什么?!“路由器”也会做信息抽取了?

文 | 雨城
编 | QvQ
前几周,一个“撞脸”路由器的联合抽取模型TPLinker横空出世,将NYT数据集的分数直接刷上了90,提高了2个百分点。卖萌屋邀请到作者雨城,来聊一聊他们在关系抽取上的工作。目前,该工作已经被COLING 2020接收。
背景
关系抽取 是从非结构化文本中抽取实体和关系的文本处理技术,属于自然语言处理中的常见任务。它是自然语言理解的基础,在智能问答、信息检索等领域有重要应用。简单来说就是给定一段文本,要抽出其中的(subject, predicate, object)三元组。例如:
{
'text': '《邪少兵王》是冰火未央写的
网络小说连载于旗峰天下',
'relation_list': [
{
'subject': '邪少兵王',
'object': '冰火未央',
'predicate': '作者'
},
]
}
pipeline的方法一般先做实体识别,再对实体对进行关系分类。这类方法忽略了实体与关系之间的联系,而且存在误差累积的问题。
为了充分利用实体与关系的交互信息和依赖关系,联合抽取的思路应运而生,即在一个模型中同时对实体和关系进行统一抽取。较早的联合抽取方法,如NovelTagging,没法解决关系重叠的问题。当一个或一对实体同时出现在多个关系时,单纯的序列标注就不再管用了,例如:
| 文本 | 关系 | |
|---|---|---|
| 单实体重叠 | 周星驰主演了《喜剧之王》和《大话西游》。 | (周星驰,演员,喜剧之王)(周星驰,演员,大话西游) |
| 实体对重叠 | 由周星驰导演并主演的《功夫》于近期上映。 | (周星驰,演员,功夫)(周星驰,导演,功夫) |
后来提出的一些方法已经可以解决重叠问题,如CopyRE 、CopyMTL 、CasRel(HBT) 等,但它们在训练和推理阶段的不一致性导致存在曝光偏差。即在训练阶段,使用了golden truth作为已知信息对训练过程进行引导,而在推理阶段只能依赖于预测结果。这导致中间步骤的输入信息来源于两个不同的分布,对性能有一定的影响。
