MSRA梅涛研究员: ICIP2017 Tutorial - 深度学习桥接视觉与语言
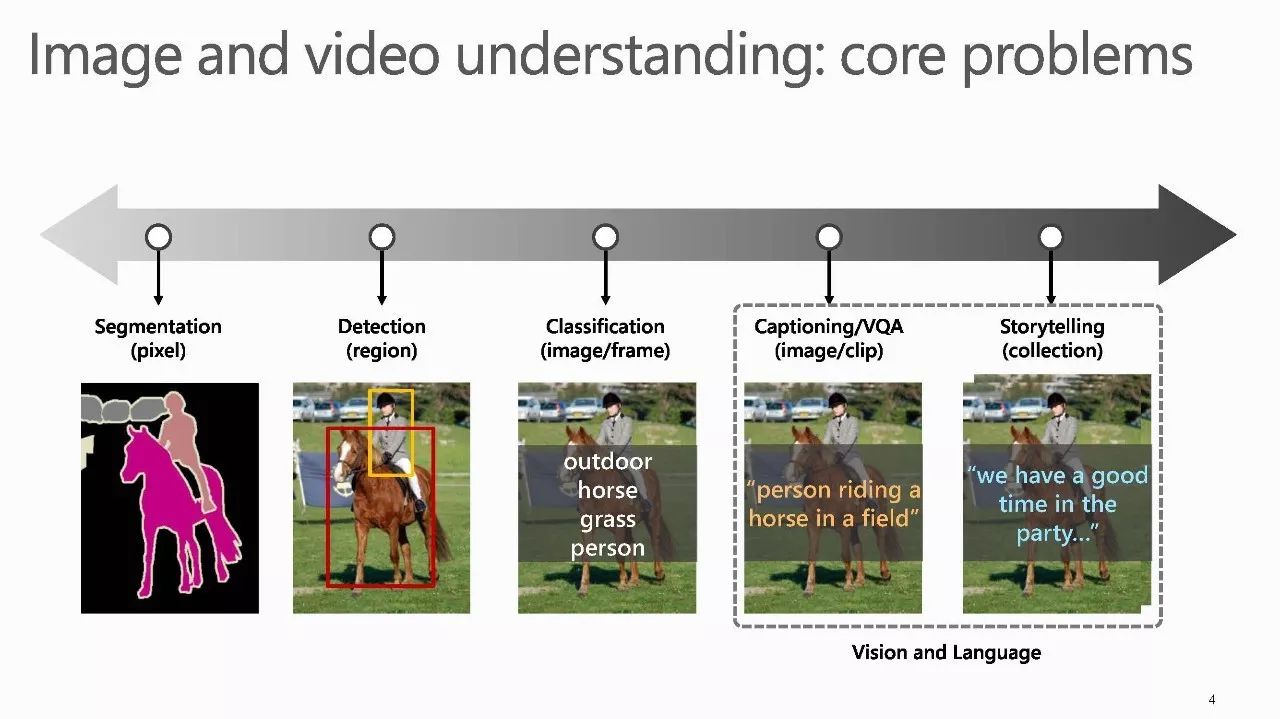
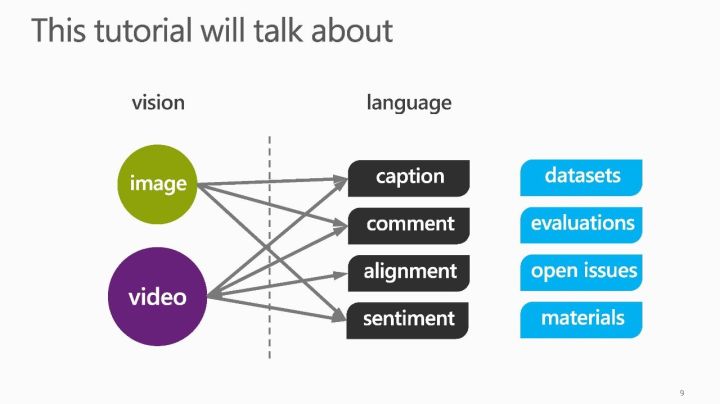
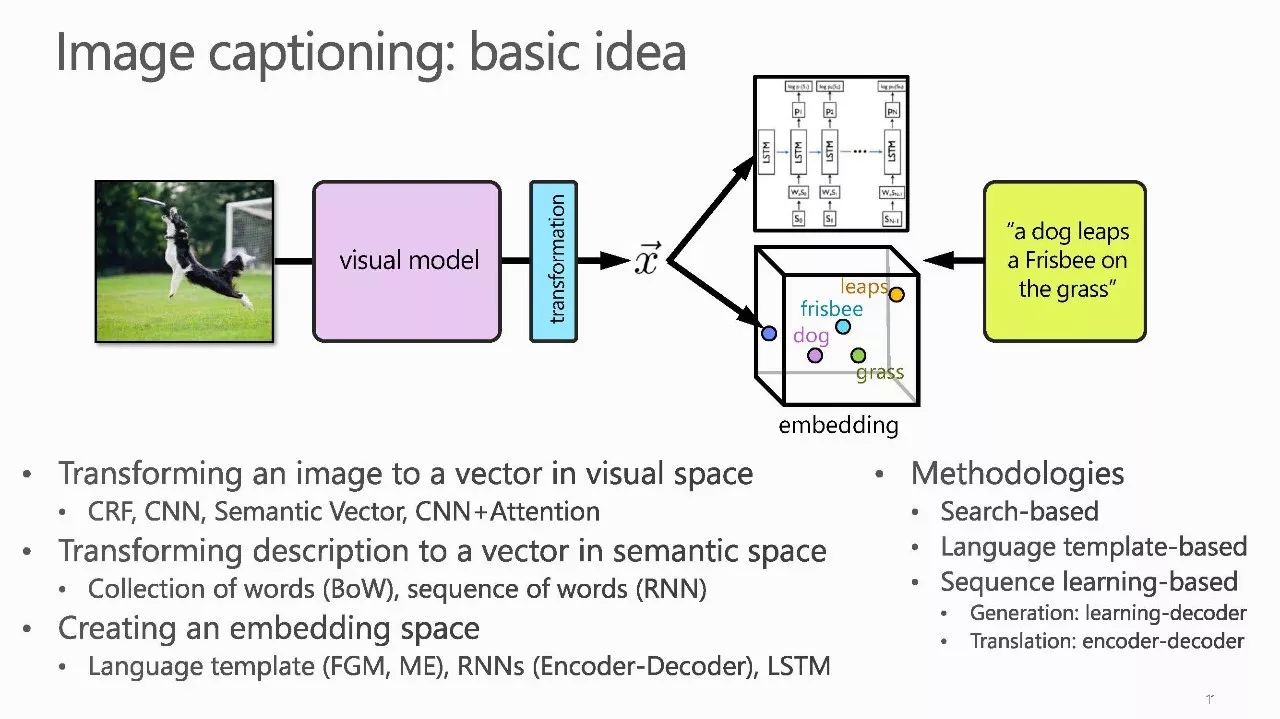
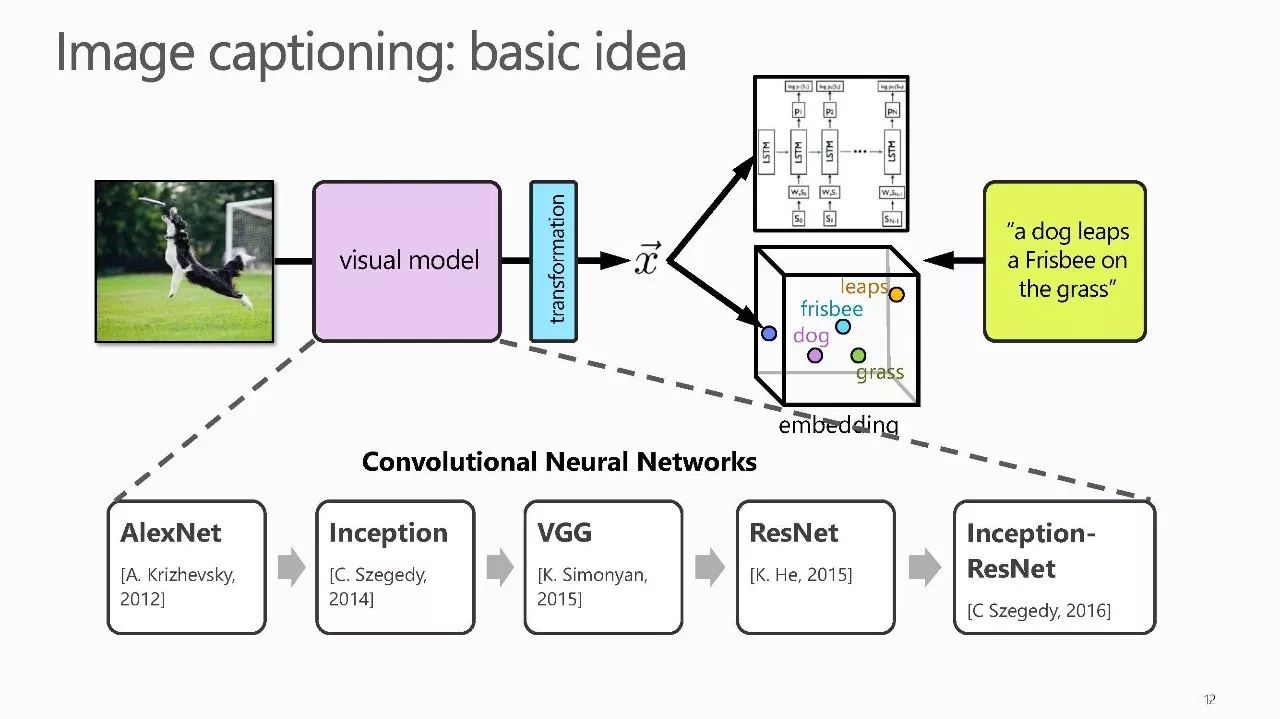
