揭秘阿里中台!一文看懂阿里推荐业务的两项利器 | 赠书


从工程的角度看,搜索和推荐既有差异点,又有共同点。阿里巴巴集团的搜索和推荐系统由同一个部门研发,因此很多工程能力是复用的,如搜索和推荐业务的算分服务引擎都是RS/RTP。
本文介绍阿里巴巴推荐的中台产品—BE召回引擎和RTP算分服务,这是阿里巴巴推荐业务的两项利器。

召回引擎BE
BE(Basic Engine)是基于阿里巴巴集团另一个更底层的框架服务Suez构建的。在Suez框架服务的基础上,BE实现了与推荐业务相关的各种功能组件,如向量召回技术、多表join召回,以及以自定义插件形式提供的排序和算分插件接口。
1.架构及工作原理
BE是一个典型的多列searcher+proxy架构,如图1所示。
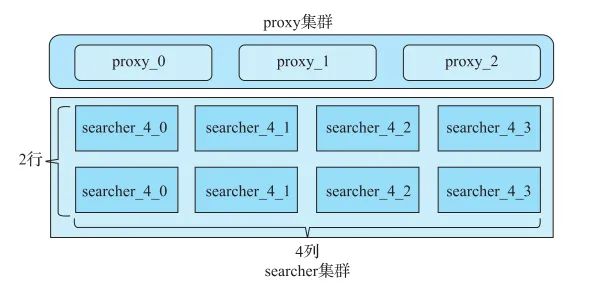
图1 BE集群部署
图1中的proxy集群有3个实例,完全对等,互为备份。searcher集群有2行4列,这表示I2I等数据被划分成4份放到4列机器上。每一列上的数据各不相同,但是执行的计算逻辑完全相同,4列合在一起组成完整的一行。2行之间完全对等,互为备份。
各种I2I/S2I/B2I的召回(search)、合并(union)、关联(join)、过滤(filter)和排序(sorter)均在searcher本地完成,最后经过proxy的合并排序(merge sorter)返回,如图2所示。
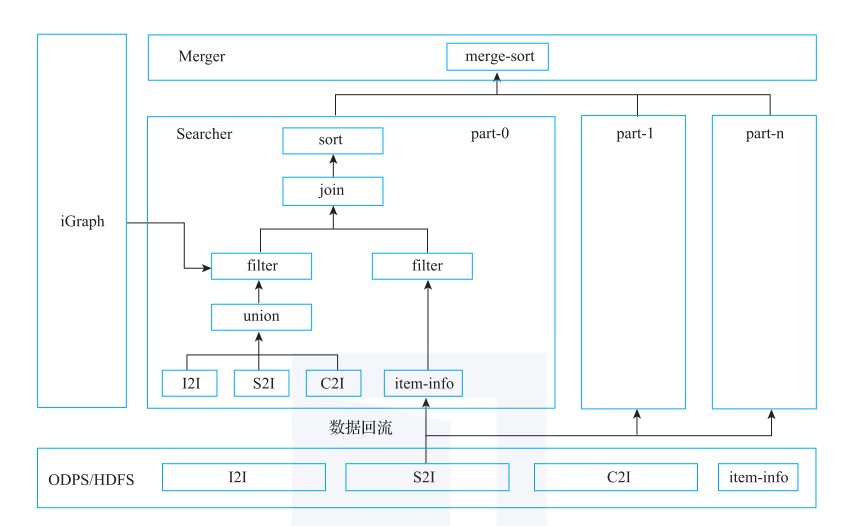
图2 BE内部逻辑
图2中的I2I、S2I、C2I都是BE支持的召回功能,BE底层是基于阿里巴巴搜索事业部研发的通用索引和检索模块indexlib实现的,这里主要用到了indexlib的KV和KKV检索的功能。
顾名思义,KV检索是输入一个或者多个K,返回一个或者多个V。KKV检索是输入pkey和skey,返回单个值;如果只输入pkey,不输入skey,则返回的是值序列。在实际的推荐业务中,主要就是用这两种检索召回机制。
合并功能(union):指的是对多张表的检索结果进行合并,取并集,并记录召回的来源表的信息和是否被两张表同时召回的信息。这些召回过程中记录下来的信息可以用在算分阶段,比如不同的来源表权重不同,则最终得分不同;以及如果是两张表同时召回的,说明被召回的元素命中多种召回策略,则两张来源表的权重相加作为最终权重用于算分,得分就更高了。
关联功能(join):由于左表所存储的信息有限,从左表召回元素集合之后,还有一些信息存在右表,通过join功能可以获取右表的信息,让记录的字段更丰富。该功能用于算分阶段和返回给调用方。
排序功能(sorter):按某个字段或者表达式进行排序,支持用自定义插件实现。
最后,对不同的列(partition)的结果进行合并,然后返回给调用方,这是一个完整的BE召回过程。
2、BE向量召回和应用
时下有一种非常流行的召回机制叫作向量召回,它通过将元素(实体)进行向量化表征来构建便于高效检索的索引。在检索端,也用相同的方式对检索元素(实体)进行向量化处理,利用检索技术进行检索召回,得到距离相近的商品或者元素(实体)集合,并根据距离远近进行排序。
