动态 | DeepMind 发布 VQVAE-2,图片生成效果超越 BigGAN

AI 科技评论按,近日,DeepMind 的研究人员宣布,VQVAE-2 问世了!
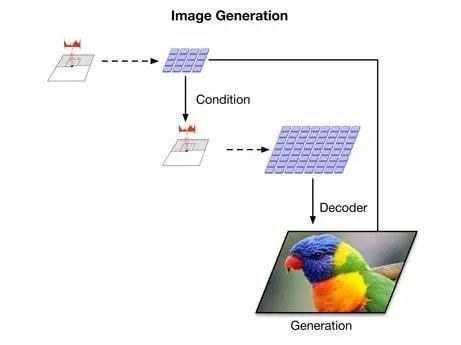
VQ-VAE 是 Vector Quantised-Variational Auto Encoder 的简写,此次的 VQ-VAE2 是 DeepMind 基于第一代 VQ-VAE 研究出来的改进模型。相关的论文已被 ICLR2019 接收为口头报告论文,DeepMind 研究员 Suman Ravuri 做了精彩的现场演讲。
论文 ARIXV 链接:http://arxiv.org/abs/1906.00446
论文摘要如下:

我们探讨了矢量量化变分自动编码(VQ-VAE)模型在大规模图像生成中的应用。为此,我们对VQ-VAE 中使用的自回归先验进行了缩放和增强,目的是生成比以前具有更高相关度和保真度的合成样本。我们使用简单的前馈编解码器网络,这让我们的模型对于编码\解码速度至关重要的应用非常有用。此外,VQ-VAE 仅仅只需要在压缩潜在空间中对自回归模型进行采样,这比在像素空间中的采样在速度上快一个数量级,对于大型图像尤其如此。我们证明了一个 VQ-VAE 的多尺度层次组织,加上强大的先验潜在代码,能够在多种数据集(如 ImageNet)上生成质量与最先进的生成对抗网络相媲美的样本,同时不受 GAN 的已知缺点,如模式崩溃、多样性的缺乏等的影响。
DeepMindAI 的这一研究表明,当用于训练分类器(数据增强)时,GAN 生成在看起来真实的样本的能力有限。初始分数与分类表现呈负相关。
论文的三位作者之一,DeepMind 的研究人员 Aaron van den Oord 在 twitter 上表示,这是一个在分层压缩潜在空间中的强大自回归模型,在创建示例时,任何模式中都没有遇到崩溃问题。
更多示例和细节如下:

他们使用一个分层的 VQVAE,将图像压缩成一个潜在空间,相对于 ImageNet 来说,这个空间要小 50 倍,相对于 FFHQ 面来说,这个空间要小 200 倍。PixelCNN 仅对最新的产品进行建模,使其能够将其能力用于全局结构和最明显的特征上。
他们 256 像素的两级 ImageNet VQVAE 中的样本如下:

结果,他们发现,这些样本在多样性方面比竞争对手的方法生成的样本要好得多。

对于百万像素的人脸(1024x1024),他们使用了三级 VQVAE 模型。

更多的样本和高分辨率未压缩图像可以在这里找到:https://t.co/EGaUMHA7FN?amp=1

感兴趣的童鞋可以下载相关论文,开始愉快地学习吧~
via:https://mobile.twitter.com/avdnoord/status/1135900129402208257
由中国计算机学会主办、雷锋网和香港中文大学(深圳)联合承办的 2019 全球人工智能与机器人峰会( CCF-GAIR 2019),将于 2019 年 7 月 12 日至 14 日在深圳举行。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。

今日限量赠送3张1000元门票优惠码,门票原价1999元,现价仅1049元,限量3张,送完即止。(打开以下任意一条链接即可兑换,先到先得)
https://gair.leiphone.com/gair/coupon/s/5cf4e5cf8d817
https://gair.leiphone.com/gair/coupon/s/5cf4e5cf8d4b0
https://gair.leiphone.com/gair/coupon/s/5cf4e5cf8d22b


