与或图网络:组成式语法的深度神经网络结构 | 焦点评论
吴田富 北卡州立大学电气和计算机工程系助理教授
2019年4月1日刊登于《视觉求索》公众号
编者序
在过去的5年中,深度学习带给计算机视觉的一个重要转变就是,用多层神经网络的模型,从大量样本中“学习到的图像特征”,来替换之前的根据各种物理成像原理、编码有效性、神经元模型等“人工设计的图像特征”,从而提升了一些识别任务的性能。虽然,端对端训练听起来完全自动化了,但神经网络的结构仍然很大程度上依赖人工设计(最近火热的网络结构自动搜索是摆脱人工设计的努力)。这其实是从一种人工设计替换了另一种人工设计,这个网络结构的空间大于图像特征的空间,而且并没有可解释的设计规律可循!目前使用十分广泛的网络结构,如 VGG、 ResNet、DenseNet、DualPathNet 等网络模型,其结构迥异,有必要探讨是否可以进行统一。
其实,在统计图模型的设计中,研究人员已经积累了基本的建模原则,
组成性(Compositionality),比如场景分解成物体,物体分解为部件,部件分解成图像基本元素(primitives、textures、textons等)。
多样性(Alternative)和可配置性(Reconfigurability),比如,各种分解的成分可以有多种选择,从而以少量的元素组合产生大量的模式结构(Configurations)。
关联性(Dependency relations),比如,部件之间的相对位置的连接和关节变化(Articulation)。
这些原则体现在传统的概率图模型比如与或图(And-or graphs),其在可解释性,鲁棒性和基于小数据学习方面有着的明显的优势。在神经网络模型之前,最流行的可变形部件模型(Deformable part-based models),就是与或图模型的一个简化的特例。但是,这些模型一直没有能够扩展到大型的数据集中,造成了一种错误的印像,好像这些模型和原理过时了。
吴田富的这篇文章就是用与或图的原理来设计神经网络的结构,提出一个与或图网络AOGNet,在当前主要的数据集如ImageNet任务中,性能超越了ResNet、DenseNet和 DualPathNets,而且具有更好的可解释性,并开始找到当前深度学习的判别式模型(CNN)与概率图模型(AOG)可能的联系,很有启发性。
值得一提的是, AOGNet这个思路早就有了,但吴田富直到CVPR 截至日期前一两个星期才得到一个足够大GPU服务器,开始在大数据集上跑这个模型,性能超过了当前的模型。这也说明一点,以前人们对神经网络的一些结论可能还为时过早。
by 朱松纯
引言
本文是在一篇CVPR19接收的论文 --- “AOGNets: Compositional grammatical architectures for deep learning”[1] 的基础上, 展开关于概率语法模型(Grammar models), 主要是与或图语法(And-or graphs, AOGs)[2] 和深度神经网络(Deep neural networks, DNNs)[3,4]深度结合的一点讨论,希望能抛砖引玉,引起大家共同探讨。文中难免有很多浅显的个人之愚见,希望读者海涵。
在计算机视觉或机器视觉(Computer Vision or Machine Vision)领域,自2012年AlexNet[5]的惊艳登场以来,基于神经网络的深度学习的这一波浪潮,带来了目不暇给的“近喜” --- 各类测试不停的刷榜和各种不同的超越人类性能,也引起无法回避的“远忧”:一方面,模型的黑盒和不易解释性,易受攻击性(Adversarial attacks),以及对大规模高质量标注数据的刚需,等等都亟需解决;另一方面,尽管很多经典模型,比如语法模型[2,6]和模式理论(Pattern Theory)[7,8],在可解释性,鲁棒性和基于小数据学习方面有着内在的优势,DNNs一枝独大的发展热度和潮流似乎使得这些经典模型逐渐“不为人所道”,形成“近在咫尺,却远在天边”的困境。
