漫画:什么是KMP算法?


作者 | 小灰
来源 | 程序员小灰(ID:chengxuyuanxiaohui)














前情回顾
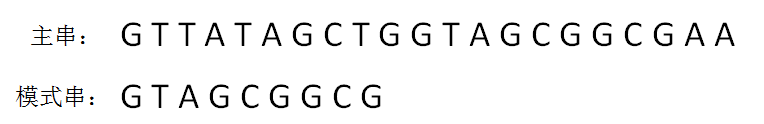
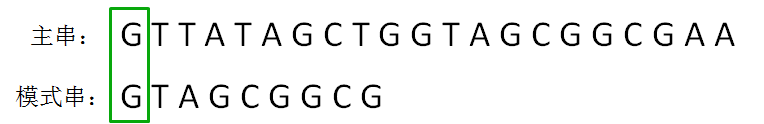
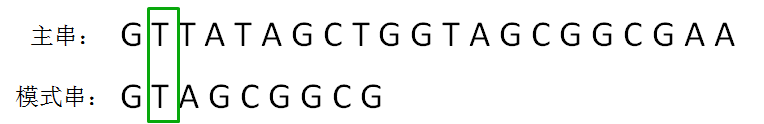
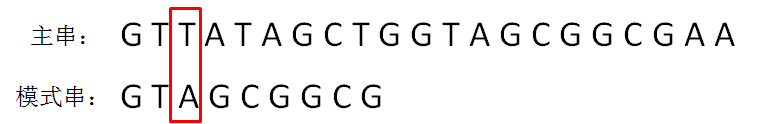
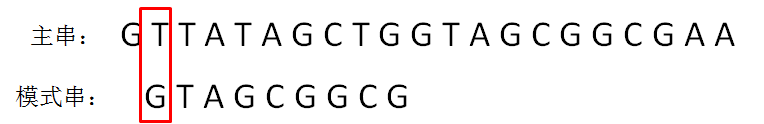
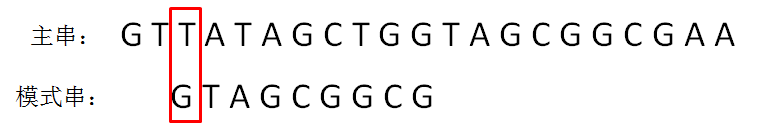
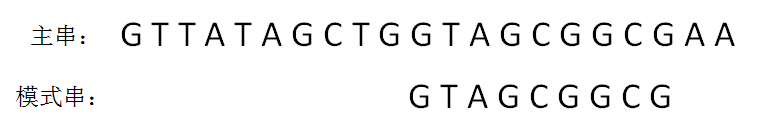
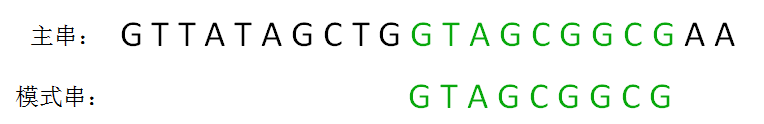
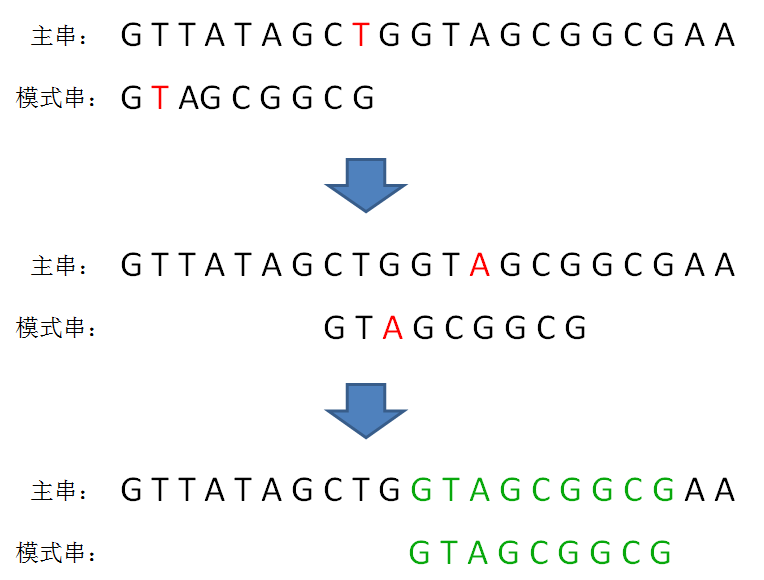





