AIDL专栏|社会媒体数据挖掘与信息传播预测
AIDL简介
“人工智能前沿讲习班”(AIDL)由中国人工智能学会主办,旨在短时间内集中学习某一领域的基础理论、最新进展和落地方向,并促进产、学、研相关从业人员的相互交流,对于硕士、博士、青年教师、企事业单位相关从业者、预期转行AI领域的爱好者均具有重要的意义。2018年AIDL活动正在筹备,敬请关注获取最新消息。
导读
在第三届“人工智能前沿讲习班”上,中科院计算所的沈华伟博士做了题为《社会媒体数据挖掘与信息传播预测》的报告。报告介绍了媒体数据挖掘中的学术功劳分配问题、社会媒体的信息传播预测以及影响力最大化研究。本文根据沈华伟博士当日报告内容整理发布,对于相关领域的研究工作具有长期价值。
关注本公众号,回复“沈华伟”,获取完整版PPT。
分享PPT仅供学习交流,请勿外传
讲师简介
沈华伟,博士,中国科学院计算技术研究所研究员,中国中文信息学会社会媒体处理专委会副主任。研究方向为网络科学和社会计算。先后获得过CCF优博、中科院优博、首届UCAS-Springer优博、中科院院长特别奖、入选首届中科院青年创新促进会、中科院计算所“学术百星”。2013年在美国东北大学进行学术访问。2015年被评为中国科学院优秀青年促进会会员(中科院优青)。获得国家科技进步二等奖、北京市科学技术二等奖、中国电子学会科学技术一等奖、中国中文信息学会钱伟长中文信息处理科学技术一等奖。出版个人专/译著3部,在网络社区发现、信息传播预测、群体行为分析、学术评价等方面取得了系列研究成果,在Science、PNAS等期刊和WWW、SIGIR、CIKM、WSDM、AAAI、IJCAI等会议上发表论文60余篇,引用1700余次。担任PNAS、IEEE TKDE、ACM TKDD等10余个学术期刊审稿人和WWW、CIKM、WSDM等20余个学术会议的程序委员会委员。

1. Collective creditallocation in science
1.1 Introduction
学术论文也可以认为是社会媒体的一种载体,因此报告的第一部分是学术中的功劳分配问题(credit allocation)。下图展现了1900年到2012年学术界发表的论文中多作者论文所占比例的变化,在过去100年内几乎每10年增加7个百分点。
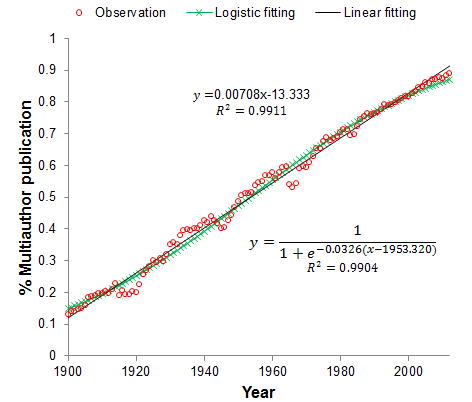
这意味学术界的合作模型在改变,多作者合作的情况越来越普遍。这就引发了一个新的问题,如何在多作者合作模式下,进行功劳分配。下图是一个直观的例子。

