如何为从 1 到 10 万用户的应用程序,设计不同的扩展方案?

通常来说,这种情况的解决方案要么是来自突然爆发的紧急事件,要么是系统出现瓶颈进行升级改造。虽然方式不同,但是我们也发现了,一个边缘项目发展成高度可扩展项目,其升级方案是有一些普适的“公式”可以套用,本文以 Graminsta 为例,为大家介绍当用户从 1 位发展到 10 万,应用程序如何扩展?
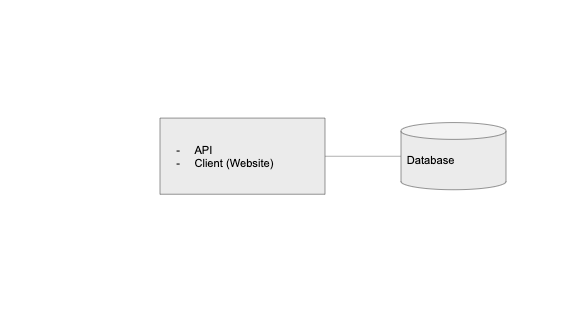
无论是网站还是移动应用,应用程序几乎都包括这三个关键组件:API、数据库和客户端,其中数据库用来存储持久数据,API 服务于数据及与其有关的请求,而客户端负责将数据呈现给用户。
在现代应用程序开发中,客户端往往会被视为一个独立于 API 的实体,这样一来就可以更轻松地扩展应用程序了。
当刚开始构建应用程序时,可以让这三个组件都运行在一个服务器上,类似于我们的开发环境,一位工程师在同一台计算机上运行数据库、API 和客户端。
当然,理论上我们可以把它部署到云上的单个 DigitalOcean Droplet 或 AWS EC2 实例上,如下所示:

但是,当我们的用户未来不止 1 个的时候,其实刚开始就应该考虑是否要将数据层拆分出来。
拆分数据层,并将其作为一个类似于 Amazon 的 RDS 或 Digital Ocean 的托管数据库的托管服务。这样做的话,虽然成本会比在一台机器上或 EC2 实例上自托管高一些,但是我们可以获得很多现成且方便的东西,例如多区域冗余、只读副本、自动备份等等。
Graminsta 现在的系统如下所示:
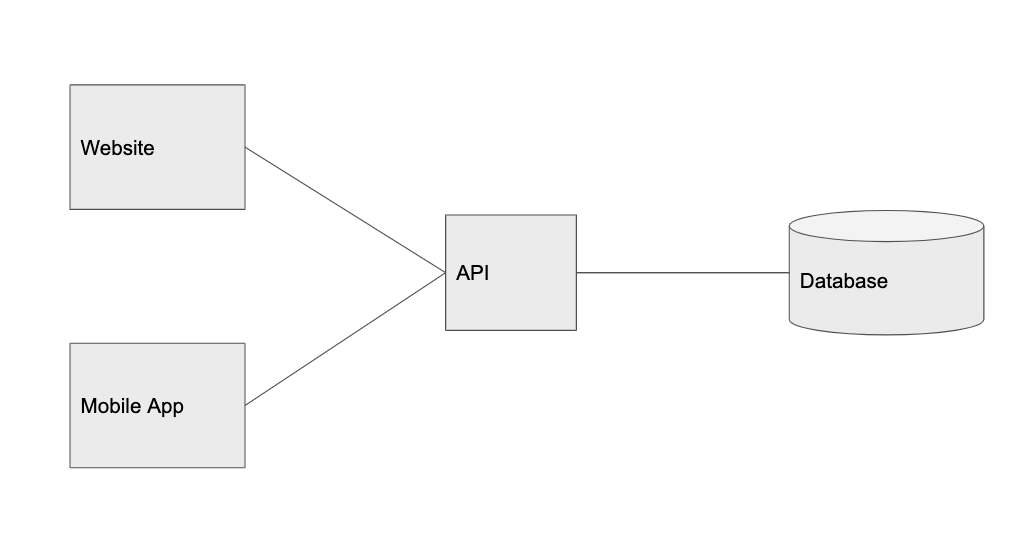
当网站流量变得稳定之后,就到了拆分客户端的时候了。
需要注意的是,拆分实体是构建可扩展应用程序的关键所在。当系统中的某一部分获得了更多流量,那么就应该把它拆分出来,根据其自身的特定流量模式来处理服务的扩展。这也是我会把客户端和 API 看作是相互独立的组件的原因,这样,我们就可以轻松为多平台构建产品,例如 web、移动 web、iOS、Android、桌面应用、第三方服务等,它们都是使用相同 API 的客户端。
现在,Graminsta 的系统如下所示:
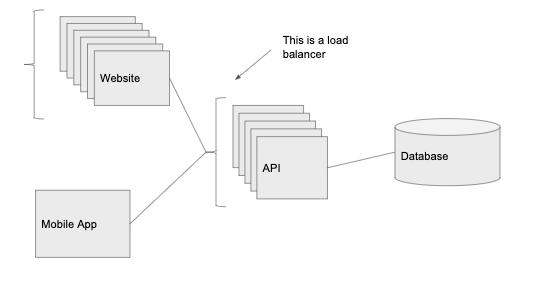
当新用户越来越多,如果只有一个 API 实例可能满意满足所有的流量,这时我们需要更多的计算能力。
这时,负载均衡器该上场了,我们在 API 前面添加一个负载均衡器,它会把流量路由到该服务的一个实例上,我们就可以进行水平扩展(通过添加更多运行相同代码的服务器来增加可以处理的请求数量)。