KMP算法的整体思路
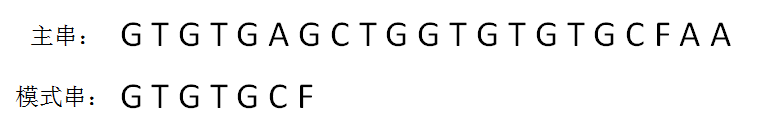
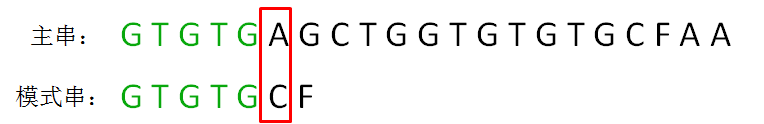

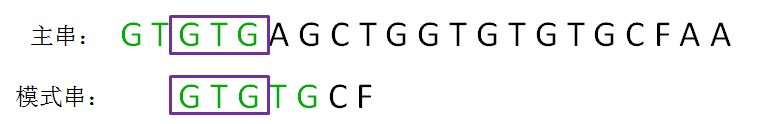
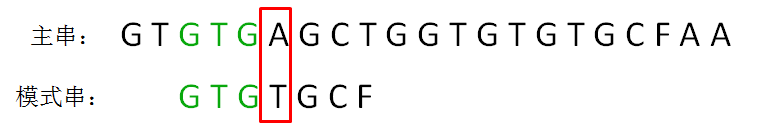