我本人自2006年一直随UCLA朱松纯教授学习概率语法模型框架和模式理论,虽久而不得其精髓,但一直深信其道,愿坚守并量力发扬之,因为直观和理论上,概率语法模型和模式理论都是经得起千锤百炼的;DNNs的这一波浪潮使我困惑和困窘了很久,在2016年8月入职北卡州立之后,经过一段时间的煎熬,我选择了研究语法模型和DNNs的深度结合,试图去破除自己内心的困惑和困窘,不忘初心,也不违背潮流,AOGNets是我们探索这个美丽后花园的途径中,翻开的一小块“鹅卵石”,希望能为语法模型与模式理论和DNNs的深度结合提供一些蛛丝马迹,敬请读者品鉴和斧正。
文章中,我首先简单介绍计算机视觉中卷积神经网络架构的现状和进行统一的可行性,进而介绍我们在语法模型的框架下提出的一个简单的统一架构 AOGNets及其实验效果。然后,我简单作一点追本溯源,回顾一下语法模型和AOGNets的由来,并对AOGNets进行小结,以及简单介绍一下AOGNets的下一步计划。最后,我想借此机会感谢很多一直以来帮助我的学生、老师和朋友。文章中,所有观点仅代表我个人愚见,提供的引用只是为可能还不熟悉相关方法的读者以备参考,并不追求完整性,同时也没有全面去总结所有相关的优秀工作,肯定有很多遗漏,望见谅。
第一节 卷积神经网络架构设计的现状和统一可行性分析
深度学习[3,4]提倡端到端的学习,避开传统手工设计特征提取的步骤,从而提高性能;但是天下没有免费的午餐,我们需要精心设计或搜索神经网络架构(Neural architectures)。神经网络架构的设计或搜索是深度学习中最核心的研究内容之一,也是影响其任务性能的决定性因素之一。一般意义上来说,我们首先要定义神经网络架构的空间,如图1所示,这个空间可以被描述为所有符合条件的有向无环图,其大小通常呈指数增长(相对于网络深度,宽度和图节点局部函数的备选个数等),并且,在这个架构空间中,深度学习的目标函数通常又是高度非线性和非凸的,我们目前还没有合适的数学框架和机器学习算法来进行透彻的分析和全局寻优。在实际应用中,我们可以化繁为简,退而求其次,分而治之,如图2所示,基于Stage和building block的策略目前被广泛使用,其中building block采取尽量简单的设计。

图1. 神经网络架构空间的示意图。
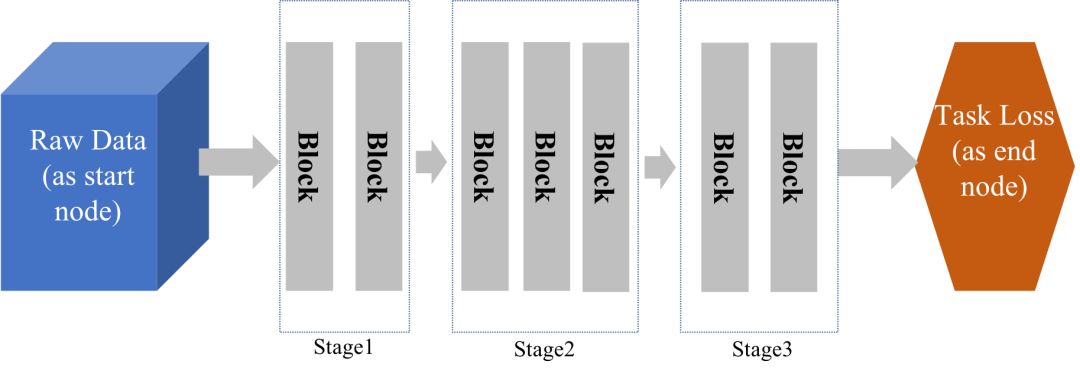
图2. 基于Stage和building block的神经网络架构设计。其中,使用多少Stages以及每个Stage使用多少个building blocks都属于模型设计超参。
考虑一个building block,其目标是如何对输入特征图进行可学习的变换,从而使得输出特征图能更好的完成当前的任务。设计方面,关键之一是如何实现高效且均衡的特征探索(Feature exploration)和特征利用(Feature exploitation/reuse)。应用方面,我们针对不同硬件平台(比如,云计算、移动计算和嵌入式等),通常面临在相互冲突的模型复杂度和运算有效性两个方面的折中选择;模型复杂度,通常包括比如,多少个building blocks以及每个block的特征维度,即深度和宽度等;模型运算有效性,通常使用客观上浮点计算量的大小或直接使用实际硬件平台的运算时间等。图3列出一些目前最流行的building blocks,包括大名鼎鼎的ResNet[9] 和DenseNet [10]。
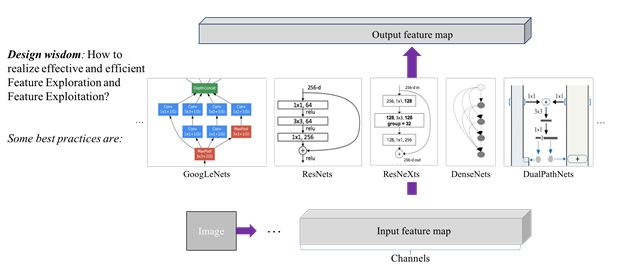
图3. 神经网络building block的设计目标和目前最流行的几种building blocks。
根据图3,我们自然会想到一些问题:能否找到一种方法去统一和融合目前最流行的building blocks?如果能,这种统一的方案是不是可以进一步提高性能(包括准确性,可解释性以及鲁棒性)?如果可以,那么这个统一方案的潜在重要性就不言而喻了。
在回答上述问题之前,我们也许会首先要问,为什么要去尝试统一?以及现有building blocks的优缺点是什么,我们怎样通过统一的架构去扬长避短?