三篇文章成果都获得了诺贝尔奖,红框中的是获奖者,可以发现第几作者获奖并没有什么规律
研究多作者合作情况下的功劳分配问题有以下几个挑战:(1)多作者合作打破了作者贡献和获得的功劳之间的对称性;(2)作者的实际贡献很难量化;(3)每个学科有自己的非正式的功劳分配规则,各不相同。研究功劳分配问题不仅在获奖时有用,在评学术职称、学生毕业等都有这种需求。
1.2 Existing Methods
现有的方法主要有以下几种。第一种是把每个作者都当做文章的唯一作者, Google Scholar就是这么做的,搜索作者名字,会显示所有标注其名字的论文,不论是第几作者也不论贡献多大,带来的问题是“通货膨胀”。
第二种是平分,但这种方法会遏制学术领导者的贡献力。
第三种是按照作者顺序或角色分配功劳。确定作者顺序本身就很复杂,而《Science》《Nature》等所要求的“角色”(用来表明各作者在研究中做了哪些工作),往往也不作为功劳分配依据,只作追责依据。
这些方法忽略了一个问题,功劳分配不是作者决定的,而是学术圈决定的。学术圈采用什么规则?举例来看:

上图案例A和B分别是2010年的诺贝尔化学奖和物理学奖的获奖文章,但化学奖只颁给了第二作者Negishi,而物理学奖是两个作者共享。分析发现,和案例A中获奖文章经常一起引用的文章都是Negishi的工作,而和案例B中获奖文章经常一起引用的文章都是Geim和Novoselov合作的。
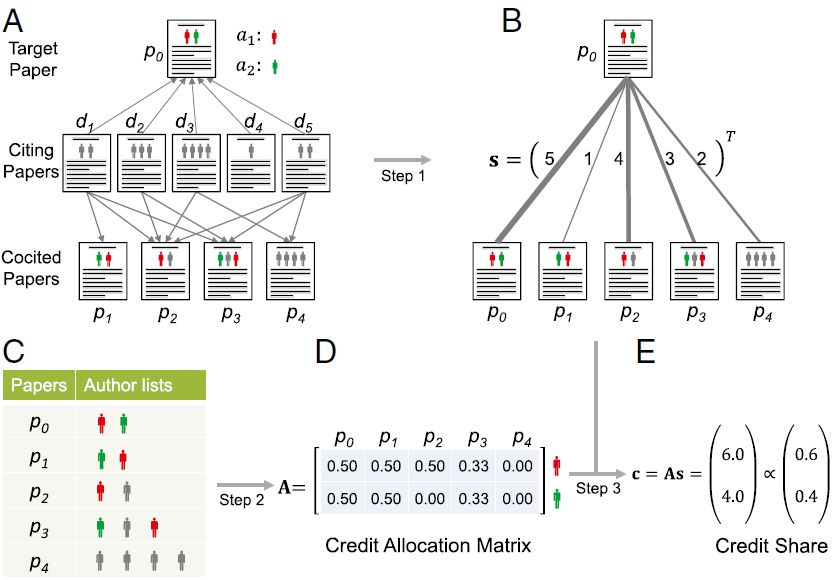
Shen &Barabási, PNAS, 2014
1.3 Our method
将这个思路表示成算法[1]。如上图,文章p0有两个作者,标记为红人和绿人。找到所有引用p0的文章,再看这些文章还引用了哪些文章pj(0≦j≦n),计算p0和pj被共同引用的次数作为权重s,之后将权重乘功劳分配矩阵A得到分配比例,分配矩阵可以根据学科不同特点构造。

采用这个方法验证之前的案例A和B,计算出的功劳分配比例与真实获奖情况相符。用该算法在APS(American Physical Society)和WOS(Web of Science)数据集进行验证,预测获诺奖文章中哪位作者是诺奖得主,结果如下。
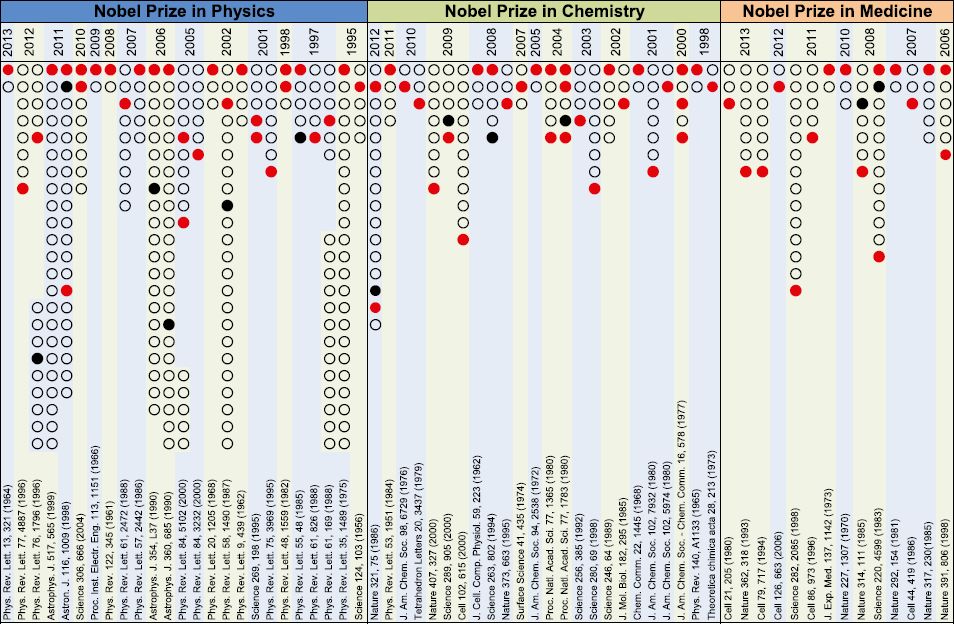
主要测试物理学奖、化学奖和医学奖,圆圈代表文章作者,红色代表预测结果与真实获奖者匹配,黑色代表预测功劳很高但未获奖作者
