人工智能落地案例:优酷泛内容智能分析平台建设实践

注:本文整理自优酷高级总监,阿里资深技术专家蔡龙军(牧己)在 QCon 2017 上海站上的演讲,原题为:《面向未来的泛内容智能分析平台建设实践》。

这一页 PPT 上面是现在互联网产业最具有代表性的一些火爆内容,第一个《大军师司马懿之军师联盟》,我们做了一下受众分析,发现这个片子的主要受众是男性高知群体。我们分析了一下原因,首先《三国演义》男性喜欢看,还有一个原因就是这个历史正剧,对女性观众而言,颜色服饰容易脸盲。第二部片子,《白夜追凶》,近年来刑侦题材里面一部非常好的片子。
接下来三部片子,《十里春风不如你》、《三生三世十里桃花》、《微微一笑很倾城》,代表了中国 7 亿主流观众人群的观看偏好,价值都在一百到两百亿流量。剩下这两部片子不重点介绍了,一个叫《人民的名义》,这个片子应该都看过,一个动作片,放在最下面的这个《战狼 2》,中国电影票房的新记录保持者,57 亿票房。回归到今天的话题,类型化发展趋势对于整个中国互联网产业带来何种影响呢?
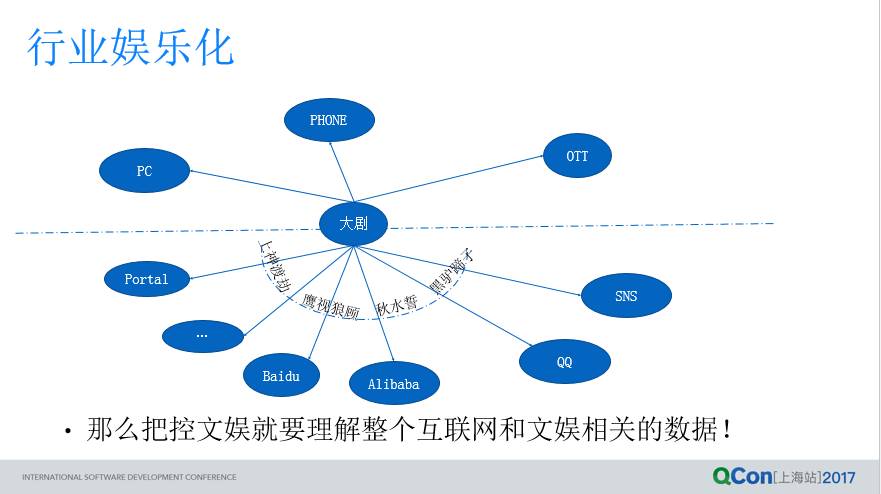
总结起来,整个产业的发展趋势是:互联网产业在娱乐化进程中,内容类型化提供了大量丰富的精品内容,这些精品化的内容背后,大量进入很多垂类的应用使用,给整个产业带来了一个娱乐化很有力的推动作用。举几个例子,《三生三世》来了之后,大量的“生祭东皇钟”、“渡劫飞升上神”进入垂类应用,而到了盗墓笔记的时候,“粽子”、“黑驴蹄子”比比皆是,更有意思的是黑猪蹄子上淘宝还有的卖,这也算得上一种文娱产业的衍生品了;无论从各个端口,手机,大屏,还是从各个垂直应用,都在大量地传播这些内容。整个行业娱乐化对内容产业本身是一个什么样的作用呢?