为什么要去尝试统一?答案应该很明显:如同手工特征设计被深度学习所诟病一样,只聚焦于一种building block设计也有明显的不足,不仅其表征学习能力总是有限的,而且可能会造成“只见树木不见森林”的危险(因为通过图1我们已经很明确的知道神经网络架构空间是巨大的);同时,尝试去统一已有的设计也是一种做研究的乐趣,做到继承与发展并重;更重要的是,根据认知科学(Cognitive science)和神经科学(Neuroscience)对人类智能发展和人脑神经网络的观察与研究,研究人员已经了解到对智能非常重要的一些原则,包括:组成性(Compositionality)、可配置性(Reconfigurability)和侧连接性(Lateral connectivity);然而,在目前流行的building blocks中,这些原则还没有充分得到体现。目前流行的building blocks的优缺点大概可以概括如下:
VGGNets[11]: 在AlexNets[5]的基础上,提出尽可能使用多层小的卷积核(3x3)来代替原本使用的较大卷积核(比如7x7或11x11),既可以保持原本的感受野,又能减少参数和计算量;这种思路在后来手工设计的网络中一直保持。但是,能有效训练的VGGNets的最大深度非常有限,主要是优化方面的问题(梯度消失,Gradient vanishing)。
GoogLeNets[12]: 在Network-in-Network方法[13]的基础上,提出了Inception模块,很好的利用了[14]在理论分析上得到的一些结果,转化为所谓的Split-Transform-Aggregate(拆分-变换-聚合) ,概括性的来讲是:
- 拆分(Split)是指要对输入特征图中的不同特征(神经元)的相关性进行分析,然后聚类;
- 变换(Transform)是指对拆分所得的不同聚类进行分门别类的针对性变换;
- 聚合(Aggregate)是指变换之后的不同聚类要再次聚合在一起,迭代到下一次拆分-变换-聚合进行更深层度的学习。
GoogLeNets初始版本的一个问题是引入了过多的设计超参(hyperparameters),不同层Inception模块的参数需要仔细设计;之后,Inception模块,特别是结合ResNets的方法后,不断改进,简化了设计,也进一步提高了性能;但是各种版本的Inception模块都采用一层的拆分-变换-聚合结构,没有更灵活的利用拆分-变换-聚合。
ResNets[9]: 在HighwayNets[15]的启发下,通过引入Skip-connections,非常漂亮的解决了更深网络的训练问题(如VGGNets加深之后出现的梯度消失),结合BatchNorm[16]的特征归一化方法,首次能在大规模数据集,如ImageNet[17]上训练深度大于100的网络,同时非常显著的提高了模型的性能,获得了CVPR16 Best Paper Award。在模型表达能力方面,至于为什么简单的Skip connections能提高网络的性能,有很多的分析,但似乎还没有统一的定论。ResNets非常巧妙的解决了特征利用(Feature exploitation)的设计,但是缺少更有效的特征探索(Feature exploration),因为Skip connections总是将前一层的特征“加”到变化之后的特征,没有去探索将它们“串接”(Concatenate)在一起之后再变换,即在两者联合的特征空间去学习的能力;同时,如PyramidResNets[18] 指出,ResNets中特征维度随着深度的增长应该平缓。
ResNeXts[19]: 基于GoogLeNets和ResNets,非常巧妙的采用了Group卷积来在ResNets的模块中实现拆分-变换-聚合;虽然整体性能得到提高,但其设计没有改进Inception模块单层的拆分-变换-聚合和ResNets缺少特征探索能力的不足。
DenseNets[10]: 针对性的解决ResNets缺少特征探索能力的不足,提出了密集型的“串接”方式来进行特征探索学习,获得了CVPR17 Best Paper Award。美中不足的是,DenseNets放弃了ResNets强大的特征利用功能,并且在ImageNet上的性能没有明显提高。
DualPathNets (DPN)[20]:通过分析,将ResNets和DenseNets作为高阶循环网络(High-Order Recurrent Neural Networks, RNNs)的特例来解释,提出了一种简单的并行架构融合两者,扬长避短,取得了非常好的效果;DPN可以被看成在Building blocks的层次之上,采用拆分-变换-聚合的想法来统一ResNets和DenseNets。
DeepLayerAggregation (DLA)[21]:上述各种网络结构在buildingblock(或Layer)的层次上基本都采用简单的前向结构(Feed-forward),没有探讨building blocks之间如何更有效聚合的问题;正如其名字所示,DLA针对性的突出了“聚合”在拆分-变换-聚合的重要性,提出了如何有效的对building blocks在它们形成整体网络的过程中(通常是在一个Stage中),同时进行聚合,改变了图2的Stage内的“串行”结构。但是,DLA没有探讨如何深入的结合building block本身在一起进行更高效的拆分-变换-聚合。