【导读】视觉内容的识别一直是数十年来计算机视觉中的一个根本挑战,以前的研究主要集中在使用预定义但有限的词汇来理解视觉内容。 由于深度学习技术的快速发展,计算机视觉和多媒体研究人员正利用深度学习来有效桥接自然语言和视觉。 在本Tutorial , 微软亚洲研究院的梅涛研究员将展示探索视觉理解和语言处理的协同作用技术的最新进展,包括视觉语言对齐,视觉字幕和评论,视觉情感分析,以及这个新兴研究领域的开放性问题。
Tutorial of 2017 IEEE International Conference on Image Processing (ICIP)
地址:https://www.microsoft.com/en-us/research/publication/vision-language-bridging-vision-language-deep-learning/








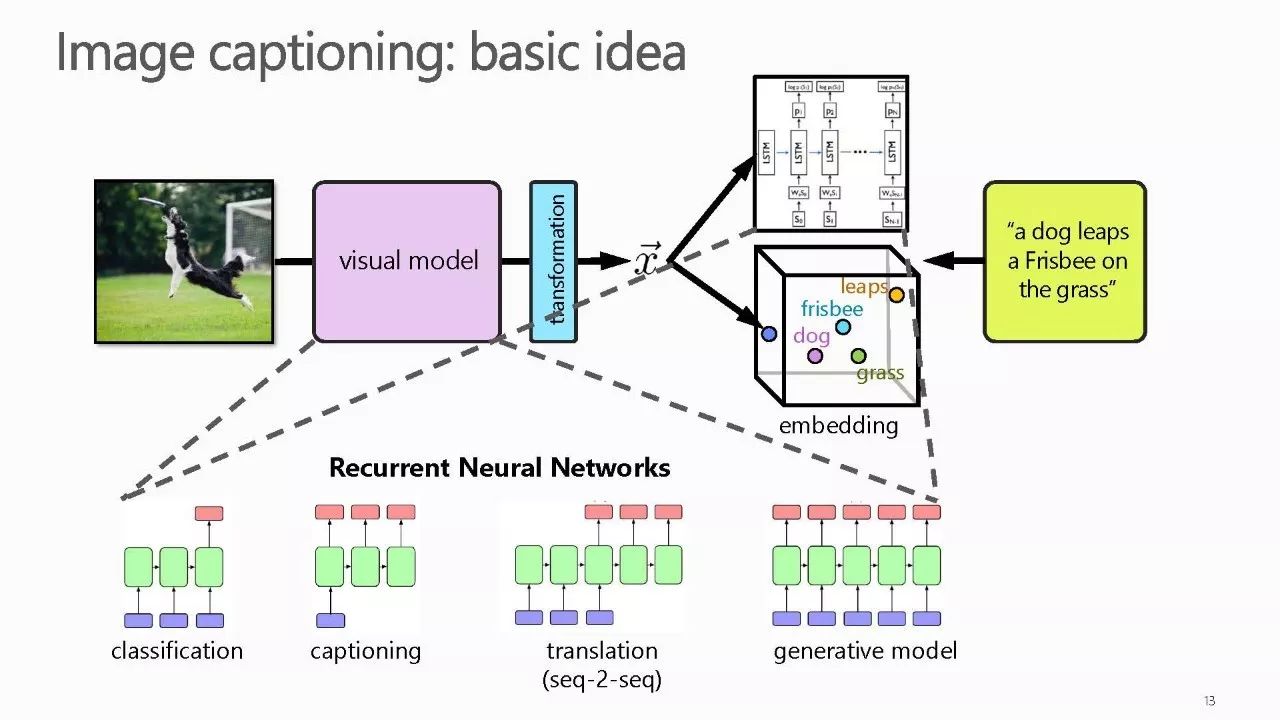

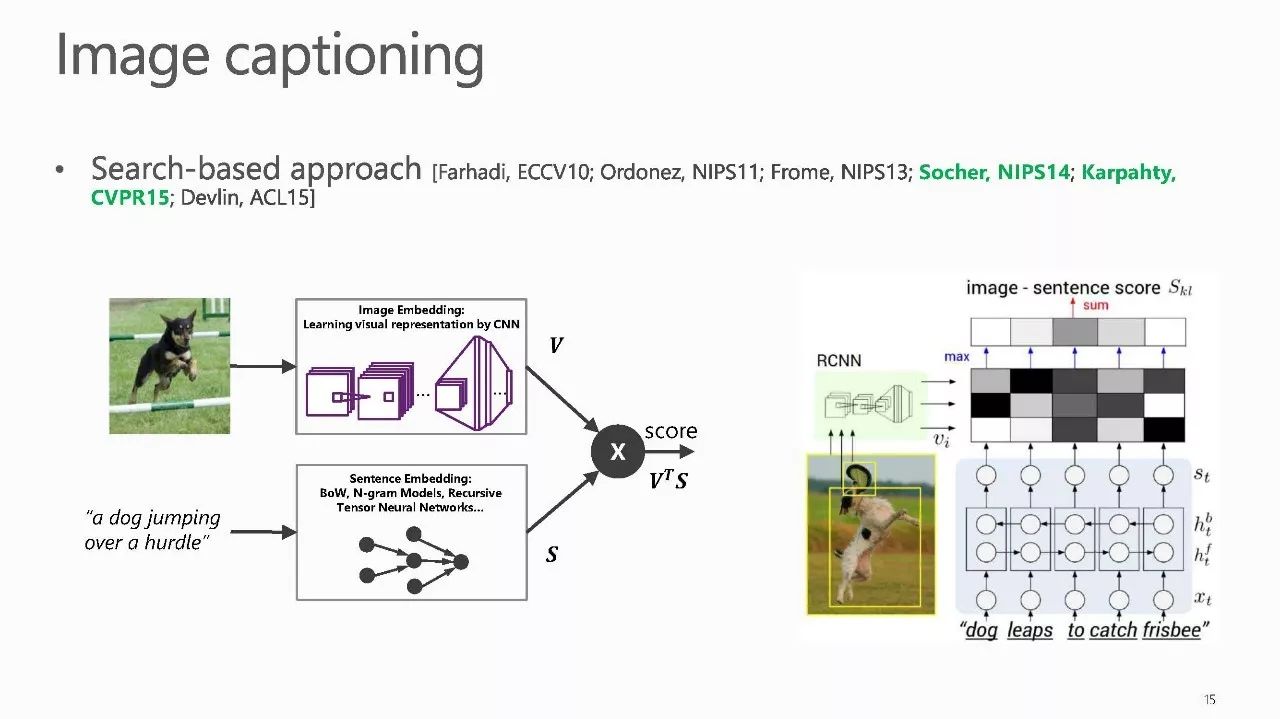

