Python 分析 9 万条数据告诉你复仇者联盟谁才是绝对 C 位!


作者 | 罗昭成
责编 | 唐小引
出品 | CSDN(ID:CSDNnews)
《复联 4》国内上映第十天,程序员的江湖里开始流传这样一个故事,即:
漫威宇宙,其实就讲了一件事情。整个宇宙就好比一个项目组。其中有一群叫作美国队长、钢铁侠、惊奇队长、浩克、索尔等人在维护这个项目,兢兢业业的维护整个项目。
某一天,出现了一个天才程序员,叫灭霸。当他加入到这家公司的时候,他意识到,这个项目已经非常庞大,仅仅是编译,就要几个小时。运行起来负重累累。而服务器资源又非常的有限,老板又不给预算买新机器,如果一直继续这么开发下去,这个项目迟早要出现 P0 事故。于是,他下定决定要把这个项目全面优化,使用用面向对象思想,提取重复代码,业务拆分,算法优化等手段,彻底优化,目标是代码量减少 50%。
美国队长带领的项目组叫复仇者联盟,发现了灭霸程序员的想法后,阻止并警告灭霸说:不要轻易去改老代码!!很容易出 bug 的,代码能跑就行!!
—— 以上来自知乎@郭启军
https://www.zhihu.com/question/321428495/answer/663671132
那么,作为一个写程序员的电影,我们怎么不能用数据来分析一下,喜欢漫威宇宙的观众对《复联 4》的评价呢?

抓取数据
业界朋友们,在电影分析中,使用猫眼的数据比较多。在本文中,笔者也使用了猫眼的接口来获取数据,方便处理,数据量也比较多。
有关接口,大家可以自己去猫眼的网站上看,也可以使用如下地址:
http://m.maoyan.com/mmdb/comments/movie/248172.json?_v_=yes&offset=20&startTime=2019-04-24%2002:56:46在 Python 中,使用 Request 可以很方便地发送请求,拿到接口返回的 JSON 数据,来看代码:
def getMoveinfo(url):
session = requests.Session()
headers = {
"User-Agent": "Mozilla/5.0",
"Accept": "text/html,application/xhtml+xml",
"Cookie": "_lxsdk_cuid="
}
response = session.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None请求返回的是一个 JSON 数据,拿到我们想要的评论原始数据,并将数据存储在数据库中:
def saveItem(dbName, moveId, id, originalData) :
conn = sqlite3.connect(dbName)
conn.text_factory=str
cursor = conn.cursor()
ins="INSERT OR REPLACE INTO comments values (?,?,?)"
v = (id, originalData, moveId)
cursor.execute(ins,v)
cursor.close()
conn.commit()
conn.close()经过大概两个小时,终于从猫眼爬取了大约 9 万条数据。数据库文件已经超过了 100M 了。

数据清洗
因为在上面抓取下来的数据,直接进行了原数据的存储,没有进行数据的解析处理。接口中包含了很多数据,有用户信息、评论信息等。本次分析,只使用了部分数据,所以需要将用到的相关数据清洗出来:
def convert(dbName):
conn = sqlite3.connect(dbName)
conn.text_factory = str
cursor = conn.cursor()
cursor.execute("select * from comments")
data = cursor.fetchall()
for item in data:
commentItem = json.loads(item[1])
movieId = item[2]
insertItem(dbName, movieId, commentItem)
cursor.close()
conn.commit()
conn.close()
def insertItem(dbName, movieId, item):
conn = sqlite3.connect(dbName)
conn.text_factory = str
cursor = conn.cursor()
sql = '''
INSERT OR REPLACE INTO convertData values(?,?,?,?,?,?,?,?,?)
