【赛尔原创】如何自动地向知识图谱中添加属性?
作者:佘琪星、姜天文、刘铭、秦兵
来自:工大SCIR
摘要:属性是实体的重要组成部分,因此如何自动获取实体的属性一直为知识图谱领域的研究者所关注。由哈尔滨工业大学社会计算与信息检索研究中心推出的开放域中文知识图谱《大词林》是通过从文本中自动挖掘实体及实体间的关系而构建而成,因此如何自动为实体添加属性也必然成为构建《大词林》所必须研究的问题之一。本文通过学习《大词林》中实体的概念层次结构和属性的表示,提出了一种基于注意力机制的属性自动获取方案。其想法可简述为,实体的属性可以通过检查它的概念类别来获得,因为实体可以作为它的概念类别的实例并继承它们的属性。实验结果显示,我们的方法能够为《大词林》中的实体自动添加属性,最终可以使大词林中实体属性的覆盖率达到95%以上。
1. 简介
属性在知识图谱的构建中起着至关重要的作用,属性不仅能够丰富实体的概念、揭示实体的特性,并且在知识库中连接了不同的实体(例如:“director”是概念类“film”的属性,它也连接了类“film”和“person”的实体)。图1是《大词林》中实体“苹果”的概念层次路径和该概念路径下“苹果”的属性。事实上,我们可以合理的作此假设:一个实体具有何种属性通常是由其概念决定的,而不是由其本身决定。例如“苹果”和“鸭梨”均具有颜色的属性,是由其二者均具有“水果/植物/生物/物”这一概念路径决定的,而与“苹果”和“鸭梨”本身的标签无太多关系。因此,可以认为实体是它的概念的实例,实体的属性可以通过检查它的概念体系(或路径)来获得。
在本文中,我们提出一种基于实体的层次化概念体系的属性自动获取方法,以自动获取实体的属性提高知识库的构建效率。与仅仅使用一个词代表实体的概念相比(例如“university”表示实体是一所高等教育的学校),用具有层次结构的概念路径(几个表示概念的单词连接为一条路径,例如“institute/school/university”,前者是后者的上位词)更为明确和可靠。例如,“university”也可能指大学的教师和学生的主体,在“institute”和“school”的帮助下,实体是一所大学的意义得到细化。因此,我们使用概念路径来表示实体概念的层次结构,而不是仅仅使用一个单词。假设我们已经具有一个属性的集合(此集合可以通过已有知识库中的属性构建而成),受近期知识图谱表示学习的启发[1][2][3][4],我们考虑将《大词林》所具有的层次化的概念体系和属性集合中的属性映射到连续的向量空间,从而将属性获取问题转化为预测任务,即从属性集合中为《大词林》中的实体预测合适的属性。
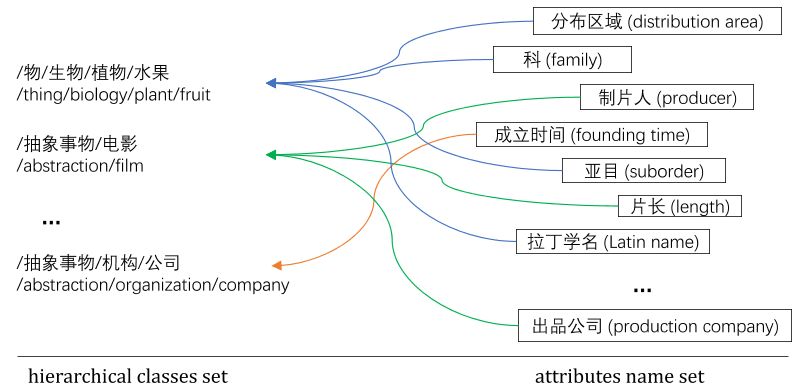
图1《大词林》中“苹果”的层次化概念体系