那么,统一现有的building blocks并超越其性能是否可行呢?答案取决于是否可以找到一个严谨的框架来定义和演算上述的组成性(Compositionality)、可配置性(Reconfigurability)和侧连接性(Lateral connectivity)等,并且在实现上能通过一种简单的形式,来对现有很多building blocks融合,从而扬长避短。其实,概率语法模型[2,6]和模式理论[7,8]已非常严谨的给出了统一的框架;它们博大精深,非我所能阐述清楚,我在后面会作一个简单的回顾和提供一些相关的参考,留给感兴趣的读者去自由探索。在下一节,我简单介绍我们在语法模型的框架下,提出的一个简单的统一架构,AOGNets的思想。
第二节 卷积神经网络架构设计的一个简单统一框架 --- AOGNets及其实验效果
图4所示是我们提出的And-or grammar (AOG) building block。图5给出一个按照图2的策略对AOG building block进行组装而得的AOGNet的简单示例。AOGNets采用了一种形式上最简单的语法模型,能比较好的统一现有的各种building blocks,并且在一系列实验中取得了更好的性能,所以应该能佐证语法模型和DNNs的深度结合一定是一座美丽的后花园,值得探索。
下面,我首先解释这个AOG building block是怎么建立的,然后说明它是如何统一现有的很多building blocks (图3)。这一部分可能有点技术性的枯燥,不感兴趣的读者可以直接跳到实验结果。
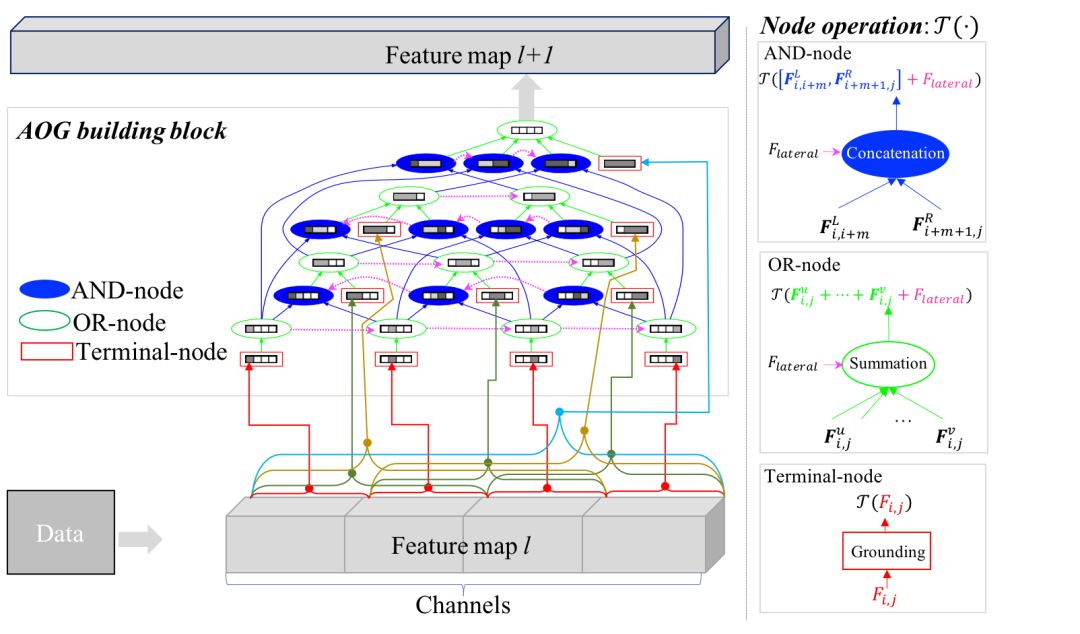
图4. AOG building block示意图。来自论文[1]。
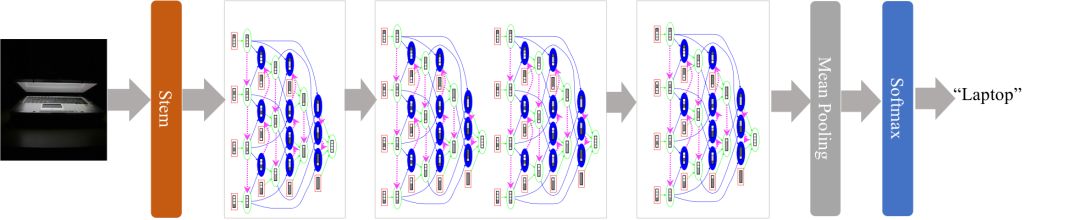
图5. AOGNets的一个简单示例。来自论文[1]。
我们首先回看一下图3,建立一个好的building block的关键之一是高效且均衡的学习特征探索(Feature exploration)和特征利用(Feature exploitation/reuse),在实现上的启发式规则是拆分-变换-聚合。再联合图3和图4一起来看,我们其实可以发现一个直观的解释:在建立building block的时候,我们首先需要引入更多的“自由度”去探索更有效的从输入特征图到输出特征图的变换,从而能更好的揭示(unfold)图1 中示例的巨大的神经网络架构空间。但是,我需要一种简约而不简单的规则来引导“自由度”,为此,语法模型的引入是一件自然而然的事。
我们的AOG building block提出使用一种最简单的语法来实现多层次,组成式的拆分-变换-聚合,大概思想如下:
首先,我们将输入特征图看成一个句子,有N个单词(例如N=4,图4),每个“单词”代表一组最基本的特征(神经元)聚类,我们希望引入一种语法结构,它能以一种简洁的组成式方式来涵盖所有可能的“句子-子句子-词组-单词”的分解,从而每个“单词或词组”都能有很多条从输入特征图变换到输出特征图的可配置(Reconfigurable)信息通路。
对自然语言处理方向熟悉的读者可能已经知道,非常经典的Cocke–-Younger–Kasami(CYK)解析算法和对应的句法结构语法(Phrase structure grammar)就是我们所想要的,并且,我们可以只利用一种分解/组成语法规则 --- 二分(Binary split),如图4所示:自上而下的看,“句子”整体通过一个或节点(OR-node)表示,我们可以直接终止对句子的分解,如此形成一个终端节点(Terminal-node,即输入特征图中的所有特征都相关,被聚为一类),或者,我们利用二分规则,能将句子分成不同的“左右子句子”,每种分解通过一个与节点(AND-node)来表示,每种分解所得的左右子句又通过不同的或节点来表示,如此按照宽度优先搜索(Breadth-first search, BFS)的图递归迭代算法,我们很容易通过一个有向无环与或图(And-or graph)来表示对应的与或句法结构语法。
进一步,我们通过Dependency grammar来在同一级别与节点,以及或节点之间引入侧连接(Lateral connections,图4中的紫色的虚线箭头所示),对应于概率语法模型中从上下文无关语法(Context-free grammars)到上下文相关语法(Context-sensitive grammar)的转变,实现更有效的聚合。