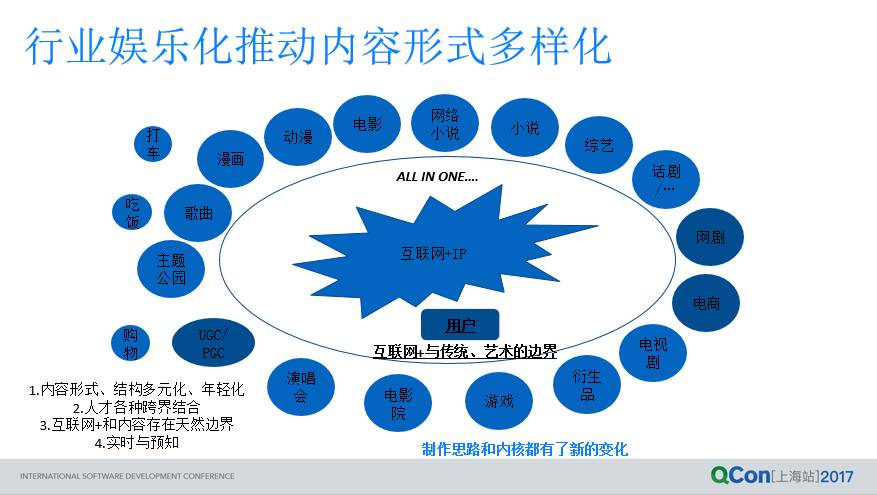
一句话来总结,行业娱乐化的进程推进了内容产业形式的多样化,比如说《三生三世》一出来,电视剧有了,电影有了,还有那些衍生品有了,还有那些好多年大家没看过的文学作品又挖出来看了一遍;这种形式多样化趋势和别的国家发展进程还是有区别的,某种程度上来讲这些形式多样化的内容前所未有。
好莱坞发展那么多年,在建设它的整个内容的发行的垂直体系,它从文学的 IP,慢慢演化成影视,电视剧,然后再到后面的衍生品、主题公园花了好多年,我们今天一下子就都涌过来了。今天对我们来说最大的挑战,第一内容类型化,走精品化的路线;第二进入垂直领域推动整个行业娱乐化发展,反过来这些娱乐化的内容形式相互作用相互影响,这些相互作用的因素对创作内核又发生了一定的影响,对于整个产业制造内核都在发生改变。
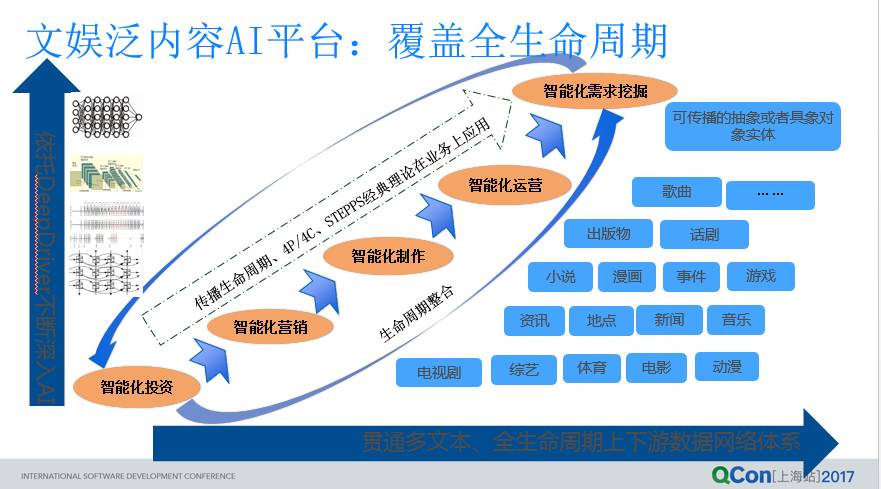
基于上面的挑战,我们想到了建设文娱泛内容 AI 平台的想法,文娱泛内容 AI 平台的基本建设思路是建立一套面向未来的三维立体分析平台,去覆盖整个内容生命周期的各个环节,三维立体分析平台包括三个轴,x 轴,y 轴,z 轴。X 轴是之前主要介绍的部分,要理解内容,需要知道内容的形式、特点,结合内容本身的生命周期,然后建立这个数据体系,对于人工智能现在发展现状而言,数据作为一种先验的知识可以提前进入。
第二个维度就是在人工智能很蓬勃之下,我们以 Y 轴建立一个人工智能学习、挖掘学习平台 DeepDriver,以 DeepDriver 为基础设施,建立它的上层的模型,基于这样的 Model 来去支撑在 Z 轴上在内容整个发展生命周期中涉及到的投资、采购、营销、运营、商业化等,以及后面的更多的业务形式和形态。今天我们没办法用一个人工智能一下子解决一个完美的问题,但是我们可以通过融合多种技术和数据,提供一个更高层面的解决方案。
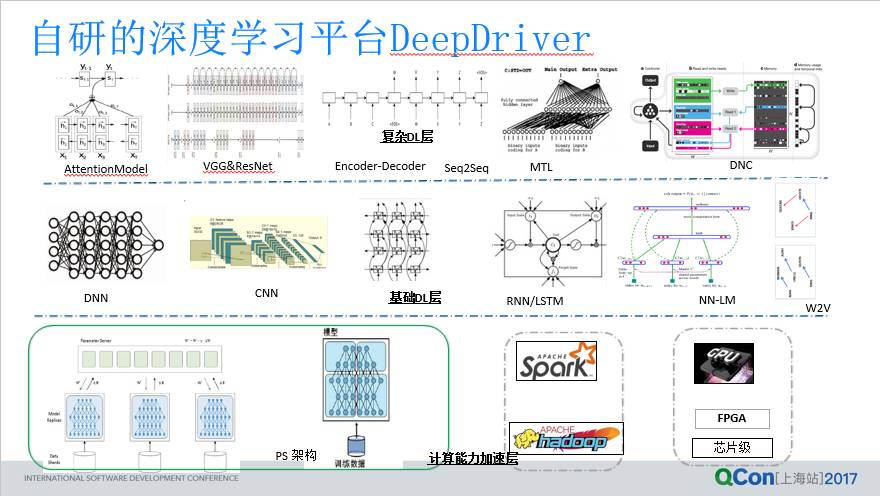
