线下沙龙 × 报名 | 呼叫各位CVer,计算机视觉专场来了!

hi,大嘎好~
这里是PaperWeekly的保留曲目——
计算未来轻沙龙
a.k.a.
大型NLPer面基现场
每每看到这类活动预告
很多CVer就会忍不住将手伸向
屏幕左上角的小黑叉

小编更是频频在后台遭受威胁
明明都是炼丹调参
凭什么搞视觉的就不能有姓名
信不信我取关给你看?

为了证明我们对各位CVer的爱
本期“计算未来轻沙龙”
我们集结了来自Hulu、Face++
以及五道口男子职业技术学院
清华大学计算机系的各位CV大佬
为大家奉上一场
计算机视觉与图形学前沿研讨会


谢晓辉 / Hulu首席科学家
谢晓辉,16 年加入 Hulu 并负责 AI 及创新研究工作。曾先后就职于松下电器研究中心、诺基亚研究院、联想核心技术实验室。05 年于北京邮电大学获得模式识别专业的博士学位。拥有 30+ 美欧专利及其它 70+ 专利申请。
视频内容理解在Hulu的应用
视频内容理解是极具挑战性的研究方向,伴随着深度学习技术的快速发展,该领域也受到了越来越多高校、研究机构和公司的关注。作为一家在线视频服务公司,Hulu 较早地启动了该领域的研究工作,在本次报告中,我们将介绍 Hulu 在该领域的相关研发工作,并分享 Hulu 取得的一些阶段性成果。

张祥雨 / Face++研究院基础模型组负责人
张祥雨,2017 年博士毕业于西安交通大学。期间参加微软亚洲研究院联合培养博士生项目,师从孙剑博士和何恺明博士,研究方向包括深度卷积网络设计,深度模型的裁剪与加速等。曾在 CVPR/ICCV/ECCV/NIPS/TPAMI 等顶级会议/期刊上发表论文十余篇,获 CVPR 2016 最佳论文奖,并多次获得顶级视觉竞赛 ImageNet/COCO 冠军。代表作包括 ResNet/ShuffleNet v1/v2 等,Google Scholar 引用数 20000+。现任旷视 Face++ 研究院基础模型组负责人。
高效轻量级深度模型的研究与实践
本次讲座主要围绕实用模型设计的两个常用技术:轻量级模型设计和模型裁剪,重点介绍本团队在高效深度模型领域的科研成果和实践经验。分享内容包括 ShuffleNet v1/v2 系列,以及 Channel Pruning 等研究成果。最后,还将简单介绍模型设计的一些实用案例。

杨晟 / 清华大学计算机系博士生
杨晟,清华大学计算机系五年级在读博士生,主要研究方向为计算机图形学和视觉计算。
基于显著性检测的三维模型重建
在这个 talk 中,我会展示如何利用显著性检测的方法,降低三维重建过程中背景物体对算法的干扰,并提升关键性物体的重建质量。该研究成果已发表于 Pacific Graphics 2017。

段续光 / 清华大学计算机系博士生
段续光,清华大学计算机系博士生在读。研究方向为跨媒体智能分析,主要针对视频和文本进行交叉理解和分析,在国际会议 NIPS 上发表一作论文。
密集视频描述生成 Dense Video Captioning
在跨媒体智能方向,视频-文本方向是一个非常重要的领域,其中视频描述生成通过将视频转换成描述视频内容的文本进行二者的交叉理解。本次报告中,我们将简要介绍视频描述生成的基本方法,并给出我们针对密集视频描述生成给出的解决方案。

报名时间:即日起至 11 月 22 日 24:00
活动时间:11 月 25 日(本周日)13:30 - 16:30

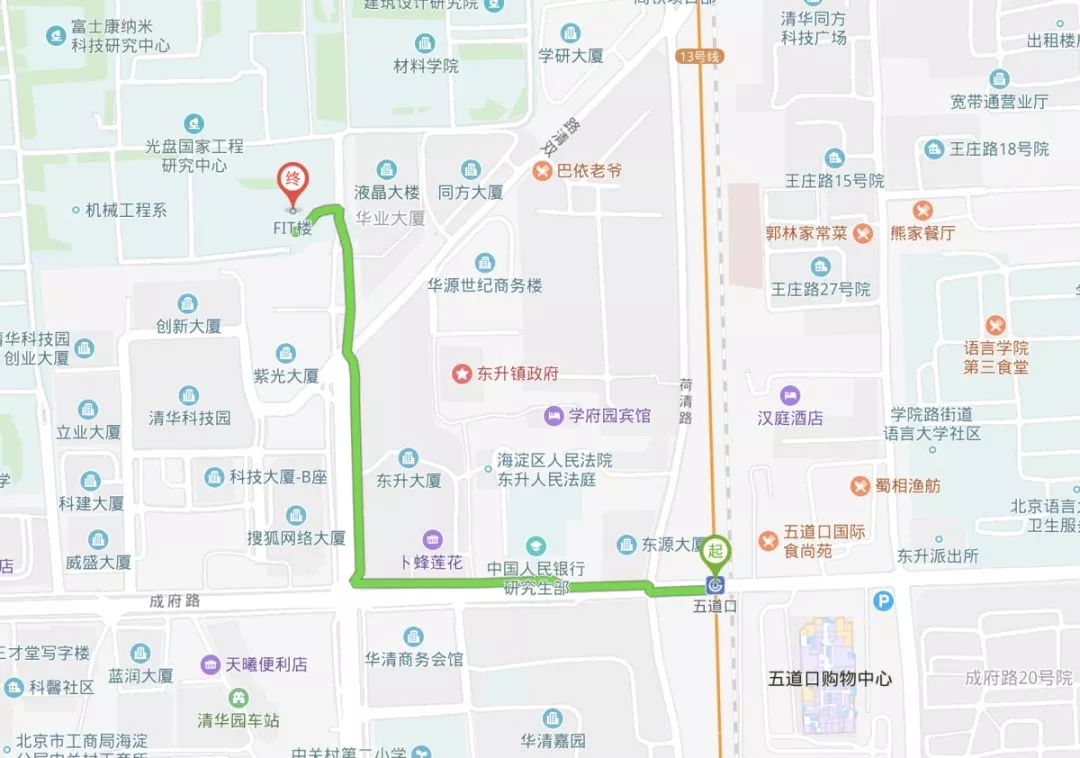
清华大学信息科学技术大楼(FIT楼)二层多功能报告厅,请从 FIT 楼西门进入

1 / 报名方式
长按识别二维码,马上抢占名额!

2 / 活动名额
1. 因场地有限,本次活动仅接受 120 位 用户凭电子门票二维码入场;
2. 为了公平起见,我们将在 11 月 20 日至 11 月 22 日期间,每天 12:30 放出 40 个报名名额;
3. 活动采取审核制报名,我们将根据用户研究方向与当期主题的契合度进行筛选,通过审核的用户将收到包含电子门票二维码的短信通知;
4. 如您无法按时到场参与活动,请于活动开始前 24 小时在 PaperWeekly 微信公众号后台留言告知,留言格式为放弃报名 + 报名电话;无故缺席者,将不再享有后续活动的报名资格。

清华大学计算机科学与技术系

PaperWeekly



🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 立刻报名