这里,值得一提的是,AOG building block通常被认为架构过于复杂;但我们认为,很多时候看起来的复杂性其实是模型的丰富和多样性,因为其本质上的创建算法是一个最简单的CYK算法(联想到数学上的分形艺术);同时,后面的实验结果会进一步表明,AOGNets在模型复杂度(参数数量)和计算复杂度(浮点运算量大小)两个方面都有优势。对于AOG building block中的节点,我们可以简单的使用一种统一的变换操作,例如常用的Conv+BatchNorm+ReLU。
如何解释AOG building block统一了现有的各种building blocks (图3)?可以从以下几个方面来概括:
终端节点: 在“拆分”方面涵盖了所有大小的词组(包括句子整体,所谓k-grams),在“变换”方面涵盖了基本的卷积,不同粒度的组卷积(Group Conv.),从而集成了GoogLeNet、ResNets 和ResNeXts的变换单元。
与节点: 实现了类似DenseNets的“串接”聚合策略,进行特征探索学习。
或节点: 实现了类似ResNets的“加”聚合策略,进行特征利用学习。
与或图的多层次结构:实现了类似Pyramid ResNets中对特征维度平稳渐增的策略。
与或图组成式架构:提供了非常丰富的信息流,实现比DPN和DLA更灵活的集成。
侧连接: 实现了提升与或图中节点的有效深度(effective depth)和及时信息融合,比DLA更深入更灵活的探索了“聚合”的方法。
整体与或语法:实现了有效的网络深度和宽度的平衡。
所以,总结起来,AOGNets可以被概述成,

其中Phrase structure grammar 和Dependency grammar 都采用了最简单和最直观的形式,联合来实现组成性(Compositionality)、可配置性(Reconfigurability)和侧连接性(Lateral connectivity),这是首次在神经网络架构中显式的实现这三种特性。
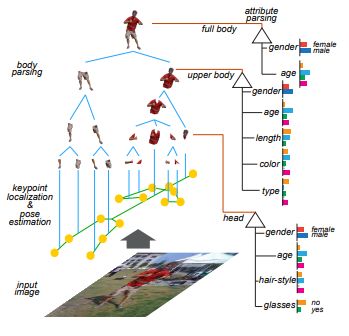
图6. Phrase structure grammar、Dependency grammar和Attribute grammar在解析人体图像中的应用。图片来自UCLA朱老师团队论文[22]。
如图6所示,上面谈到的Phrase structure grammar和Dependency grammar之前已经在UCLA朱老师团队的工作[22]中被应用到对人体图像进行联合人体部件解析和人体属性(Attributes)识别。其中Phrase structure grammar用来从语义上,对人体从整体到部件进行多层次、组成式建模;Dependency grammar用来对部件之间的空间和语义关系进行建模,同时结合Attribute grammar来做解析敏感的属性识别。联合三种语法,属性可以非常有效的在人体整体和人体部件同时学习,其识别更加鲁棒(比如,抗遮挡和视角变化),同时属性对人体部件解析也通过相关性语法给予帮助(比如解决人体左右对称部件之间的解析模糊性)。
为了验证语法架构的优势,我们在模型的其他方面,都采取最常用和普通的实现;比如,我们采用了和ResNets完全同样的节点运算函数—Conv+BatchNorm+ReLU,所以在同等实验配置下,AOGNets在性能上的提升,应该都归功于其基于语法模型的架构。在实验中,我们测试了AOGNets两个方面的性能:预测准确性(Predictive accuracy)和描述准确性(Descriptive accuracy,作为模型可解释性的一种衡量方法)。AOGNets都取得更好的表现。我们会很快公开AOGNets的所有代码,方便大家参考。
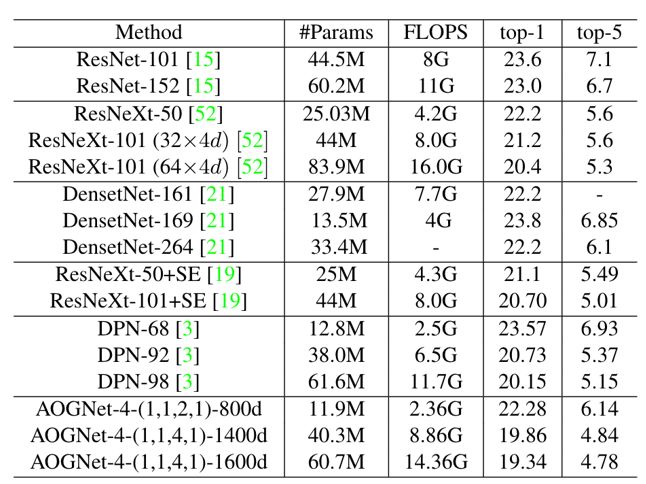
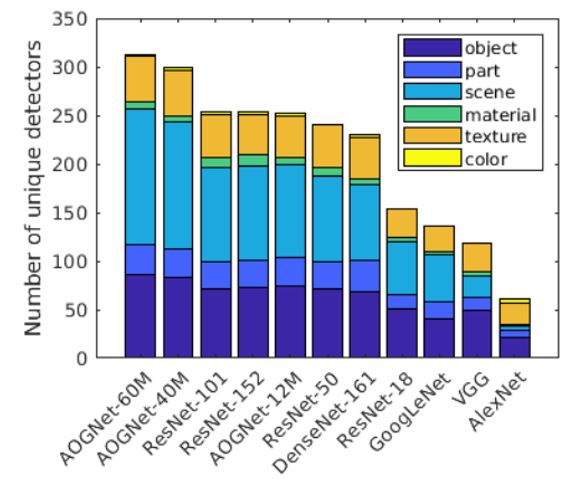
表1. 上:在ImageNet-1000上Top-1 和Top-5错误率(越小表示性能越好)的比较(224x224分辨率下Single-model single-center-crop的性能);下:基于network dissection 方法的模型可解释性比较。来自论文[1]。
ImageNet-1k图像分类数据集:AOGNets取得了同等可比情况下最优性能和最佳可解释性。ImageNet已经是测试不同神经网络架构的标准数据集,包含1000类物体,训练和测试子集大小分别为1.2M和50K。我们测试了224x224分辨率下Single-model single-center-crop的性能。实验比较,如表1(上)所示,AOGNets取得了最优性能。表格中其他方法的参考文献,具体请见论文[1]。值得注意的是,我们AOGNets在训练过程中只使用了最基本的数据增强(random crop 和horizontal flip),也没有使用任何额外的训练技巧。同时,如表1(下)所示,我们按照Network dissection[23]的方法,比较了不同模型的可解释性:Network dissection是目前比较广泛使用的定量的评价神经网络可解释性的一个方法;评价标准是根据网络中最后一层卷积层中的unique的卷积核(即detector)的数目的多少;其uniqueness是根据其提供的一个涵盖视觉低,中和高层模式的数据库来计算。
