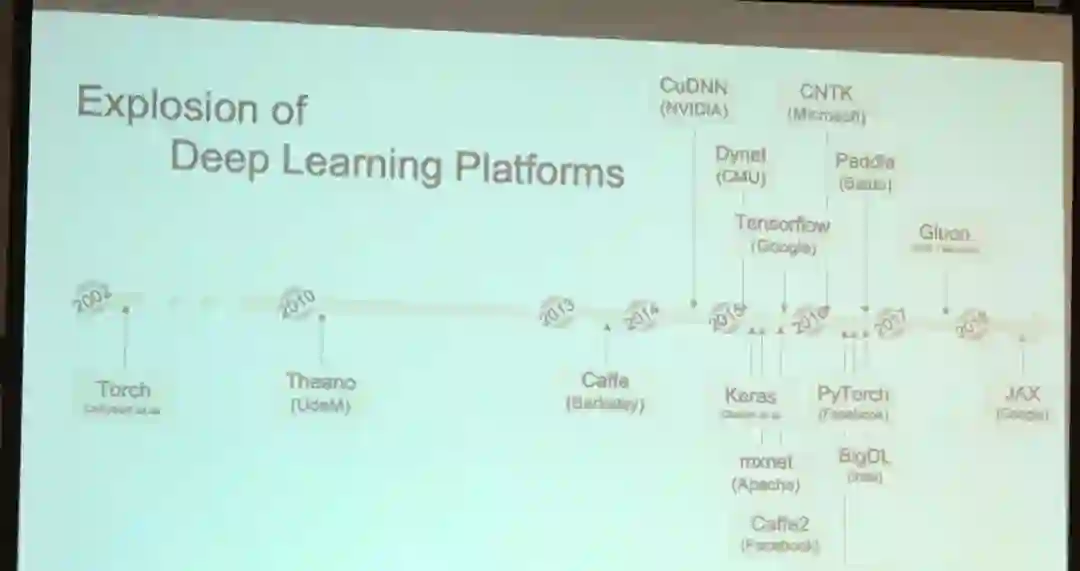
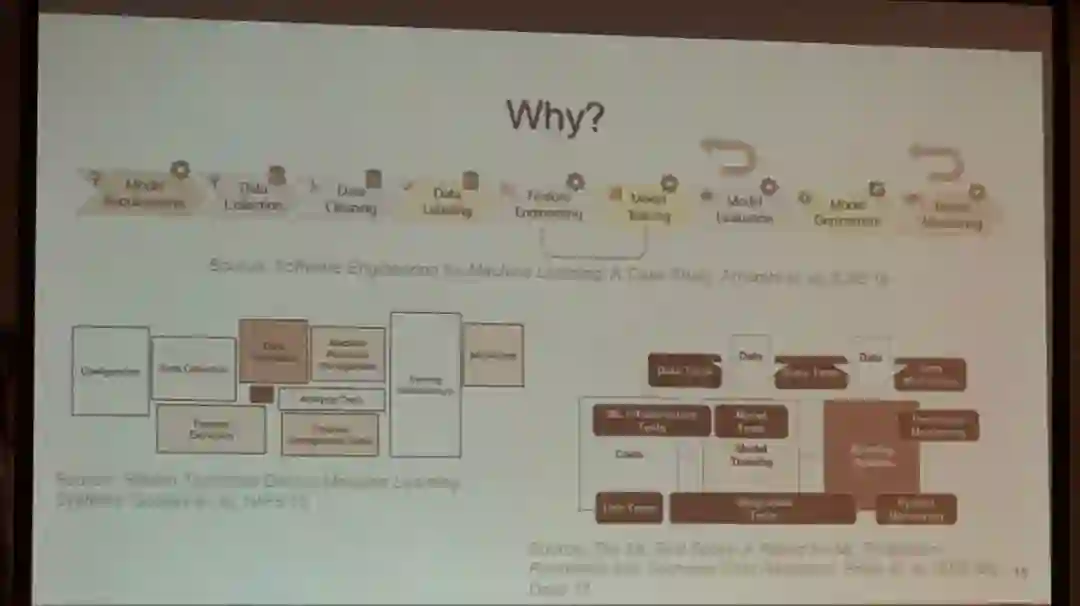
本文详细介绍了SOSP 2019 人工智能系统专题讨论会的相关内容。
ACM 操作系统原理研讨会(SOSP)是人工智能系统研究领域一个历史悠久且享有很高声望的会议。
今年的 SOSP 在距离多伦多以北大约 200 公里的湖畔小城亨茨维尔举办。在周日的雨天里
,机器之心来到了 SOSP 人工智能系统专题讨论会的现场。
![]()
随着AI 的迅速发展和广泛应用,人工智能系统领域研究者一直致力于为 AI 开发全新的系统工程设计方法。
SOSP 人工智能系统专题讨论会主要关注 AI 和操作系统相关领域的研究和进展。
《使用程序组成的视频事件技术规范》
《深度学习模型的自适应分布式训练》
《神经网络剪枝的标准化评估》
《AliGraph:一个工业级图神经网络平台》
Matei Zaharia(在中国被称「马铁」)来自斯坦福大学和位于旧金山的数据处理公司 Databricks,他毕业于多伦多圣约瑟夫学院中学和滑铁卢大学。
再次回到安大略省,他针对机器学习系统面临的特有挑战为主题进行了演讲。
Zaharia 在博士期间了开发一种高效率的分布式计算引擎,后来发展成「Apache Spark」,其中包含支持 SQL 查询和机器学习的各种库和组件。
Zaharia 对系统研究和机器学习的理解无疑对系统和机器学习的研究者而言都很重要。
他在演讲中介绍了他领导的斯坦福团队过去两年的工作,并解释了他们用系统式方法解决这些挑战的方式。
在识别机器学习系统所面临的特有挑战之前,Zaharia 先介绍了传统软件开发与机器学习软件开发的差异。
传统软件开发的目标是实现特定的功能,结果的质量也仅取决于代码的质量,而且实现的结果也是确定的。
而机器学习开发则不一样,其目标是优化一个指标(比如准确度),结果质量不仅取决于代码,还要看输入数据和参数调节的情况,而且实现的结果有一点随机。
他说明了系统研究者在改进机器学习方面的三个主要方向:
面向数据的模型训练和推理
机器学习应用质量验证和调试工具
改进机器学习平台
对于面向数据的模型训练和推理,Zaharia 介绍了斯坦福大学的两个项目:
NoScope(VLDB』17)和 Blazelt(CIDR』19)。
NoScope 实现推理优化的方式是针对特定应用或查询优化机器学习模型的执行过程。
这会分成两步来执行。
首先进行模型特化,即训练一个小型 CNN 来识别数据集中的特殊类别;