下面介绍一下我们在过去的几年当中,建立的这个自主研发的这个深度学习平台 DeepDriver。我们把它分成三层,第一个,最下面那层叫模型加速层,也就是我们如何用硬件的计算资源,提供上面的计算能力;第二层叫基础模型层,第三层叫复杂模型层。
下面一一来介绍,用计算资源来支撑上面的计算能力,经典的就是两种做法,一种集中式的用芯片,用 GPU。第二种方式是,我们用分布式的方式,分布式方式可以基于 Spark/Hadoop 的架构,也可以基于 Prarameter Server 架构。基于分布式架构又包括两种形式,一种叫数据分布式,一种叫模型分布式,由此构成我们底层的一个模型加速层。
第二层是技术模型层,这块就是目前主流的 ANN、DNN、CNN、RNN,LSTM,然后还有一些 W2V 等等。最上面一层叫做复杂模型层,是下面这个基础模型层的一些变种,例如 Resnet 等,或者其他模型的拼接,例如 Seq2Seq 模型就是两个 LSTM 结合的。以及还有一些其他的更复杂的模型,都统一放在这一层。
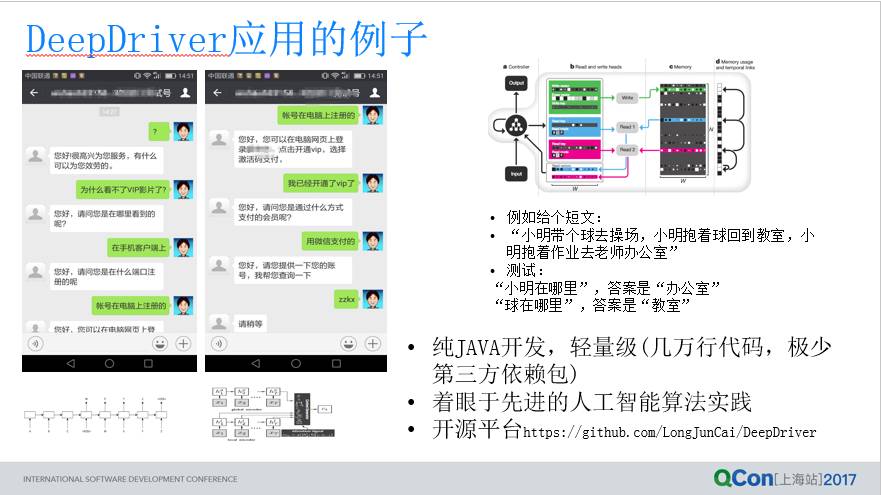
再介绍下两个小例子,以对 DeepDriver 有个更介绍清楚。从第一行代码开始写,第一篇论文开始读,开发了一个纯 Java 的深度学习平台, Java 工程师想做深度学习,DeepDriver 是个不错的选择,在编写过程中很少使用第三方,它整个代码也只有几万行,跑起来也比较轻量级。
我们有同事跟 TensorFlow 做一个对比,用的是后面会介绍有一个基于 CNN 的情感分析的网络,用 DeepDriver 跑的硬件的需求要比 TensorFlow 低。另外,DeepDriver 要尝试把这个行业先进的一些算法模型集成过来,应用到我们的产业进行落地,所以它目标不是要做整个行业人工智能基础设施,我们希望把最先进的一些模型快速落地,基于这两个思路。有两个例子,一个例子是典型的 NLP 生成模型的例子,我们把客服的数据灌进去,然后学,学一段时间之后基本上能做到今天这个样子:
我:我说我看不了会员了。
机器:在哪个端看不到会员了?