传统方法大多直接将属性分配给实体,这给多角色实体带来了诸多不便。在《大词林》中,每个实体平均有两个概念。例如,实体“苹果”既可以指“水果”,也可以指“公司”,甚至可以指“电影”。然而,属性不像属性值一样具体,其更具有一般性。比如对于苹果的属性-“颜色”,其属性值是“绿色”,而其他水果的“颜色”不一定是绿色,但是其他水果也拥有“颜色”这一属性。对于属于同一概念的实体,它们几乎共享相同的属性集。这意味着与将属性分配给实体相比,将属性分配给其概念似乎更有意义。
多角色实体在概念和属性之间产生的属性分配歧义问题是我们工作的主要挑战。举例来说,通过已有的知识库(例如百度百科或维基百科),我们很容易能够得知“苹果”有一个“导演”的属性,但很难获取与这个属性相关联的概念。而事实上,实体的属性又是由其概念决定的,例如在“苹果”具有的多种含义中,如“水果”、“电影”或“公司”等,直接与属性“导演”相关的概念是“电影”。为此,我们提出了一种基于注意力模型的层次化概念体系表示方法,来对实体的概念体系和属性之间的映射进行学习,以解决此问题。
本文以百度百科的属性数据为基础构建属性集合,并利用百度百科中的属性向《大词林》中的实体添加属性。我们随机抽取了《大词林》中687392个实体,有395327个实体具有至少一个属性,余下292065个实体没有任何属性。,如果单纯依靠百度百科向《大词林》中的实体提供属性,那么属性对实体的覆盖率为57.51%。但是如果考虑到具有相同概念的实体共享类似的属性,并依此进行补全,那么属性的覆盖率可提高至 98.48%。
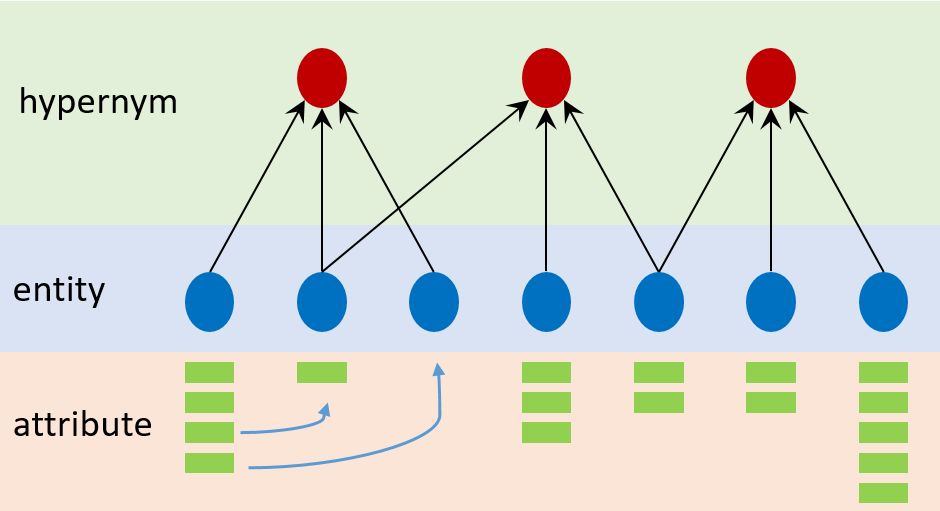
图2 属性推荐图例
以图2为例,如果依靠百度百科,只有部分实体拥有完整的属性,但是由于缺失属性的实体和已有属性的实体共享相同的概念,因此可以将已知的属性推荐给缺少属性的实体。图3显示了《大词林》中“止痛片”概念下的部分实体,其中“玄胡止痛片”和“祛止痛片”不具有任何属性,通过概念补全后这两个实体拥有了相应的属性,结果如图4所示。

图3 “止痛片”概念下的部分实体和其属性
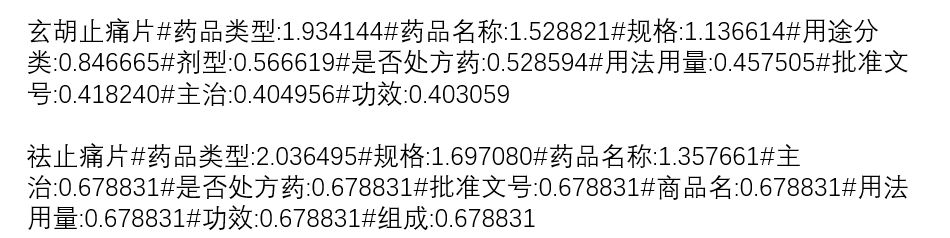
图4 通过概念补全后的实体属性
2. 模型介绍
本文中涉及的属性获取任务是通过给定{E,C,A,R1,R2}来预测R3,并通过R3来完成根据实体的概念路径将属性集合中的属性推荐给实体的任务。E代表《大词林》中的实体集合,C代表《大词林》中的概念集合(也称为上位词),A代表属性集合(由百度百科获取),R1代表每个实体的上位词路径(也称为概念路径),R2代表每个实体具有的属性(通过百度百科直接映射得到),R3是实体的概念路径与属性的对应关系,整个过程如图5所示。
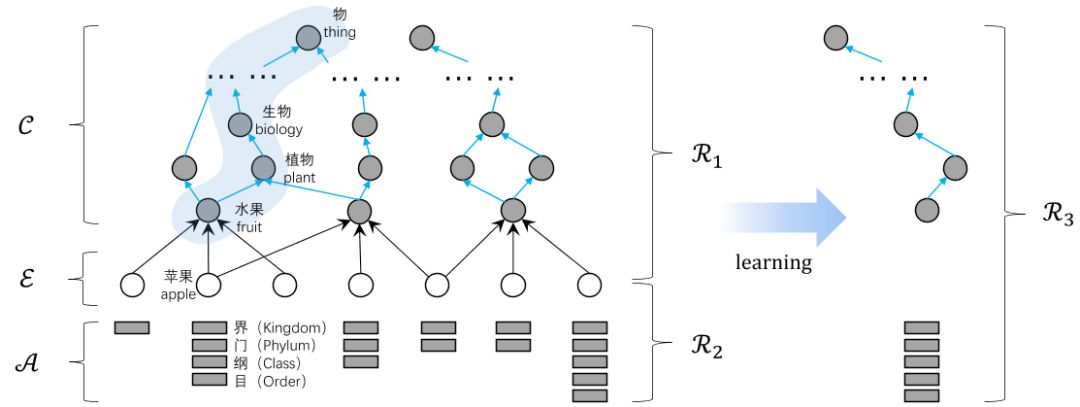
图5 用符号表示的任务定义
2.1 通过LSTM实现概念路径的表示学习