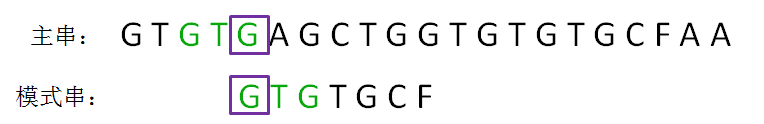




next 数组
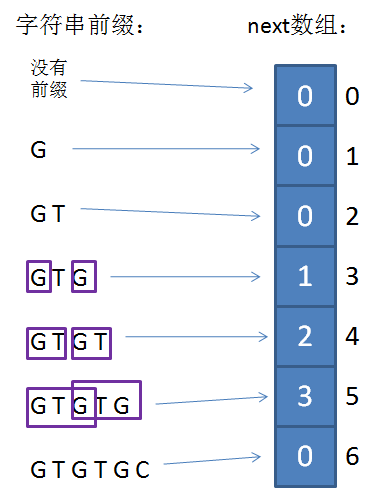
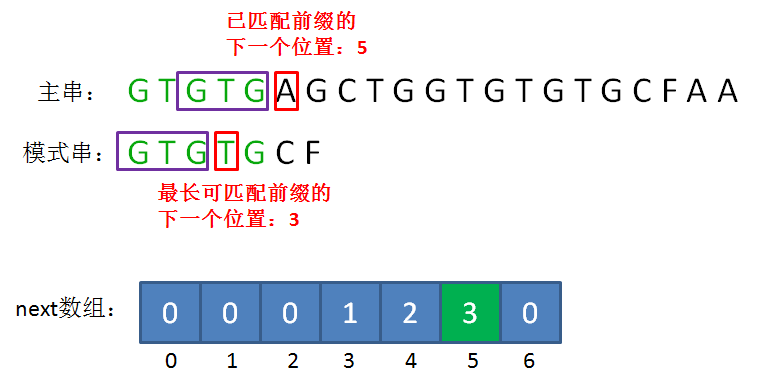
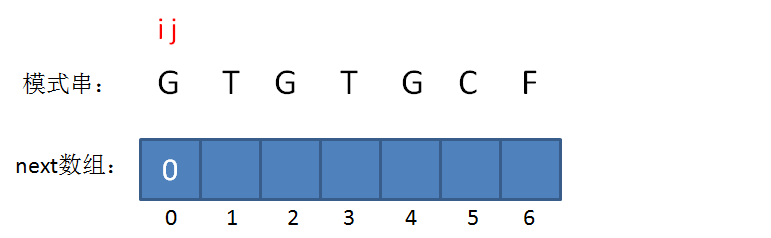
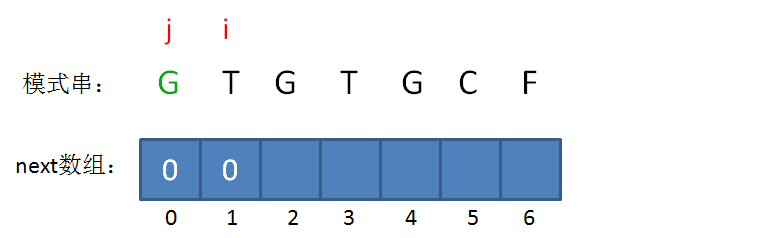
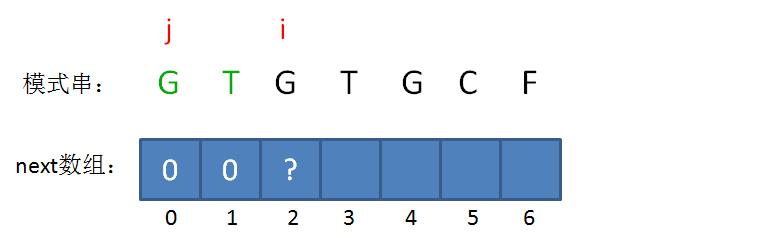
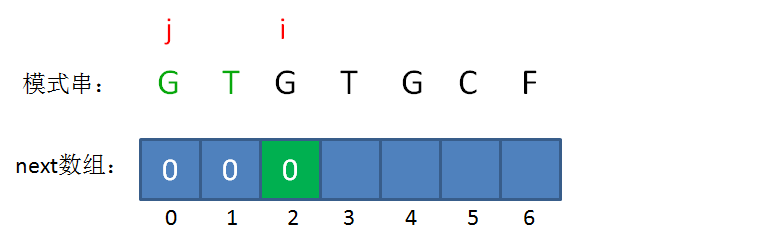
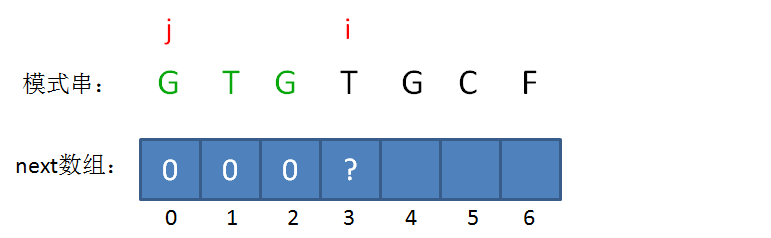
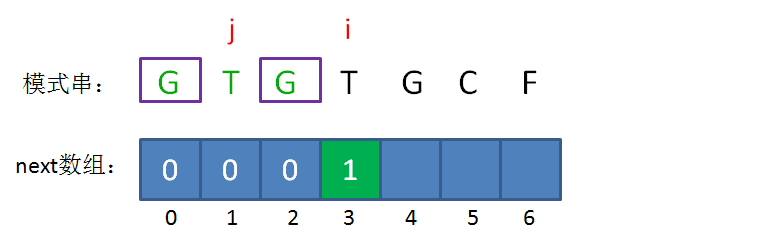