'''
values = (
getValue(item, "id"),
movieId,
getValue(item, "userId"),
getValue(item, "nickName"),
getValue(item, "score"),
getValue(item, "content"),
getValue(item, "cityName"),
getValue(item, "vipType"),
getValue(item, "startTime"))
cursor.execute(sql, values)
cursor.close()
conn.commit()
conn.close()通过 JSON 库将原始数据解析出来,将我们需要的信息存储到新的数据表中。

数据分析
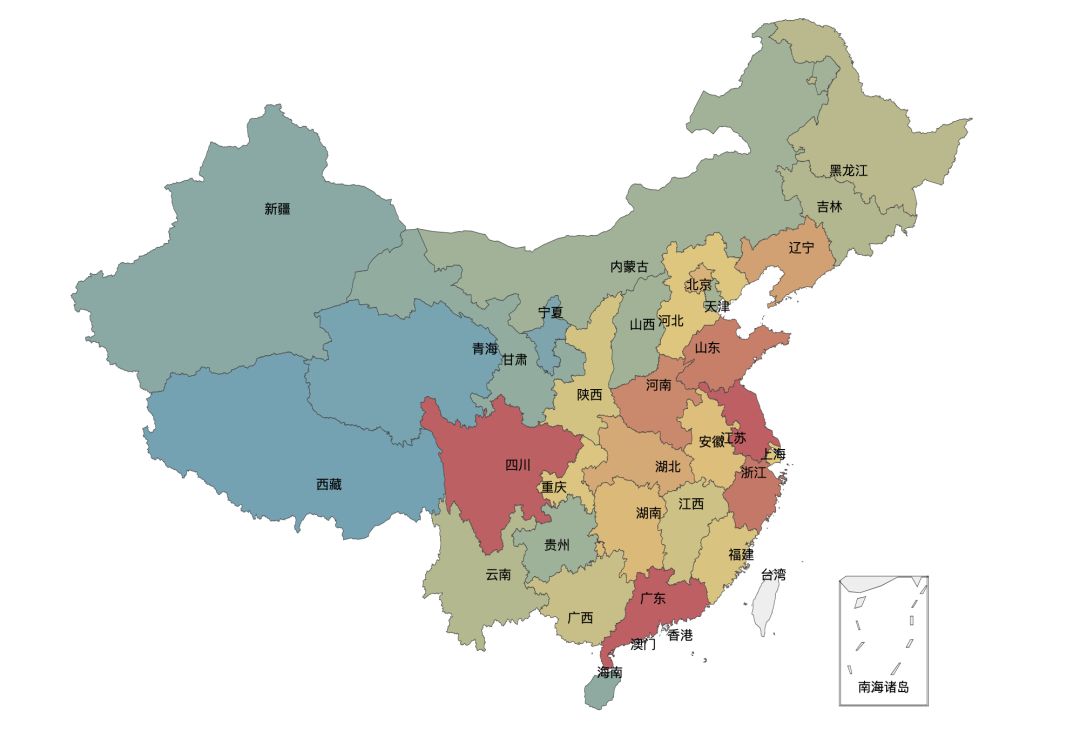
因为没有任何一个平台能够拿到用户的购票数据,我们只能从评论的数据中,以小见大,从这些数据中,分析出一些走势。 在评论数据中,我们能看到评论用户所在的城市。将数据所在的位置解析,划分到各对应的行政省,可以看到每个省评论数量,见下图(颜色越红,用户评论数量越多):
城市
从图中可以看到, 上海、广州、四川用户的数量显然要比其他城市的用户数量要多得多。再来看一下代码:
data = pd.read_sql("select * from convertData", conn)
city = data.groupby(['cityName'])
city_com = city['score'].agg(['mean','count'])
city_com.reset_index(inplace=True)
fo = open("citys.json",'r')
citys_info = fo.readlines()
citysJson = json.loads(str(citys_info[0]))
print city_com
data_map_all = [(getRealName(city_com['cityName'][i], citysJson),city_com['count'][i]) for i in range(0,city_com.shape[0])]
data_map_list = {}
for item in data_map_all:
if data_map_list.has_key(item[0]):
value = data_map_list[item[0]]
value += item[1]
data_map_list[item[0]] = value
else:
data_map_list[item[0]] = item[1]
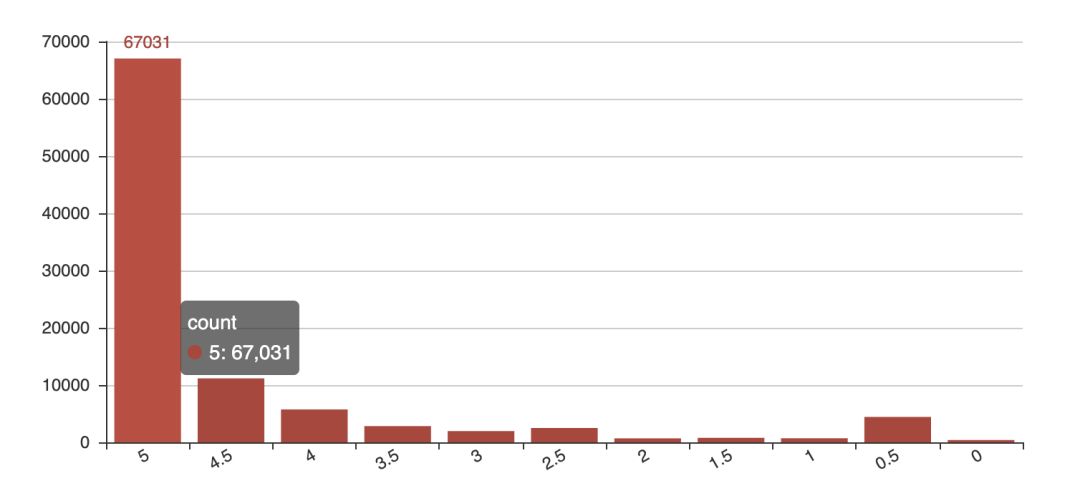