我们在 web 端和 API 前面添加了一个独立的负载均衡器,这意味着我们拥有了多个运行 API 和 web 客户端代码的实例。该负载均衡器会把请求路由到任何一个流量最小的实例上。并且,我们还可以从中得到冗余,当一个实例宕机(过载或崩溃)时,其他实例还可以继续运行,响应传入的请求,而不是整个系统宕机。
负载均衡器还支持自动扩展,在流量高峰时可以增加实例的数量,当流量低谷时,减少实例数量。借助负载均衡器,API 层实际上可以无限扩展,如果请求增加,我们只需要不断增加实例就可以了。
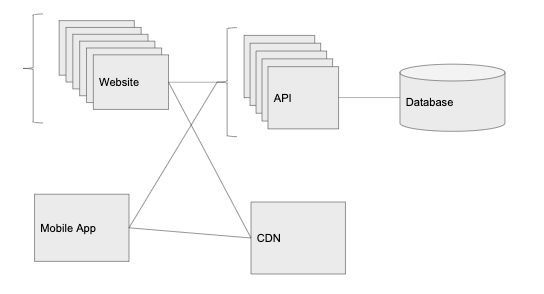
编者注:到目前为止,我们拥有的产品和 PaaS 公司(如 Heroku 或 AWS 的 Elastic Beanstalk)提供的开箱即用产品非常类似。Heroku 把数据库托管在单独的主机上,用自动扩展来管理负载均衡器,并允许我们把 API 和 web 客户端分开托管。对于早期初创企业来说,使用 Heroku 等服务来做项目是一个不错的选择,所有必需的、基本的东西都是开箱即用。
对于 Graminsta 来说,处理和上传图像为服务器带来了很大的负担。所以,Graminsta 选择了使用云存储服务来托管静态内容,例如图像、视频等(AWS 的 S3 或 Digital Ocean 的 Spaces),而 API 应该避免图像处理和图像等业务。
另外,使用云存储服务,我们还可以使用 CDN,可以在遍布全球不同的数据中心自动缓存图像。我们的主数据中心可能托管在
我们从云存储服务得到的另一样东西是 CDN(在 AWS,这是一个被称为 Cloudfront 的插件,但是很多云存储服务都以开箱即用的方式提供它)。CDN 将在遍布全球不同的数据中心自动缓存我们的图像。
虽然我们的主数据中心可能托管在俄亥俄州,如果有人在日本对图像发出了请求,那么云供应商就会进行复制,将其存储在位于日本的数据中心,下一个请求该图像的日本用户就会很快收到图像。
负载均衡器在环境中添加了 10 个 API 实例,使得 API 的 CPU 和内存消耗都很低,CDN 帮助我们解决了世界各地图像请求的问题。但是现在,我们有一个问题需要解决,那就是请求延迟。
通过研究,我们发现数据库 CPU 的消耗占比达到了 80%-90%,因此扩展数据层成为了当务之急。数据层的扩展是一件很棘手的事情,虽然对于服务无状态请求的 API 服务器来说,只需要添加更多实例即可,但是对于大多数数据库系统来说,却不是这样。