然后是查询优化,即将多个模型级联起来,再进行调节以达到目标准确度。
机器学习推理成本很高——Zaharia 解释说胜任 CNN 实时处理视频流所需的 GPU 价格每一块高达 1000 美元。
Blazelt 通过查询优化和模型特化来联合优化 SQL 查询和机器学习任务,从而能实现有效的成本节省。
![]()
Blazelt 优化模型的方式是聚合查询和限制查询数量。
其中聚合查询能通过将特化模型输出作为采样的一个控制变量,来加速近似查询;
而限制查询数量则是根据匹配查询的可能性,使用特化模型对帧进行排序,然后再运行完整模型。
![]()
在质量保证(QA)和调试工具方面,Zaharia 讨论了他的团队在 NeurIPS 2018 上提出的模型断言(model assertion)工作。
![]()
模型断言类似于软件断言,是通过机器学习应用的输入/输出情况来判断模型的质量。
机器学习应用可能会因复杂的难以调试的开发流程而失败。
举个例子,人类性别的分类准确度可能会因种族差异而各有不同。
![]()
而断言可让模型在执行时对结果有一定的预期,比如在视频分析时一个物体不应该突然在视频帧中凭空出现或突然消失、在自动驾驶应用中激光雷达和视频检测器的结果应该一致、心脏节律的检测结果也不应该频繁发生变化……这样的断言能用于改善机器学习应用的质量。
![]()
主动学习模型也能使用断言,从而帮助选择所要标记和用于训练的数据,并且还能减少失败断言的数量。
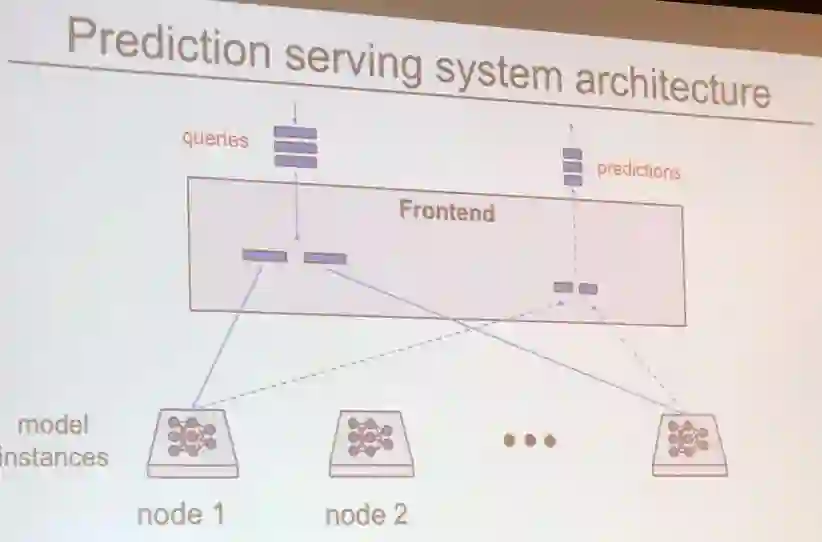
最后,Zaharia 介绍了工业级机器学习平台所面临的挑战。
因为机器学习开发往往在特定设置中进行,所以在为产业开发机器学习应用时会出现一些特有的痛点:
Zaharia 提议为机器学习的数据准备、训练和部署过程的标准化开发一种新型系统,并介绍了 Databricks 开发的 MLflow 平台。
![]()
Zaharia 还提到了其它一些机器学习特有的机会:
![]()
数据验证和监控(比如 TFX Data Validation)
面向监督的系统(比如 Snorkel、Overton)
将机器学习的数值本质用于优化、安全等(比如 TASO、HogWild、SSP、联邦式机器学习)
Caroline Lemieux 是加州大学伯克利分校的四年级在读博士生,也是一位出色的演讲者。
![]()
Lemieux 的演讲遵照了伯克利的传统,以「A Berkeley view of...」开篇,从编程语言和软件工程角度介绍了改进机器学习系统性能方面的工作。