虽然这些方法都是在一个模型中对实体和关系进行了联合抽取,但从某种意义上它们“退化”成了“pipeline”的方法,即在解码阶段需要分多步进行,这也是它们存在曝光偏差的本质原因。
本文提出了一种新的实体关系联合抽取标注方案,可在一个模型中实现真正意义上的单阶段联合抽取,不存在曝光偏差,保证训练和测试的一致性。并且同时可解决多关系重叠和多关系实体嵌套的问题。
论文题目:
《TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking》
论文链接:
https://arxiv.org/abs/2010.13415
源码链接:
github.com/131250208/TPlinker-joint-extraction
Arxiv访问慢的小伙伴也可以在 【夕小瑶的卖萌屋】订阅号后台回复关键词 【1110】 下载论文PDF~
Idea的由来
说了那么多,终于要进入正题了。我最初的idea是为了解决一个比较极端的情况,曝光偏差的问题其实是“顺便”解决的。在许多关系抽取的比赛数据集中,我发现部分关系的实体存在嵌套,请看以下两个例子:
| 文本 | 关系 | |
|---|---|---|
| 关系内嵌套 | 哈尔滨工业大学 | (哈尔滨工业大学,位于,哈尔滨) |
| 关系间嵌套 | 北京市政府正式东迁至通州 | (北京市,包含,通州)(北京市政府,位于,通州) |
虽然当前已经有很多方法可以专门用于识别嵌套实体,但是把它们直接融合到关系抽取中也并不是那么容易。即使可以,多少显得有点笨重。于是,我开始思考如何能够用一个简单直接的方法识别嵌套实体,并与关系抽取任务优雅融合。