本文使用LSTM[5]来学习概念路径的表示。图4显示了一个使用LSTM建模概念路径的方法。其中LSTM-cell[6]由浅灰色框标出,序列模型的最终输出由深灰色框标出,LSTM应用于概念路径“/抽象事物/机构/教育机构/学校/大学”上,最终输出为概念路径的向量表示。
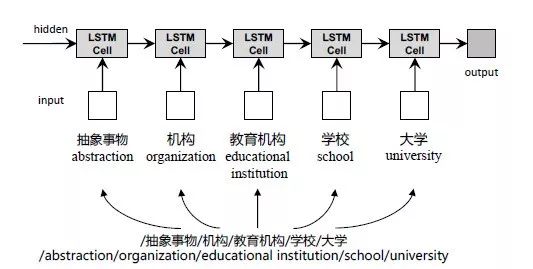
图6 用于概念路径表示的LSTM网络
2.2 利用注意力模型完成概念路径的叠加嵌入表示
如前所述,我们可以将百度百科中的属性添加到《大词林》与百度百科同现的实体上而完成属性的初步填充,但是经过抽样统计发现这种方法仅仅能够为《大词林》不到60%的实体添加上属性。基于属性初步填充的结果,我们可以得到一组(Pe, a)形式的元组,其中Pe是给定实体e的概念路径集合,a是实体的属性,然而我们并不知道Pe中的哪一条路径具有属性a。为了确定实体的概念路径和属性的映射关系,进而将属性映射到对应的实体上,我们提出一种解决方法,它由三部分组成:
概念路径的表示学习(图5介绍);
概念路径上的选择注意力机制以确定概念路径和属性的对应关系;
基于翻译的嵌入模型预测实体的属性。整体结构如图7所示。
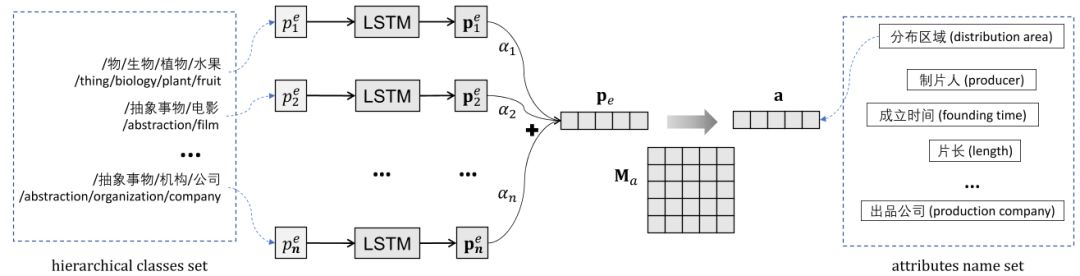
图7 属性预测整体解决方案
与传统的基于翻译的嵌入方法专注于实体-关系-实体三元组(h, r, t)[1]不同,我们所期望获得的是由实体不同的概念路径及其对应属性形成的二元元组(p, a)。因此,不像三元组(h, r, t)中有r这样的显式算子,我们为每个属性构造一个映射矩阵,其映射过程为pMa = a,其中p,a,Ma分别是概念路径、属性及映射矩阵的嵌入向量。
因为已知的仅仅是某个实体具有哪些属性,这样必须退而求其次通过LSTM学习每个实体的所有概念别路径的表示,显然的不同的概念路径对某一实体是否具有某个属性的影响是不一样的。例如,“水果”这一概念能够确定实体“苹果”可以具有属性“颜色”,而“电影”这一概念能够确定实体“苹果”应该具有“制片人”这一属性。这样,我们就不能对每个概念路径一视同仁。由图7所示,我们用选择注意力模型去建模概念路径和属性的对应关系,以尽可能降低训练中产生的噪声。通过计算每一条概念路径和要预测属性的匹配度来为每条路径分配权重。最终使用学习到的权重和每条路径的表示结果加权求和来确定最终的这个实体的路径表示pe。
2.3 训练方法
根据上文的描述,我们希望当概念路径p拥有a这一属性时,pMa和要预测的属性a的距离最短;相反,当p不具有属性a时,则距离较长。为实现此目标,我们使用L1或者L2范数来度量两者之间的距离,记为d(pMa,a)。利用元组(Pe, a)的集合作为训练集Ω,Pe是对于一个给定实体e的概念路径集合,a是实体e的属性。然后我们在训练集上最小化边界距离来共同学习概念路径和属性的表示:
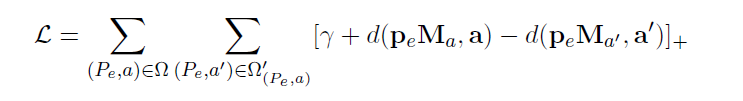
γ> 0是一个边界超参数,a和a’分别代表实体属性的正例与负例。
3. 实验结果
3.1 数据集介绍
实验数据由《大词林》中抽样得到,具体方法如下:
随机抽取20000个实体及其概念路径。
利用百度百科向这些实体填充属性。
对属性进行低频过滤,保留至少出现在20个实体中的属性。
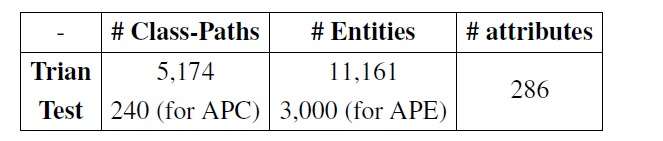
随机选取3000个实体作为测试集验证“基于实体预测属性”这一任务的效果,同时随机选取240条概念路径作为测试集验证“基于概念路径预测属性”这一任务的效果。数据集的统计如表1所示,APE和APC分别代表基于实体和基于概念路径的属性预测任务。
表1 数据集统计结果
3.2 实体属性预测(APE)
从实体的角度来看,预测其属性无疑是必要和重要的。因此,我们提出了实体属性预测任务(APE),以预测给定实体的属性。当然由于实体可能具有多重含义,因此我们也希望能够将属性和其对应的概念路径联系起来(APC任务)。
由于实体被视为其概念的实例,因此仅通过检查实体的概念就可以获得实体的属性集。在APE中,对于给定的实体,我们首先获取其概念路径集合,然后使用它们来预测实体的属性。Hits@k评价方法适用于APE任务,因为可以过滤掉某些同义的属性,比如“中文名(中文名字)”,“外文名(英文名字)”,等等,结果如表2所示。
表2 APE任务的Hit@k值
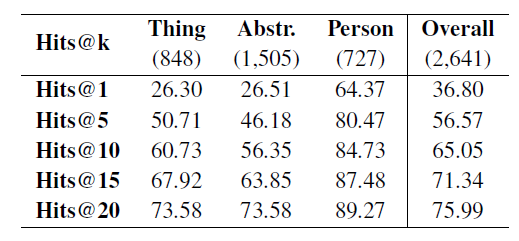
除了在全部实体上检查Hits@k之外,实验中还考虑了不同概念类别的实体(即,“物”、“抽象”、“人”)。表2括号中的数字为对应不同类别的实体的数量。结果表明,近76%的实体在前20个预测属性中至少获得了一个正确的属性。对于“人”类型的实体,Hits@k的结果除Hits@1外均超过80%。另外两类的结果与整体评价相比较差。
事实上,表2中的结果是从以百度百科中的属性数据为基础向《大词林》做映射而构建的测试集上得到的,但是由于百度百科中的实体过多依赖于人工众包而《大词林》中的实体则完全由文本中自动抽取得到,因此两者存在不对等,从而引入了大量的噪声而影响了评测的准确率。当然,更加有效的方法是人工构建测试集,但是这样太费时费力了。
由于实体具有多重含义,因此我们更加关心我们的模型是否能够通过预测属性来区分实体的多重含义。这里我们仅仅通过抽样的方式构建了实体“苹果”和“利华”的属性预测结果,如图8所示。沿箭头方向,我们给出了实体不同的概念路径对应的属性预测结果,以“苹果”为例,其在《大词林》中具有“水果”、“电影”、“公司”三种含义,而左侧的“科”、“拉丁学名”等则代表“苹果”的部分属性。图中的颜色代表根据注意力机制对不同概念路径的预测属性的注意程度,单元格颜色越深表示权重越大。