我:在手机端
机器:他说你在哪注册的?
我:在电脑上注册的。
机器:购买会员的流程是这样的…
我: 已经买了
机器:你把帐号给我。
…..训练后的模型能够根据你问问题的整个过程进行应答,这是去年开始流行的生成式模型。这个模型背后实现是 Seq2Seq 模型,用两个 LSTM 进行实现,左边的 LSTM 做 Encoder,右边的 LSTM 做 Decoder,中间用 Attention Model 进行整合。
第二个例子,我想介绍一下 DNC 模型,神经网络计算机,它的前身叫 NTM,叫神经网络图灵机,是 DeepMind 公司的另外一个作品, 16 年 DeepMind 的 CEO 认为他们公司两个最了不起的一个成果,第一个是阿尔法狗,大家都知道,第二个是 DNC,这个是 16 年 10 月份的一篇论文发在 Nature 上研究成果,很基础的一个元件,基础架构就是尝试建立一个计算机,包括内存、控制器,以及读头和写头,整个过程是用神经网络去实现的,通过这种方式去达到整个过程都是可学习的。
下面例子是 Babi Test 的例子“小明去上学,小明球场踢足球,小明回教室,小明拿着作业去老师办公室”问“小明在哪里,球在哪里”,回答这样的问题,今天用这个模型去学的能把它学的非常准确,答案都能答对,基于这两个例子来让大家对这个平台有些了解,大家有感兴趣的我们可以多多交流,希望更多的人能去学习应用这个实行。
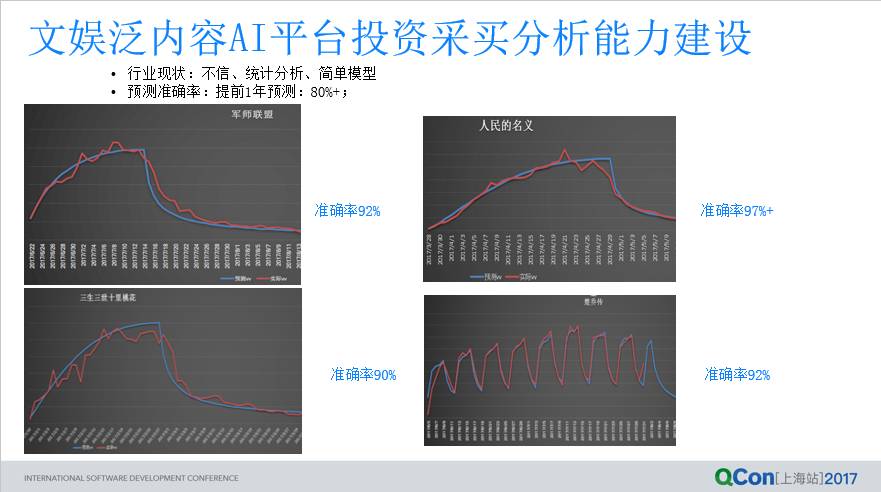
这部分,介绍下基于泛内容 AI 平台做的投资采购,和营销运营分析功能。投资采购这块,内容采买之前都会做一下流量预测,用深度学习去做流量预测这个事情,能做到行业最好的预测,准确率能达到超过 80% 以上,例如《三生三世》,《军师联盟》这几个片子准确率都还不错。