可以看到预测准确率较高,但也存在错误情况,一个典型的错误是1997年诺贝尔物理学奖得主预测。
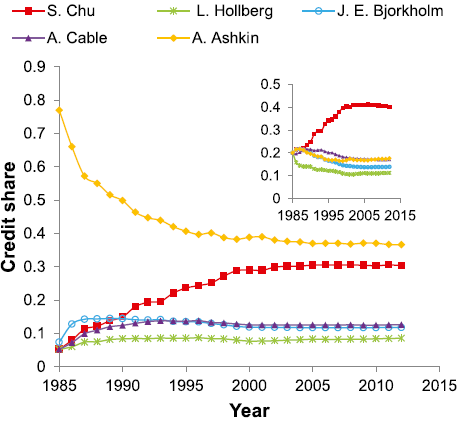
The credit share of1997 Nobel prize-winning paper
(Phys Rev Lett 55,48 ,1985)
实际获奖者是S.Chu(朱棣文),算法预测获奖者是他导师A.Ashkin。将朱棣文加入团队前导师的文章去掉,预测结果如右上角所示,符合获奖状况。所以算法的错误原因是直接将所有论文在一起统计,导师从业时间更长,论文积累更多,预测时更有优势。这个错误带来的启发是,可以看整个学术生涯中功劳分配的比例随时间变化的趋势,即演化(evolution)。
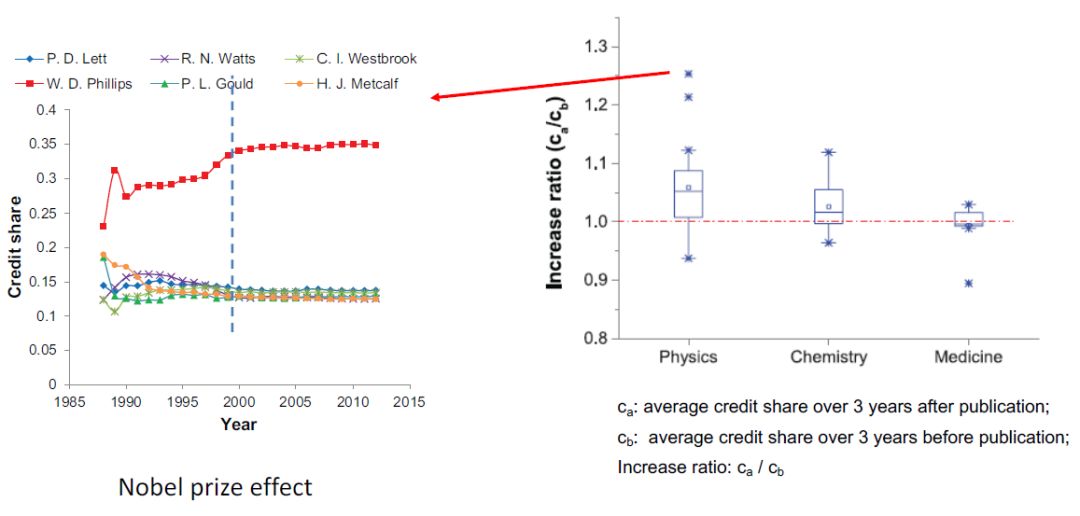
上图左侧是1997年另一篇诺贝尔物理学奖文章作者的功劳分配演化图,诺奖得主W.D.Philips在获奖之后功劳分配比例更高了,类似“富者越富”现象。该现象在物理学特别明显,在化学不明显,医学几乎没有。
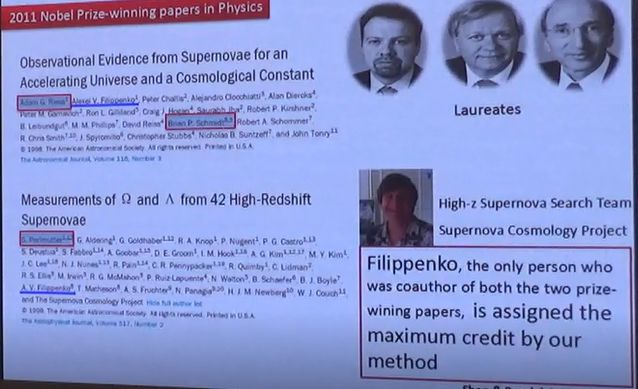
如图是另一个典型错误。两篇文章同时获得了诺贝尔物理学奖,获奖者是红线框出的三个作者,但我们算法算出来的第一是蓝线标注的作者。原因是只有他是两篇文章的共同作者,但他在团队中实际贡献很小,这说明我们算法只根据数据计算还是不准确的。
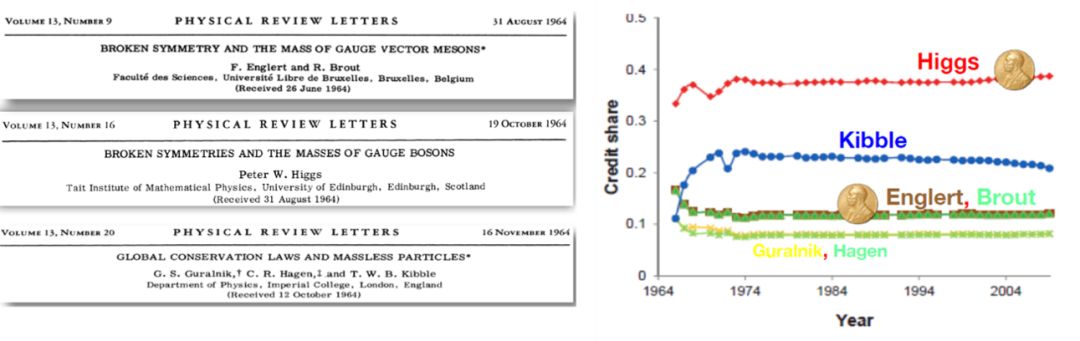
2013年诺贝尔物理学奖授予了希格斯玻色子的发现,有三篇独立的文章都对此有贡献,上图右侧是对这三篇文章的作者获诺奖情况的预测,实际上只有Higgs和Englert两人获奖。这个奖项颇具争议,很多人认为Kibble应当获奖,但从这个例子可以看出我们的算法不仅能计算一篇文章中各作者的功劳,还可以解决多人独立从事同一研究,谁该获得认可的问题。
学术功劳分配研究工作给了我们三个启示:(1)功劳分配不是按作者顺序,也不是按真实贡献,而是按“被感知”的贡献;(2)已成名科学家和年轻科学家合作时得到的好处更多;(3)功劳分配比例是动态量,会随时间演化。
2. Cascade Prediction
2.1 Introduction
第二部分工作是Cascade Prediction,即信息传播预测,可以预测社会媒体中的话题热度等。Cascade的数据形式一般有三种:

Three kinds of cascades
