综述 | 基于2.5/3D的室内场景理解
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
主要内容
介绍

数据表示
核心技术
1、Convolutional Neural Networks

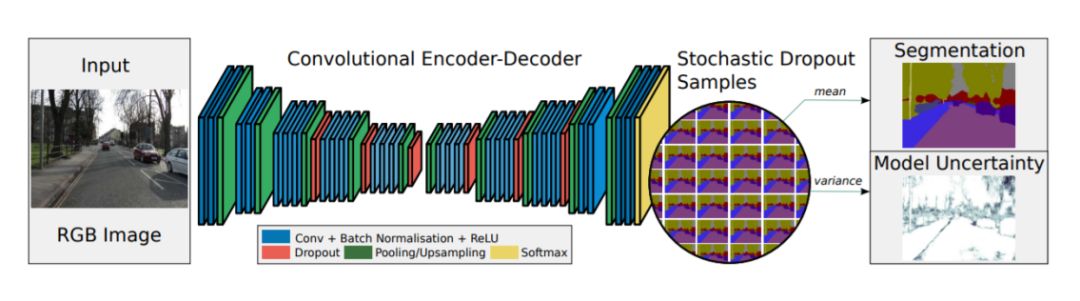
2、Recurrent Neural Networks
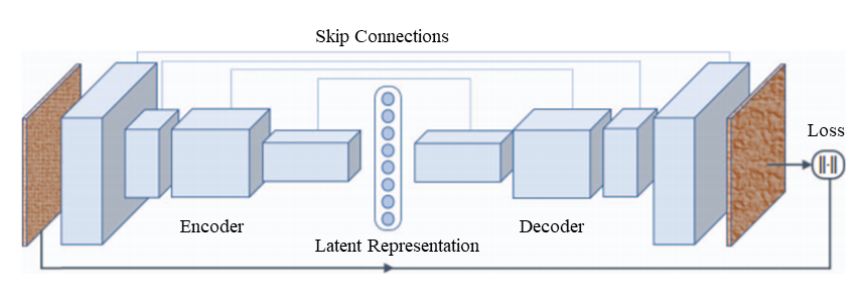
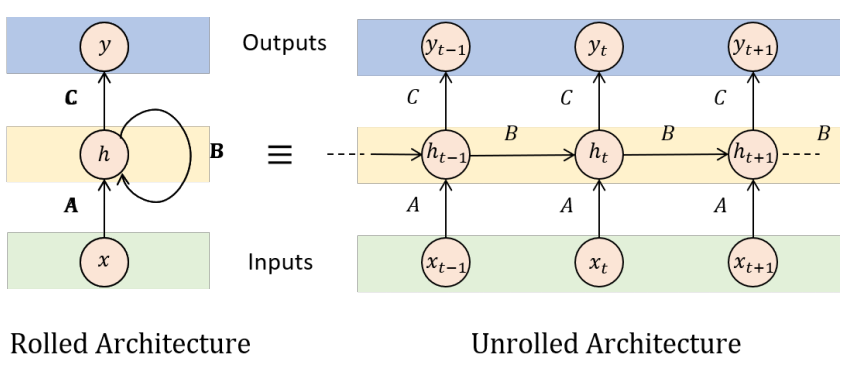
3、Encoder-Decoder Architectures

4、马尔可夫随机场(Markov Random Field)
5、Sparse Coding(稀疏编码)