MS-COCO物体检测和实例分割数据集。MS-COCO是目前最通用的物体检测和分割的数据集。我们在最新的maskrcnn-benckmark的代码框架[24,25]下测试了AOGNets,如表2所示,AOGNets取得了比ResNets和ResNeXts都好的性能。
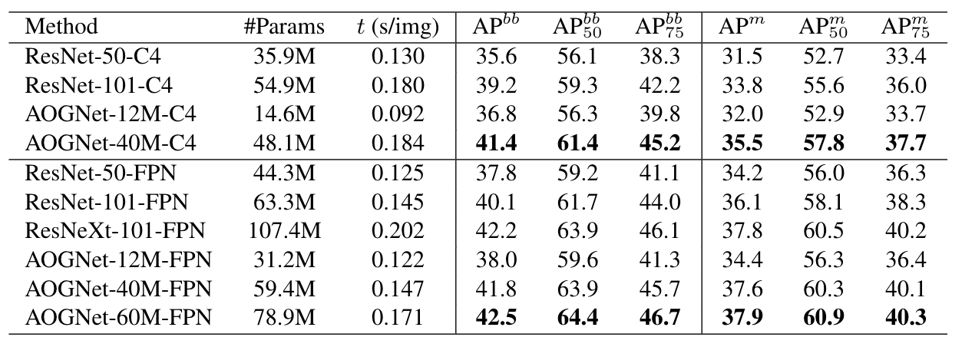
表2. 在MS-COCO上基于Mask-RCNN框架的性能比计较。来自论文[1]。
第三节 语法模型的回顾
看完上述AOGNets的基本思想后,大家可能会有疑问:为什么我们会去采用最简单的自然语言处理的语法模型?这里我想引用D. Mumford教授在其博客文章《Grammar isn’t merely part of language》(语法不仅仅只是语言的一部分) [26]中的一段话
“Grammar in language is merely a recent extension of much older grammars that are built into the brains of all intelligent animals to analyze sensory input, to structure their actions and even formulate their thoughts.”(大概翻译为:在所有智能动物的大脑中都都由来已久的建立了语法模型,这些语法模型的作用是去分析各种感知信息,规划智能动物接收感知信息后的动作行为,甚至帮助其思想的形成;而语言中的语法只是这些更深层面的语法的一个近期的扩展)。
对这段话的全面理解可以参考UCLA朱老师和D. Mumford教授的文章[2] 以及相关文献[7,8]等。AOGNets只是对这段话做了一次最简单的“小试牛刀”。
语法模型的一般性介绍可以参看之前在《视觉求索》发表的一篇焦点评论 ––– “概率语法图模型发力,小样本学习的突破”: 对语法建模的思想一开始出现在对自然语言建模的研究中,研究者通过随机上下文无关语法(Stochastic context free grammar,SCFG)来对自然语言的词法、句法等建模。在图像中,由于视觉模式本身的多层次和组成式特点,对语法建模更为重要,是建模的一个核心问题。自然语言中字与字之间,词与词之间等存在显式的左右顺序(Left-to-right)关系,但在图像中不存在,这给图像语法建模带来了很大的困难:SCFG并不直接适用。图像语法的里程上,概率语法图和组成模型的演变和发展主要包括,著名华人人工智能专家傅京孙(K.S. Fu)在上个世纪70年代提出的句法模式识别(Syntactic pattern recognition)、U. Grenander的模式理论(Pattern theory)、S. Geman提出的视觉中compositionality和reusable parts的概念和模型,朱松纯(S.-C. Zhu)和D. Mumford在2006年提出的与或图(And-or graph)模型,以及诸多与深度学习结合的相关工作。其中,与或图的概念开始是出现在人工智能的启发式搜索中[27],UCLA的J. Pearl等提出对解空间进行与或分解,是算法的与或图diagram(而非概率表达模型);UCLA朱松纯教授团队首次将其发展到图像表示建模中,用于表达组成结构非常复杂的物体类别,如时钟、衣服等。后来进一步推广到时空因果与或图(STC-AOG)来统一表达场景、物体、行为、事件、与因果。近年来,西北大学吴郢教授团队和中山大学林倞教授团队等也在语法建模和深度学习结合方面有深厚独到的建树。
追本溯源, AOGNets回归到最简单的语法模型来进行神经网络架构的设计,主要是由于“近水楼台先得月”,在我非常熟悉的UCLA朱老师的相关工作,包括我本人之前求学期间的一些工作的基础上开展的一个小尝试。
相关工作1:可变形与或树[28] (CVPR2013)。这是我们之前采用与或语法对可变形部件模型(Deformable part-based models, DPMs)[29]在物体检测任务上进行尝试,改变DPMs原有自底向上的贪婪式学习物体的配置模型,进行自顶向下的与或图全局搜索,在PASCAL VOC2007和2012上得到比DPMs 及相关变种模型更好的性能。
相关工作2:基于与或图的在线物体跟踪,学习和解析[30](CVPR2014, PAMI2016)。这是我们对上述可变形与或树模型在物体跟踪方向上的扩展,取得了非常好的效果,也在OTB100和VOT两个数据集上超过了很多跟踪模型,包括当时一些基于深度学习的模型。
上述两个工作中,我们都是使用传统的手工设计特征HOG[31]。我们集中在2D 的语法模型对物体或场景的空间配置进行与或建模,在弱监督(weakly-supervised)情况下通过判别式学习对物体可变形与火树模型进行寻优,其与或图中的每个节点代表的是一个物体或场景的可变形部件(parts)或子配置(sub-configurations)。AOGNets其实是做了“减法”,集中在特征通道(1D)上,其与或图的创建是之前2D版本的一个简化;但是AOGNets没有去进行“剪枝”,而是保留所有可能的解析树,进行端到端的学习。对于2D AOG在基于DNNs的物体检测中应用,特别是其对可解释性深度物体检测方面的潜力,我们最近也有一个小的尝试[32],进一步的研究还在进行之中。
