神经网络佛系炼丹手册
作者:高开远
学校:上海交通大学
研究方向:自然语言处理
写在前面
前几天有一篇关于神经网络训练的博文刷屏了,作者是特斯拉AI主管、李飞飞徒弟Andrej Karpathy。看了一眼之后发现跟之前CS231N课上的其中一节主题非常相似,而且在实际coding中也确实非常实用,于是趁着五一没事就再复习总结一遍记录下来,希望对大家也都有帮助吧。
Andrej Karpathy博文链接:A Recipe for Training Neural Networks
Overview
在这篇文章里默认大家都已经熟悉神经网络了,不再深入介绍NN的基础知识了。。下图是全连接的三层神经网络以及相对应的代码
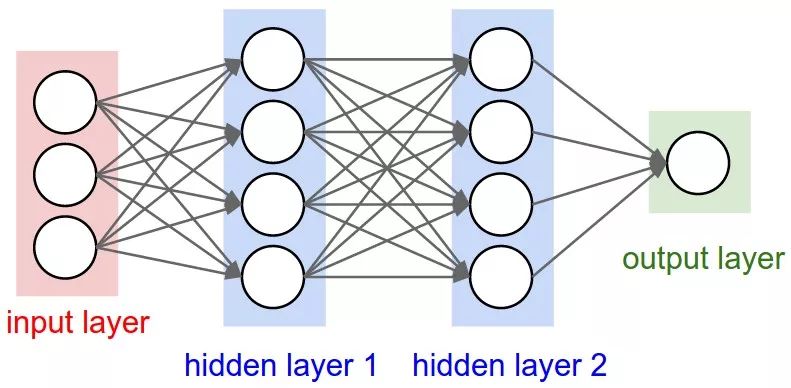
# forward-pass of a 3-layer neural network
f = lambda x: 1.0/(1.0+np.exp(-x)) # activation function
x = np.random.randn(3,1) # input vector [3,1]
W1 = np.random.randn(4, 3) # [4,3]
b1 = np.zeros(4, 1)
W2 = np.random.randn(4, 4)
b2 =np.zeros(4, 1)
W3 = np.random.randn(1, 4)
b3 = np.zeros(1, 1)
h1 = f(np.dot(W1, x) + b1)
h2 = f(np.dot(W2, h1) + b2)
output = np.dot(W3, h2) + b3
下面进入主题,主要侧重点就是关于神经网络实际应用过程中需要注意的一些点:
activation functions
data preprocessing
weight initialization
regularization
gradient check
babysitting the learning process
hyperparameter optimization
model ensembles
……
激活函数选择
参考神经网络中常用激活函数总结,里面涵盖了基本所有流行的常用的神经网络激活函数。
数据预处理
”数据和特征决定了机器学习的上限,而各种模型和算法只是尽可能地去逼近这个上限”
所以我们决定用机器学习的方式来解决问题的第一步就是观察数据,神经网络也不例外。花费时间去探索数据理解数据的分布以及试图找到数据的特征,而不是直接开始coding。有可能你会发现数据集中存在重复的样本;有可能你会发现错误或者损坏的标签(在很多比赛发布的数据集中很常见);有可能你会发现数据是不平衡的…同时在你观察数据的过程中,其实也是你自己在脑子里搭建模型的过程,比如某个任务中local features是否已经足够?图像的空间位置是否需要考虑?等等
对于我们的输入矩阵X(形状为[N x D]),通常有三种常见的数据预处理形式:
Mean subtraction
Normalization
PCA and Whitening


权重初始化
在开始训练神经网络模型之前,我们需要对网络中的权重进行初始化赋值。
不能全零初始化!!!
随机初始化:用很小的数值进行权重初始化,例如
W = 0.01* np.random.randn(D,H),但是这样有一个问题就是数值很小容易导致反向传播过来的值也很小,有可能造成‘gradient vanish’Xavier初始化:神经网络如果保持每层的信息流动是同一方差,那么会更加有利于优化。不过,Xavier Glorot认为还不够,应该增强这个条件,好的初始化应该使得各层的激活值和梯度的方差在传播过程中保持一致,这个被称为Glorot条件。
tf.contrib.layers.xavier_initializer(uniform=True, seed=None, dtype=tf.dtypes.float32)正确初始化最后一层权重:例如你正在处理一个回归问题,输出的平均值为50,那么你就可以初始化最后一层bias为50
Batch Normalization
BN层可以认为是神经网络中的一个和全连接层,卷积层池化层等类似地单独的一层,主要就是加快收敛,减少过拟合,减缓梯度下降等优点。具体可以参考张俊林老师的深度学习中的Normalization模型,非常有用。
正则化
正则化的目的就不用讲了吧。
L2正则
L1正则
Elastic net (L1 + L2)
Dropout:Dropout: A Simple Way to Prevent Neural Networks from Overfitting
获取更多的数据:data augment
更小的输入维度:把那些包含冗杂信息的特征丢弃
更小的模型:
减小batch size
权重衰减:
early stop:
监控训练过程
在训练神经网络的过程中,通常我们需要观察一些衡量模型效果的变量。
loss function
观察训练过程中的loss值可以让我们跟踪模型的效果

train/val accuracy
通过观察对比训练/验证集上的准确率可以发现模型是否过拟合

超参数优化
神经网络模型中有许多超参数设置,比如:初始学习率、学习率衰减方案、正则化系数等。
Implementation:worker and master
使用一份验证集而不是交叉验证(cv)
超参数范围:在对数尺度上进行超参数搜索
尽量使用随机优化而不是网格优化:Random Search for Hyper-Parameter Optimization
从粗到细分阶段搜索
贝叶斯差参数最优化
模型集成
在实践的时候,有一个总是能提升神经网络几个百分点准确率的办法,就是在训练的时候训练几个独立的模型,然后在测试的时候平均它们预测结果。集成的模型数量增加,算法的结果也单调提升(但提升效果越来越少)。还有模型之间的差异度越大,提升效果可能越好。进行集成有以下几种方法:
同一个模型,不同的初始化:使用交叉验证来确定最好的模型超参数,然后使用这些超参数训练不同随机初始化的模型
在交叉验证在获得的效果最好的模型 :使用交叉验证来得到最好的超参数,然后取其中最好的几个(比如10个)模型来进行集成。
同一个模型的不同记录点:如果训练非常耗时,那就在不同的训练时间对网络留下记录点(比如每个周期结束),然后用它们来进行模型集成。
使用参数的平均值:和上面一点相关的,还有一个也能得到1-2个百分点的提升的小代价方法,这个方法就是在训练过程中,如果损失值相较于前一次权重出现指数下降时,就在内存中对网络的权重进行一个备份。这样你就对前几次循环中的网络状态进行了平均。你会发现这个“平滑”过的版本的权重总是能得到更少的误差。直观的理解就是目标函数是一个碗状的,你的网络在这个周围跳跃,所以对它们平均一下,就更可能跳到中心去。
点击'阅读原文'直达原文链接,欢迎投稿,AI、NLP均可。