Lemieux 强调,尽管现在用于开发机器学习应用的工具和平台有很多,但构建深度学习应用依然很困难。
不过一位大胆的听众表达了自己的不同意见。
然后 Lemieux 解释了她的观点。
![]()
在编程系统方面,支撑传统软件开发的支柱有三个:
性能、生产力、正确性。
Lemieux 提出也能以类似的方式促进深度学习的开发。
首先,深度学习应用的性能可在编译器方面得到提升。
编译器能为不同的硬件适应性地生成二进制代码。
![]()
因为在为不同的硬件优化编译结果方面,用户能够知道的情况比通用编译器多,所以 Lemieux 提议使用高层面的平台,让用户能向编译器表达自己的性能优化方法。
她说使用 Halide 这样的语言有助于性能提升。
她也说各种机器学习平台的不同 API 很让开发者头疼,因此她建议为机器学习开发过程添加一个代码推荐系统,就像 Java 集成开发环境的自动补全,比如 IntelliJ 或者 Eclipse。
她解释说,尽管如此,但是添加代码推荐功能需要输入系统,而 Python 等动态语言还缺乏这样的能力。
「那么我们应该怎么做呢?
我们想要推断张量的类型。
事实上,类型信息已经嵌入在机器学习平台之中了。
」
基于这一见解,Lemieux 及其团队提出了 AutoPandas,这是一种基于神经网络的生成器,能够生成更好的 API 代码:
https://people.eecs.berkeley.edu/~ksen/papers/autopandas2.pdf
Lemieux 问:
传统的软件调试工具能否用于深度学习?
结论是不能,因为没有复现 bug 的方法。
由于单个输入对调试没什么用处,所以机器学习应用必须依赖大量输入来进行调试。
这意味着开发者在调试机器学习模型时必须非常了解他们的数据。
Lemieux 演讲的问答环节出现了一些不同的声音,一位来自谷歌的听众认为机器学习开发并不比传统软件开发更困难,也一样是「遨游于 API 之海」。
第三个特邀演讲来自 Chris De Sa 教授,他毕业于斯坦福大学,现在是康奈尔大学的副教授。
他是一位精力非常充沛的演讲者。
毫无疑问,这个演讲令人印象深刻而且充满新意,就连他的幻灯片的字体也是很少见的衬线体。
![]()
De Sa 在演讲中介绍了如何通过应用不同的数值精度来提升机器学习的效率,尤其是在分布式系统上。
De Sa 希望让机器学习的速度更快,计算更高效。
让机器学习系统更加高效的方法包括低精度算术和异步并行/分布式训练。
低精度算术的思想是使用更小、精度更低的数值(比如 16 位浮点数或 8 位整型数)替代机器学习之前使用的 32 或 64 位浮点数。