实际上,这里用到的底层向量索引和检索技术是由阿里巴巴达摩院研发的,一方面将其封装成通用的底层功能库,集成到BE服务中,用于词向量和短文本向量召回的场景;一方面将其集成到其他服务(如HA3引擎)中,用于在文本搜索场景下解决文本匹配不足而造成的零少结果问题。
在BE中,向量召回也是一种召回方式,可以与BE最擅长的KV和KKV召回形式同时使用,也可以作为一种独立的召回方式实现完整的业务召回。
目前,向量召回已在阿里巴巴集团的大量场景(如猜你喜欢、猫客、SEO等场景)中应用,并取得了不错的效果。在1688的业务实践中,我们用BE的向量召回功能实现了SEO内链系统的重构,取得了不错的业务结果。
SEO(Search Engine Optimization,搜索引擎优化)是一种重要的营销手段,商家通过影响用户搜索引擎内的自然排名从搜索引擎中获得尽可能多的免费流量。SEO流程为:发现→抓取→解析→索引→排名→展现→转化。其中,内链系统就占了其中的3个重要环节:通过构建内链系统扩大搜索发现率、提高网页爬虫抓取量。因此,优化SEO内链系统对于SEO站内优化非常重要。
1688.com之前的SEO内链系统存在覆盖率不高且不均匀、相关性不佳、零少结果较多的问题。使用BE的向量召回功能重构SEO内链系统后,完美地解决了以上问题,召回成功率、覆盖率、相关性均有大幅提升。从整体效果看,爬虫量和索引量指标均得到大幅提升。
1688.com的SEO系统的架构如图3所示。
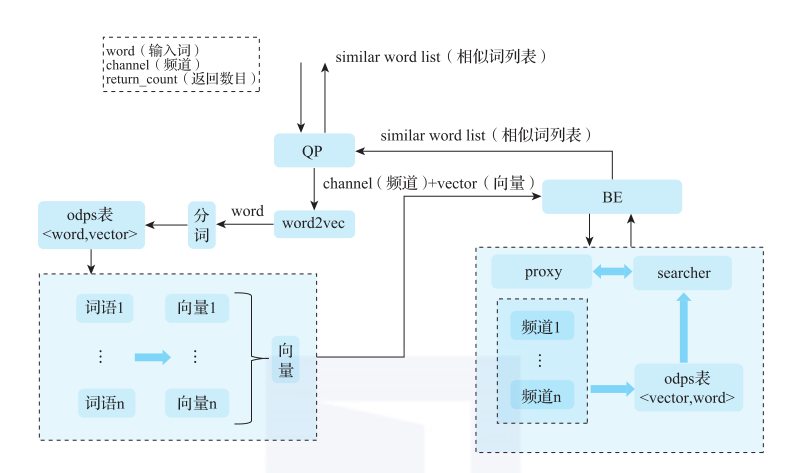
图3 1688的SEO系统架构
BE是推荐系统负责在线召回的引擎,基于DII算法在线服务平台实现,融合了搜索从离线到在线的全链路技术体系,并依托管控系统,实现了从开发、上线到运维的全生命周期管理。

算分服务RTP
为满足推荐和搜索两大业务对score/rank的需求,阿里巴巴搜索事业部在2016年开发了最初的RTP系统Rank Service排序服务器。它是一个支持数据分区、function函数插件化、实时feature特征和model模型更新的分布式服务。基于Rank Service我们可以搜索业务的match匹配和rank排序拆分为两个独立的模块,从而提升业务迭代效率及整体集群性能。
为更好地支持算法团队快速迭代深度模型,赋能业务,搜索事业部又对RTP系统进行了大幅度的迭代和升级。2017年引入了TensorFlow,将整个RTP框架改造成一个图执行引擎,从而可以支持任意的可用图描述的机器学习模型。在此基础上,又进一步增加了按模型分partition的功能,从而解决了超大模型单机无法容纳的问题。
在阿里巴巴内部,推荐业务使用了RTP的在线打分功能;搜索业务不仅使用了在线打分功能,还使用RTP对打分的结果进行在线排序。
1. RTP和TensorFlow Serving
TensorFlow在2017年提供了Tensorflow Serving,可以将训练好的模型直接上线并提供服务,RTP也支持将TensorFlow的模型上线并提供服务。那么,问题来了,既然已有TensorFlow Serving,为什么还要用RTP?引用RTP开发团队资深技术专家以琛的观点,相比TensorFlow Serving,RTP有如下3方面特点和优势。
