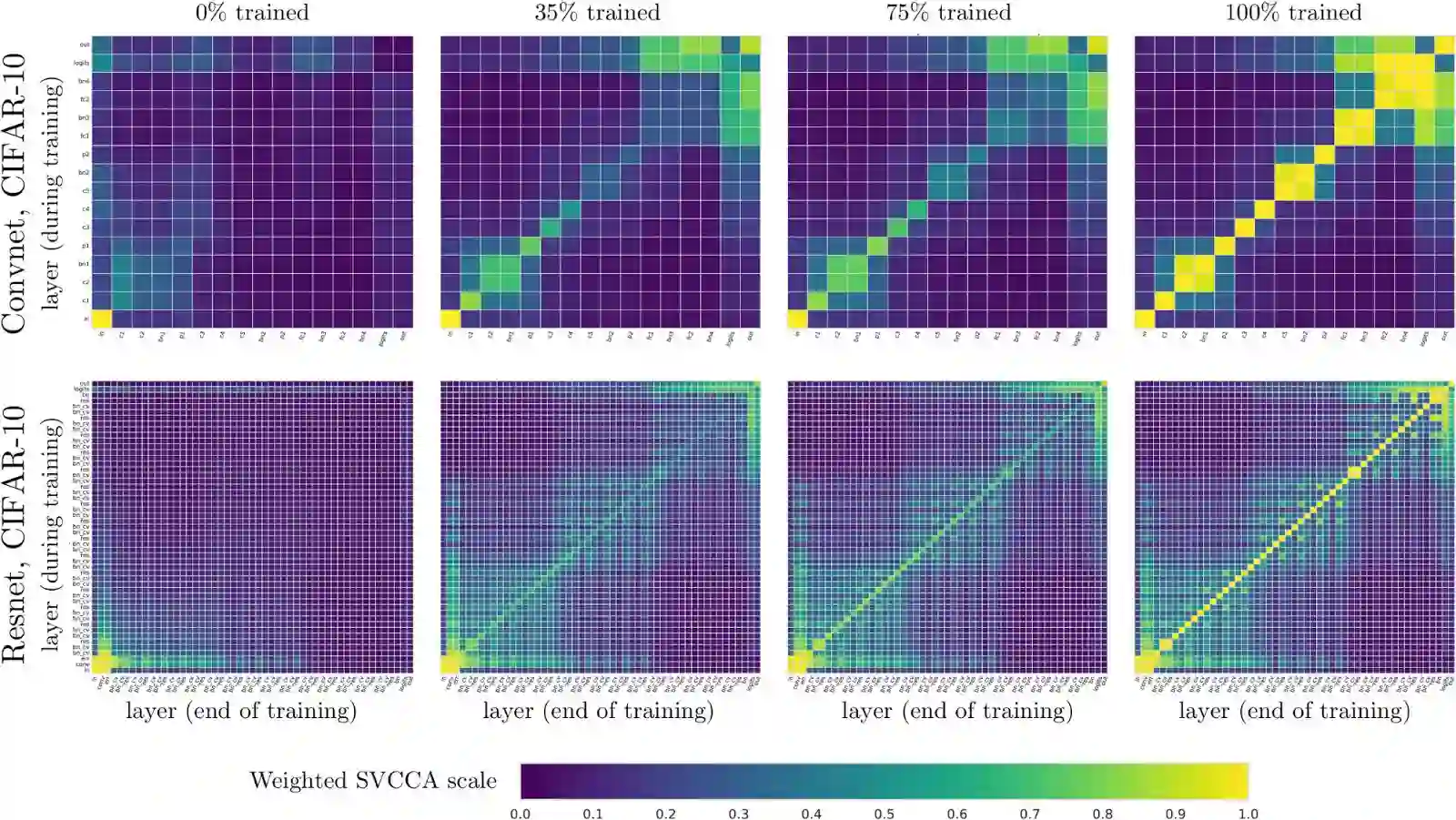
研究人员发现了自下而上收敛的证据,越靠近输入的层越先收敛,层数越高收敛时间越长。由此我们可以利用一种更快的训练方法——冻结训练(Freez Training),具体细节可阅读这篇论文。此外,这种可视化的方法还能突出网络的属性。在第一排有几个2x2的方块,对应批规范层,它们与前几层的表征是相通的。在最后一行,在训练结束时,我们可以看到类似棋盘的格子出现,这是由于网络的残差连接与以前层有更多的相似性。
到目前为止,研究人员已经将SVCCA集中应用于CIFAR-10,但如果利用离散傅里叶变换的预处理技术,这种方法可以延展到ImageNet这样尺度的模型上去。谷歌的研究人员将其应用到了ImageNet的ResNet中,比较了潜在表征与应用在不同类别的表征的相似性:
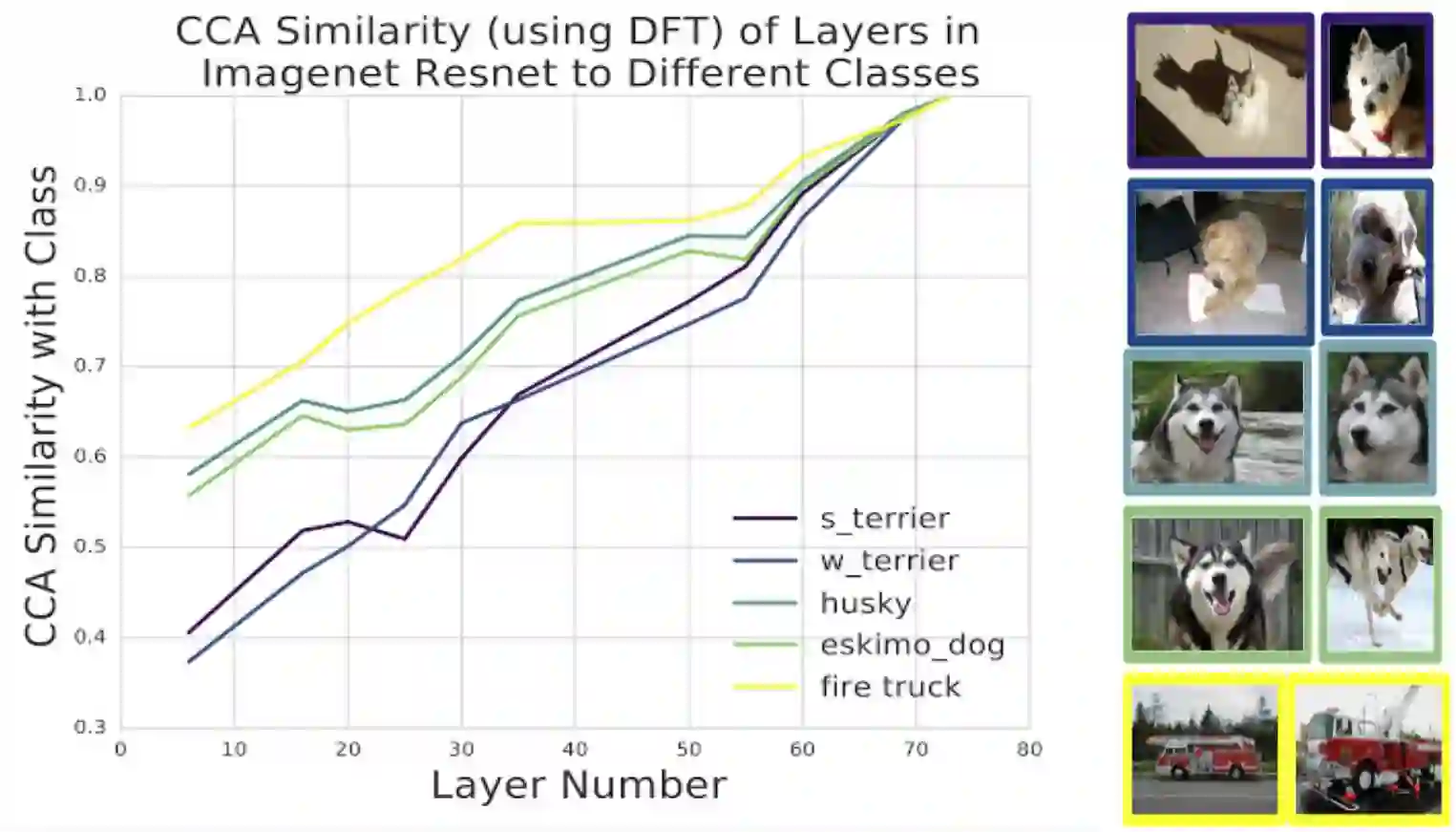
不同类别潜在表征之间的SVCCA相似性。研究人员使用了不同层数的ImageNet ResNet,0表示输入,74表示输出,比较了隐藏层和输出了捏之间的表征相似度。有趣的是,不同类别的学习速度不同:消防车那一组的学习速度要快于狗狗类的学习速度。另外,哈士奇类和梗犬类的学习速度相同,这反映了它们在视觉上相似性较高。
谷歌的论文中详细说明了目前实验的细节,同时也涉及不同应用,例如通过投影在SVCCA输出来压缩DNN、冻结训练方法(一种更节省运算量的深度神经网络训练法)。在探索SVCCA的过程中,研究人员还有几个渴望尝试的方向——将其移动到不同类型的架构、跨数据集比较、将对齐方向实现更好地可视化。这些成果将在下周的NIPS 2017上展示给大家。
原文地址:https://research.googleblog.com/2017/11/interpreting-deep-neural-networks-with.html
代码地址:https://github.com/google/svcca