相关工作3:基于与或图的可解释性人工智能框架,这个涉及UCLA朱松纯教授团队最近一系列的重要工作[2,33-35];加入北卡州立之后,我一直保持追踪朱老师组的大部分论文,继续吸收养分;统一框架方面,感兴趣读者可以参看朱老师之前在《视觉求索》的长文 --- “初探计算机视觉的三个源头、兼谈人工智能” 和“浅谈人工智能:现状、任务、架构与统一”。
第四节 AOGNets的小结和下一步计划
AOGNets只是语法模型和DNNs结合的最简单的一个例子。希望通过这个例子,我表达清楚了这样一个认识:
其实在很多计算机视觉和表征学习(Representation learning)问题上,用语法模型并非是“先入为主”,而是用或不用,语法模型其实都在那里。很多时候可能会发现,“蓦然回首,那人却在灯火阑珊处”,很多模型和方法能在语法模型下统一,交流,再发展。
我们目前继续在AOGNets方向努力,希望能尽快做出一些好的结果和大家分享;我简单的谈谈我们很感兴趣的几个方面:
计算机视觉方向上,从AOGNets到Auto-AOGNets: 熟悉神经网络架构搜索(Neural architecture search, NAS)[36]的读者应该早有疑问,有了目前最流行的NAS,是不是可以就不用关心语法模型了?我们认为,NAS更需要语法模型来指导设计更好的搜索空间。NAS可行的关键之一是需要定义一个非常好的架构空间(图1);NAS通常策略是所谓的抽样—评价—更新(Sample-Evaluate-Update),对模型架构空间的定义是决定其成败和效率的关键因素之一。与或语法在这方向上的潜力应该更大,实现上,我们需要更强的GPU资源。
自然语言理解方向上,从AOGNets到AOGTransformer: 看完AOGNets创建过程之后,另一个自然的疑问是:基于自然语言理解中的句法结构语法和Dependency语法的AOGNets是否可以返回去对自然语言进行建模?答案应该是非常肯定的,我们目前尝试AOGNets和Transformer[37]模型的深度结合,希望AOGTransformer能更灵活和灵巧的实现很多自然语言理解的任务。
视觉和语言结合方向上,如视觉常识推理,从AOGNets到AOGReasoner: 目前,常识推理被认为是当前人工智能的一个“短板”。我们正在探索对如何结合AOGNets和图卷积网络(GraphCNNs)[38]来实现具有一定常识推理能力的系统。
我们的一个中期目标是在现有深度学习的平台之上(比如PyTorch),搭建一个语法模型的系统,来实现灵活可扩展的Auto-AOGNets + AOGTransformer + AOGReasoner,从而能提供一个大家能广泛使用的小平台。这里也宣传一下:希望对上述方向感兴趣的同学选择加入我们组,也期待和感兴趣的同行多交流和合作。
这里附带讲一点个人随感:2018年8月份,我有幸随UCLA朱老师和吴英年老师,参加了Brown大学D. Mumford教授(我师爷)80岁生日庆祝和研讨会,聆听了很多前辈大师们的精彩报告。由于机缘巧合,研讨会中间有个时间空档,朱老师安排我对AOGNets做了一个简短的汇报。在我的汇报中,我用AOGNets作为一个例子,谈了模式理论中最简单的一个语法模型(如上述),是如何能帮助最前沿的深度学习更好的设计其核心的网络架构,受到与会的几位老师的肯定,让我深感荣幸和备受鼓舞。研讨会的最后,朱老师高瞻远瞩的论述了一个统一理论框架和深度整合框架,更加坚定了我在这个方向上研究和努力的决心。另外,特别高兴的是朱老师组织了一个NGO, International Center for AI and Robot Autonomy (CARA)来进一步推进他的统一理论框架和深度整合框架。我深信其不可估量的前景和“原天地之美而达万物之理”的追求,也希望自己将来能有机会参与到其中,“到中流击水,浪遏飞舟”。
致谢
AOGNets论文从有初始想法(2016年底)到有幸被CVRP19接收,经历了一个相对比较痛苦的过程:主要是缺少GPU资源,我们后来感叹说这是一个因为缺少GPU而被暂时耽误的模型!这期间,感谢学生李曦来(论文一作)和论文合作者宋熙的坚持和努力,也感谢UCLA朱松纯教授和吴英年教授、西北大学吴郢教授、北卡州立Hamid Krim教授、北京大学王亦洲教授和Salesforce 熊蔡明博士等等众多师友的一直鼓励和帮助。同时,十分感谢前ARO项目经理Liyi Dai博士的赏识和支持。
参考文献(按文章中出现次序)
[1] X. Li, X. Song and T.F. Wu. AOGNets: Compositional grammatical architectures for deep learning. In IEEE CVPR, 2019.