常规的学习模型和思路,不管是深度神经网络还是简单的线性模型,都是基于已有的数据,然后用这个模型去逼近要预测的事情的事实和真相。今天在用深度学习或者别的模型去做这些事情的时候,常逼近真相的过程当中,很容易把一些不是那么本质的特征抓出来,结果模型预测的准确率看起来很高,但实际上已经偏离了,机器学习力叫过拟合或泛化能力不行,所以在这种情况下,我们是觉得这个直接走这个思路是比较难走通的。
理论上模型能做到,跟实践中能找到这个模型做到是两码事。我们换了个思路尝试了一下,预测这个事为什么这么困难?举三个例子,第一个例子是股票的例子,我们说这个股票是有代表性的,一家公司的股票往上走,往下行,它都有一个发展过程,发展过程会有一些符合自己的发展规律,有一些符合自己的生命周期。第二个,很多待预测个体间具有竞争的博弈关系,第三个,很多待预测事物内部由很多多变的因素构成。
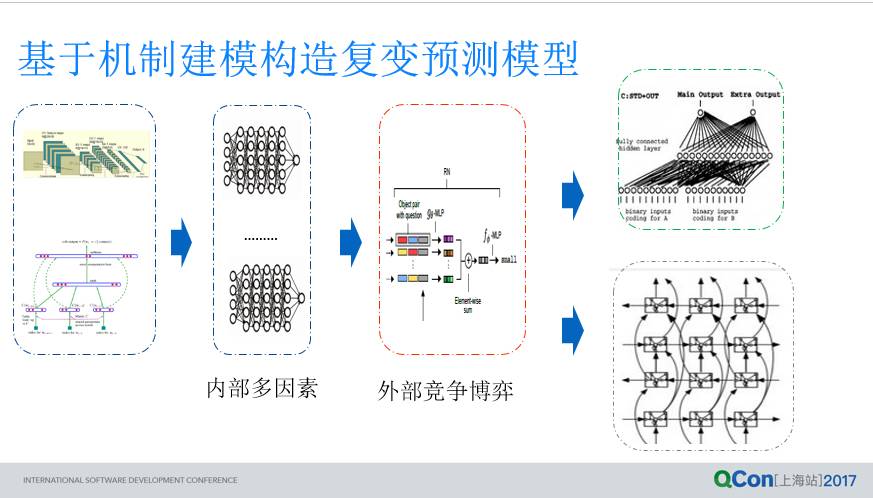
所以我们尝试把预测这个问题通过分层来解决,通过分层模型对各个主要特点分别进行建模,来降低单个模型一下达到预测的难度。分层解决这个思路就是把数据先用神经网络,自然语言模型做 Embedding,Embedding 后变成可量化的数据,然后是通过那几部分进行建模,对于内部因素,我们用一个 DNN 去逼近它;对于刚才介绍的具有外部竞争的博弈的关系的竞争对象,用了一个推理 (RelationNet) 网络,推理网络是 17 年四五月份最新的一个成果,然后在图像里面应用的,我们拿过来做竞争关系使用;然后还有一个经典模型 LSTM,通过 LSTM 对整个生命周期进行建模;对于不能抓住问题本质这块,我们通过 MTL 进行建模,MTL 可以在同时预测多任务过程中进行多维度预测,在这个过程中通过不同的任务进行预测,从而增加了噪音提高预测的精准度。
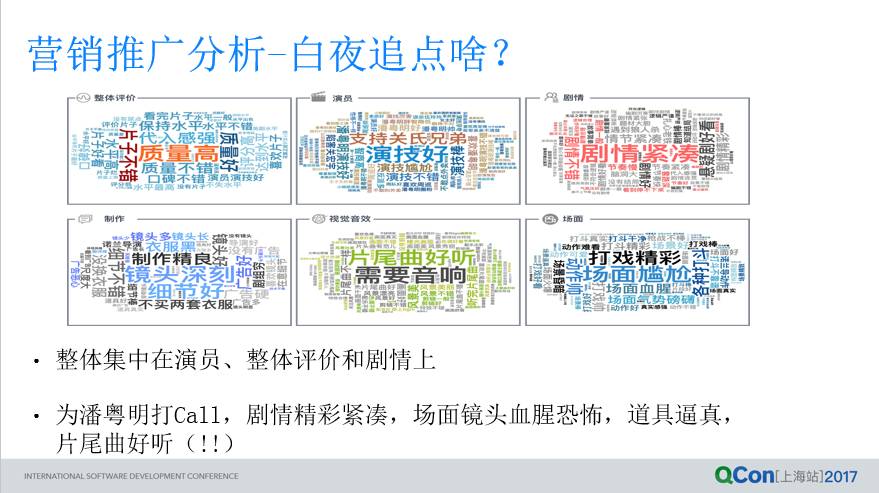