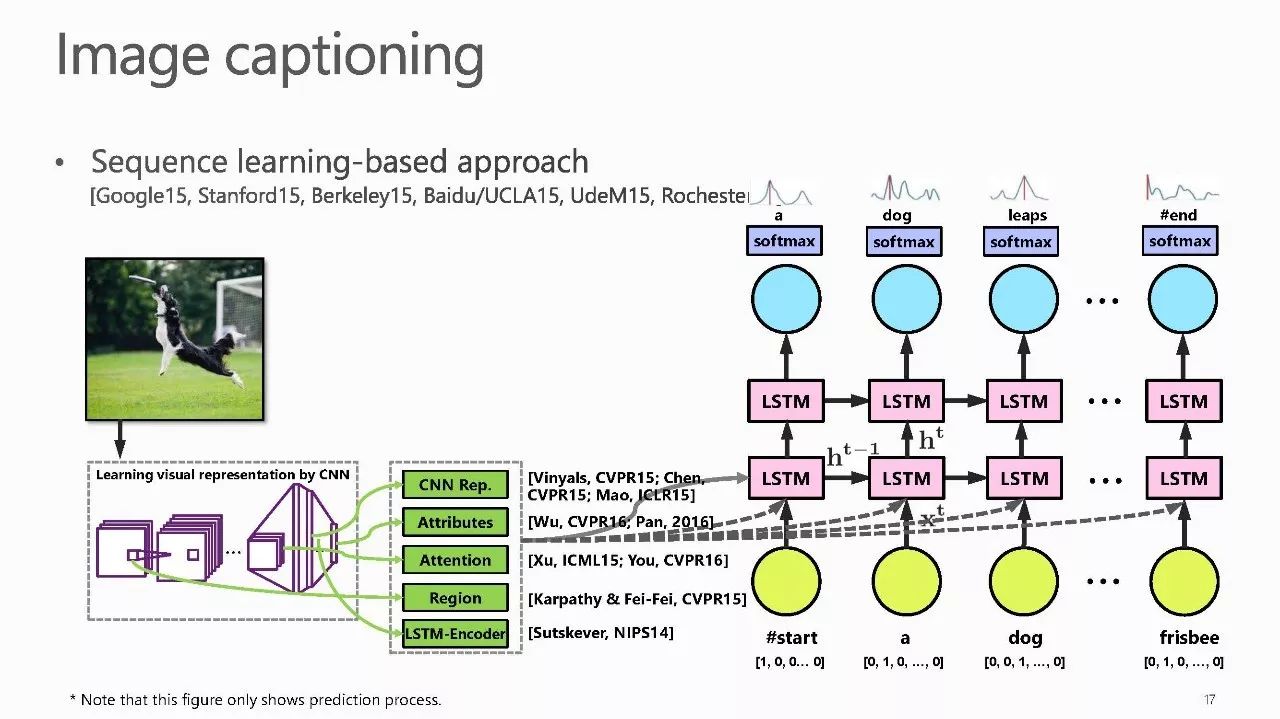



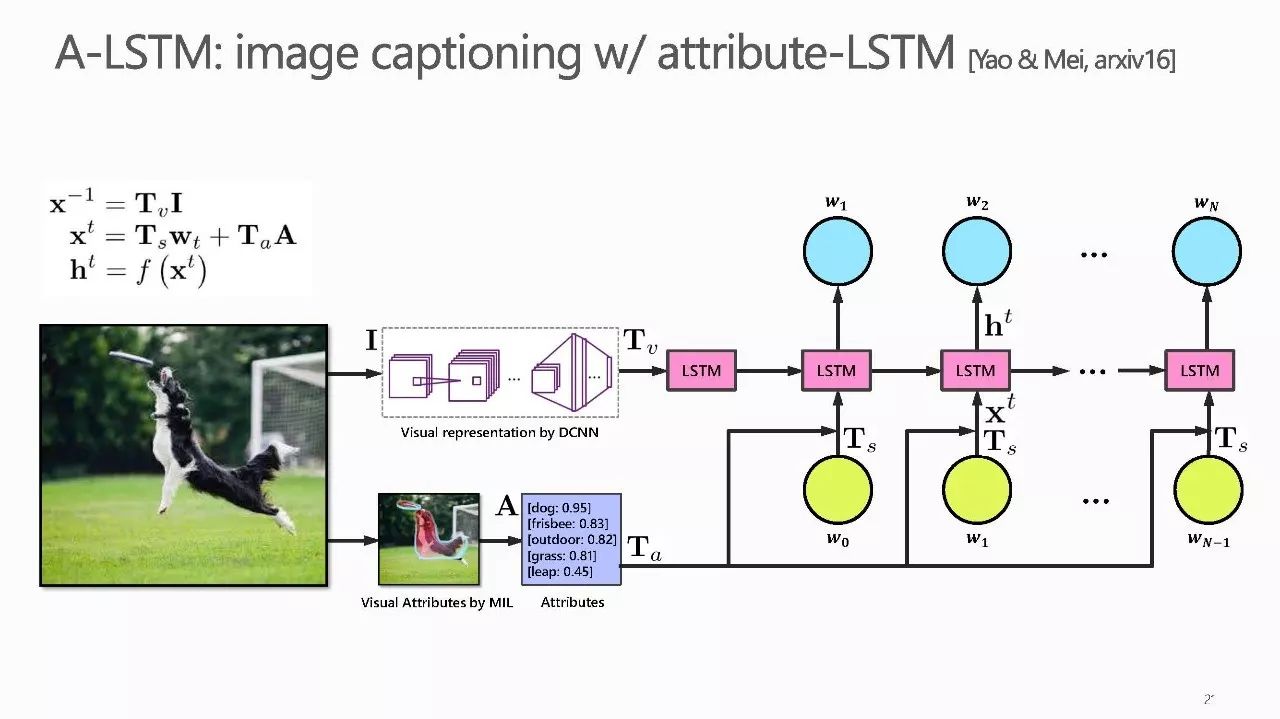
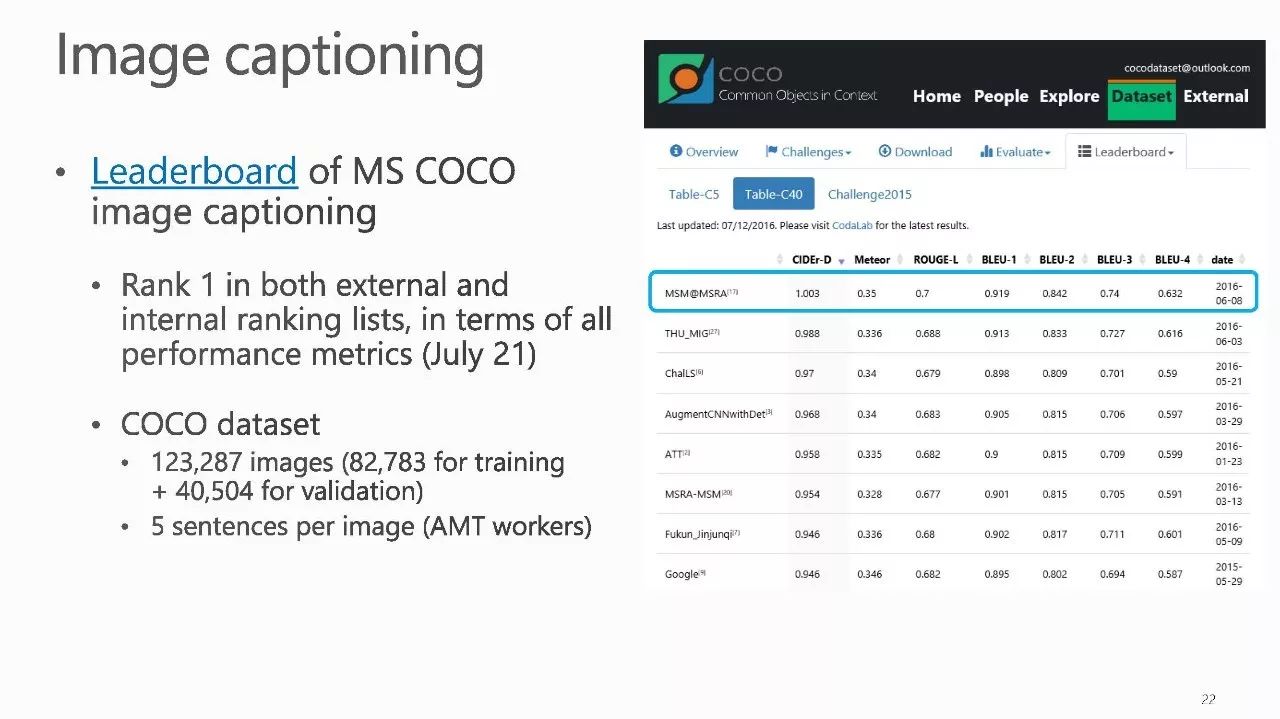
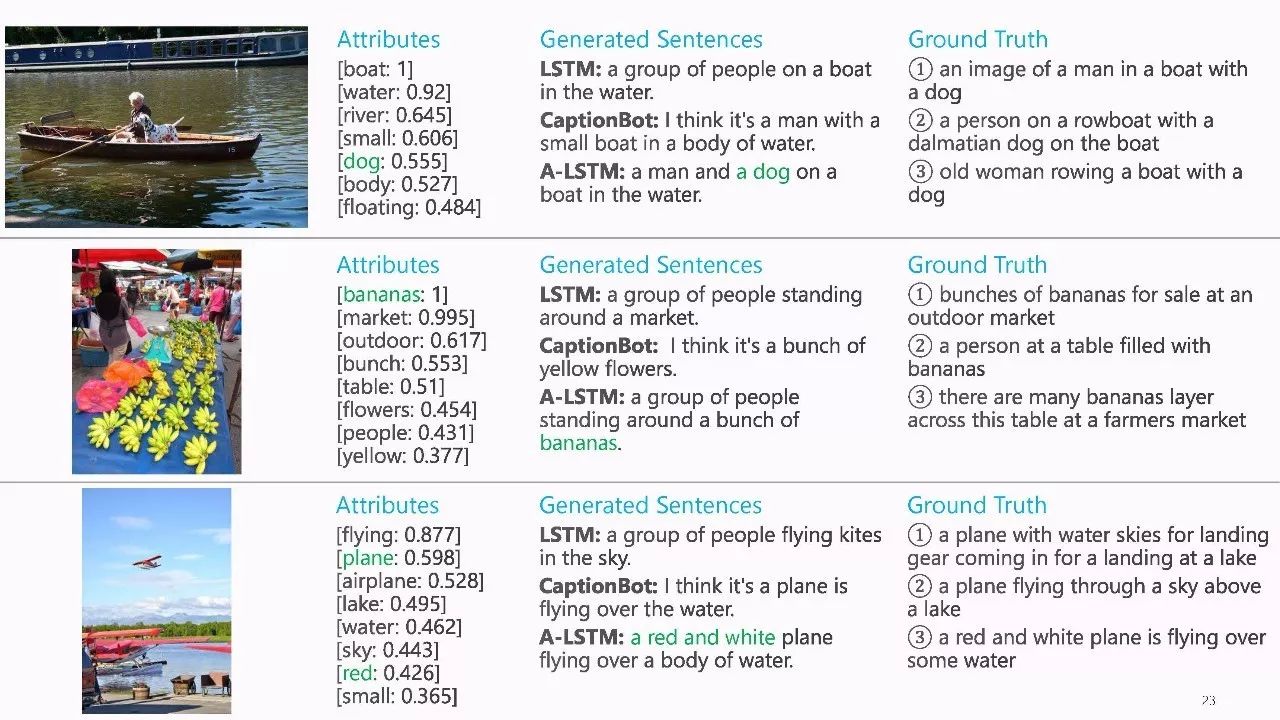
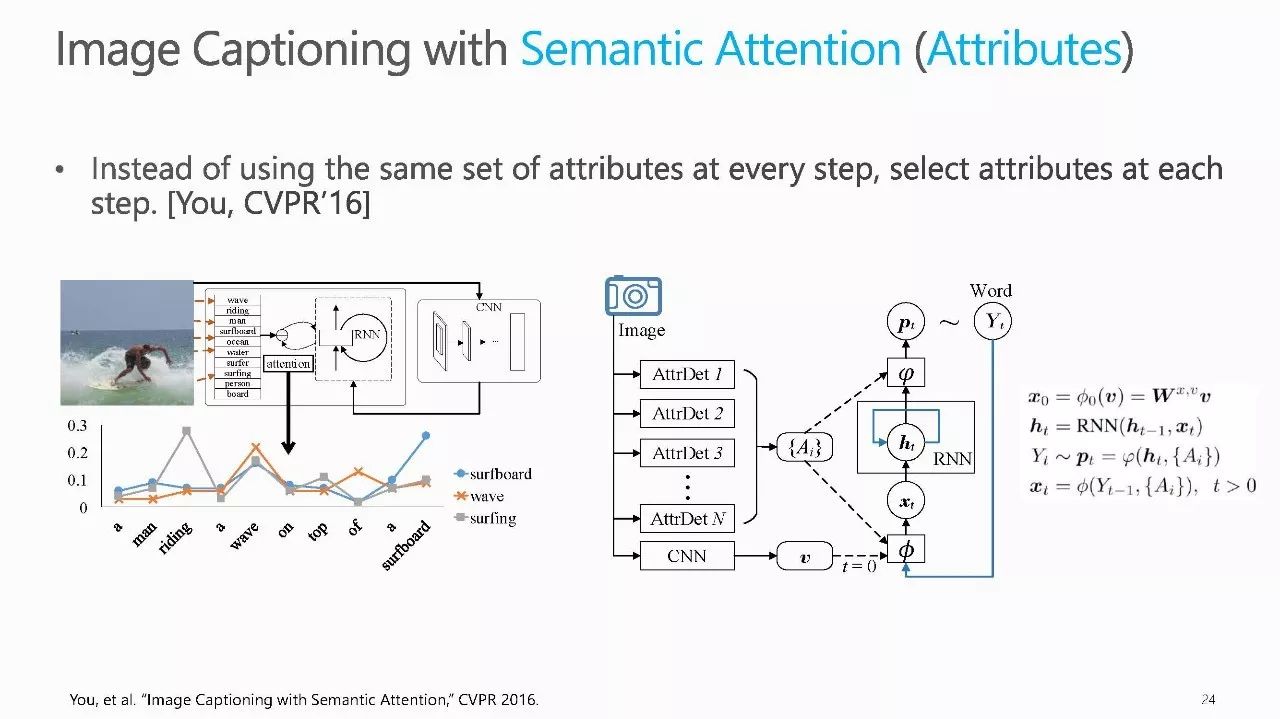
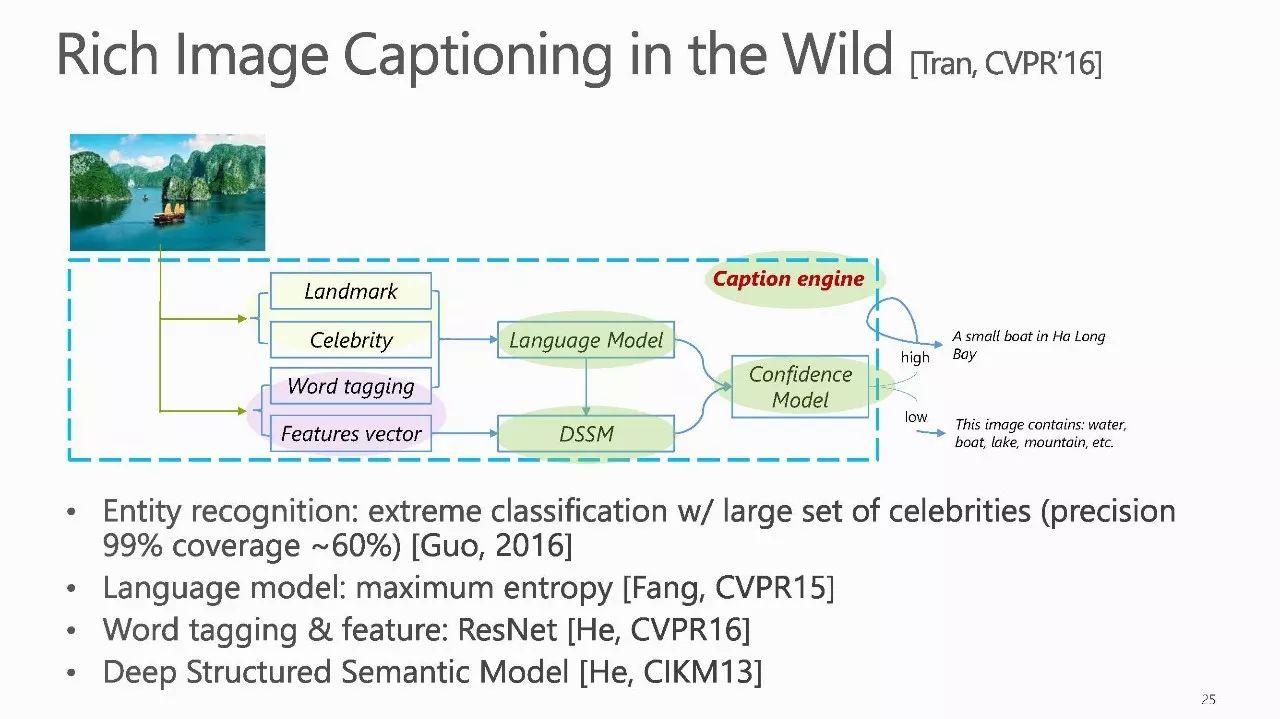