[2] S.-C. Zhu and D. Mumford. A stochastic grammarof images. Foundations and Trends in Computer Graphics and Vision, 2(4):259–362, 2006.
[3] Y. LeCun, Y. Bengio and G.E. Hinton. Deep learning. Nature 521(7553): 436-444, 2015.
[4] J. Schmidhuber. Deep learning in neural networks: An overview. Neural Networks, vol.61, 2015.
[5] A. Krizhevsky, I. Sutskever and G.E.Hinton. ImageNet classification with deep convolutional neural networks. In NIPS, 2012.
[6] K.S. Fu. Syntactic pattern recognition, applications. Springer-Verlag, Berlin, New York, 1977.
[7] U. Grenander and M. Miller. Pattern theory: From representation to inference. Oxford University Press, 2007.
[8] D. Mumford and A. Desolneux. Pattern theory, the stochastic analysis of real-world signals. AKPeters/CRC Press, 2010.
[9] K. He, X. Zhang, S. Ren and J. Sun. Deep residual learning for image recognition. In IEEE CVPR, 2016.
[10] G.Huang, Z. Liu, L. van der Maaten and K. Q. Weinberger. Densely connected convolutional networks. In IEEE CVPR,2017.
[11] K. Chatfield, K. Simonyan, A. Vedaldi and A. Zisserman. Return of the devil in the details: Delving deep into convolutional nets. In BMVC, 2014.
[12] C. Szegedy, S. Ioffe and V. Vanhoucke. Inception-v4, inception-resnet and the impact of residual connections on learning. CoRR, abs/1602.07261, 2016.
[13] M. Lin, Q. Chen and S. Yan. Network in network. CoRR, abs/1312.4400, 2013.
[14] S. Arora, A. Bhaskara, R. Ge and T. Ma. Provable bounds for learning some deep representations. In ICML, 2014.
[15] R.K. Srivastava, K. Greff and J. Schmidhuber. Highway networks. CoRR, abs/1505.00387, 2015.
[16] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, 2015.
[17] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg and L. Fei-Fei. ImageNet large scale visual recognition challenge. IJCV, 115(3):211–252, 2015.
[18] D. Han, J. Kim and J. Kim. Deep pyramidal residual networks. IEEE CVPR, 2017.
[19] S. Xie, R.B. Girshick, P. Dollar, Z. Tu and K. He. Aggregated residual transformations for deep neural networks. In CVPR, 2017.
[20] Y. Chen, J. Li, H. Xiao, X. Jin, S. Yan and J. Feng. Dual path networks. In NIPS, 2017.
[21] F. Yu, D. Wang and T. Darrell. Deep layer aggregation. In CVPR, 2018.
[22] S. Park, B. X. Nie, and S.-C. Zhu. Attribute and-or grammar for joint parsing of human pose, parts and attributes. IEEE TPAMI, 40(7), 1555-1569, 2018.
[23] D. Bau, B. Zhou, A. Khosla, A. Olivaand A. Torralba. Network dissection: Quantifying interpretability of deep visual representations. In IEEE CVPR, 2017.
[24] F. Massa and R. Girshick. maskrcnn-benchmark: Fast, modular reference implementation of instance segmentation and object detection algorithms in PyTorch. https://github.com/facebookresearch/maskrcnn-benchmark , 2018.
[25] K. He, G. Gkioxari, P. Dollar and R. Girshick, Mask R-CNN, In ICCV, 2017.
[26] D. Mumford. Grammar isn’t merely part of language. http://www.dam.brown.edu/people/ mumford/blog/2016/grammar.html.
[27] J. Pearl. Heuristics: intelligent search strategies for computer problem solving. Addison-Wesley Longman Publishing Co., Boston, MA, USA, 1984.
[28] X. Song, T.F. Wu, Y. Jia and S.-C. Zhu. Discriminatively trained and-or tree models for object detection. In IEEE CVPR,2013.
[29] P. F. Felzenszwalb, R.B. Girshick, D. McAllester and D. Ramanan. Object detection with discriminatively trained part-based models. IEEE TPAMI, 32(9):1627–1645, 2010.
[30] T.F. Wu, Y. Lu, and S.-C. Zhu. Online objecttracking, learning and parsing with and-or graphs. IEEE TPAMI, DOI: 10.1109/TPAMI.2016.2644963, 2016.
[31] N. Dalal and B. Triggs. Histogramsof oriented gradients for human detection. In IEEE CVPR, 2005.
[32] T.F. Wu, W. Sun, X. Li, X. Song and B. Li. Towards interpretable R-CNN by unfolding latent structures. CoRR abs/1711.05226.
[33] Q. Zhang, Y.N. Wu and S.-C. Zhu. Interpretable convolutional neural networks. In IEEE CVPR 2018.
[34] Q. Zhang, Y.N. Wu, H. Zhang and S.-C. Zhu. Mining deep and-or object structures via cost-sensitive question-answer-based active annotations. CVIU, 176-177: 33-44 (2018).
[35] Q. Zhang, R. Cao, F. Shi, Y.N. Wu and S.-C. Zhu. Interpreting CNN knowledge via an explanatory graph. In AAAI, 2018.
[36] B. Zoph, Q. V. Le. Neural architecture search with reinforcement learning. InICLR, 2016.
[37] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A.N. Gomez, L. Kaiser and I. Polosukhin. Attention is all you need. In NIPS, 2017.
[38] J. Bruna, W. Zaremba, A. Szlam and Y. Lecun. Spectral networks and locally connected networks on graphs. In ICLR, 2014.