疫情期间,我每天苦思冥想,瞠目抖腿,抓耳挠腮,摇头晃脑,鬼哭狼嚎,差点以头抢地。最后,一拍大腿,嗨,不就是头和尾的区别。只要一个实体的头部token和尾部token被唯一确定,那它就可以与外部或者内部的其他实体区别开。那么如何确定头尾呢?我们要的不是多个标签,而是一个标签,因为多个标签难免要遇到配对的问题。那么,答案呼之欲出了,就是 矩阵。矩阵中的一个点可以确定一对token。一句话的所有嵌套实体都可以在一个矩阵中被一个点唯一标注,如下图所示:
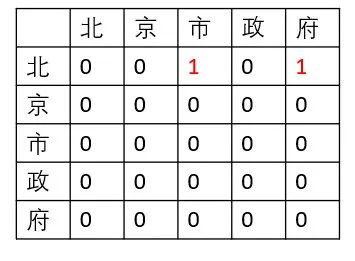
纵轴为头,横轴为尾,图中的两个红色1标签分别标注了(北,市)和(北,府),代表“北京市”和“北京市政府”为两个实体。
实体解决了,那么关系怎么办呢?那是一个下午,落日的余光洒在地板上显得格外刺眼,我看了一眼客厅的沙发,忽然想起了那天夕阳下的思考。一拍脑袋,邻接矩阵不就是用来表示节点关系的吗?实体关系可不可以也用两个token的关系来表示呢?答案又呼之欲出了。对,那就是subject和object的头部token以及尾部token。例如:(周星驰,演员,喜剧之王)-> (周,演员,喜),(驰,演员,王)。
有些同学可能会疑惑为什么还要标尾部token,头部token对的关系不就已经足够表达关系了吗?那是因为如果不确定尾部边界,仍然无法解决嵌套问题。如前文例子中的“北京市”和“北京市政府”就是共享头部token的嵌套实体。
有些小伙伴可能已经看出来了,我们不知不觉就把subject和object在同一解码阶段确定了下来。于是,曝光偏差就不存在了。
标注方案
具体的标注方案如下图所示:
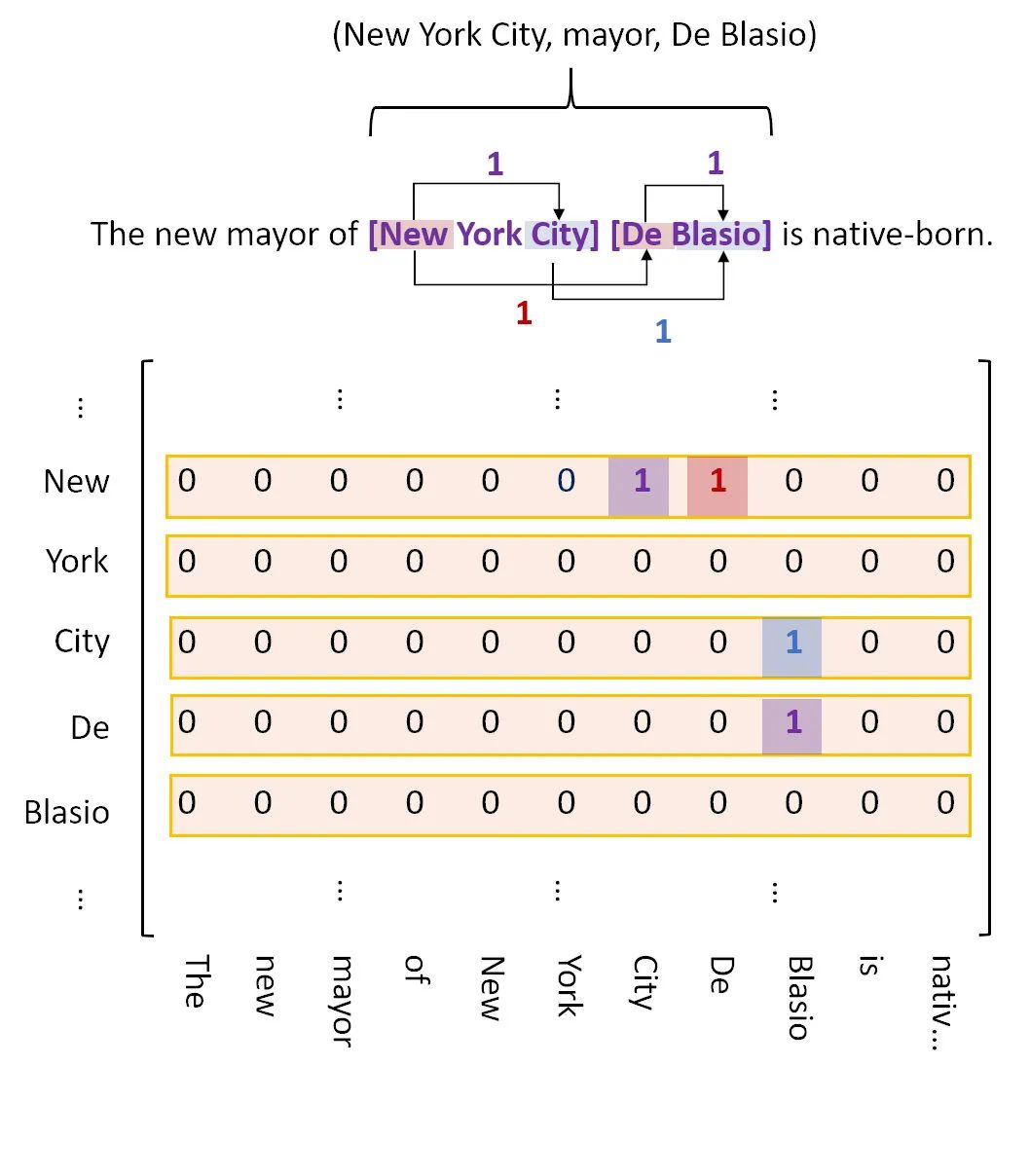
其中 紫色 标签代表实体的 头尾关系 ,红色 标签代表subject和object的 头部关系 ,蓝色 标签代表subject和object的 尾部关系 。至于为什么用颜色区分,是因为这三种关系可能重叠,所以三种标签是存在于不同矩阵的,这里为了便于阐述,才放在一起。