data_map = [(realKeys(key), data_map_list[key] ) for key in data_map_list.keys()]漫威电影一直深受中国朋友们喜欢的高分电影。豆瓣评分 8.7 分,那我们的评论用户中,又是一个什么样的趋势呢?见下图:
评分数
从图中可以看到,评 5 分的数量远高于其他评分,可见中国的观众朋友确实喜欢漫威的科幻电影。
复联从 1 开始便是漫威宇宙各路超级英雄的集结,到现在的第 4 部,更是全英雄的汇聚。那么,在这之中,哪位英雄人物更受观众欢迎?先看代码:
attr = ["灭霸","美国队长",
"钢铁侠", "浩克", "奇异博士", "蜘蛛侠", "索尔" ,"黑寡妇",
"鹰眼", "惊奇队长", "幻视",
"猩红女巫","蚁人", "古一法师"]
alias = {
"灭霸": ["灭霸", "Thanos"],
"美国队长": ["美国队长", "美队"],
"浩克": ["浩克", "绿巨人", "班纳", "HULK"],
"奇异博士": ["奇异博士", "医生"],
"钢铁侠": ["钢铁侠", "stark", "斯塔克", "托尼", "史塔克"],
"蜘蛛侠": ["蜘蛛侠","蜘蛛","彼得", "荷兰弟"],
"索尔":["索尔", "雷神"],
"黑寡妇": ["黑寡妇", "寡姐"],
"鹰眼":["鹰眼","克林顿","巴顿","克林特"],
"惊奇队长":["惊奇队长","卡罗尔", "惊奇"],
"星云":["星云"],
"猩红女巫": ["猩红女巫", "绯红女巫", "旺达"],
"蚁人":["蚁人", "蚁侠", "Ant", "AntMan"],
"古一法师": ["古一", "古一法师", "法师"]
}
v1 = [getCommentCount(getAlias(alias, attr[i])) for i in range(0, len(attr))]
bar = Bar("Hiro")
bar.add("count",attr,v1,is_stack=True,xaxis_rotate=30,yaxix_min=4.2,
xaxis_interval=0,is_splitline_show=True)
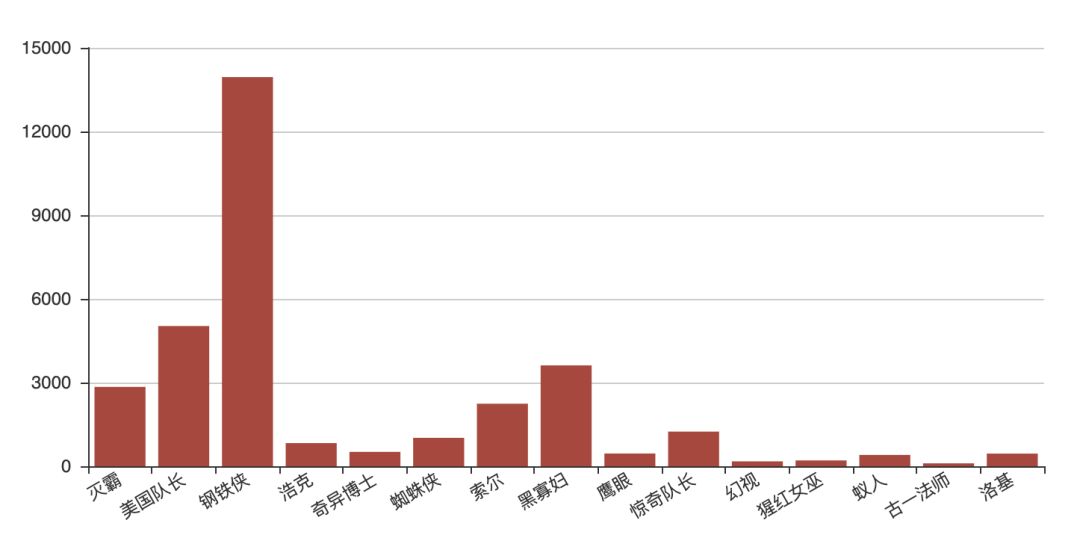
bar.render("html/hiro_count.html")运行结果如下图,可以看到钢铁侠钢铁侠是实至名归的 C 位,不仅电影在电影中是,在评论区仍然也是实至名归的 C 位,甚至于远超美队、寡姐和雷神:
英雄评论次数
从以上观众分布和评分的数据可以看到,这一部剧,观众朋友还是非常地喜欢。前面,从猫眼拿到了观众的评论数据。现在,笔者将通过 Jieba 把评论进行分词,然后通过 Wordcloud 制作词云,来看看,观众朋友们对《复联》的整体评价:

词云分析
可以看到,灭霸和钢铁侠出现的词频比其他英雄要高很多。这是否表示,这部剧的主角就是他们两个呢?