第一类是只记录行为的时间信息,比如网页被访问的时间记录、查询被使用的时间记录等;第二类cascade不仅记录时间,还记录用户,比如网页是哪个IP地址访问的,微信是哪个人转发的等;第三类是时间、转发用户、原发用户三元组,不仅要记录什么人什么时间发布,还要记录是从哪儿看到的,比如微博以及学术论文引用等。
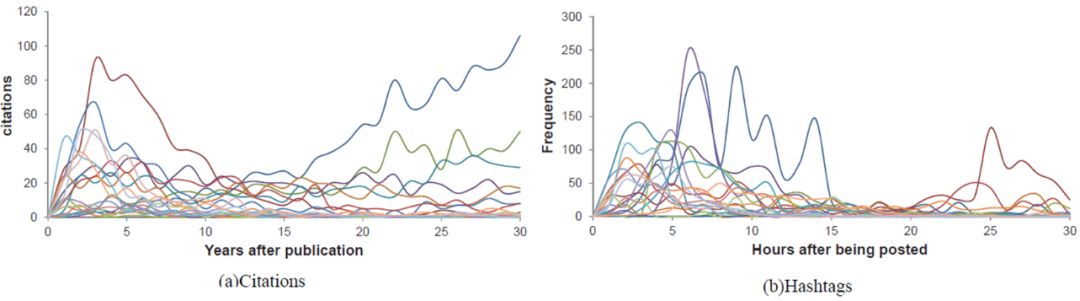
具体来看,上图(a)是论文的引用,时间单位是年,发表后每一年被引用多少次就是传播的动力学过程(Cascade Dynamics)。(b)是Twitter话题频率,时间单位精确到小时,微博可以精确到秒。时间单位很重要,如果选错预测结果会很差。
2.2 Problem formulation

Problem formulation
下面进入问题的形式化,如图,问题从输入和输出分四类。输入分两类,一类是事先预测,比如微博刚发出来就能知道会有多少人转发;另一类预测需要观测一段时间,比如微博观测两小时或论文观测两年后再预测。输出也分两类,一类是回归(Regression),预测论文引用量、微博转发量、微信评论数、视频下载量等;另一类是分类(Classfication),比如预测一个微博会不会火,变成二分类问题。基本上事先预测都做分类,观测一段时间才能做回归。
2.3 Challenges
预测不火的消息很容易,但预测哪个消息会火特别难。主要有两个原因,第一个是消息的热度动力学过程(popularity dynamics)是幂律分布的,第二个是没有Null-model,即没有能刻画这个问题的干净的模型,系统不是独立的系统,易受外界因素影响,比如预测一条微博会转200次,发布者可能专门雇很多人转到500次。
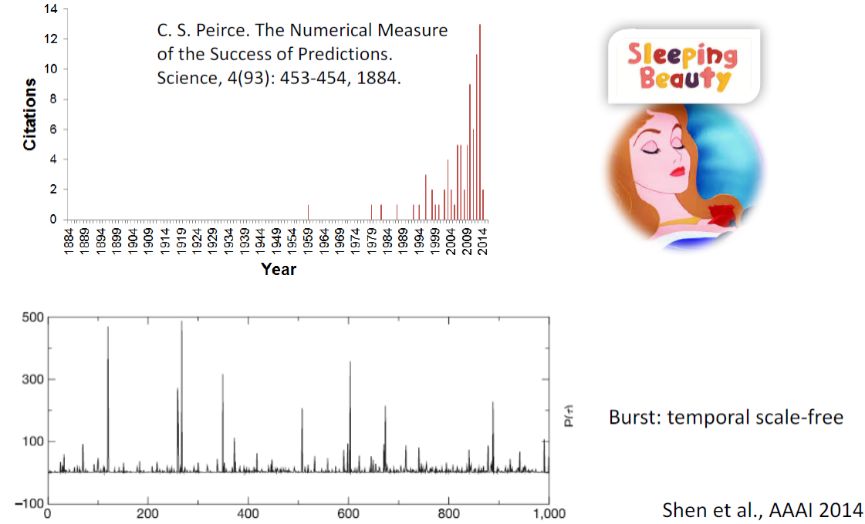
来看两个真实的例子。1884年《Science》刊登了The Numerical Measure of the Success of Predictions这篇文章,近一百年没人引用,后来突然就火了,这个现象被称为“睡美人”。那么多“睡”的文章哪个是“美人”,又将由谁“唤醒”,是预测的难点。另一个难点是关于预测的时间,几年前《爆发》这本书中提到人在行为过程中,某一段时间会一直干一件事,然后停好长时间,再一直干这件事,再停好长时间,这也为我们的预测提供挑战。
2.4 Existing Methods
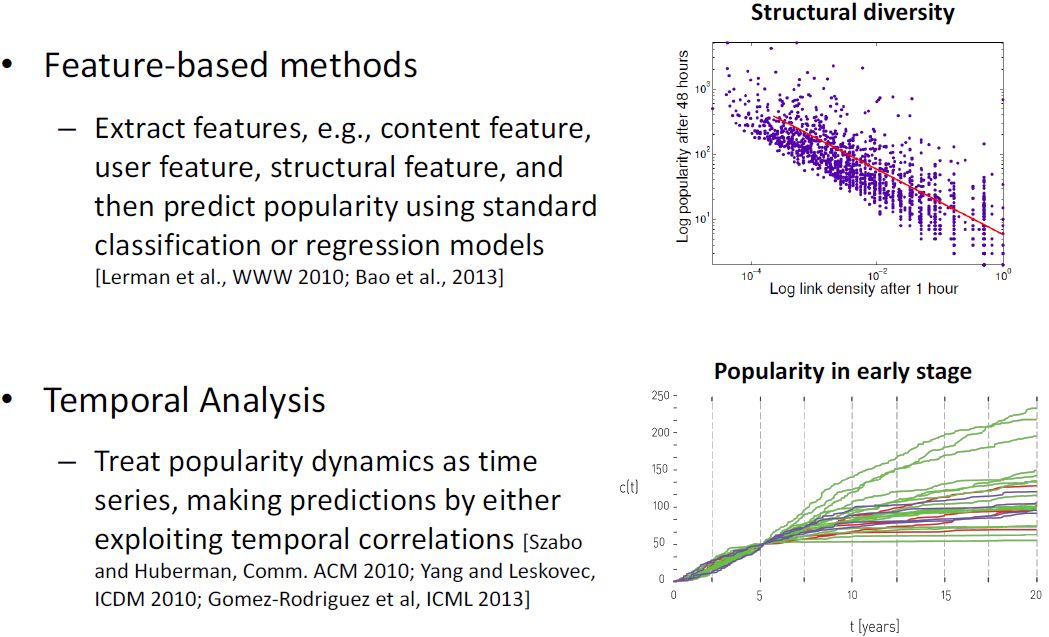
