【泡泡一分钟】如何在神经网络中嵌入焦距信息从而更好地从单目图像中恢复深度信息
每天一分钟,带你读遍机器人顶级会议文章
标题:Learning Depth from Single Images with Deep
Neural Network Embedding Focal Length
作者:Lei He, Guanghui Wang ,Zhanyi Hu
来源:arXiv 2018.03.27
播音员:申影
编译:杨小育
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——如何在神经网络中嵌入焦距信息从而更好地从单目图像中恢复深度信息,该文章发表在2018 arXiv 上。
从单幅图像中得到深度信息是场景理解中的一个重要问题,在过去的几年中该问题引起了广泛的关注。从条件马尔科夫随机场到非参数方法,再到最近的深度卷积神经网络方法,深度信息估计的准确性得到了大幅度的提升。单个2D图像和恢复出来的3D图像存在着固有的关联性。在本文中,我们首先证明了焦距和深度信息之间的关联性,并通过实验进行了验证,表明焦距对深度信息恢复的准确性有很大影响。
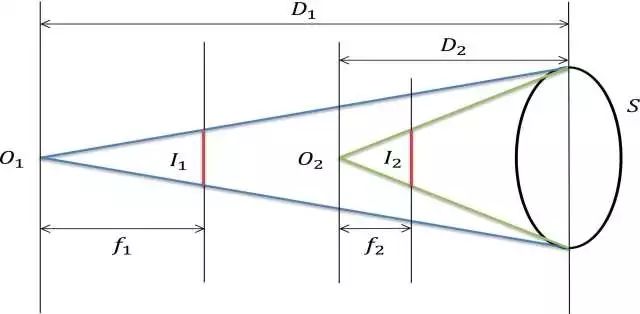
图1 深度信息和焦距之间存在关联性
为了嵌入焦距信息来进行单目图像的深度信息学习,我们提出了一种从固定焦距数据集生成变焦距数据集的方法,并且可以简单有效的填补新生成的图像中的空缺。
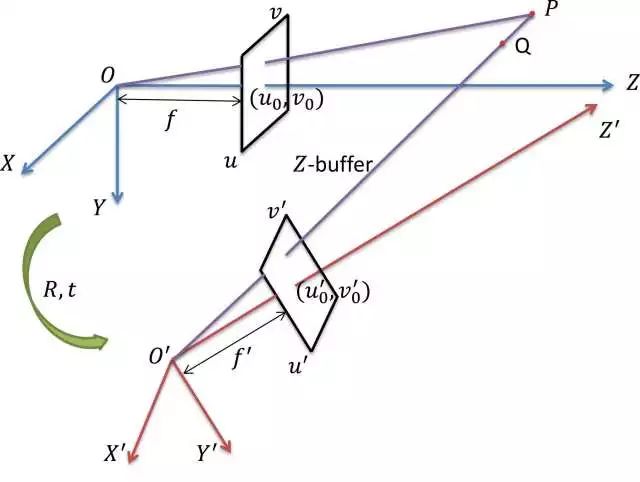
图2 固定焦距数据集和变焦距数据集之间的转换
为了准确地恢复深度信息,我们提出了一种新的深度神经网络来有效融合固定焦距数据集上的中间层信息进行深度信息推断,该方法集胜过了基于预先训练的VGG方法。
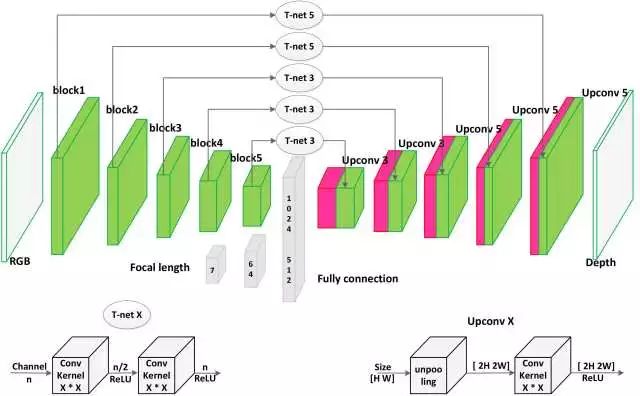
图3 本文提出的神精网络结构
此外,新生成的变焦距数据集作为神经网络学习和推理阶段的输入信息。在固定焦距和变焦距数据集上的大量实验表明,与未嵌入焦距信息的方法相比,嵌入焦距信息的方法可以显著提高图像深度信息恢复的准确性。

图4 NYU v2数据集上的深度预测效果

图5 KITTI数据集上的深度预测效果
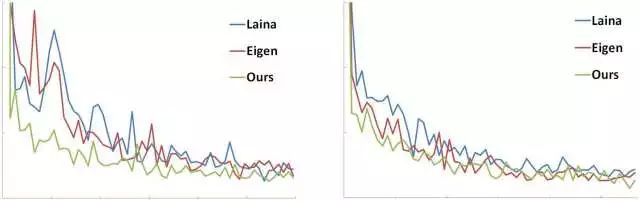
图6 KITTI数据集和NYU v2数据集的训练错误

Abstract
Learning depth from a single image, as an important issue in scene understanding, has attracted a lot of attention in the past decade. The accuracy of the depth estimation has been im-proved from conditional Markov random fields, non-parametric methods, to deep convolutional neural networks most recently. However, there exist inherent ambiguities in recovering 3D from a single 2D image. In this paper, we first prove the ambiguity between the focal length and monocular depth learning, and verify the result using experiments, showing that the focal length has a great influence on accurate depth recovery. In order to learn monocular depth by embedding the focal length, we propose a method to generate synthetic varying-focal-length dataset from fixed-focal-length datasets, and a simple and effective method is implemented to fill the holes in the newly generated images. For the sake of accurate depth recovery, we propose a novel deep neural network to infer depth through effectively fusing the middle-level information on the fixed-focal-length dataset, which outperforms the state-of-the-art methods built on pre-trained VGG. Furthermore, the newly generated varying-focal-length dataset is taken as input to the proposed network in both learning and inference phases. Extensive experiments on the fixed- and varying-focal-length datasets demonstrate that the learned monocular depth with embedded focal length is significantly improved compared to that without embedding the focal length information.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com