实际上,这种思想已经在一些机器学习专用加速硬件上得到了应用,其中很多训练芯片都利用了低精度计算。
异步并行/分布式训练则会用到更多计算节点,这就意味着可以同时存储和处理更多数据。
并行训练既可以在单个芯片中实现,也可以在多个芯片上进行。
这种训练方式有很明显的优势,比如可以训练更大更复杂的模型,而且还能通过云基础设施实现显著的扩展。
这两种方法已经在一些前沿进展和机器学习服务中得到了应用,比如 TensorFlow 和 PyTorch 等主流机器学习框架;
谷歌云机器学习引擎、微软 Azure 机器学习 Studio、Catapult 项目、亚马逊 SageMaker、ML on AWS 等主流云平台;
AlphaZero 棋类引擎使用了超过 5000 个 TPU 进行训练,利用了精度较低的 ALU。
低精度计算的缺点就是精度低。
这就意味着在计算中会积累更多舍入误差。
这些舍入误差会在学习过程中累积,导致学习得到的系统准确度更低。
因此,精度的选择需要权衡考虑内存/吞吐量与准确度。
异步并行的缺点包括需要以并行的方式设计学习算法,而学习算法也需要能处理分布式通信的高延迟和低吞吐量问题。
为了克服这些缺点以及进一步改善机器学习系统,De Sa 提出:
将这些误差视为已经有很多噪声的机器学习系统的噪声
验证限制这种噪声对算法的影响的理论
使用理论来构建更可靠的算法和系统
De Sa 以 DNN 训练为例介绍了数值精度在机器学习训练中的影响。
![]()
定点数可能也有效,但却受限于比浮点数窄很多的数值范围。
因此 De Sa 介绍了一种混合方法:
Block Floating Point。
他们观察到,当存储数值张量时,通常这些数值都在同一范围内,所以如果以浮点数的形式存储,它们的指数一样或相近。
基于这一观察,Block Floating Point 通过为多个数值存储单个指数而能实现强大的数值处理能力。
他总结了低精度的格式,并表示当前的问题是缺乏硬件支持。
![]()
为了能更轻松地模拟低精度训练,De Sa 及其团队提出了一个名为 QPyTorch 的框架,支持多种数值精度格式。
除了这个可用于不同低精度格式的模拟框架,De Sa 的团队还通过一篇 ICML 2019 论文给出了由于低精度数值而造成的准确度损失的理论保证。
De Sa 介绍的另一个研究主题是改进异步并行/分布式学习。
一个常用的解决方案是通信压缩。
通信压缩的主要思想是在计算节点之间传递向量时,使用带宽需求更低的压缩版本。