首先是feature-based方法。特征主要包括用户特征、内容特征、结构特征和时序特征。Feature-based方法的好处是能够提供一些领域常识,比如预测准确率一般是多高,任务做到什么水平可行,以及哪些特征有用。
研究发现主要有用的是时序特征,所以另一种方法是时序分析,采用各种时序模型,但这种方法的一个天然问题是,用方差小的变量预测方差大的变量,效果较差。比如用论文发表五年之后的引用次数来预测二十年后的引用次数,肯定预测不好。
所以feature-based方法和时需分析模型都不行,虽然提供了很好的baseline,但没有对传播预测问题有任何理解
2.5 Reinforced Poisson Process Model [2]

Key factors topopularity dynamics
我们在理解传播过程当中,主要考虑了三个关键因子:第一,信息本身固有的质量,比如一看就容易火的话题、质量很高的论文等;第二,“富者愈富”机制,即消息的转发关注量越大,其吸引力也越大;第三,时间衰减效应,即,随着时间流逝,信息的吸引力也会随时间进行一定程度的衰减。将这三个因子相乘就得到我们的预测模型。
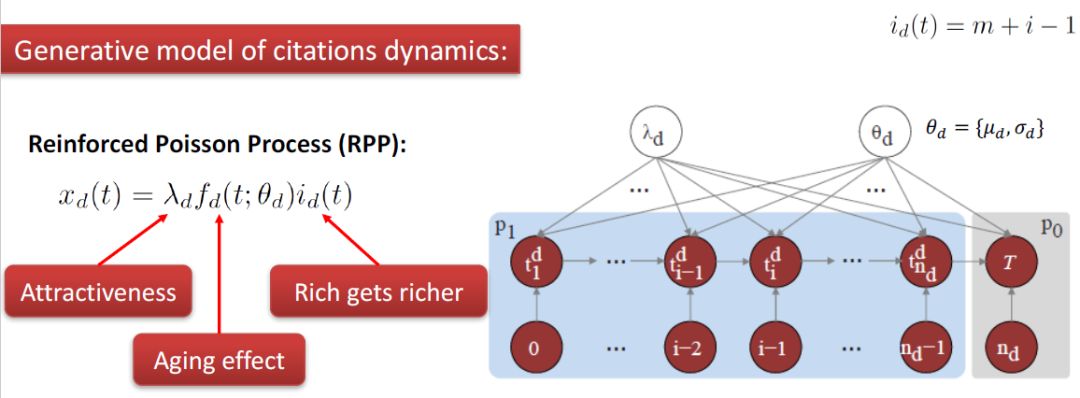
Reinforced Poisson Process
之后就使用机器学习,需要足够多的数据量来训练。我们的模型比较简单,在机器学习得到模型参数之后,可以结合微分方程直接得到论文在某时刻的引用量。

我们来看这个三因子模型能否对论文引用动力学过程进行很好地刻画。如下图所示,对六个不同期刊的论文进行刻画,结果一样,只是参数不同,说明这个模型虽然简单,但刻画到了规律[3]。
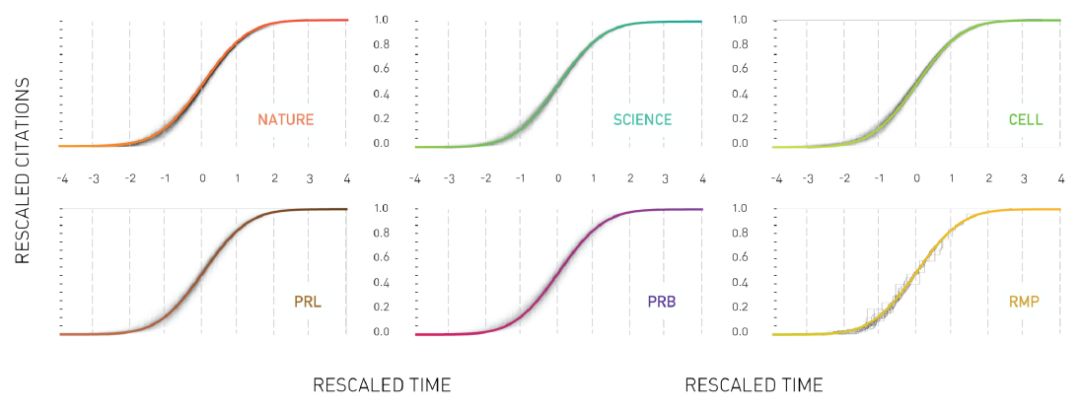
Universal citationdynamics for different journals
RPP模型的另一个优势是,它是生成式模型,能够重现论文引用的分布。
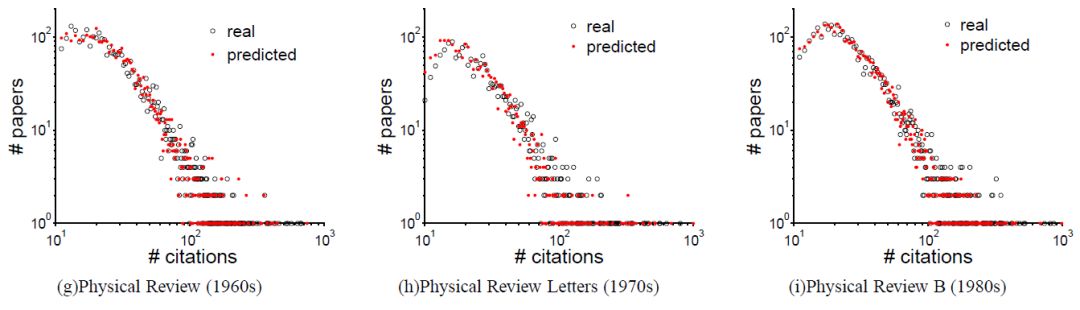
The RPP model is able to reproduce the citation distribution, indicatingthat the RPP model can also be used to model the global properties of citation system.
