浅谈酒精代谢与机器学习数据流转机制
点击蓝字关注这个神奇的公众号~
熟悉我的朋友都知道我平时喜欢小酌一杯,主要是借助酒精来活血化瘀,做到气血通畅。刚好我妈寄给了我一壶纯天然绿色无公害葡萄酒。

可能有些同学刚入门机器学习,还不清楚整个数据在机器学习过程中是如何流转的,今晚我们边喝边聊,就说酒精代谢和机器学习数据流转的关系。
请先看下图,这就是一张数据流转的架构图,我先喝上一大口,然后给大家慢慢讲解。
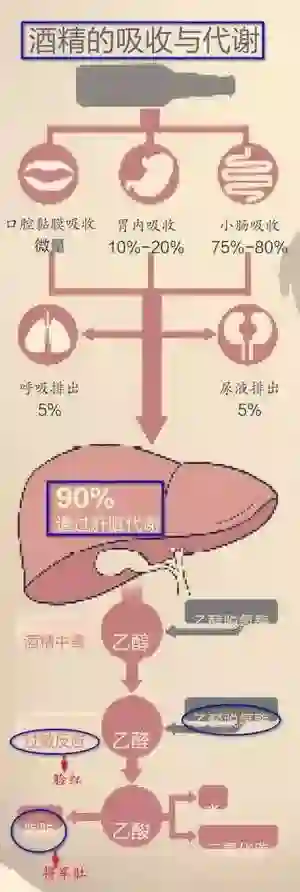
从上到下来看上面这张图,首先我们把机器学习需要用到的数据比作是嘴里的红酒,通常数据有很多维度,在做某一垂直领域的业务的时候,往往是提取部分维度的数据而不是全维度,就像红酒也会根据自身酸、酒精、水、无机物等成分不同而被口腔黏膜、胃、小肠各自吸收一样,第一步要根据业务需求挑选合适的数据字段。
到了第二步,也是很关键的一步,去噪。把数据中的对结果干扰大的数据去除,比如空值数据,乱码数据等。红酒经过吸收,也会将这类没有营养的降解物或者水分通过人体的下水道排出体外,这就是为啥,喝酒容易上厕所。
第三步,到了红酒到了肝脏部分,就像是数据进入到了计算引擎去计算。酒精会在肝脏中进行氢反应,这类化学反应有点像数据和算法的结合。这里有一点要注意的是,酒的摄入量不得超过肝脏的分解速度,数据也不要超过计算引擎的计算能力。如果酒真的这么多(数据量大),请采用分布式计算,多找几个人一起喝。
最后一步,机器学习算法生成的是一个模型,这个模型会被用来做预测。那红酒喝下去生成的是啥呢,就是人的主观经验模型,经过长年的饮酒,你的身体会有一种认知,喝多少会上头,喝多少会飘飘欲仙,喝多少会醉,这就是身体机能中的模型。喝的次数越多,对酒量越有认知,就像计算迭代越多次模型越精准。
最后的最后,我感觉有点晕了,请大家关注“凡人机器学习”,一个不平凡的技术型公众号,谢谢。
登录查看更多
相关内容





相关VIP内容
相关资讯
相关论文