工业界如何用知识图谱搞事情?我的CCKS20大会参后感

上周末去南昌参加了CCKS2020[1],全国知识图谱与语义计算大会。北京已经是凉飕飕的天气了,而南昌还有大大的太阳和暧暖的风,吃的也很合口味,还看了秋水广场的喷泉表演,真是一次圆满的蹭会。

说回正题,我目前的主要工作和图谱相关,所以参会的目的是向业界小伙伴们学习如何用图谱花式搞事情。
会议的session很多[2],我重点关注了百度、阿里、美团、小米、华为、京东等厂的报告。下面就来聊聊工业界的知识图谱技术现状。
知识图谱的构建
知识图谱的构建是提取结构化知识的过程,是图谱应用的前提。大部分都涉及以下几个阶段的流程:
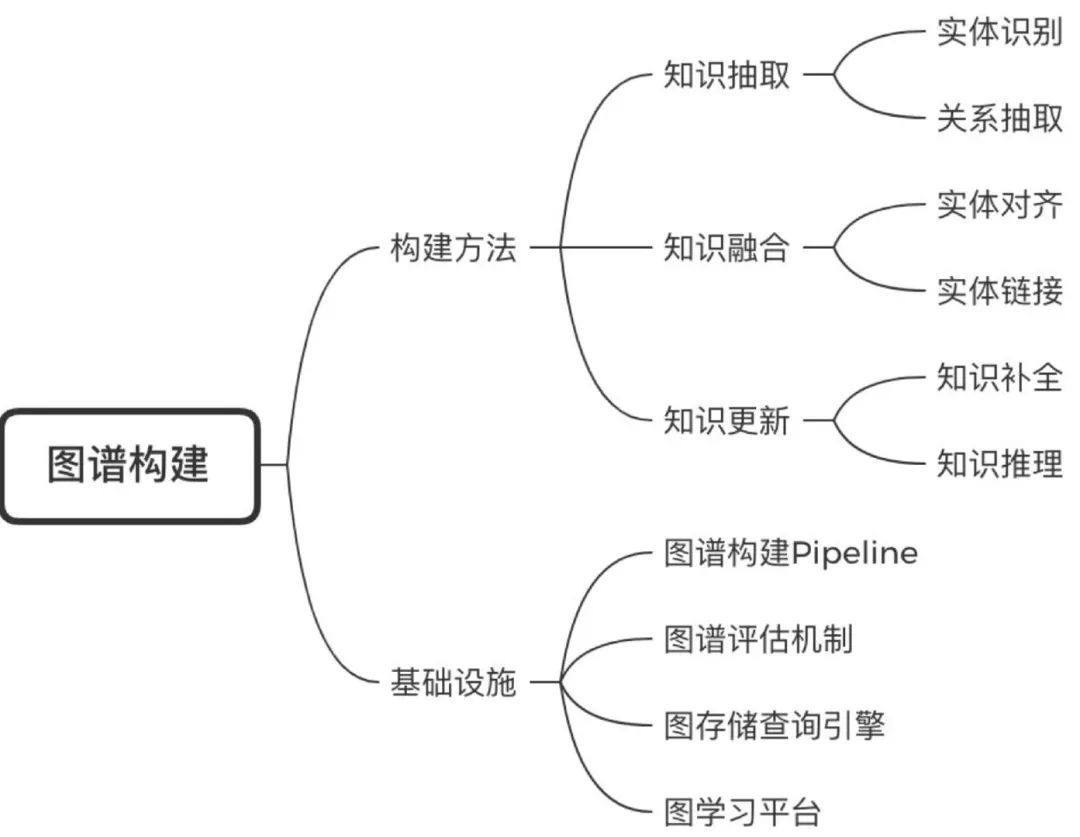
对于学术界来说,算法关注的点主要在构建方法上的各个细节,但工业界的构建情况其实有些gap。
首先,业务图谱的大部分数据来源于结构化信息。除了百度这样的通用搜索引擎,业界大都构建与业务息息相关的垂类图谱,而因为本身是IT行业的关系,数据的信息化会好一些。所以图谱中大部分核心节点来源于结构化数据,比如美团的商家信息、淘宝京东的商品信息和本身的类目、属性体系。
但结构化数据的丰富并不意味着业界的图谱数据更易获取,因为业务图谱同时要求广度和深度,要覆盖尽可能多的节点和关系、拥有多维度的知识(核心节点的各种属性、标签),来提升业务的召回。这时候可以利用UGC和用户行为数据,去挖更多的节点。
比如对于电商来说,商家只给出了商品的各个参数,而突然有一天马保国老师推荐了它,大部分用户会去搜“马保国推荐”而不是商品的准确名字,这样就造成了用户query和商品的gap,需要给商品打上更多的tag去扩召回。
挖出新的节点后,就要和老节点建立关系,而这里也很难用一个关系抽取的任务去解决。因为业务数据并没有大家想的那么多,也就没法找到节点的共现语料。所以可以将节点间的关系抽取转化成判别任务。
除了构建算法外,同样重要的还有偏工程的基础设施。这里我列了四点:
-
图谱构建Pipeline:真正把节点挖掘、关系判别、以及后续的知识融合更新整个系统高效地run起来,为业务提供源源不断的支持 -
图谱评估机制:这个是最重要的,大部分场景都是准确率优先,需要对pipeline中的每个环节都进行离线评估 -
图存储查询引擎:保证数据的高效存储和查询,还有可视化 -
图学习平台:更high-level的设施,用来进行graph embedding的计算
知识图谱的应用
比起构建,知识图谱的应用更有意思一些。
最常见的搜索推荐落地就不说了,另一个很大的落地场景则是KBQA,华为云语音语义创新Lab、美团语音交互中心、京东AI研究院、小米小爱、平安人寿AI的报告中都介绍了相关实践。
