更轻量的 cnocr-V1.1.0 :最小模型只有 6.8M
作者:吴金龙,爱因互动技术合伙人,算法负责人
知乎专栏:智能对话机器人技术
原文链接:
https://zhuanlan.zhihu.com/p/134115239
cnocr 是Python3下的中英文OCR包,通过pip命令安装后即可直接使用。
pip install cnocr==1.1.0V1.1.0 对代码做了很大改动,重写了大部分训练的代码,也生成了更多更难的训练和测试数据。训练好的模型相较于之前版本的模型精度有显著提升,尤其是针对英文单词的识别。
以下列出了主要的变更:
更新了训练代码,使用mxnet的
recordio首先把数据转换成二进制格式,提升后续的训练效率。训练时支持对图片做实时数据增强。也加入了更多可传入的参数。允许训练集中的文字数量不同,目前是中文10个字,英文20个字母。
提供了更多的模型选择,允许大家按需训练多种不同大小的识别模型。
内置了各种训练好的模型,最小的模型只有之前模型的
1/5大小。所有模型都可免费使用。相较于之前版本的模型,新的模型精度有显著提升,尤其是针对英文单词的识别。新模型已经可以识别英文单词间的空格。
支持文字识别只在给定字符集中进行。 对于一些纯数字或者纯英文字母的应用场景可以带来识别率提升。
优化了对黑底白字多行文字图片的支持。
mxnet依赖升级到更新的版本了。很多人反馈mxnet
1.4.1经常找不到没法装,现在升级到>=1.5.0,<1.7.0。
示例

自带可直接使用的模型
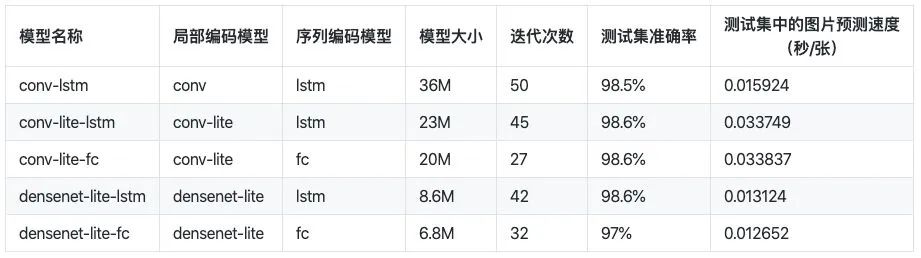
cnocr的ocr模型可以分为两阶段:第一阶段是获得ocr图片的局部编码向量,第二部分是对局部编码向量进行序列学习,获得序列编码向量。目前两个阶段分别包含以下的模型:
局部编码模型(emb model)
conv:多层的卷积网络;conv-lite:更小的多层卷积网络;densenet:一个小型的densenet网络;densenet-lite:一个更小的densenet网络。
2. 序列编码模型(seq model)
lstm:两层的LSTM网络;gru:两层的GRU网络;fc:两层的全连接网络。
cnocr目前包含以下可直接使用的模型,训练好的模型都放在 cnocr-models 项目中,可免费下载使用:
更多的说明可参见 cnocr 项目说明,或者之前的介绍文章:
相关链接:
https://github.com/breezedeus/cnocr
https://zhuanlan.zhihu.com/p/60767671
本文由作者授权发布于AINLP公众号,点击文末“阅读原文”直达原文。
推荐阅读
百度PaddleHub NLP模型全面升级,推理性能提升50%以上
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
From Word Embeddings To Document Distances 阅读笔记
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
可解释性论文阅读笔记1-Tree Regularization
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。