要从数据库获得更多信息的最简单方法之一是给系统引入一个新的组件:缓存层。实现缓存最常用的方法是使用内存中的键值存储(如 Redis 或 Memcached),且大多数云厂商都会提供数据库服务的托管版本。
当该服务正在进行对数据库相同信息的大量重复调用时,就是缓存大显身手的时候了。当我们访问数据库一次时,缓存就会保存信息,之后再进行相同请求时,就不必再访问数据库了。
例如,如果有人想在 Graminsta 中访问 Mavid Mobrick 的个人资料页面时,我们把从数据库中得到的结果,缓存在 Redis 中关键字 user:id 下,到期时间为 30 秒。之后,每当有人访问 Mavid Mobrick 的个人资料时,我们会首先查看 Redis,如果存在相关资料,那就直接从 Redis 提供数据。
大多数缓存服务的另一个优点是,与数据库相比,更容易扩展。Redis 有个内建的 Redis 集群(Redis Cluster)模式,用的是跟负载均衡器类似的方式,可以把我们的 Redis 缓存分布到多台机器上 。
所有高度扩展的应用程序几乎都充分利用了缓存的优势,缓存是构建快速 API 不可或缺的部分,可以提供更好的查询和更高效的代码,如果没有缓存,我们可能很难扩展到数百万用户的规模。
由于对数据库的访问相当多,因此我们需要在数据库管理系统来添加只读副本。借助上面提到的托管服务,只需要点击一下就可以完成。只读副本将和主数据库保持一致,并且能够用于 SELECT 语句。
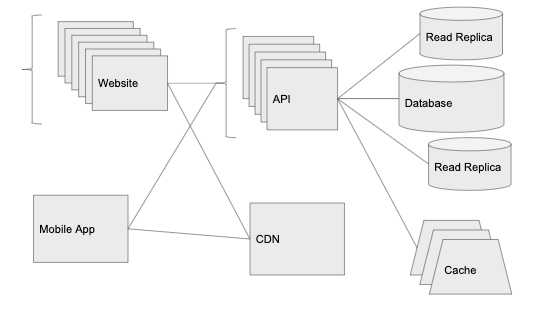
随着应用的不断扩展,我们会把重点放在拆分独立扩展的服务。例如,如果我们使用了 websockets,那么会把 websockets 处理代码抽取出来,放在新的实例上,同时安装负载均衡器。该负载均衡器可以根据 websocket 连接打开或关闭的数量来上下扩展,与我们收到的 HTTP 请求数量无关。
如果未来还会遇到数据层的限制,我们就会对数据库进行分区和分片。
我们会使用 New Relic 或 Datadog 等服务安装监控程序,并通过监控程序发现比较慢的请求,改进它。同时,随着扩展的不断进行,我们希望能够发现更多的瓶颈并解决它。
扩展阅读
https://alexpareto.com/scalability/systems/2020/02/03/scaling-100k.html
InfoQ Pro 是 InfoQ 专为技术早期开拓者和乐于钻研的技术探险者打造的专业媒体服务平台。
InfoQ Pro 推出新人福利,扫描下方二维码关注 InfoQ Pro,回复”资料“,即可免费获得InfoQ全套迷你书,机会难得,快来领取吧!






