漫画:什么是Bitmap算法?
来自:梦见(微信号:dreamsee321)




两个月之前——


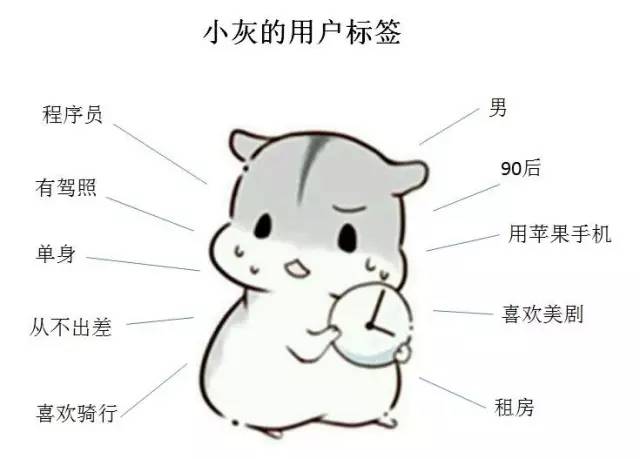


为满足用户标签的统计需求,小灰利用Mysql设计了如下的表结构,每一个维度的标签都对应着Mysql表的一列:
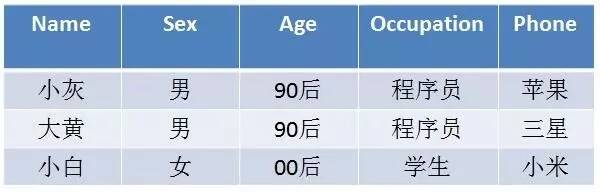
要想统计所有90后的程序员该怎么做呢?
用一条求交集的SQL语句即可:
Select count(distinct Name) as 用户数 from table whare age = '90后' and Occupation = '程序员' ;
要想统计所有使用苹果手机或者00后的用户总合该怎么做?
用一条求并集的SQL语句即可:
Select count(distinct Name) as 用户数 from table whare Phone = '苹果' or age = '00后' ;

