推荐|caffe-orc主流ocr算法:CNN+BLSTM+CTC架构实现!

简介
caffe_ocr是一个对现有主流ocr算法研究实验性的项目,目前实现了CNN+BLSTM+CTC的识别架构,并在数据准备、网络设计、调参等方面进行了诸多的实验。代码包含了对lstm、warp-ctc、multi-label等的适配和修改,还有基于inception、restnet、densenet的网络结构。代码是针对windows平台的,linux平台下只需要合并相关的修改到caffe代码中即可。
caffe代码修改
1. data layer增加了对multi-label的支持
2. lstm使用的是junhyukoh实现的lstm版本(lstm_layer_Junhyuk.cpp/cu),原版不支持变长输入的识别。输入的shape由(TxN)xH改为TxNxH以适应ctc的输入结构。
3. WarpCTCLossLayer去掉了对sequence indicators依赖(训练时CNN输出的结构是固定的),简化了网络结构(不需要sequence indicator layer)。
4. densenet修改了对Reshape没有正确响应的bug,实现了对变长输入预测的支持。
5. 增加transpose_layer、reverse_layer,实现对CNN feature map与lstm输入shape的适配
编译
1. 安装opencv,boost,cuda,其它依赖库在3rdparty下(包含debug版的lib:http://pan.baidu.com/s/1nvIFojJ)
2. caffe-vsproj下为vs2015的工程,配置好依赖库的路径即可编译,编译后会在tools_bin目录下生成训练程序caffe.exe
3. 相关的依赖dll可从百度网盘下载(http://pan.baidu.com/s/1boOiscJ)
实验
数据准备
(1)VGG Synthetic Word Dataset
(2)合成的中文数据(http://pan.baidu.com/s/1c2fHpvE)

数据是利用中文语料库(新闻+文言文),通过字体、大小、灰度、模糊、透视、拉伸等变化随机生成的。
字典中包含汉字、标点、英文、数字共5990个字符(语料字频统计,全角半角合并)
每个样本固定10个字符,字符随机截取自语料库中的句子
图片分辨率统一为280x32
共生成约360万张图片,按9:1分成训练集、验证集(暂时没有分测试集)
网络设计
网络结构在examples/ocr目录下主要实验结果
英文数据集 VGG Synthetic Word Dataset:

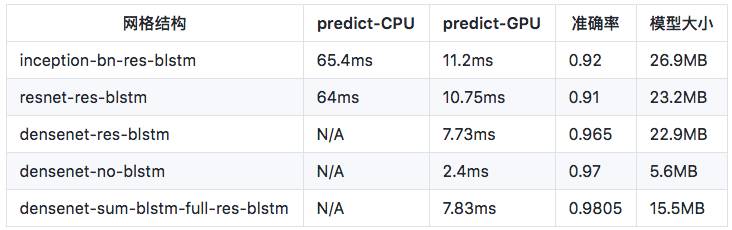
中文数据集:
中文数据集上训练好的模型:
http://pan.baidu.com/s/1i5d5zdN
说明:
CPU是Xeon E3 1230, GPU是1080TI
densenet使用的是memory-efficient版本,其CPU代码并没有使用blas库,只是实现了原始的卷积操作,速度非常慢,待优化后再做对比。
“res-blstm”表示残差形式的blstm,“no-blstm”表示没有lstm层,CNN直接对接CTC
准确率是指整串正确的比例,在验证集上统计,"准确率-no lexicon"表示没用词典的准确率,"准确率-lexicon-minctcloss"指先在词典中查找Edit Distance <=2的单词,再选择ctcloss最小的单词作为识别结果
predict-CPU/GPU为单张图片的预测时间,predict-CPU的后端是openblas,MKL比openblas快约一倍。中文数据集上图片分辨率为280x32,英文数据集100x32
densenet-sum-blstm-full-res-blstm相对于densenet-res-blstm有两点改动:(1)两个lstm结合成blstm的方式由concat改为sum;(2)两层blstm都采用残差方式连接(CNN最后的Channel数改为与blstm结点数相同),最后得到了最高的准确率。
一些tricks
(1) 残差形式的blstm可显著提升准确率,中文数据集上0.94-->0.965,两层BLSTM都用残差后又提升到了0.9805
(2) 网络的CNN部分相对于BLSTM部分可以设置更高的学习率,这样可以显著增加收敛速度疑问
(1)去掉blstm,直接用CNN+CTC的结构,在中文数据集上也可以取得很高的准确率(densenet-no-blstm),为什么?
可能的原因:a)CNN最后一层得到的特征对于字符级别的建模已经具有很好表征,b)lstm收敛较慢,需要更长的时间才能达到相同的精度。现存的问题
(1)宽度较小的数字、英文字符会出现丢字的情况,如“11”、“ll”,应该是因为CNN特征感受野过大没有看到文字间隙的缘故。
提高准确率TODO
1. 数据方面: 增大数据量,语料库均匀采样(https://yq.aliyun.com/articles/109555?t=t1)
2. 网络方面:增大网络(train、test loss很接近,现有网络没有过拟合),Attention,STN,辅助loss
引用
multi-label的支持(http://blog.csdn.net/hubin232/article/details/50960201)
junhyukoh实现的lstm版本(https://github.com/junhyukoh/caffe-lstm)
caffe-warp-ctc(https://github.com/BVLC/caffe/pull/4681)
memory-efficient densenet(https://github.com/Tongcheng/caffe/)
浙大90后女黑客在GeekPwn2017上秒破人脸识别系统!
周志华点评AlphaGo Zero:这6大特点非常值得注意!