这已经成为了分布式机器学习领域一项流行的技术。
在这种设置中,并行的计算节点通过发送梯度来进行通信。
某些梯度压缩很简单,因为梯度会随着算法收敛而变小。
但是,由于梯度通信的本质,传统的通信压缩会受到模型参数的维度的限制。
这方面还有很多工作要做,De Sa 谈到了一些问题:
有可能在学习中渐进式地降低通信量,但要做到这一点,我们需要重新思考算法中通信的方式,只通信梯度或参数的标准方法无法实现做到这一点。
而且,只是稍微改变问题的限界条件,我们想要用于压缩通信的算法的结构就会需要改变,而某些案例甚至完全不能实现压缩。
另一种并行机制是工作管道并行化(pipeline parallelism)。
其中,每个计算节点负责网络的一部分层。
这种并行化能让用户确切知道延迟出现的位置,因为工作管道中的计算节点是以锁步(lockstep)方式运行的。
但是,在计算一个梯度时,同一参数的多个读取可能给出不同的值,而这个参数可能已被工作管道中的另一个计算节点更新过了。
这是之前的异步方法中没有的误差来源,会导致实现结果背离。
De Sa 及其团队开发了一种基于工作管道并行的新型异步 DNN 训练方法:
PipeMare。
这种训练方法能实现与同步训练相当的结果表现。
最后,De Sa 总结了他的团队在低精度算术和分布式机器学习训练方面的工作:
QPyTorch、SWALP、o(d) 通信、PipeMare。
De Sa 表示,机器学习系统在系统指标与统计准确度方面存在权衡,通过对这种权衡进行理论理解,可以通过在算法到硬件的整个层次结构中实现性能提升。
基于学习的编码计算:一种用于机器学习推理系统的弹性计算的全新方法
Rashmi K. Vinayak 是 CMU 的一位副教授,领导着 TheSys 研究组,该研究组则隶属于著名的并行数据实验室(PDL)。
Vinayak 和她的团队正应用当今的先进理论来提升计算机系统。
![]()
分布式机器学习系统有多个计算节点,这些计算节点有可能会故障或偶尔落在后面。
如何帮助计算节点在故障后恢复是一个很重要的问题。
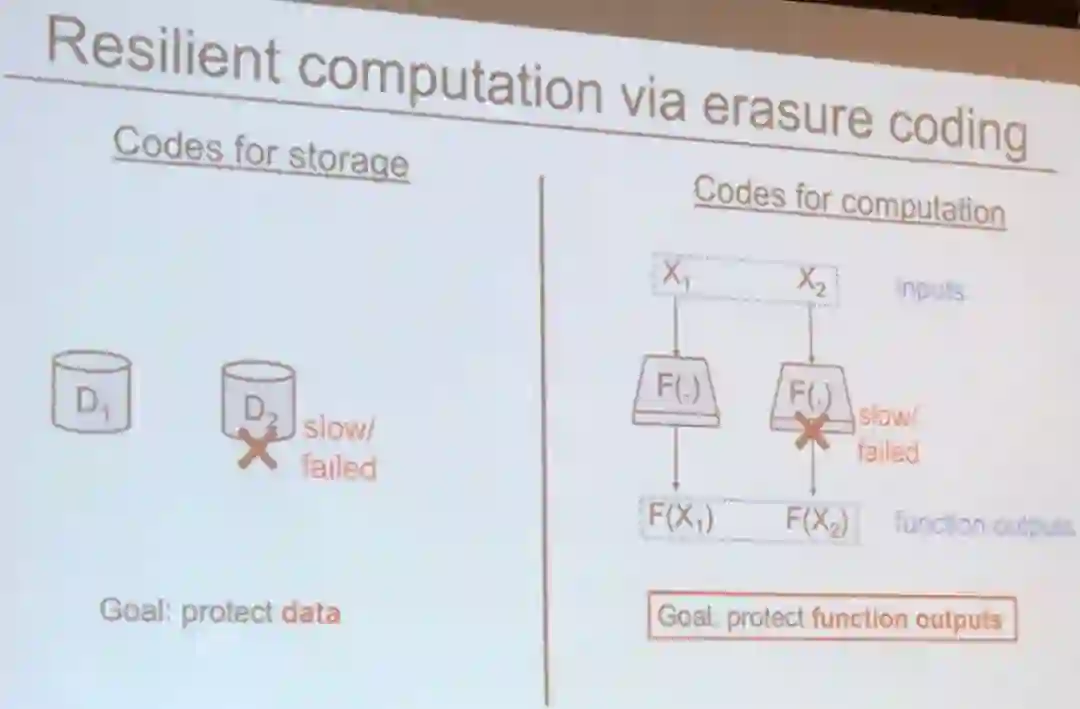
从高层面看,Vinayak 演讲的思想是利用纠删码技术(erasure coding)的恢复能力来平衡分布式机器学习系统中的恢复延迟和资源负载。
纠删码技术在数据存储和传输领域有广泛的应用,因为它能提供一种有效的恢复数据的方式,且不会引起过多冗余。
但是,用于存储的编码和用于计算的编码是非常不同的。
Vinayak 重点介绍了这些不同之处。
她将用于函数的纠删码技术分为两类:
易于实现的线性函数和难度更大的非线性函数。
![]()
为了将这种编码技术用于不同的计算,Vinayak 和她的团队提出了一种基于学习的方法。
Vinayak 最后介绍了他们团队的论文和代码库:
为强化学习构建可扩展系统以及使用强化学习构建更好的系统
田渊栋是 Facebook 一位研究科学家和经理,他毕业于 CMU 和上海交通大学。
田渊栋是个很酷的人,说到强化学习就谈个不停。
在 SOSP,他探讨了如何改进强化学习训练系统以及如何构建强化学习算法来解决系统研究中的问题。
他将自己的工作比作一个循环——构建用于强化学习的可扩展系统,然后应用强化学习来提升系统。
![]()
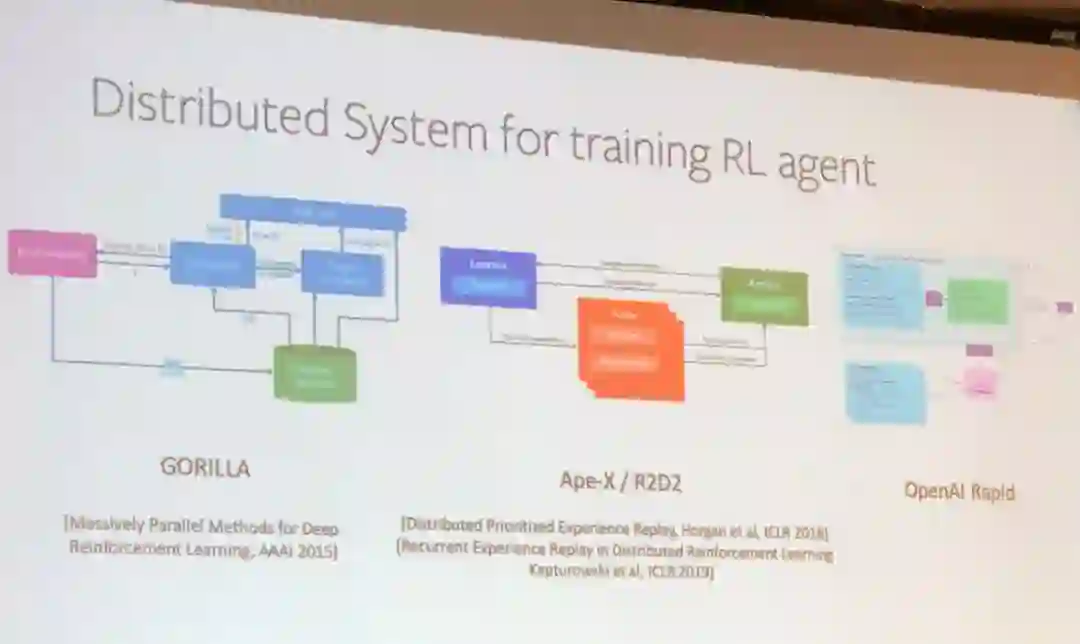
田渊栋的演讲首先介绍了用于训练强化学习智能体的三种分布式系统。
首先是异构系统中存在许多需要考虑的权衡:
不同类型的目标(执行器、环境、训练器、重放缓存)、CPU 与 GPU 的分配、多线程与多处理、分批问题、局部与分布式、同步与异步(在策略与离策略,完美的同步不可能提供最好的性能)。
另一个问题是算法设计和系统设计会互相影响,需要统一考虑。
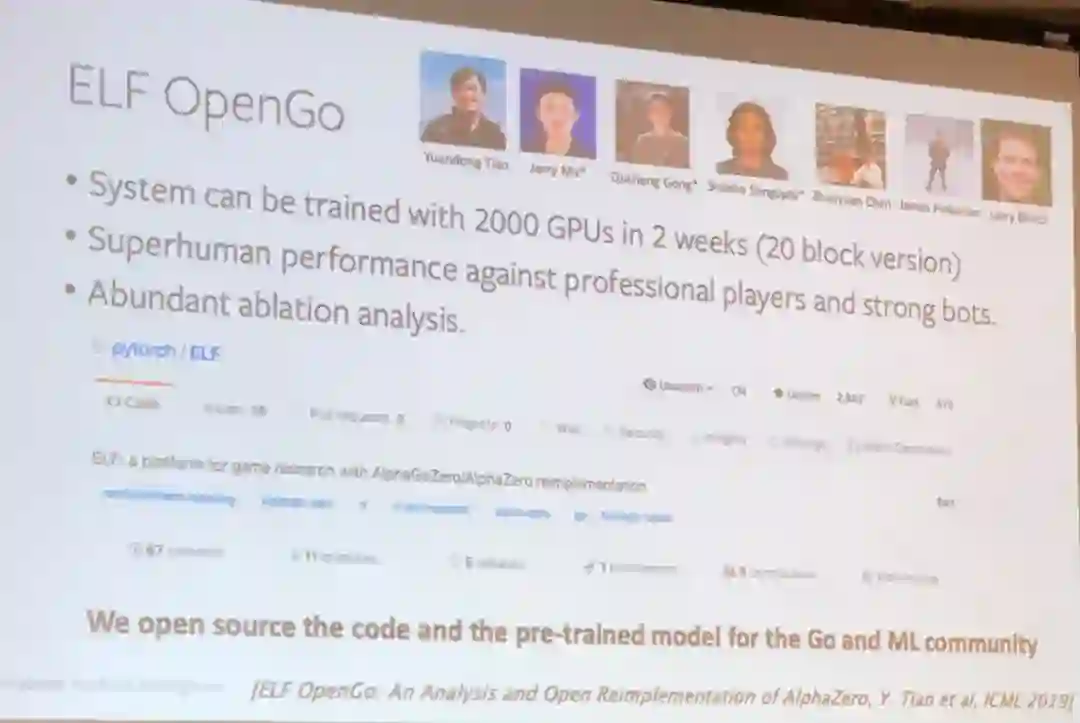
为了解决这些难题,Facebook 的研究者提出了一种用于博弈研究的强化学习框架 ELF,这项研究将现身于今年的 NeurIPS 会议。
田渊栋在介绍基于 ELF 系统训练的 OpenGo 模型之前揶揄了一番谷歌 AlphaZero:
「结果很不错,没有代码,没有模型。
」
然后他自豪地介绍了 Facebook 的开源 ELF OpenGo。
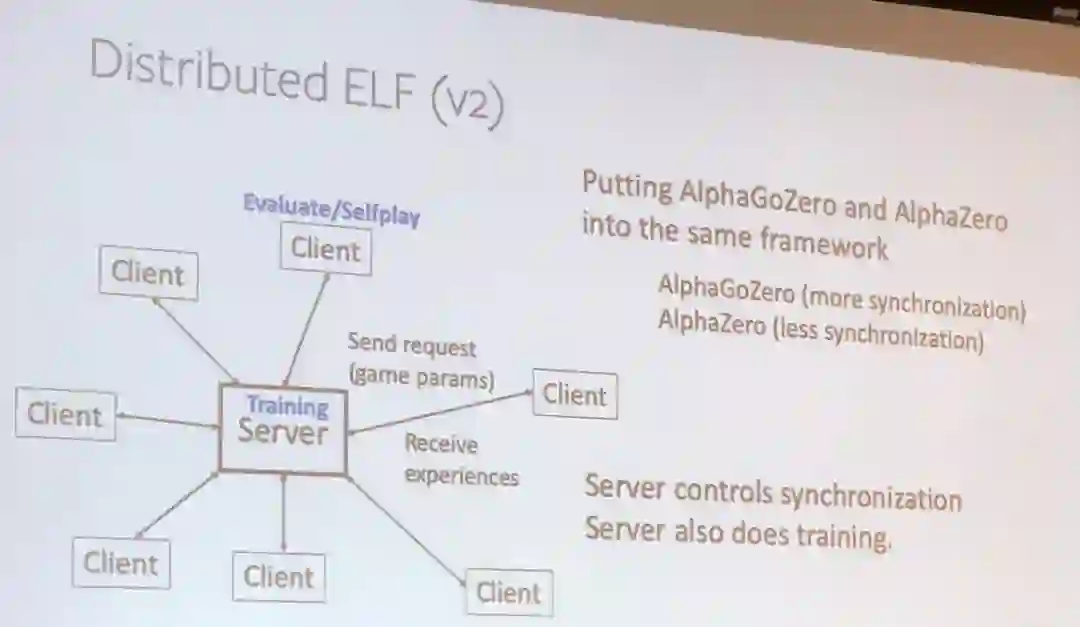
田渊栋详细介绍了分布式 ELF 系统的第 1 版和第 2 版,其中第 2 版相对前一版增加了一些加速强化学习训练的技巧。
![]()
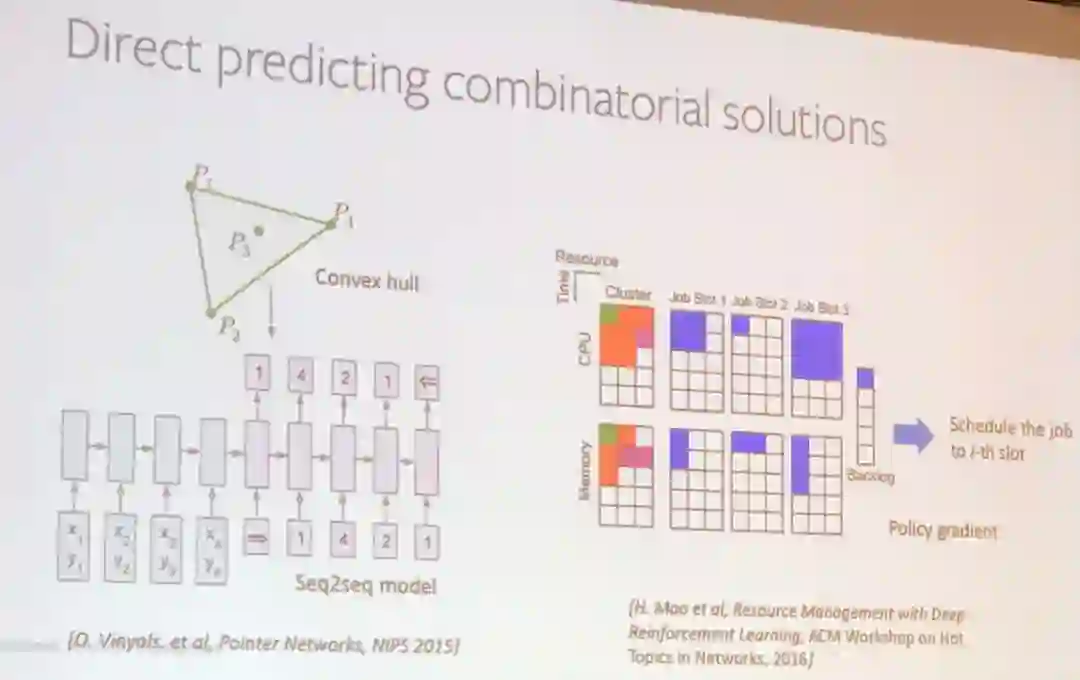
然后他介绍了他的团队正试图用强化学习解决的一个 NP-hard 组合优化问题。
一些系统研究者最近开始使用强化学习来解决一些现实问题,比如 DeepRM(H.Mao et al, Resource Management with Deep Reinforcement Learning, ACM Workshop on Hot Topics in Networks, 2016)
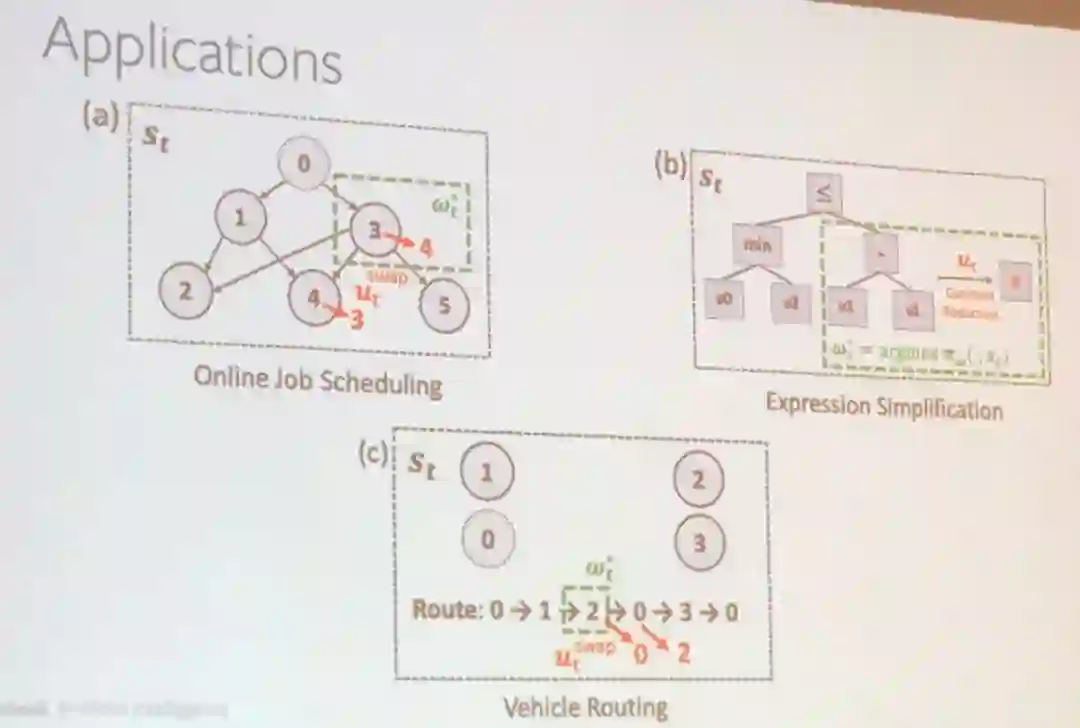