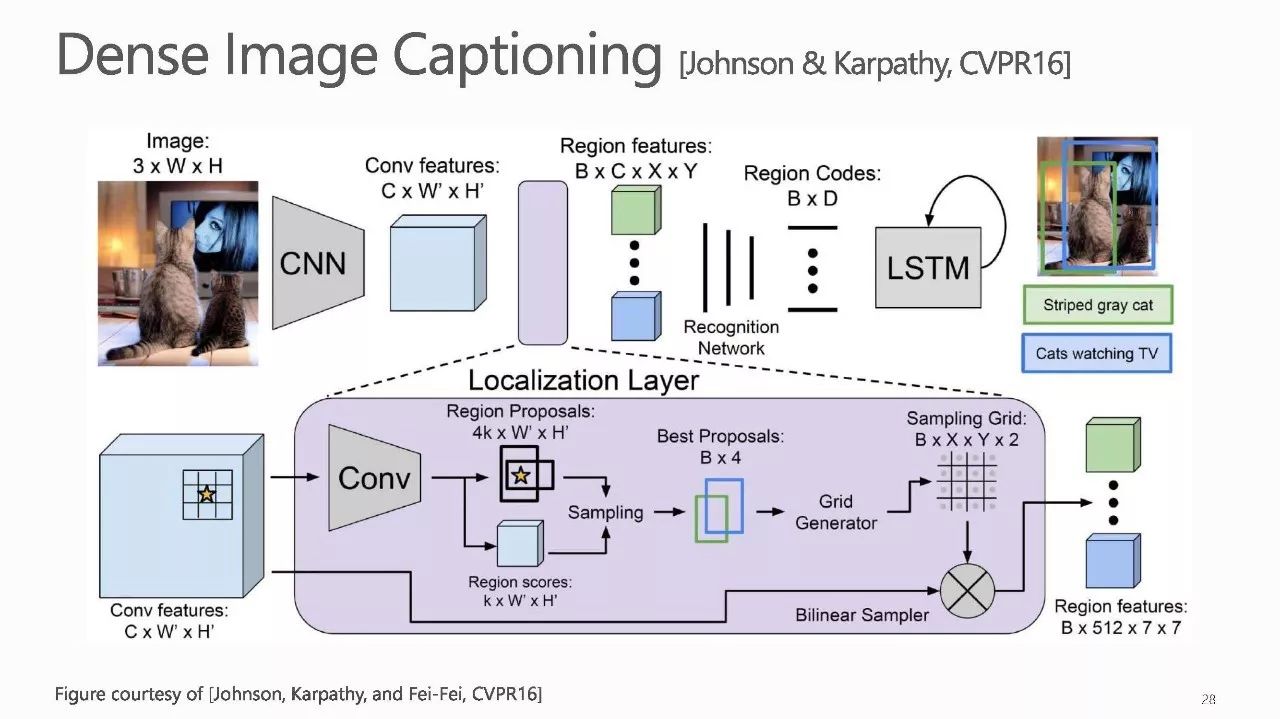
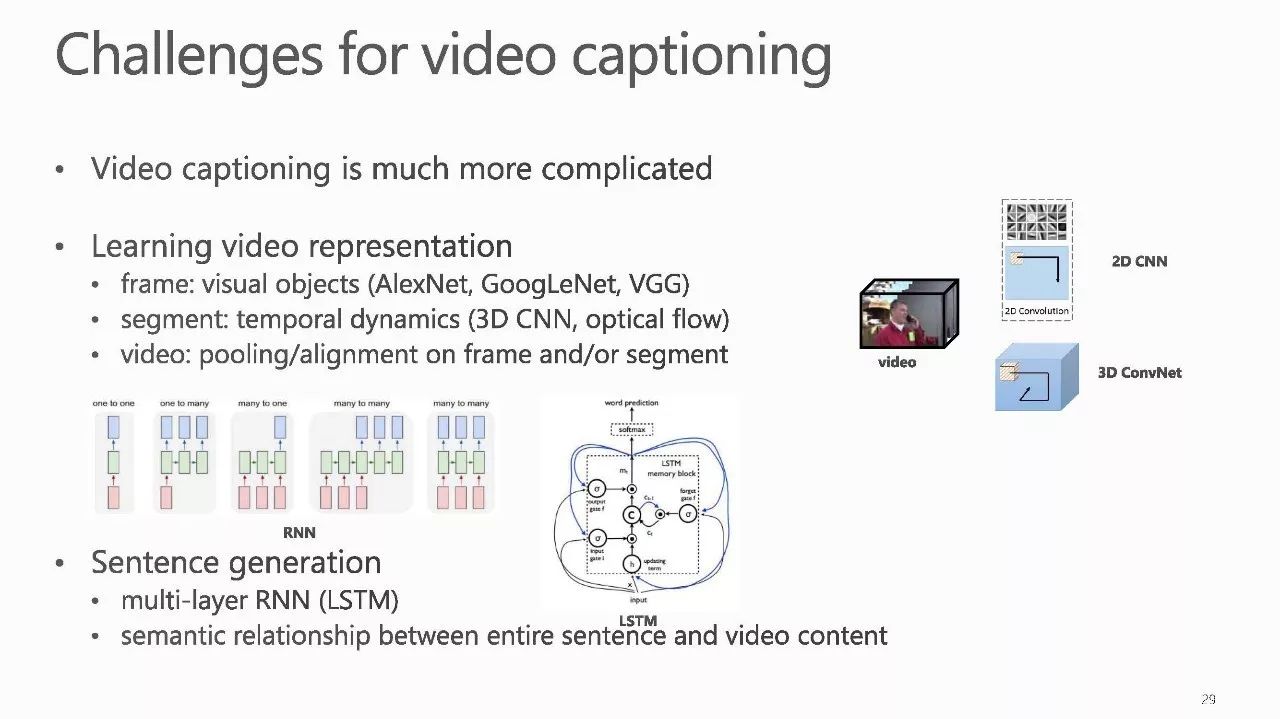

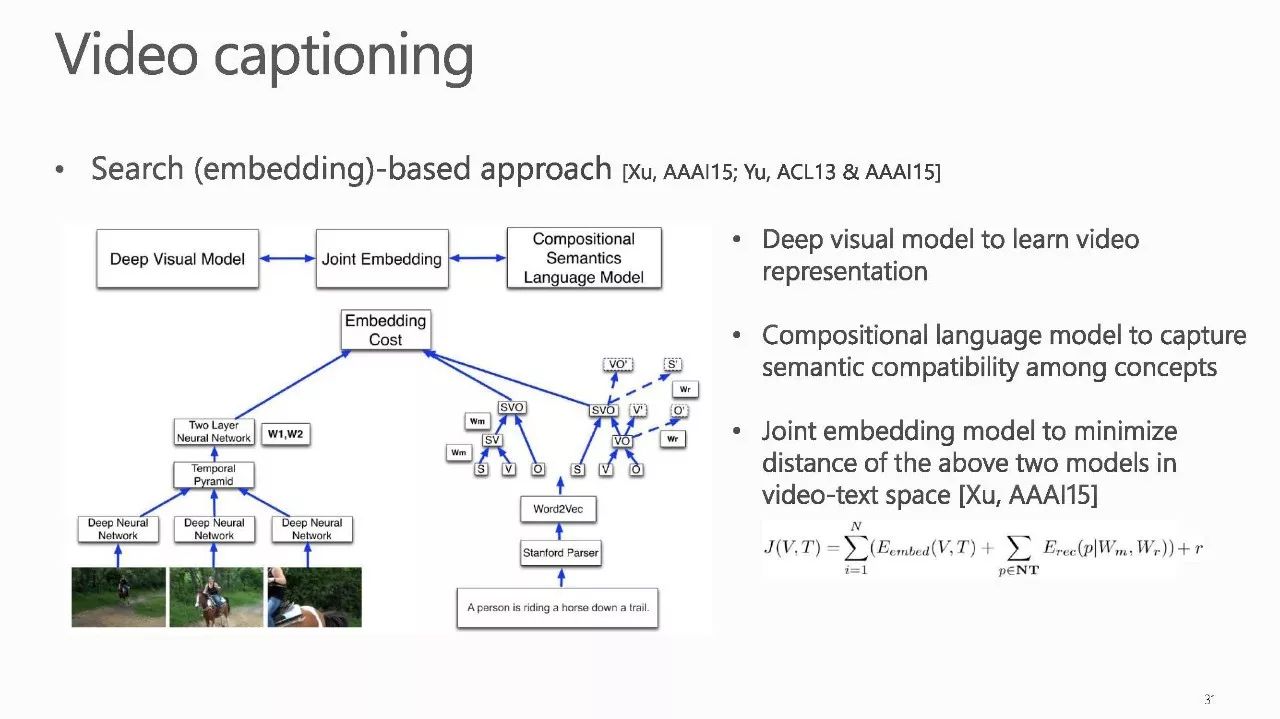

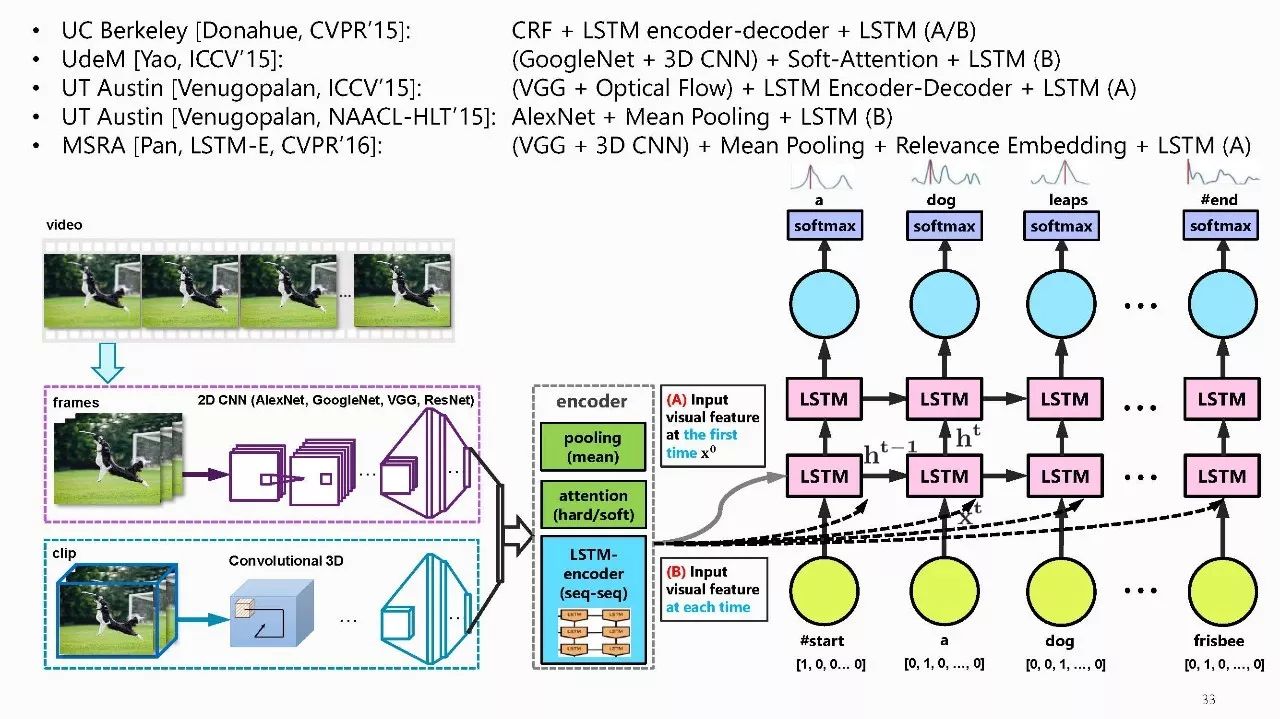



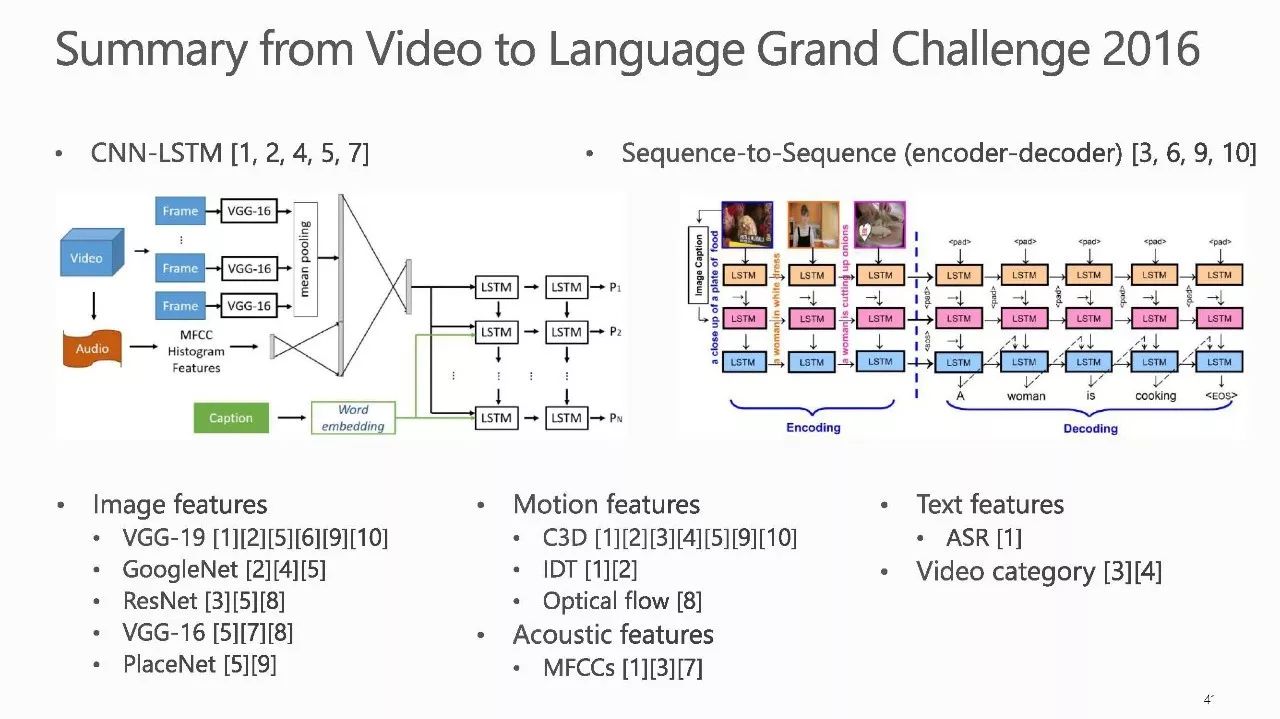