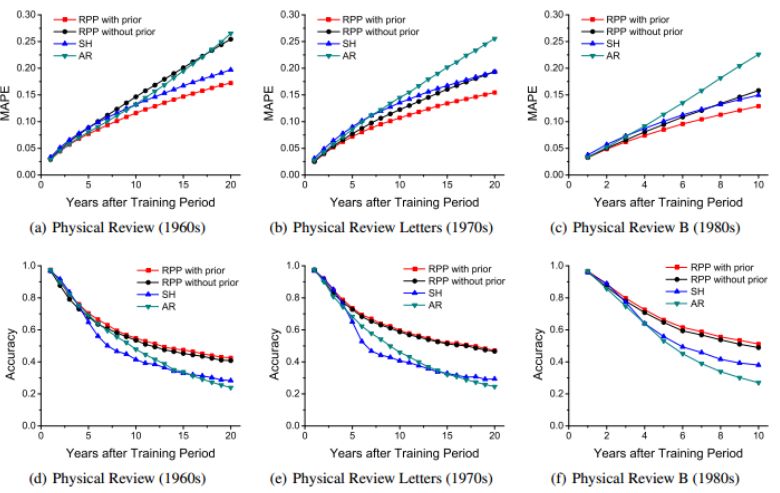
RPP模型对论文引用数的预测结果,明显优于经典的AR方法(autoregression)和SH方法(the linear regression method of logarithmicpopularity)。
2.6 Extensions of the RPP model

之后有多种对RPP模型的扩展,这里主要介绍第三种扩展[4]。
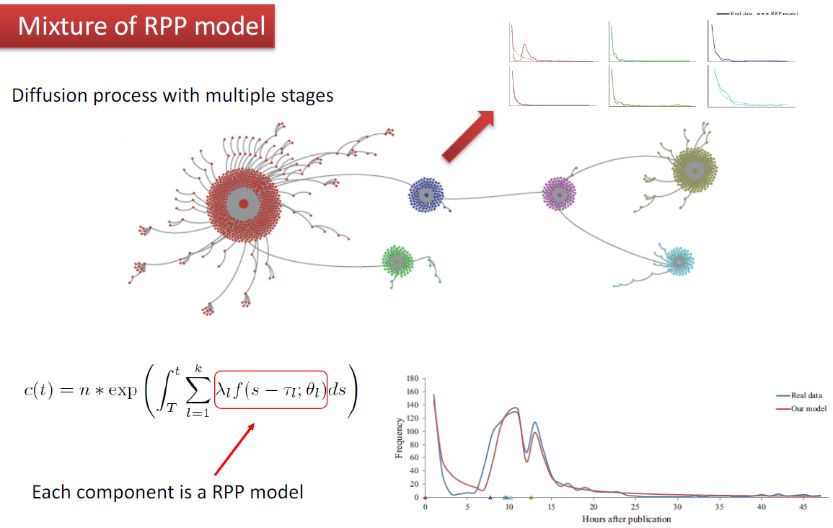
如图,RPP模型能够预测每个单独的传播过程(图中的小圆圈),但难以预测整个传播过程,它可能是由6个传播过程叠加出来的。可以先分类,每一类采用一个模型,整体做一个混合模型。可以看到整体预测结果比较准确,但红色圆圈部分预测不准。这是因为红色部分的转发量太大,是分两天完成的,时间不均匀(比如微博,白天和半夜在线人数不同,转发量也受到影响),不符合我们原来认为的传播在均匀介质中进行。而其他传播过程转发量很小,所需时间短,近似均匀,所以预测比较准。之后又有方法加入了对时间不均匀性的刻画,采用Hawkes Process[5],效果有所提升。
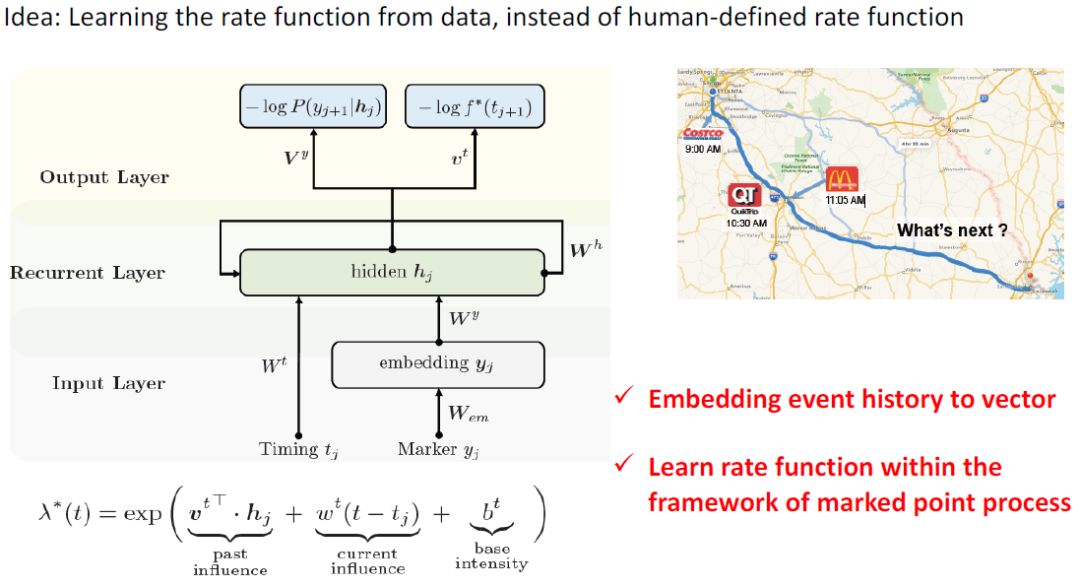
Recurrent Marked Point Process (Du et al., KDD 2016)
也有采用深度学习的方法,好处是不再需要人来定义各种扩展,直接自动学习得到函数,输入的特征也可以自动提取。但整体框架还是对速率函数进行扩展,把三项分别用RNN进行学习。后来还做到了端到端[6].
2.7 Summary
Cascade Prediction需要理解传播过程,需要知道消息如何吸引关注,受什么因素影响。需要将这些因素在模型中刻画好,还要有很好的泛化能力。
目前的趋势是:从feature-engineering到feature-learning;从无监督方法到有监督方法。CascadePrediction的学术价值很大,至今仍然是一个开放的问题。
3. Influence Maximization
影响力最大化问题就是给定一个社会网络,如何找到一些种子节点来最大化信息传播的影响。
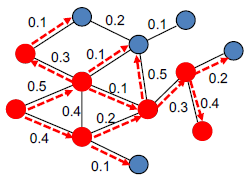
Spread of influence