6、Decision Forests
7、Support Vector Machines
主要的一些问题
1、Image Classification
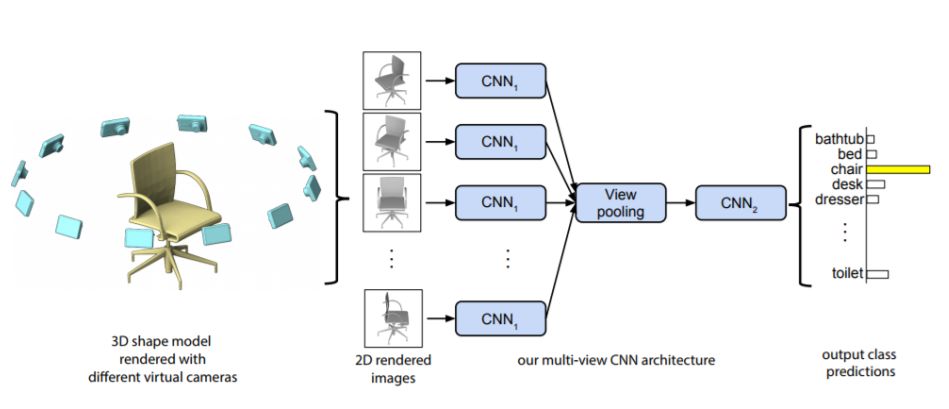
2、Object Detection
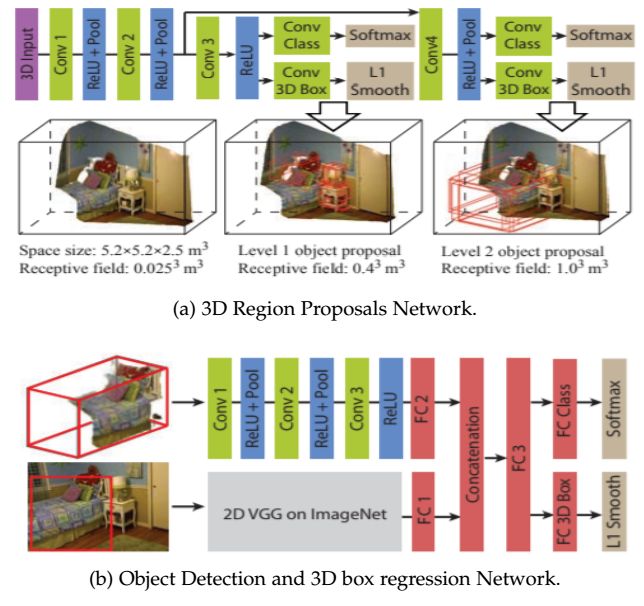
3、Semantic Segmentation
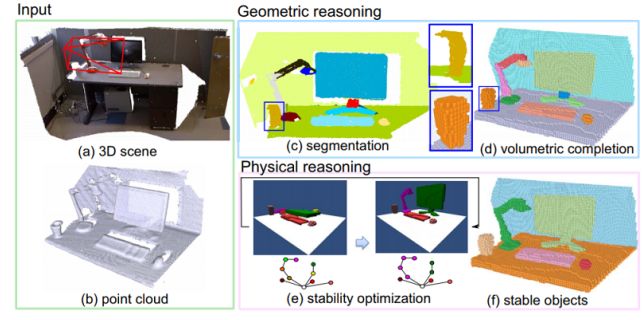
4、Physics-based Reasoning

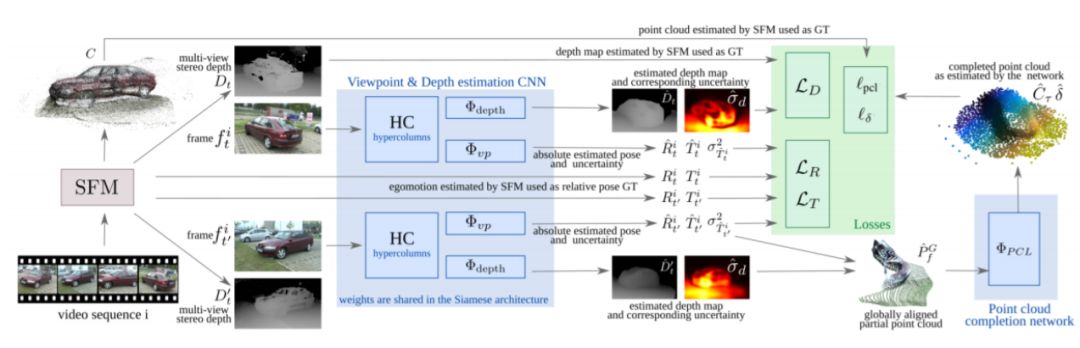
5、Object Pose Estimation
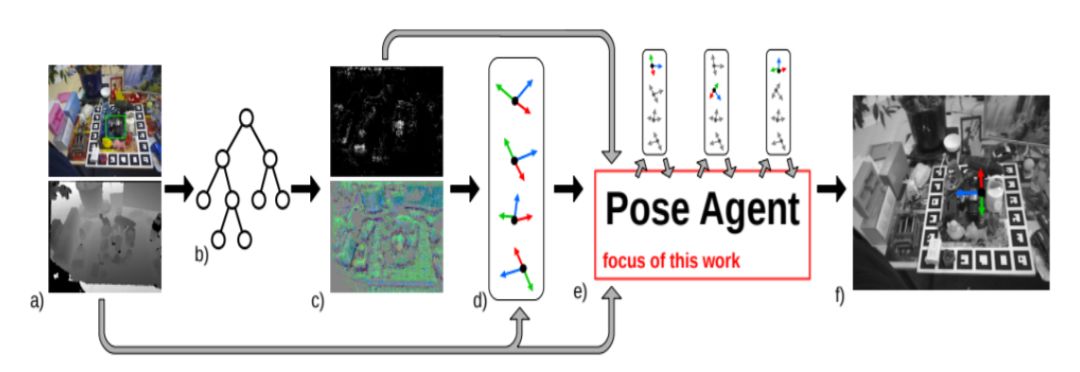
6、3D Reconstruction from RGB-D