在智能客服场景下,一般有KBQA、FAQ和阅读理解三路召回。小米小爱的报告提到目前KBQA的答案采用占比是最高的。从实用角度,KBQA相比FAQ需要的人工配置会更少、对训练数据的利用更加充分,同时更加官方和规范。
FAQ是问题pair匹配,问“寿险怎么买”和“意外险怎么买”是两个问题,而对于KBQA来说“怎么买”这个关系是一样的,只需要区分核心实体就可以,换成别的也是一套逻辑,而FAQ则需要增加新的标准问配置。
另一个火热的场景就是医疗,百度和医渡云的报告都围绕这个主题。医疗领域的药品信息、疾病信息结构化之后都很有价值,这里印象深刻的场景主要是处方推荐审核,我国三四线城市以及农村的部分医疗人员专业水平与经验可能不足,利用药品的主治疾病、副作用信息可以辅助医生开处方。
相比以上的互联网和医疗领域,还有一个场景有着更多的非结构化数据,那就是金融。不过金融场景的大部分精力还是在静态、动态图谱的构建上,要对海量的金融新闻进行及时处理。同时这个场景需要更多的推理能力,比如A公司增加了一个股东B,那B入股的其他公司也就与A有了联系。
知识图谱vs向量表示
讲完了业界的图谱构建和应用现状,想再谈一下对于图谱和向量表示的看法。
其实在选择知识图谱这个领域之前,我最纠结的一个问题就是:BERT发展得这么好,知识图谱会不会被丢掉?
不仅担心图谱的可替代性,也担心自己因为掌握这个工具而思维固化。比如一个语义理解任务,我可以选择去怼更多的数据、也可以选择优化模型结构、还可以选择引入外部知识,我担心自己会“为了用图谱而用图谱”,丧失了其他路径的操作能力。
不过真正做了之后,却发现自己之前的顾虑有些多余。在业界,图谱是为应用而生的,有的场景适合,而有的场景不需要。在处理一个问题时,我们会将它不断细分,再解决不同的子问题,图谱只需要被用到合适的地方就好了。
再回到图谱是否会被表示替代的问题,我认为几年内肯定不会,但随着技术的突破,会有更高维度的非文本表示来存储知识。
图谱说白了还是一个中间阶段的表示,我们都知道更干净更优质的文本会让模型得到更好的效果,我认为图谱work也是这个道理。不少人觉得图谱的可解释性强,但可解释性强的特征工程也在一点点被万物embedding取代。而且知识图谱很多的节点、关系都是人工先定义好再去挖掘的,人工筛选信息的能力可能这个阶段还是强于模型,但再过几年就不一定了。
与其担心一个技术过几年是否被取代,不如提升自己的学习能力,来跟着rumor我紧追AI前沿叭~

彩蛋
本以为会见到李航老师,结果变成了一场云面基

去八一大桥撸了黑猫白猫(请原谅我的摄影技术)


参考资料
2020全国知识图谱与语义计算大会: http://sigkg.cn/ccks2020/
[2]CCKS20会议日程: http://sigkg.cn/ccks2020/?page_id=440
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏