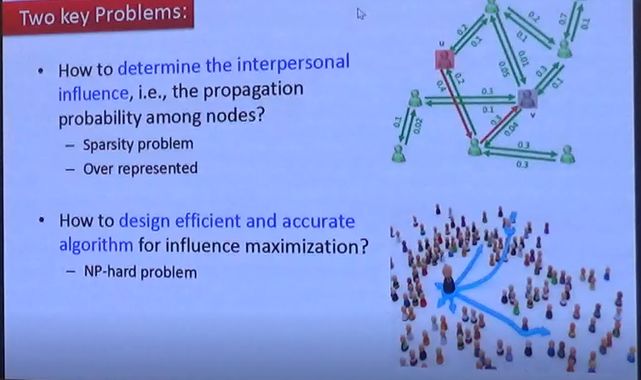
Two key problems
现存的方法主要有两种。第一种是贪心算法,每次都选当前传播影响力最大的节点,之后选剩下的网络中影响力最大的节点,一个一个加进来。这个算法可以保证近似比是1-1/e-ϵ,即算法最差结果是最优解的63%,经常是90%多。缺点是算法很慢,单机(3.4G的CPU,32G内存)最多跑几千万个节点。另一种算法是启发式算法,运算很快,但没有近似比保障,有时候效果很差。我们希望找到效果较好且运算较快的方法。

影响力最大化问题的目标函数有三个性质。第一,非负;第二,单调,随节点增多影响力不会变小;第三,边际效益递减,比如3个节点时再加一个节点,带来的收益比5个节点时再加一个节点带来的收益大(注:这3个节点被包含在5个节点中)。贪心算法要达到1-1/e-ϵ的近似比需要精确地计算𝜎(S),否则会带来误差,因此计算过程中需要花很多代价进行蒙特卡洛模拟来尽可能估计准𝜎(S),从而导致运算很慢。
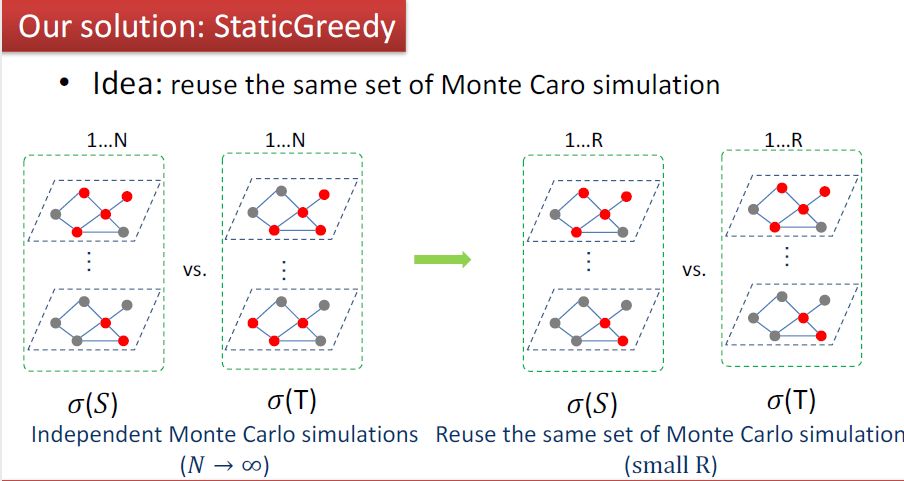
我们换一种思路,不用分别估计𝜎(S)和𝜎(T),而是直接比较二者谁大谁小[7]。实验证明这样可以将蒙特卡洛模拟的次数降低2~3个数量级,运算时间降低3~4个数量级。
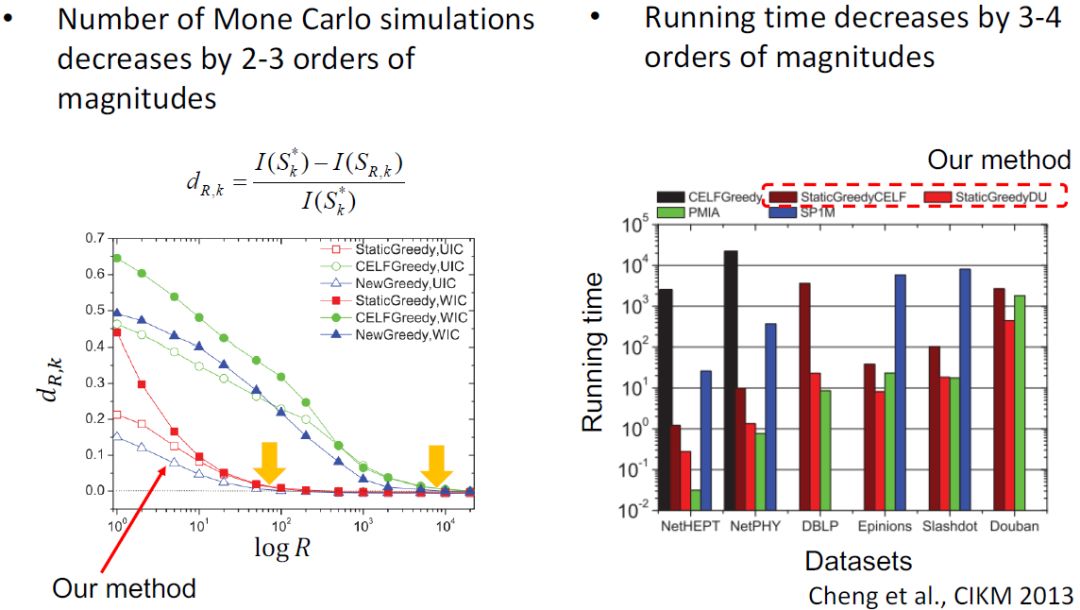
Static Greedy:Result
为适用于真实社会网络需要进一步提速。贪心算法选出一个个节点,需要满足边际效应递减,最终得到按边际效应递减排序的节点列表。所以一个思路是直接找到这个列表[8],随便给一个节点序,看是否满足边际效应递减,如果不满足,调整相应节点,直到满足。该方法使耗时进一步降低了1~2个数量级,可以在单机上跑完真实的微博7亿数据集。
References
[1] Hua-Wei Shen, Albert-László Barabási.Collective credit allocation in science. PNAS,111(34):
[2] Huawei Shen, Dashun Wang, ChaomingSong, Albert-László Barabási. Modeling and predicting popularity dynamics viareinforced Poisson process. AAAI 2014.