两个月之后——




———————————————





1. 给定长度是10的bitmap,每一个bit位分别对应着从0到9的10个整型数。此时bitmap的所有位都是0。

2. 把整型数4存入bitmap,对应存储的位置就是下标为4的位置,将此bit置为1。

3. 把整型数2存入bitmap,对应存储的位置就是下标为2的位置,将此bit置为1。

4. 把整型数1存入bitmap,对应存储的位置就是下标为1的位置,将此bit置为1。

5. 把整型数3存入bitmap,对应存储的位置就是下标为3的位置,将此bit置为1。

要问此时bitmap里存储了哪些元素?显然是4,3,2,1,一目了然。
Bitmap不仅方便查询,还可以去除掉重复的整型数。





1. 建立用户名和用户ID的映射:
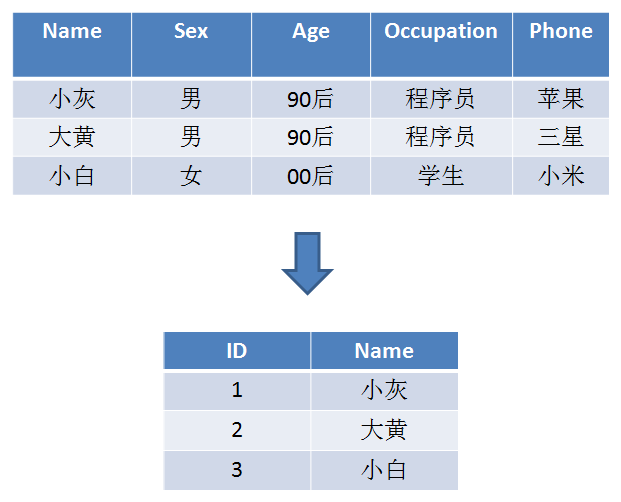
2. 让每一个标签存储包含此标签的所有用户ID,每一个标签都是一个独立的Bitmap。
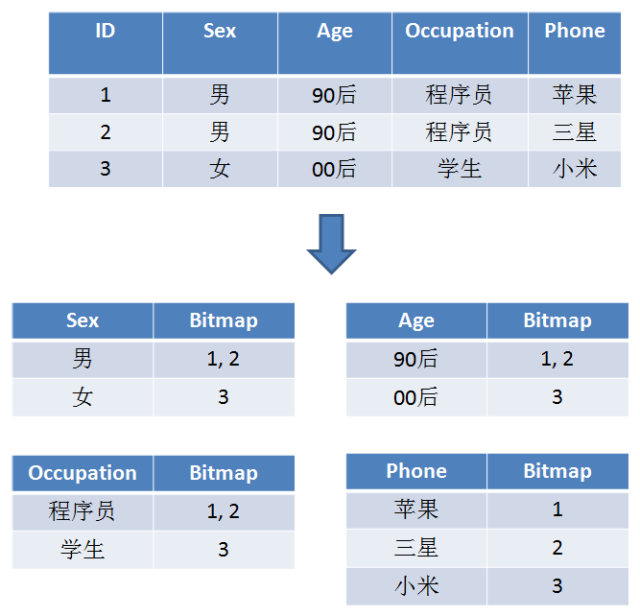
3. 这样,实现用户的去重和查询统计,就变得一目了然:
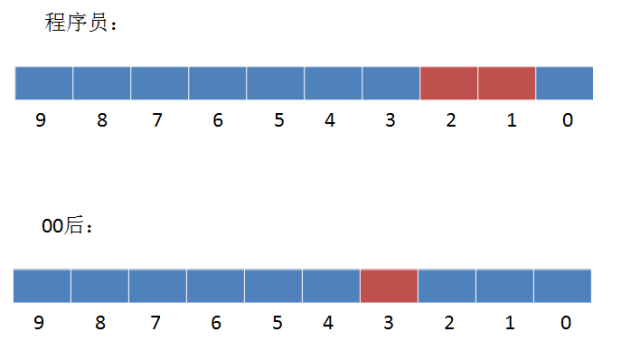


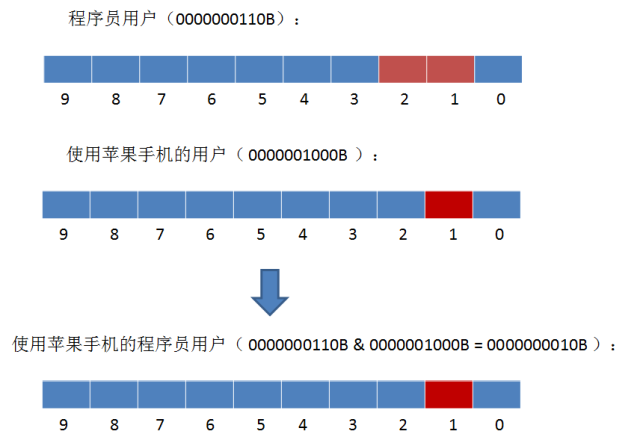
1. 如何查找使用苹果手机的程序员用户?
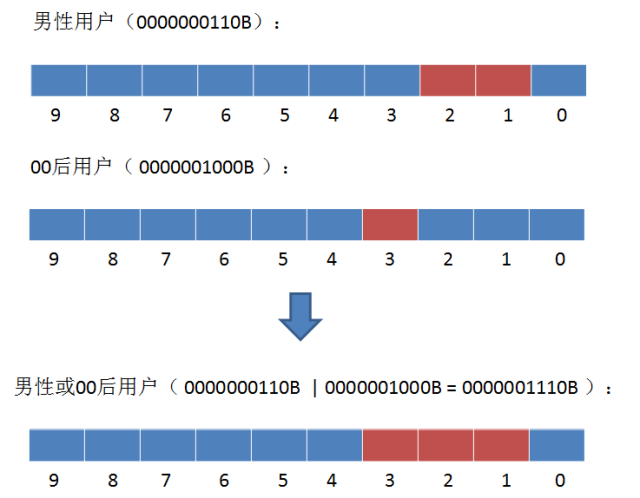
2. 如何查找所有男性或者00后的用户?





几点说明:
1. 本文的灵感来源于京东金融数据部张洪雨同学的项目经历,感谢这位大神的技术分享。
2. 该项目最初的技术选型并非Mysql,而是内存数据库hana。本文为了便于理解,把最初的存储方案写成了Mysq数据库。
—————END—————
系列文章:
●本文编号2560,以后想阅读这篇文章直接输入2560即可
●输入m获取文章目录

算法与数据结构