7、Saliency Prediction(显著性预测)
8、Affordance Prediction
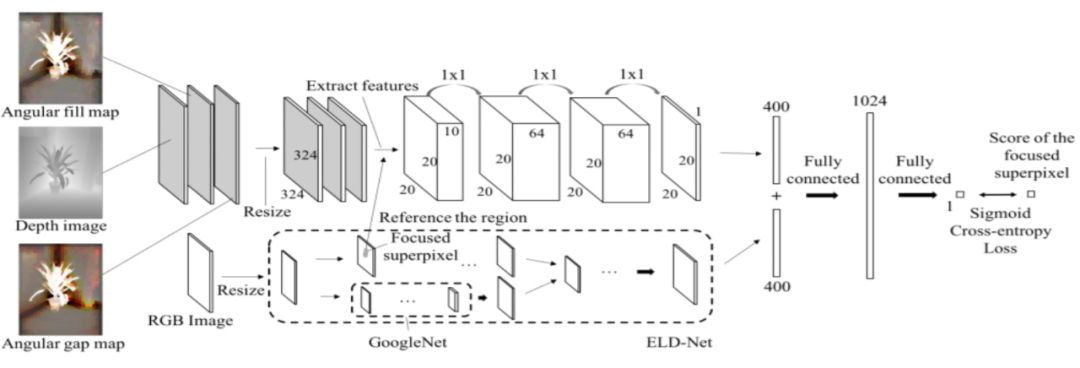
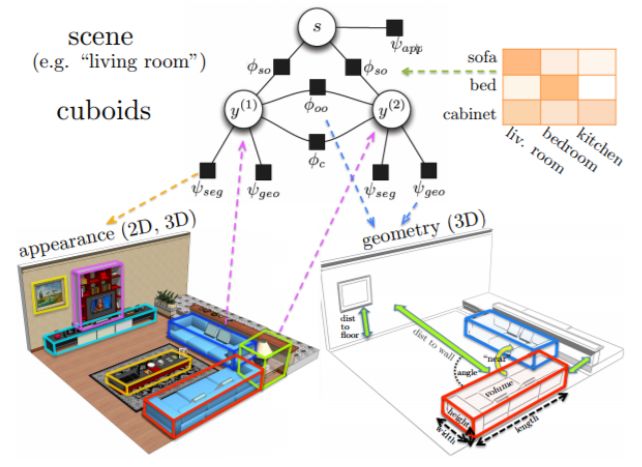
9、Holistic/Hybrid Approaches

 上述内容,如有侵犯版权,请联系作
者,会自行删文。
上述内容,如有侵犯版权,请联系作
者,会自行删文。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

投稿、合作也欢迎联系:simiter@126.com

长按关注计算机视觉life
欢迎加入从零开始学习SLAM知识星球,详见:如何从零开始系统化学习视觉SLAM?
推荐阅读
从零开始一起学习SLAM | 不推公式,如何真正理解对极约束?
从零开始一起学习SLAM | 理解图优化,一步步带你看懂g2o代码
从零开始一起学习SLAM | 用四元数插值来对齐IMU和图像帧
给优秀的自己点个赞

登录查看更多
相关内容
Arxiv
3+阅读 · 2018年5月1日




相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2018年5月1日