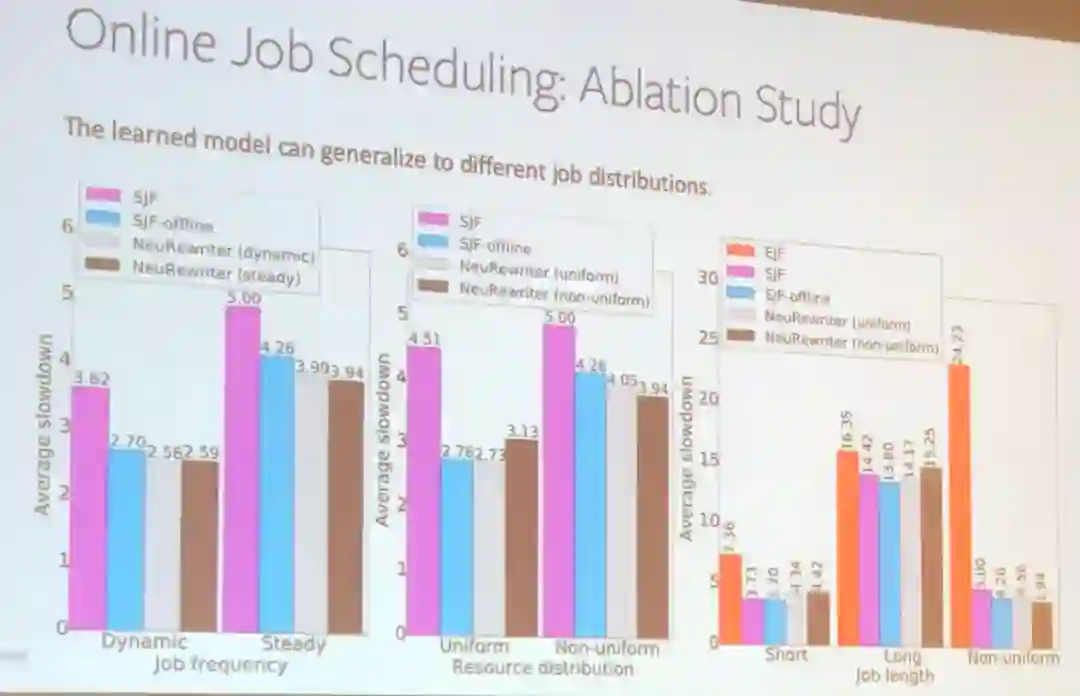
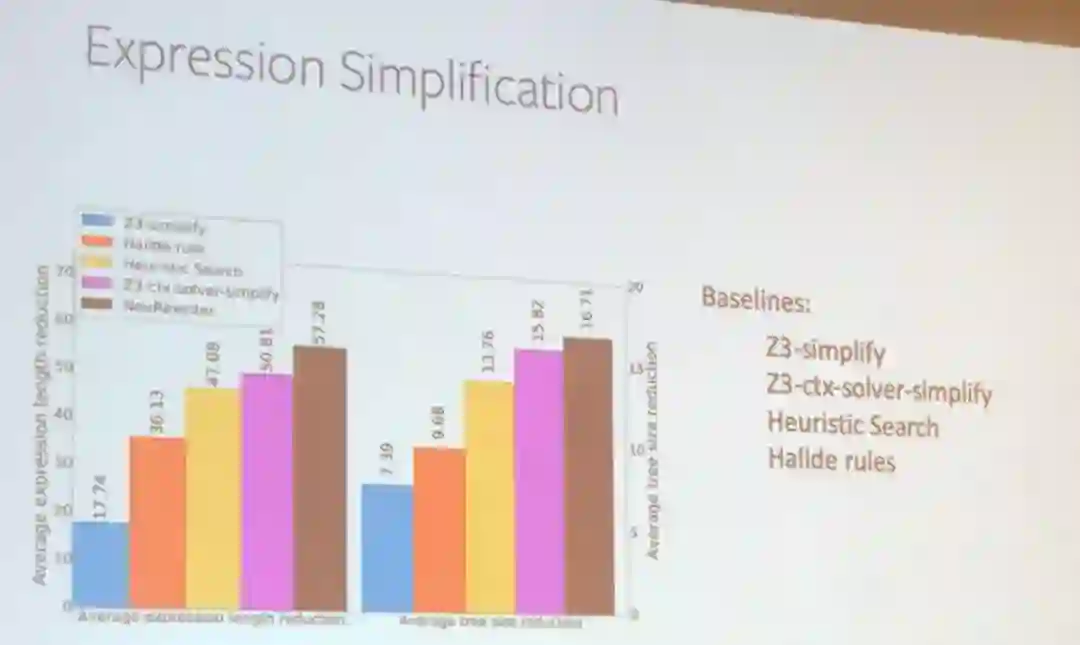
田渊栋还通过几个案例解释了使用强化学习改进系统的方式,包括在线工作调度和表达式简化。
在这两个应用中,田渊栋团队的解决方案优于大多数已有方案。
![]()
最后,田渊栋总结了他的 Facebook 研究团队在强化学习和大规模系统方面的工作。
谷歌大脑的 Alex Beutel 在卡内基梅隆大学取得了计算机科学博士学位,他的导师是 Christos Faloutsos 和 Alex Smola。
![]()
在一堆系统研究者面前谈机器学习公平性是有点冒险的,毕竟这帮人里面有人对机器学习的有效性还持怀疑态度,但
Beutel 做得很好。
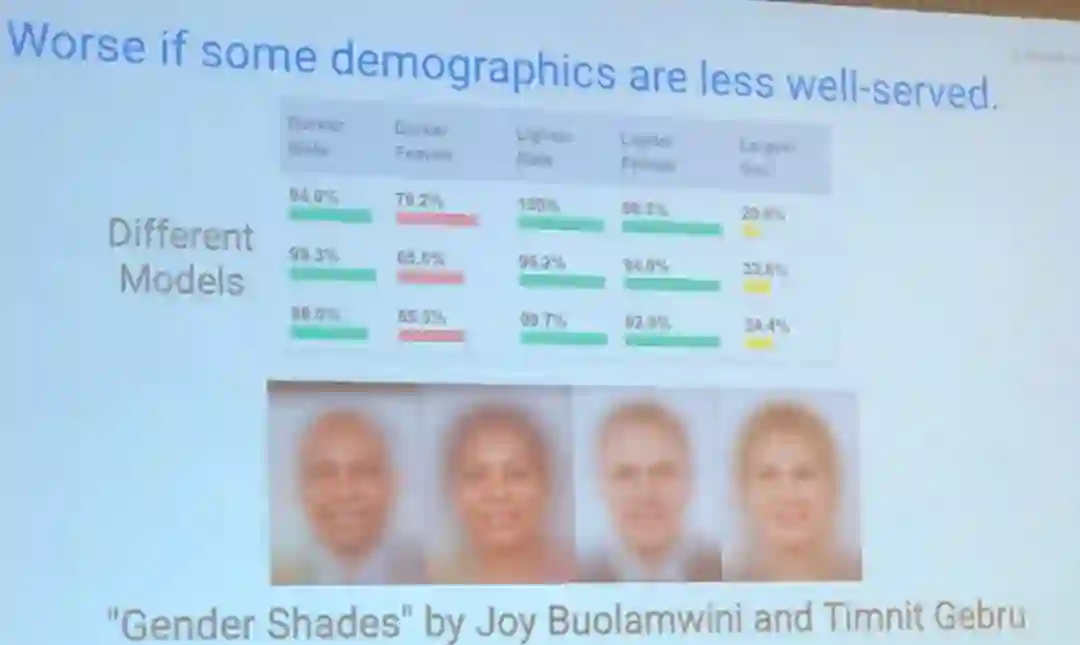
Beutel 以「Gender Shades」为例讨论了机器学习中不公平,其展示了识别模型在识别深色皮肤的女性时准确度显著下降的情况。
![]()
他接下来介绍了「算法公平性」的概念:
算法公平关注的是理解和防止通过算法系统或算法辅助决策系统不公平或有偏见地对待种族、收入、性取向或性别等特征有差别的人。
![]()
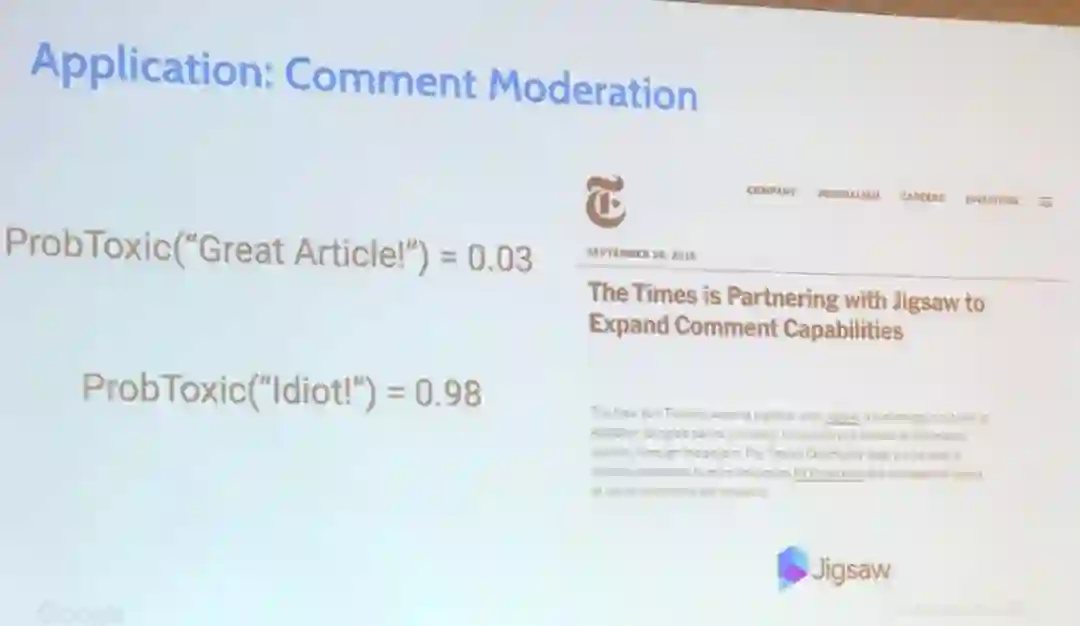
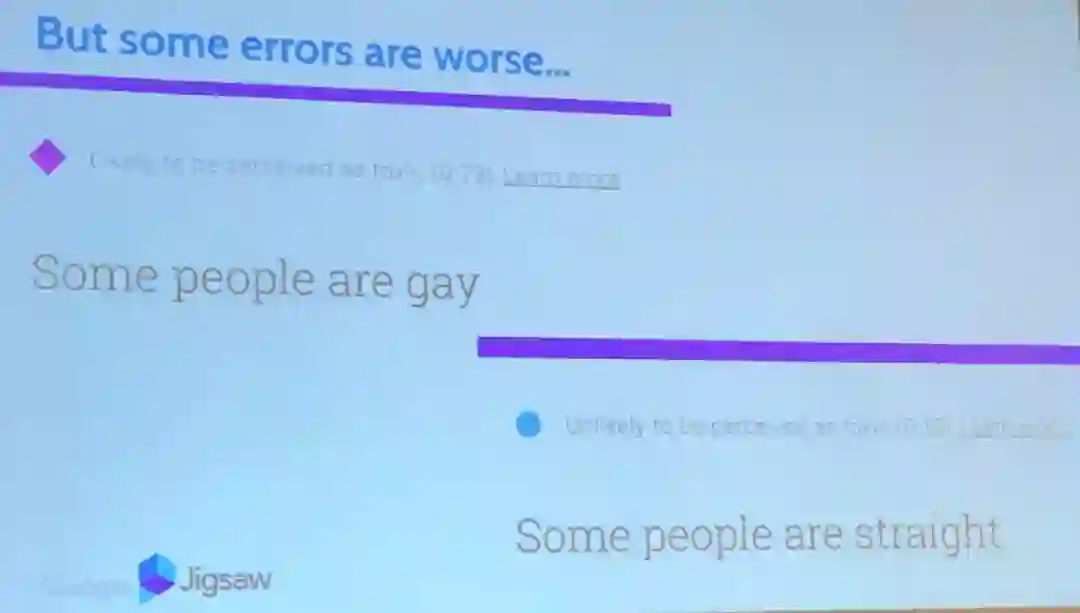
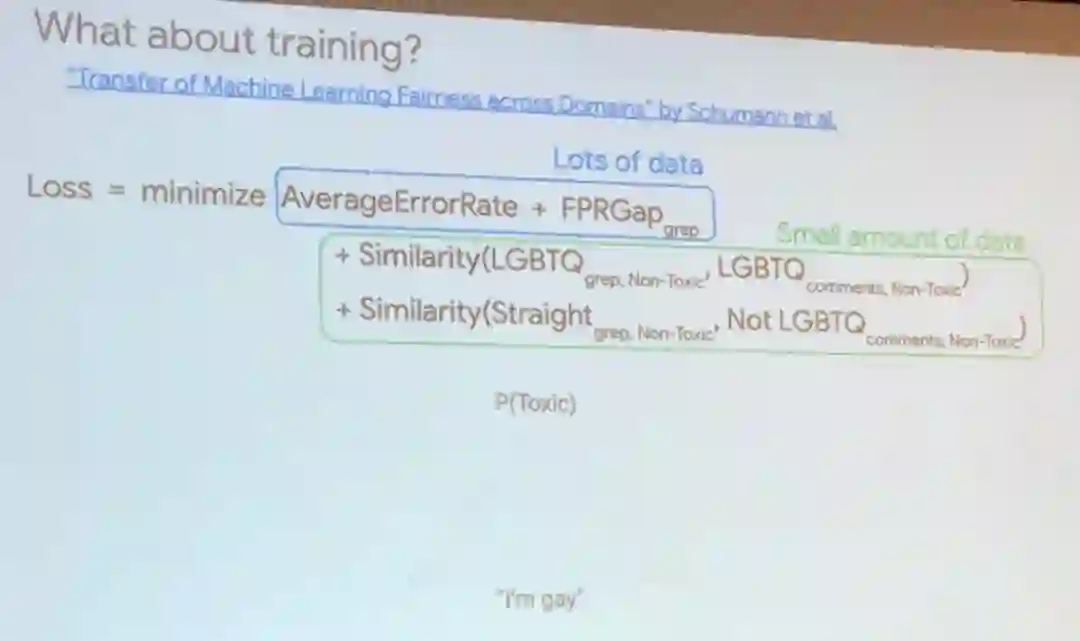
Beutel 强调,这样的偏见和不公平在机器学习领域并不罕见,他还给出了在评论审查应用方面的例子,比如「有些人是同性恋」会被算法认为比「有些人是异性恋」更有敌意。
为了解决这个问题,他提出我们应当联合考虑主要群体数据集与少数群体数据集,这样才能为我们训练的模型更加公平。
![]()
Beutel 还说明了他相信为了提升公平性机器学习领域需要研究的未来方向,其中包括数据准备和模型设计。
而且这不仅需要机器学习公平基础设施的发展,还需要与机器学习研究紧密合作。
在数据方面,需要密切注意数据采样和标注的方式等。
在模型设计方面,要关注不同模型之间的交互方式等。
除了特邀演讲,这个人工智能系统研讨会还有一个专题演讲议程,演讲者都是论文海报被该研讨会接收的作者。
下面这两个给我们留下了深刻的印象:
这项研究很有意思,因为其试图在运行时监控 SGD 指标,并据此修改训练设置。
这个想法很直观,很可能很多人都考虑过这种方法,但是没能实现它。