细心的朋友应该发现了,钢铁侠、灭霸的数量在词云和评论数量里面不一致。原因在于,评论数量就按评论条数来统计的,而词云中,使用的是词频,同一条评论中,多次出现会多次统计。所以,灭霸出现的次数居然高于了钢铁侠。
最后,再来分析一下钢铁侠与灭霸的情感分析,先上代码:
def emotionParser(name):
conn = conn = sqlite3.connect("end.db")
conn.text_factory = str
cursor = conn.cursor()
likeStr = "like \"%" + name + "%\""
cursor.execute("select content from convertData where content " + likeStr)
values = cursor.fetchall()
sentimentslist = []
for item in values:
sentimentslist.append(SnowNLP(item[0].decode("utf-8")).sentiments)
plt.hist(sentimentslist, bins=np.arange(0, 1, 0.01), facecolor="#4F8CD6")
plt.xlabel("Sentiments Probability")
plt.ylabel("Quantity")
plt.title("Analysis of Sentiments for " + name)
plt.show()
cursor.close()
conn.close()此处,使用 SnowNLP 来进行情感分析。
情感分析,又称为意见挖掘、倾向性分析等。简单而言,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。
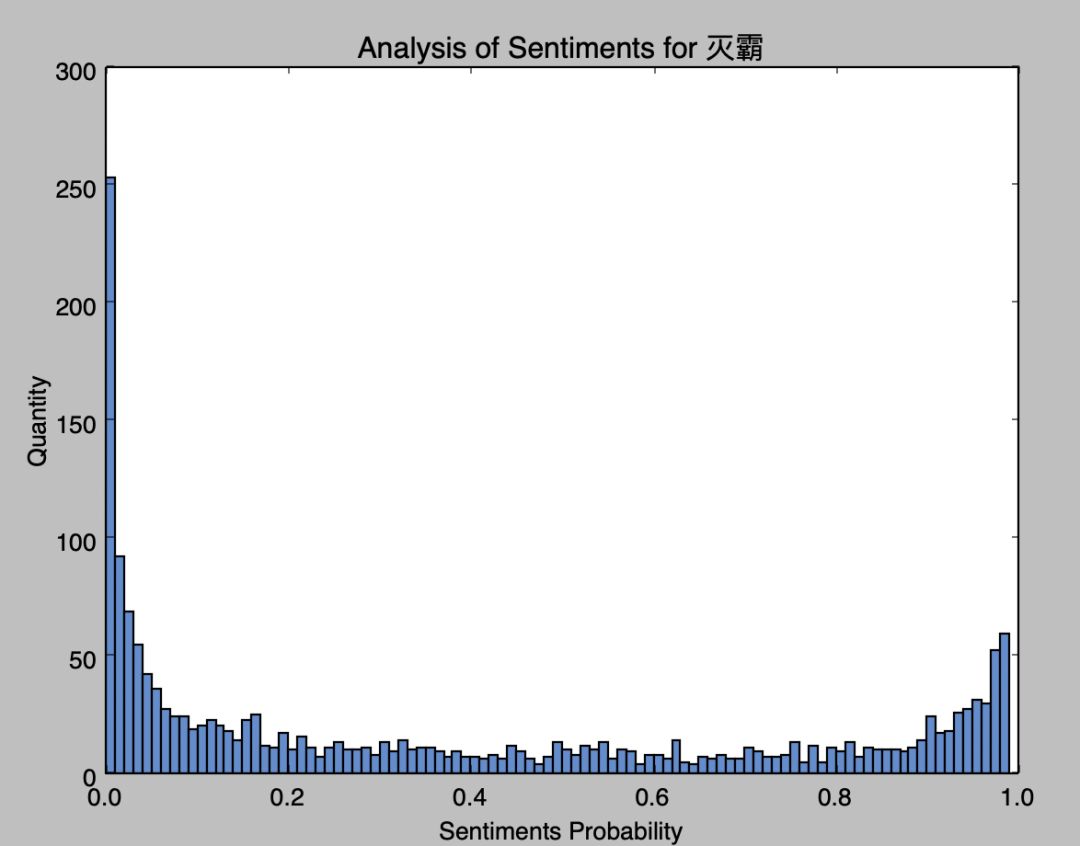
灭霸
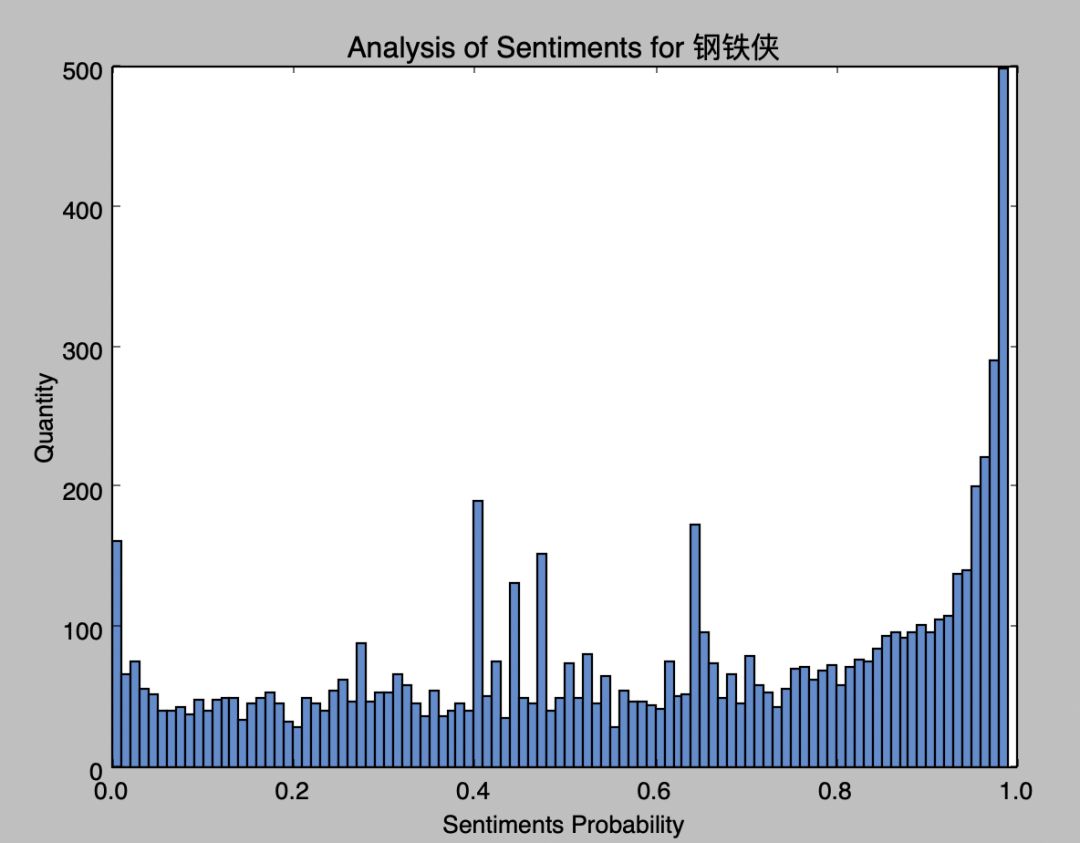
钢铁侠
从图中看到, 钢铁侠的正向情感要比灭霸的正向情感要高,反派角色就是容易被人抗拒。
最最后,从《银河护卫队》时期穿越而来的灭霸在最后分钟变成了粉末消散而去,这也给我们程序员一个警钟:
重构代码,改善设计,降低系统复杂度,这样做很好。但是,一定要保证系统的稳定运行,不留安全隐患,不然,早晚会丢掉自己的工作。


作为码一代,想教码二代却无从下手:
听说少儿编程很火,可它有哪些好处呢?
孩子多大开始学习比较好呢?又该如何学习呢?
最新的编程教育政策又有哪些呢?
下面给大家介绍CSDN新成员:极客宝宝(ID:geek_baby)
戳他了解更多↓↓↓

热 文 推 荐
☞60倍回报! AI工程师用OpenAI创建了一个比特币自动交易工具! 这里是详细做法 | 技术头条
![]()
你点的每个“在看”,我都认真当成了喜欢