举一个例子,白夜追凶这个剧。首先看一下白夜追凶大家喜欢什么,我们把这个数据拉出来一看,然后我们把它整个拆成剧情、整体、演员、导演、特效、音效等多个主题,用户到底喜欢这个剧的哪方面。根据数据发现用户喜欢这个剧的剧情紧凑、环环相扣,喜欢这个演员双胞胎无缝切换、演技好,根据分析的结果,我们在营销推广上就不用特别的担心特效其他负面影响,所以给整个团队的一个信心,大家更关心的是哥哥弟弟这个片子演的角色,里面的一些剧情推理的东西,我们就可以在营销活动、物料里,持续对用户感兴趣的这些地方进行一些调整和支持这样的一些工作。
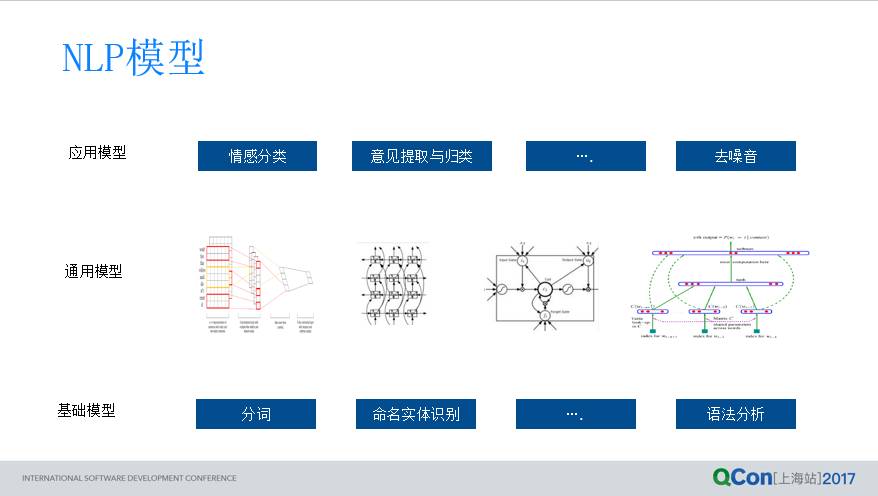
这个背后怎么做?很简单,自然语言模型的东西,我们今天尽量想把它简化,把它划分成三个阶段,三个部分,第一部分,底层的一个基础,分词,词性标注,命名识别,以及这个语法的一些东西。第二部分,我们说是通用模型,通用模型 CNN,LSTM 这些东西。
基于这样通用模型跟底层的这些模型,上面我们有一些应用的模型,我们要解决情感分类,不相关,区属等等,我们要做很多这样的应用。
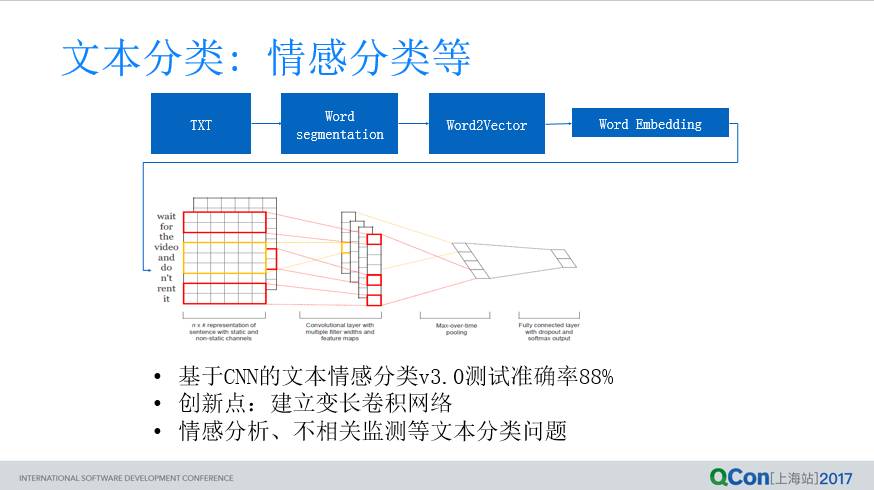
我们以文本分类为例子,用 CDN 去做情感分类效果挺好,先介绍一下做法: 先对文本进行分词,然后再对每个词做 Embedding,从而使得这些词就完成了向量化,然后再把这些词按句子里出现顺序组合到一起变成一个矩阵,数字化矩阵就像一张图,再用一个 CNN 去卷积,卷积之后再对内容进行一个 Pooling 的过程,对 Pooling 完的结果再做一个全连接,全连接完了就预测分类,这种文本分类,可以用在情感分类,用户关心的剧情、特效、演员等,应用特别广。