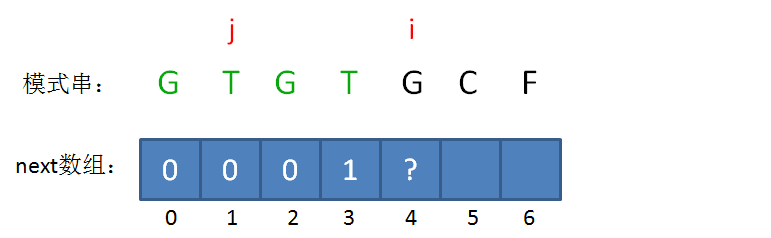
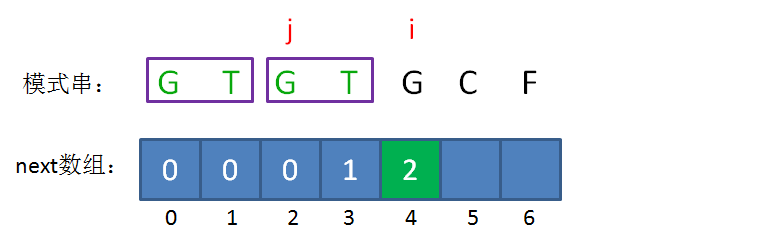
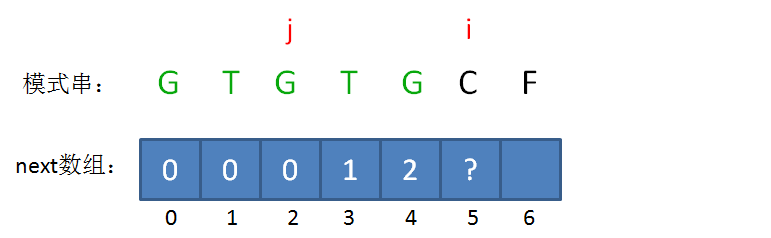
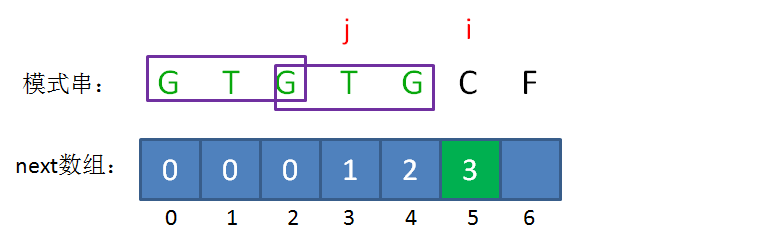
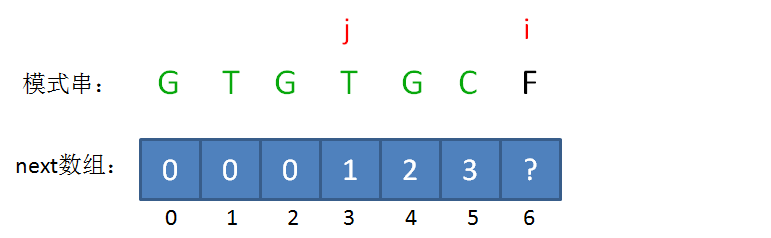
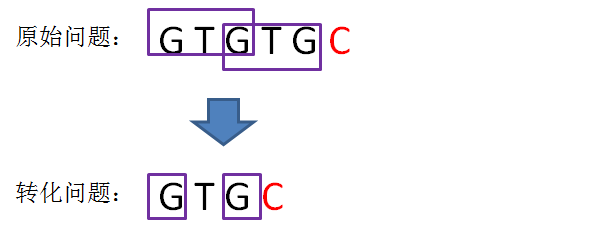
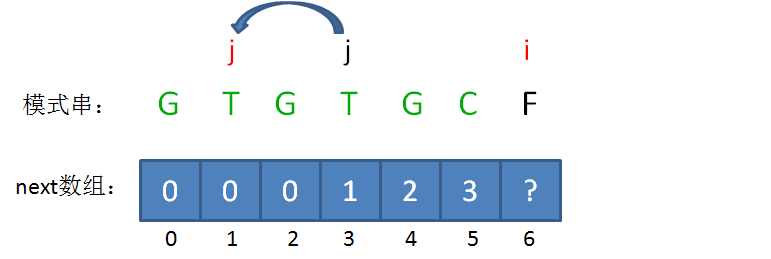
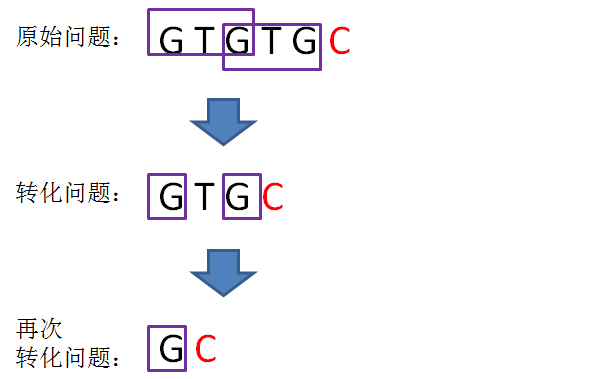
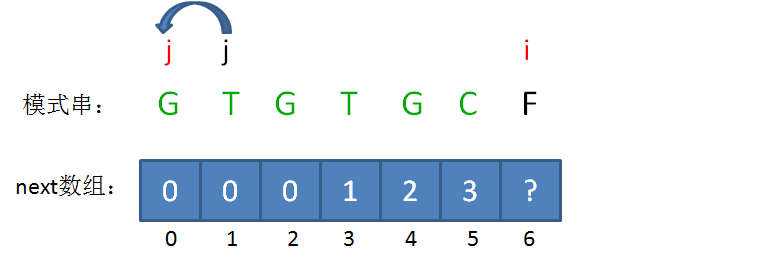
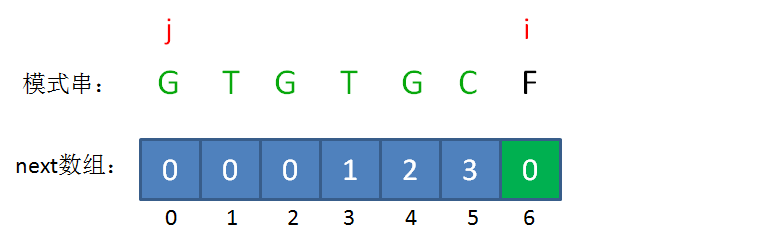