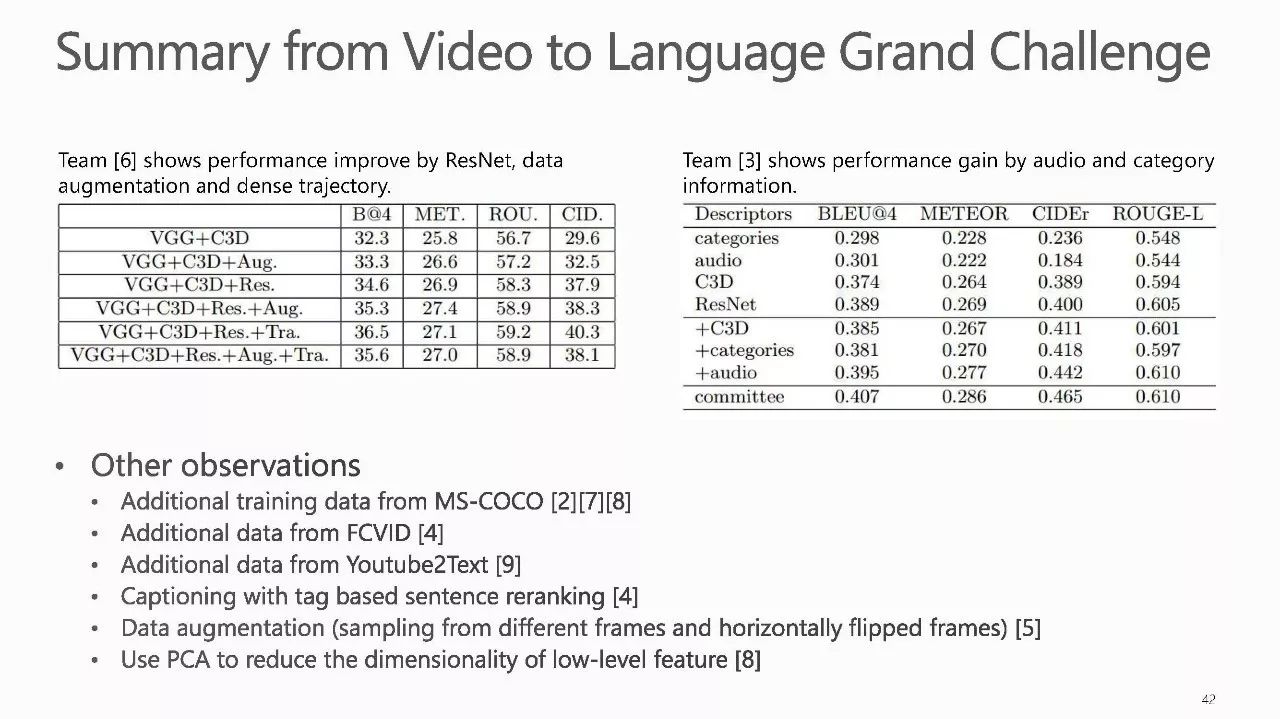




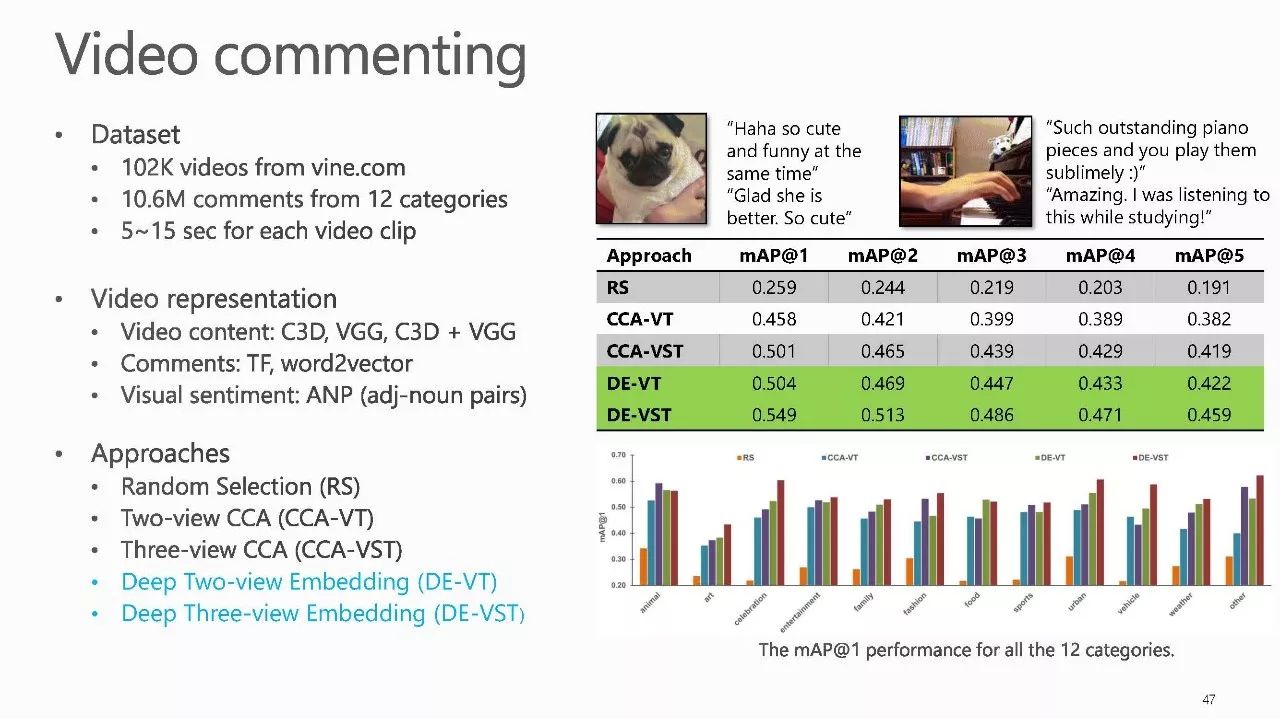





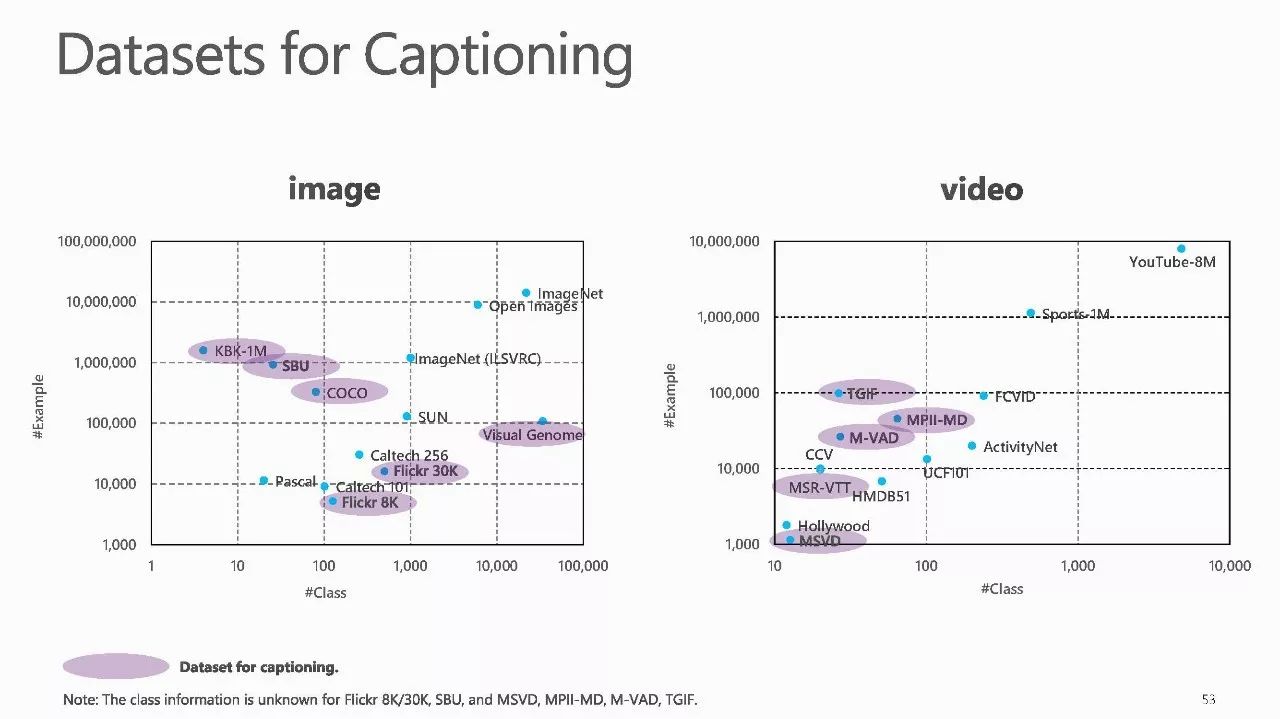







作者介绍:
梅涛,微软亚洲研究院资深研究员,国际模式识别学会会士,美国计算机协会杰出科学家,中国科技大学和中山大学兼职教授博导。主要研究兴趣为多媒体分析、计算机视觉和机器学习,发表论文 100余篇(h-index 42),先后10次荣获最佳论文奖,拥有40余项美国和国际专利(18项授权),其研究成果十余次被成功转化到微软的产品和服务中。他的研究团队目前致力于视频和图像的深度理解、分析和应用。他同时担任 IEEE 和 ACM 多媒体汇刊(IEEE TMM 和 ACM TOMM)以及模式识别(Pattern Recognition)等学术期刊的编委,并且是多个国际多媒体会议(如 ACM Multimedia, IEEE ICME, IEEE MMSP 等)的大会主席和程序委员会主席。他分别于 2001 年和 2006 年在中国科技大学获学士和博士学位。主页:http://research.microsoft.com/en-us/people/tmei/
欢迎使用专知-一体化AI知识服务!点击阅读原文即可访问,访问专知,获取更多人工智能最新资讯、技术、算法、知识等资源。
同时请,关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法等内容。扫一扫下方关注我们的微信公众号。