之前的模型都是基于词典的处理方式,根据词的极性和否定词等来判断情感。互联网用户,经常说的一句话叫做,“大家都说这个片子很好,我就呵呵了”,就是里面一个负向词都没有,常规的模型是解决不了的,因为这里面的“呵呵”词性根据上下文也发生了一些改变,所以用这种方式之后,它会把这个前后这种依赖关系给选出来,这种方式我们做了一下,这个准确率能做到 88 分。
总结一下,今天总共给大家介绍了几部分,第一部分介绍了整个行业,文娱产业的内容发展的趋势类型化,类型化推动了整个产业娱乐化,产业娱乐化进程反过来作用,使的内容产业的生产方式、运作方式、营销方式都发生了一些改变,那对更好把握这些层面提出了很多挑战,我们建了今天的文娱泛内容 AI 平台,基于这样一个文娱泛内容 AI 平台,我们重点介绍了一下建立自主研发的深度学习平台 DeepDrvier,然后介绍了投资、营销、运营领域做了一些人工智能实践。
最后展望一下,今天整个产业技术领域都有非常快速的发展,这些发展趋势对整个产业是个巨大的推动力,每一次人工智能技术革命的发展,都会让模型更准确,只要结合领域的痛点,就可以在有限的技术条件下,把这个产业推向一个更好的发展!谢谢大家。今天我的汇报就到这。
作者介绍

蔡龙军(牧己),硕士毕业于北京交通大学,曾在 IBM 等多家知名企业工作,主导研发了开源深度学习平台 DeepDriver,并基于该平台在图像、NLP,以及对话、预测等领域都有深入的应用。主导研发了行业领先的大数据内容生命周期三维立体分析平台,是国内外领先的视频行业的智能大数据驱动运营分析应用,并由此受邀在中国计算机学会大数据论坛等学术交流会进行了成果分享,受到广泛好评和反响;也曾主导企业的国家 863 人工智能基础平台项目的申请,并完成了企业内部的人工智能体系规划。对大数据和人工智能技术有着信仰般的热情,欢迎多多沟通、交流。
今日荐文
点击下方图片即可阅读

第一次全国程序员人口普查
极客时间 App 已在苹果商店上线,点击 阅读原文 即刻下载!
安卓版正在吐血研发中,敬请期待!