KMP算法的具体实现


-
// KMP算法主体逻辑。str是主串,pattern是模式串
public static int kmp(String str, String pattern) {
//预处理,生成next数组
int[] next = getNexts(pattern);
int j = 0;
//主循环,遍历主串字符
for (int i = 0; i < str.length(); i++) {
while (j > 0 && str.charAt(i) != pattern.charAt(j)) {
//遇到坏字符时,查询next数组并改变模式串的起点
j = next[j];
}
if (str.charAt(i) == pattern.charAt(j)) {
j++;
}
if (j == pattern.length()) {
//匹配成功,返回下标
return i - pattern.length() + 1;
}
}
return -1;
}
// 生成Next数组
private static int[] getNexts(String pattern) {
int[] next = new int[pattern.length()];
int j = 0;
for (int i=2; i<pattern.length(); i++) {
while (j != 0 && pattern.charAt(j) != pattern.charAt(i-1)) {
//从next[i+1]的求解回溯到 next[j]
j = next[j];
}
if (pattern.charAt(j) == pattern.charAt(i-1)) {
j++;
}
next[i] = j;
}
return next;
}
public static void main(String[] args) {
String str = "ATGTGAGCTGGTGTGTGCFAA";
String pattern = "GTGTGCF";
int index = kmp(str, pattern);
System.out.println("首次出现位置:" + index);
}






阿里大牛:华先胜、丁险峰直播分享!
今晚7点,阿里巴巴集团副总裁华先胜——《人工智能:是风、是云,还是雨?》
面向开发者详解视觉智能技术规模化落地的挑战;面向企业详述如何通过核心AI技术、产品化 及平台化实现客户价值并构建壁垒?

☞ 两成开发者月薪超 1.7 万、算法工程师最紧缺! | 中国开发者年度报告
☞探索处理数据的新方法,8 个重点带你搞懂云数据库——DBaaS(数据库即服务)到底是什么!
☞基于区块链技术的数据共享赋能AI驱动网络
☞2020 AI人才报告:每年74%人才需求增长,创业公司平均薪水约20万美元
☞在家办公憋疯了?不,我还能再待一年!

登录查看更多
相关内容
Arxiv
5+阅读 · 2018年7月23日





相关VIP内容
相关资讯
相关论文
Arxiv
5+阅读 · 2018年7月23日