从注意力矩阵可以看出,属性大多出现在其对应的概念路径上,在不相关的概念路径上权重几乎为零。如概念路径“/抽象事物/电影”引起了属性“片长、出品公司、制片人”的注意。但是,也有一些错误的理解,例如属性“中文名”和“外文名”只出现在“人物”或“公司”对应的概念路径中的一条上,这是不准确的,因为从常识上来说这两个属性都应该被这两条概念路径分别包含。幸运的是,这种错误可以被APC任务所掩盖,因为APC从实体的角度来预测属性。
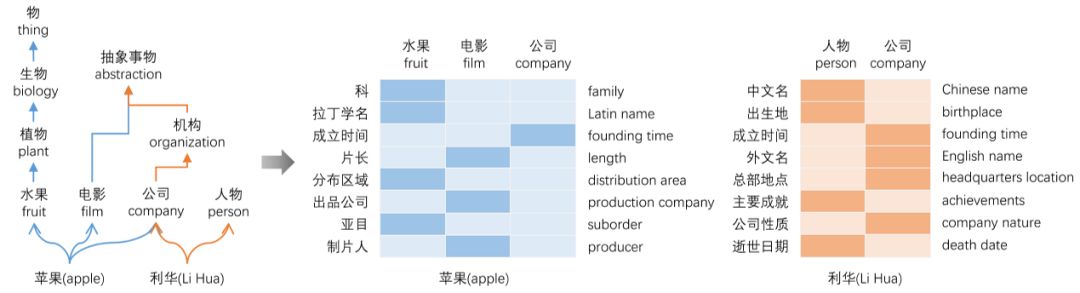
图8 多角色实体属性预测结果
3.3 概念路径属性预测(APC)
从概念路径的角度出发,我们提出了概念路径属性预测任务,以评估模型将概念路径映射到属性的能力。在这个任务的预测过程中,我们使用了没有针对概念路径的选择性注意力模型,因为任务APC中只涉及一个唯一的概念路径,因此不需要注意力机制。
由于中文缺乏标准的“概念类别-属性”对评测数据集,我们手动标注结果的正确性:top-k预测属性。手动标注原则如下:
过滤不准确的概念路径。
过滤掉过于抽象的概念路径,例如:“/抽象事物/能力/竞争力”。
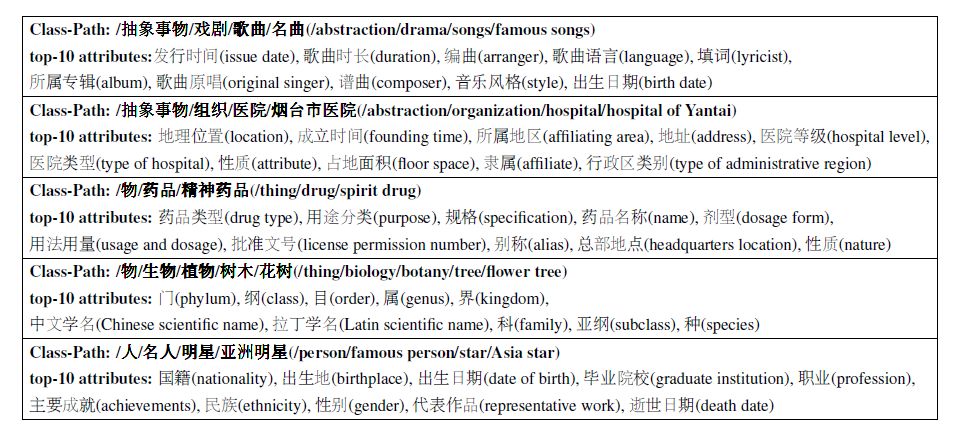
经过筛选,在P@k评估中包含了240条待测试的概念路径中的184条(见表1)。最终结果如表3所示,括号中的数字为具有过滤后的概念路径的实体的数量。由结果可知,可以利用学习到的路径表示来准确预测概念路径对应的属性,全局结果的P@1的准确率超过75%,不同实体类别中P@10的准确率接近70%。事实上,这些给定的概念路径在训练阶段是看不到的,但是由结果显示属性可以准确的映射到相对应的概念路径上,这表明《大词林》的构建是动态的。我们还从表3的预测结果中列出了一些例子,并在表4中标注了中文和英文。注意,这些例子对应的概念属于不同的领域,但是我们的模型可以准确地预测与这些领域相关的属性。
表3 APC任务的P@k值
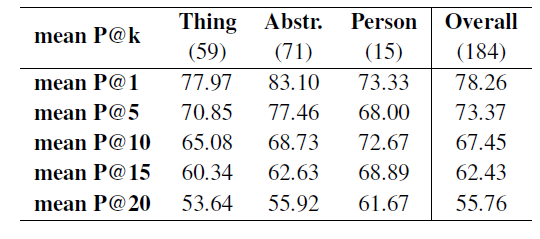
表4 不同领域的概念路径属性映射情况
4.结论
属性是实体的重要组成部分,属性添加一直为知识图谱研究领域的学者所关注。本文围绕《大词林》研究了如何为知识图谱自动添加属性这一问题。通过联合学习《大词林》中实体的概念层次结构表示和属性的表示,可以获得实体概念至属性的映射,自动地为实体添加合适的属性。在实验阶段,我们设计了两种不同的属性获取任务以验证本文提出的属性获取方法的准确性,包括给定实体预测隶属于实体的属性以及给定实体的某个概念预测属于该概念下的属性。实验结果表明,本文提出的属性获取方法能够将属性准确地映射到实体对应的某个概念下,能够实现自动的属性获取,提高了知识库的可扩展性和提升了知识库的构建效率。
参考文献
[1] Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Jason Weston, and Oksana Yakhnenko. 2013. Translating embeddings for modeling multi-relational data. In Advances in neural information processing systems, pages 2787–2795.
[2] Yankai Lin, Zhiyuan Liu, Maosong Sun, Yang Liu, and Xuan Zhu. 2015. Learning entity and relation embeddings for knowledge graph completion. In AAAI, pages 2181–2187.
[3] ZhenWang, Jianwen Zhang, Jianlin Feng, and Zheng Chen. 2014. Knowledge graph embedding by translating on hyperplanes. In AAAI, pages 1112–1119.
[4] Han Xiao, Minlie Huang, and Xiaoyan Zhu. 2015. From one point to a manifold: Knowledge graph embedding for precise link prediction. arXiv preprint arXiv:1512.04792.
[5] Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long short-term memory. Neural computation, 9(8):1735–1780.
[6] Alex Graves and Jürgen Schmidhuber. 2005. Framewise phoneme classification with bidirectional lstm and other neural network architectures. Neural Networks, 18(5):602–610.
本期责任编辑:丁 效
本期编辑:赖勇魁
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套!
![]()
![]()
![]()
后台回复【五件套】
下载二:南大模式识别PPT
![]()
后台回复【南大模式识别】




由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!