[3] Dashun Wang, Chaoming Song, Hua-WeiShen, Albert-László Barabási. Response to Comment on “Quantifying long-termscientific impact”. Science, 345:149, 2014.
[4] Jinhua Gao, Huawei Shen, Shenghua Liu,Xueqi Cheng. Modeling and predicting retweeting dynamics via a mixture process.WWW 2016.
[5] Bao P, Shen H W, Jin X, et al. Modelingand Predicting Popularity Dynamics of Microblogs using Self-Excited HawkesProcesses. WWW 2015.
[6] Li C, Ma J, Guo X, et al. DeepCas: AnEnd-to-end Predictor of Information Cascades. WWW 2017.
[7] Suqi Cheng, Huawei Shen, Junming Huang,Guoqing Zhang, Xueqi Cheng. StaticGreedy: solving the scalability-accuracydilemma in influence maximization, CIKM2013.
[8] SuqiCheng, Huawei Shen, Junming Huang, Wei Chen, Xueqi Cheng. IMRank: influencemaximization via finding self-consistent ranking. SIGIR 2014.
感谢AIDL志愿者顾一凡协助整理!
志愿者持续招募中,有意者联系微信号“AIDL小助手(ID:must-tech)”

历史文章推荐:
AI综述专栏| 大数据近似最近邻搜索哈希方法综述(下)(附PDF下载)
2018CCAI丨不忘初心,方得始终——我国人工智能发展如何务实推进
AI综述专栏| 大数据近似最近邻搜索哈希方法综述(上)(附PDF下载)