现在,来自伦敦帝国理工学院的研究者取得了成功,开发出了 KungFu,并且已经将其开源:
https://github.com/lsds/KungFu
![]()
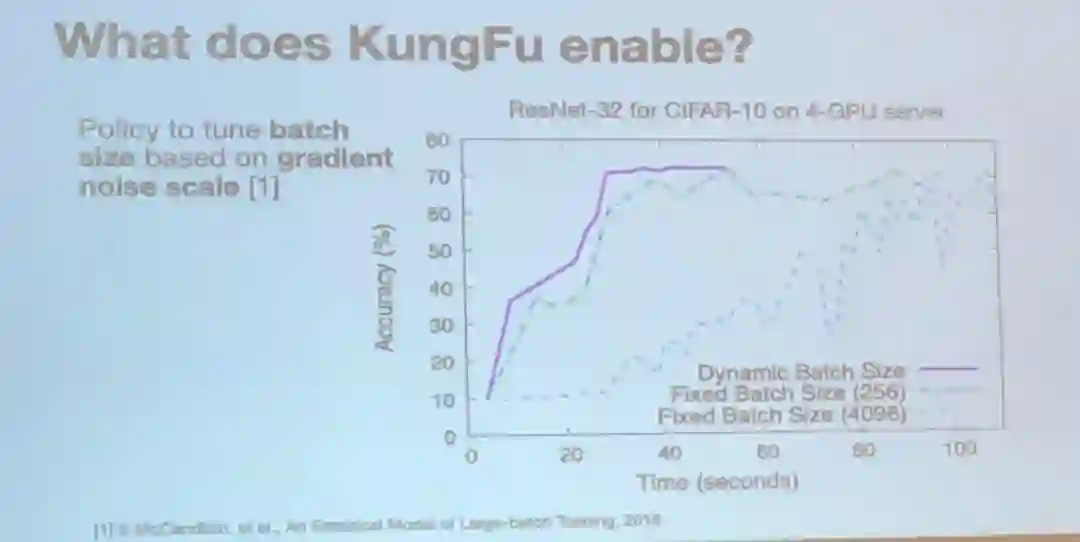
通过基于梯度噪声扩展调整批大小,研究者展示了 KungFu 的能力。
![]()
KungFu 有一些亮眼的优点:
能为自适应深度学习提供高效的支持、能提供用以表达自适应策略的高层策略、能在数据流引擎内部进行监控和适应、与去中心化通信层进行了联合设计。
我想应该会有不少机器学习系统研究者可能想使用 KungFu 来测试他们的新想法。
这个演讲来自肖文聪博士。
在微软亚洲研究院的博士期间,他就开始在研究图计算和机器学习系统。
阿里云为整个阿里巴巴集团业务提供了强大的计算支持。
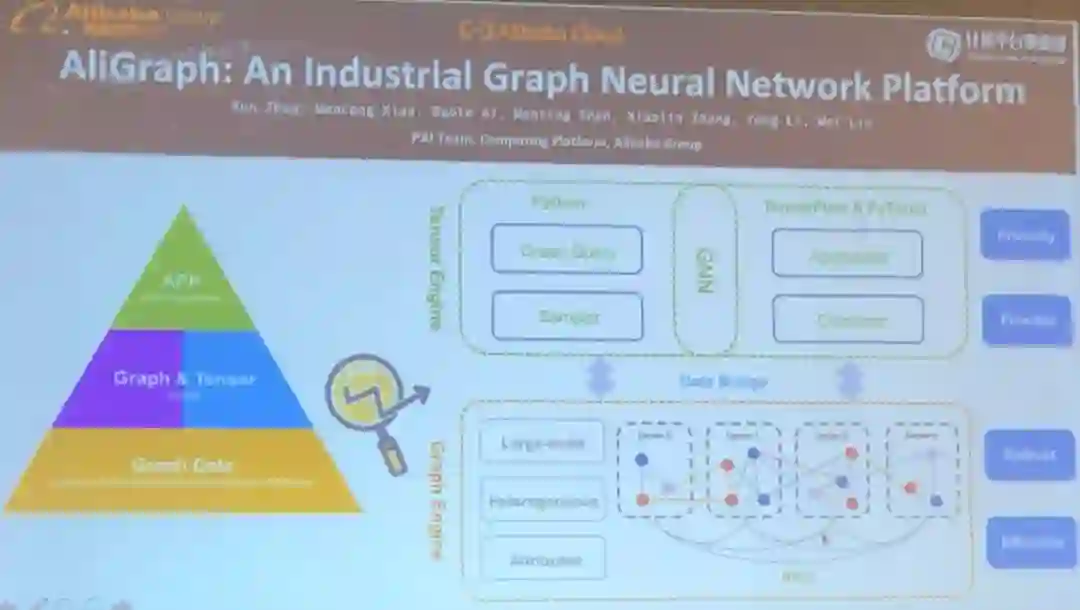
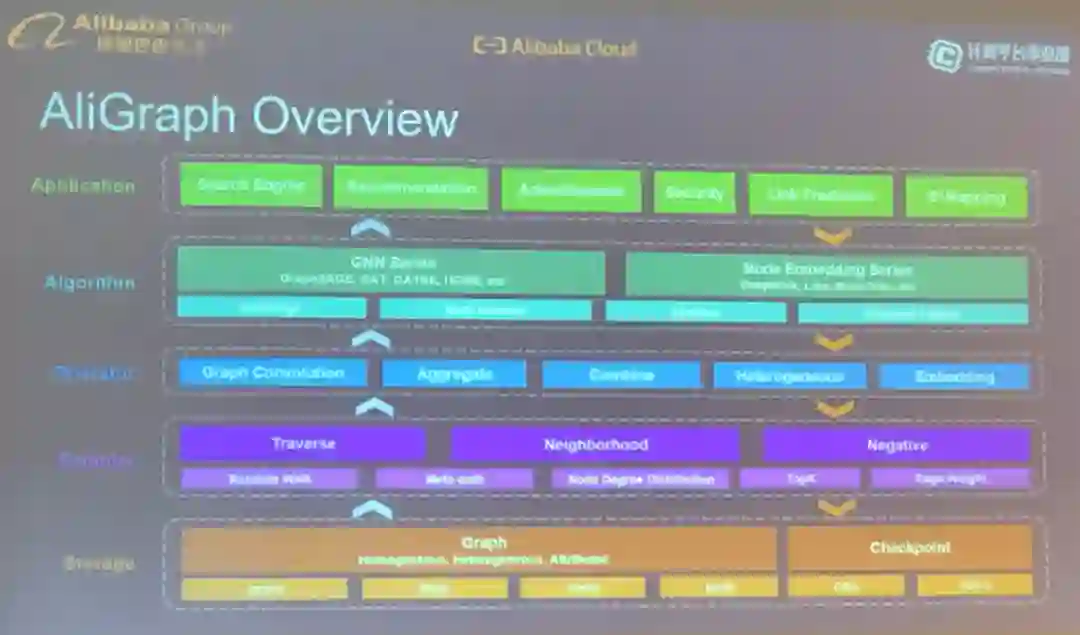
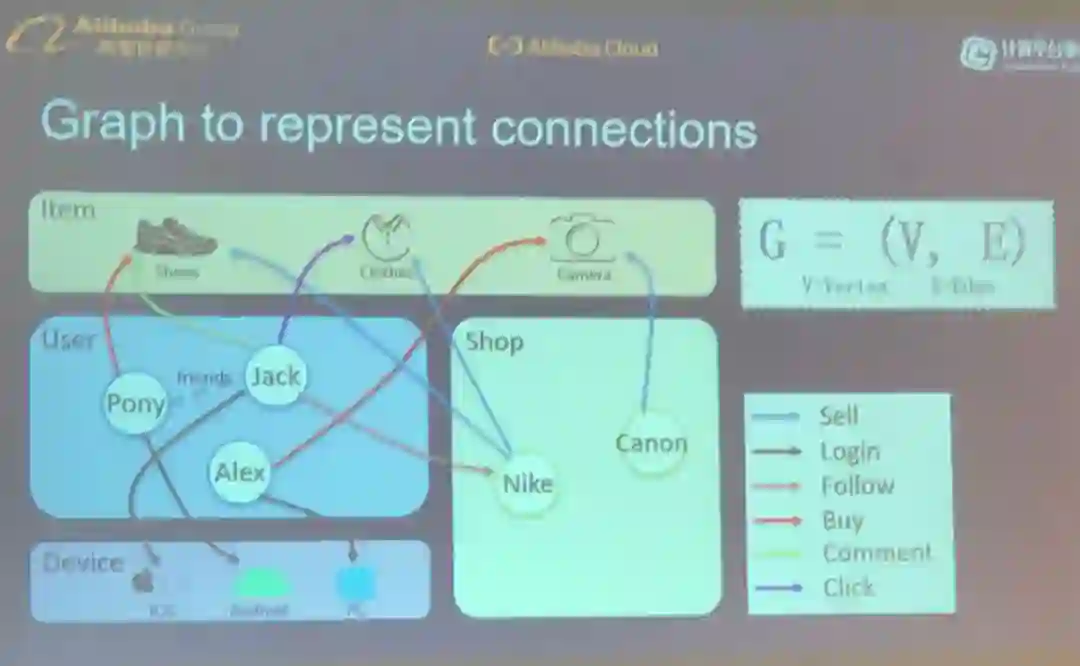
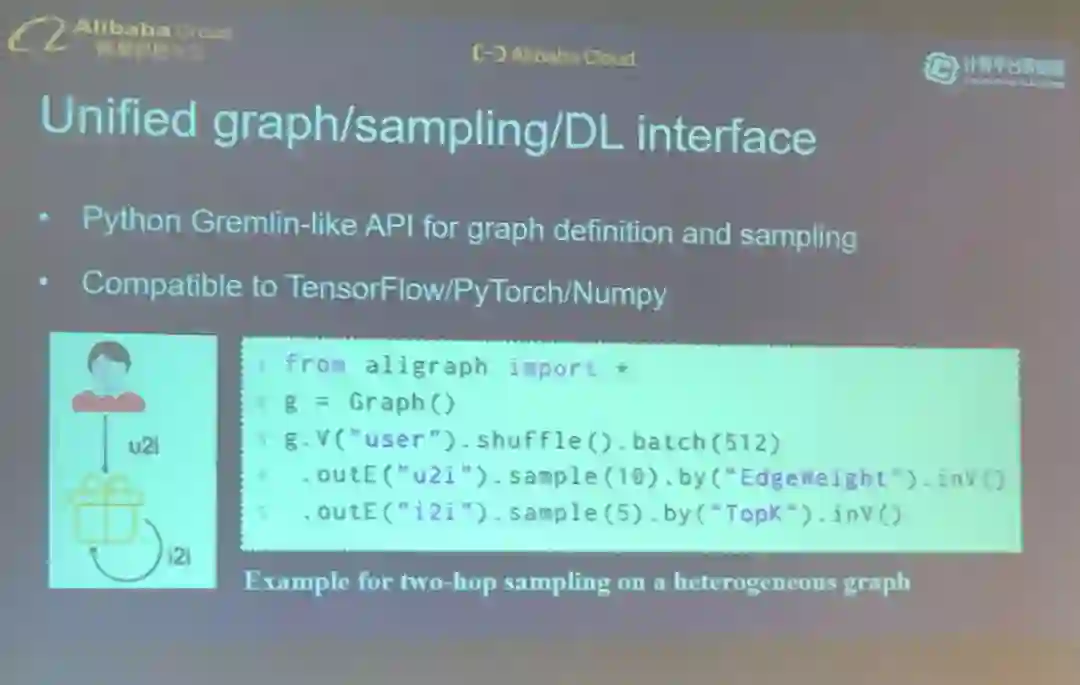
AliGraph 看起来像是一个巨型引擎,能处理各种各样的用图描述的数据。
AliGraph 为执行图计算(比如对异构图进行采样)提供了 Python 式的接口。
AliGraph 已被整合到阿里巴巴的许多服务中,包括推荐、搜索、反垃圾信息、安全、社交关系挖掘、在线支付。
未来的研究方向是更多系统优化和实现更多 GNN 应用。
SOSP 人工智能研讨会从上午九点持续到下午五点。感受
高度汇聚的专业知识,听
全世界最优秀的头脑分享他们的全新思想,这一点非常振奋人心。
另外,能从观众那里听到有见地的不同声音也非常有趣。
本届 SOSP 人工智能研讨会的幻灯片:https://www.dropbox.com/s/i0gyfnl0dcvyooy/SOSP%202019%20AI.zip
第三届机器之心「Synced Machine Intelligence Awards」年度奖项评选正在进行中。本次评选设置六大奖项,重点关注人工智能公司的产品、应用案例和产业落地情况,基于真实客观的产业表现筛选出最值得关注的企业,为行业带来实际的参考价值。
参选报名日期
:
2019 年 10 月 23 日~2019 年 12 月 15 日
评审期
:
2019 年 12 月 16 日~2019 年 12 月 31 日
![]()