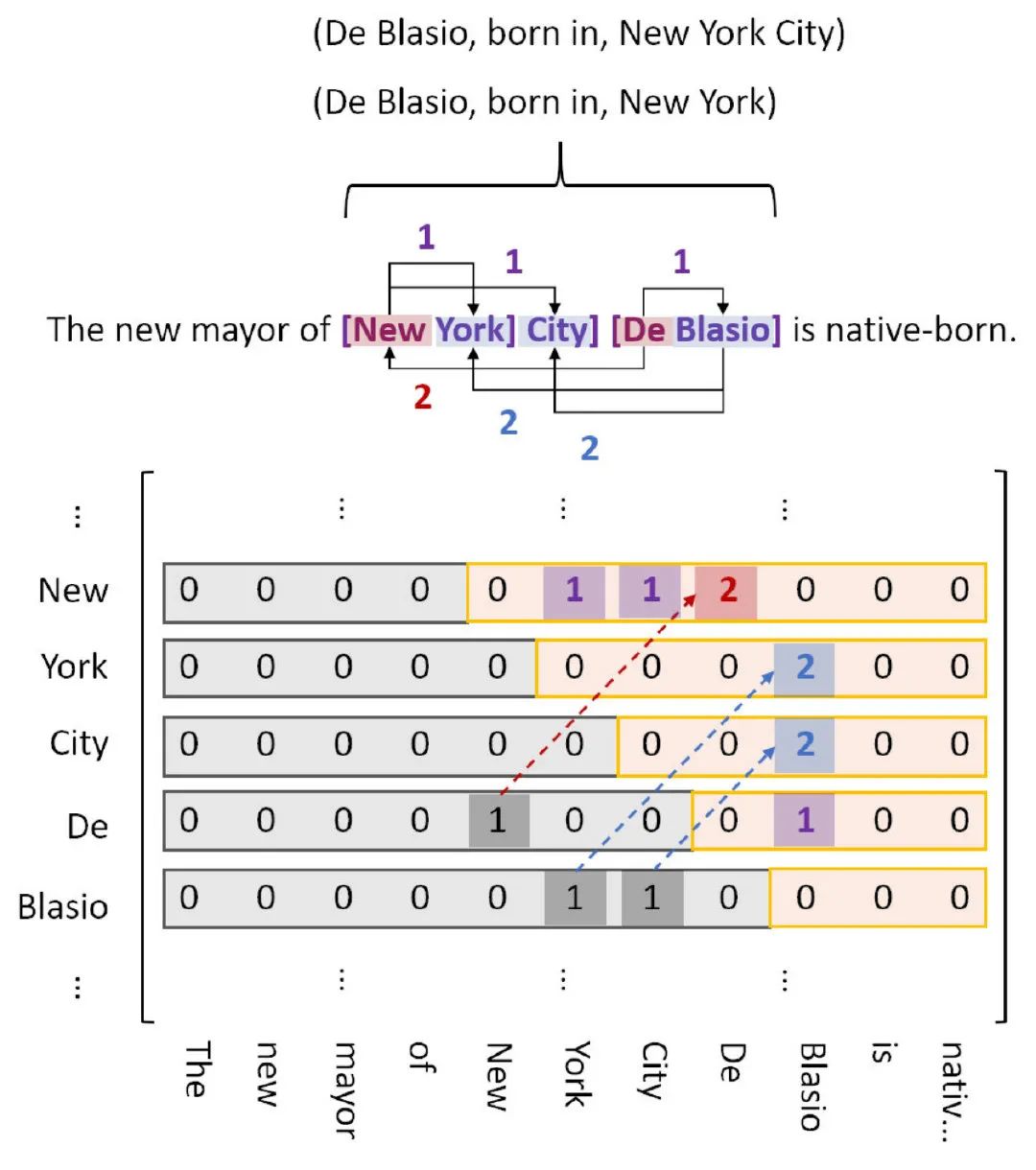
因为实体尾部不可能出现在头部之前,所以紫色标签是不可能出现在下三角区的,那么这样标就有点浪费资源。能不能不要下三角区?但要注意到,红标和蓝标是会出现在下面的。所以我们把红蓝标映射到上三角区对应位置,并标记为2,然后弃了下三角区,如下图:
模型
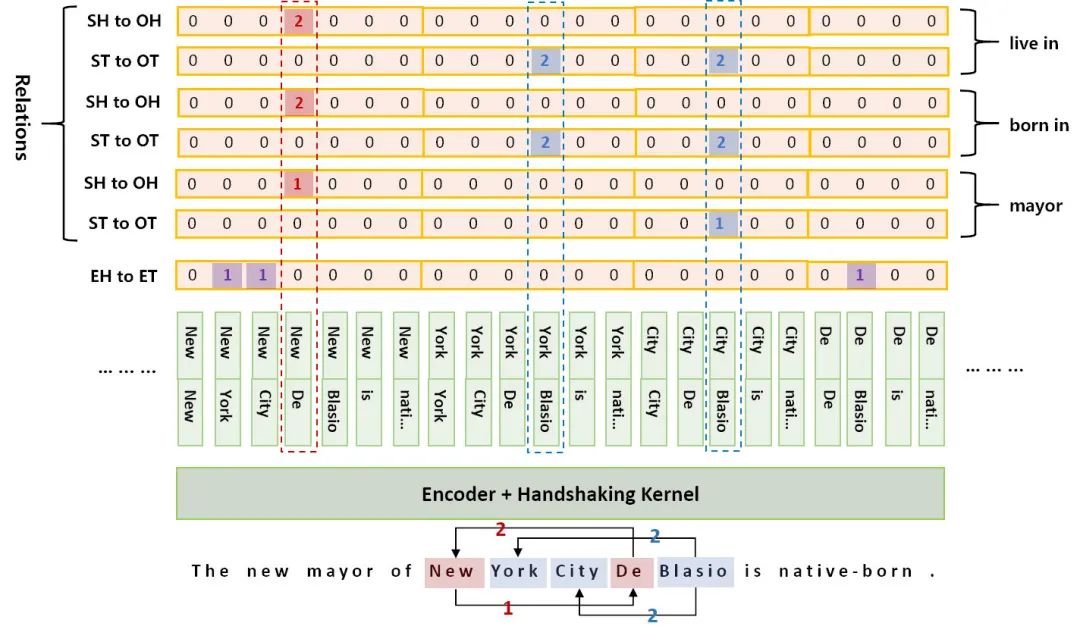
模型结构比较简单,整个句子过一遍encoder,然后将token两两拼接输入到一个全连接层,再激活一下输出作为token对的向量表示,最后对token对进行分类即可。换句话说,这其实就是一个较长序列的标注过程。
在上图的例子中,可以解码出5种关系:
(New York City, mayor, De Blasio),
(De Blasio, born in, New York),
(De Blasio, born in, New York City),
(De Blasio, live in, New York),
(De Blasio, live in, New York City)
实验结果
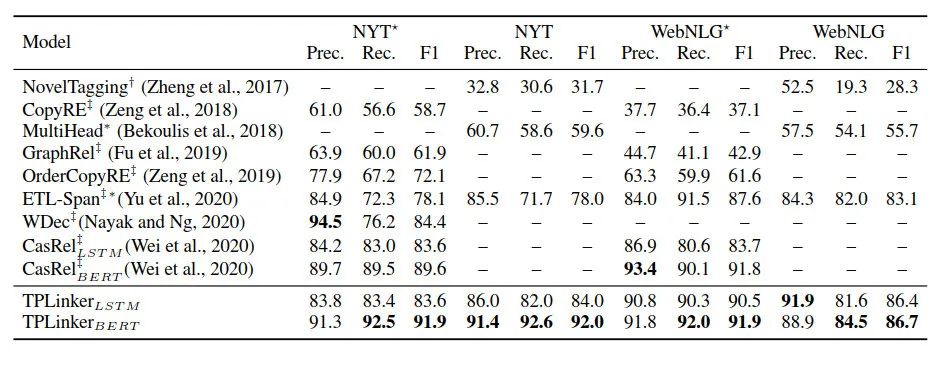
截止到论文发表,该模型在NYT和WebNLG两个信息抽取任务上都取得了当时的SOTA!
未来的工作
这里主要提一下值得改进的地方:
-
论文中token对的向量表示采用的是直接拼接,这种简单的方式可能并不能展现出最佳的性能。 -
实体和关系的识别使用的都是相同的向量表达,这可能会相互干扰。最新的两篇相关论文也指出了使用不同的特征去分别解决两个任务可能对性能有提升: A Frustratingly Easy Approach , Two are Better than One 。 -
模型将原本长度为N的序列扩展成了O(N2)的序列,这无疑增加了开销,使得处理长文本变得比较昂贵。
[1] Extracting relational facts by an end-to-end neural model with copy mechanism. https://www.aclweb.org/anthology/P18-1047
[2] CopyMTL: Copy Mechanism for Joint Extraction of Entities and Relations with Multi-Task Learning. https://arxiv.org/abs/1911.10438
[3] A novel cascade binary tagging framework for relational triple extraction https://arxiv.org/abs/1909.03227
[4] A Frustratingly Easy Approach for Joint Entity and Relation Extraction. https://arxiv.org/abs/2010.12812
[5] Two are Better than One: Joint Entity and Relation Extraction with Table-Sequence Encoders.https://arxiv.org/abs/2010.03851
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
。
欢迎加入AINLP技术交流群
进群请添加AINLP小助手微信 AINLPer(id: ainlper),备注NLP技术交流 ![]()
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。
阅读至此了,分享、点赞、在看三选一吧🙏