对于大规模打分场景而言,大部分的数据从请求中带入是不合适的,而RTP系统本地有数据存储的能力,而且是基于Suez框架的表存储,有高效的压缩读取机制,同时还能完全支持实时链路。
RTP系统额外增加的feature产生、数据读取、插件等机制,使其能够做到灵活支撑业务逻辑。
RTP系统是基于Suez框架开发的,因此能继承其管控系统、分布式行列服务等能力,这使得我们的系统拥有了数据分片、模型分片的能力,从而在大规模模型或者数据应用场景中,发挥巨大优势。
Suez在线服务框架是搜索事业部自研的大数据在线服务的通用抽象(要求具备秒级数据更新的最终一致性)。Suez框架统一了以下3个维度的工作。
索引存储(全文检索、图检索、深度学习模型)
索引管理(全量、增量及实时更新)
服务管理(最终一致性、切流降级扩缩容等)
下面用一张图来描述RTP与Suez框架的关系。
图4是RTP系统的架构图。图中Tf_search是RTP的内核,基于Indexlib和Suez Worker承载对外提供端口服务。Suez Worker的部署由Suez admin完成和管理,而Suez worker和Suez admin的机器资源(如CPU、内存等)都是通过一个叫作Hippo的资源调度框架来管理的。
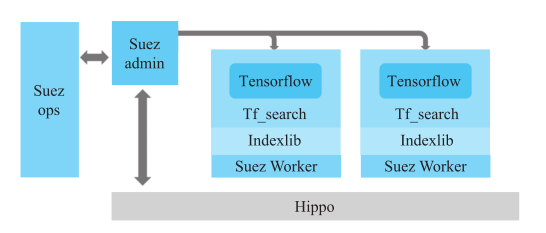
图4 RTP系统架构
RTP和TensorFlow Serving一样,基本的功能就是将模型进行加载并提供端口对外服务。下面,首先从阿里巴巴网站的搜索和推荐业务来阐述RTP在其中的位置;然后,介绍RTP的模型和数据更新机制;
接着,从RTP提供对外服务接口开始,一步步深挖RTP是如何借鉴TensorFlow的图化思想来实现既支持TensorFlow的原生深度模型,又支持LR模型、GBDT等传统模型的;最后,介绍在面对海量的数据和模型时,RTP在工作效率、稳定性及性能方面具备的独特优势。
2. RTP在阿里巴巴的应用
RTP应用在阿里巴巴的搜索和推荐业务中。对于搜索业务,RTP不仅用于对商品集合进行在线打分,也用于对商品集合按规则进行排序。对于推荐业务,RTP主要用于对商品集合批量打分。
图5是从搜索架构的视角看RTP的位置和作用。Rank Service和RTP内部其实是基于同一份二进制文件拉起的服务,都可以认为是宽泛意义上的RTP。两者的差异在于加载的模型不同,因而作用不同。
图中左下角的Rank Service加载的是Hobbit和Unicorn的Graph,作用是打分和排序;图中右下角的RTP加载的是深度模型的Graph,如WDL模型,作用是打分。
Rank Service将商品集合信息请求RTP,RTP算分后将结果返回给Rank Service,然后按分值进行排序,这些都是在Hobbit和Unicorn的Graph中完成的。
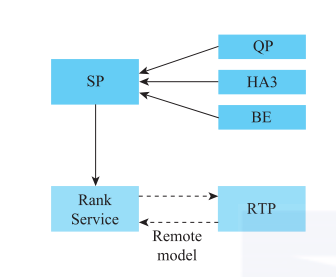
图5 RTP架构角色
我们接下来再从推荐架构的视角看RTP的位置和作用。推荐架构相对简洁,基于RTP使用模型对商品集合进行在线打分。
在阿里巴巴,ABFS(Ali Basic Feature Service)提供的是用户实时行为特征服务。IGraph既可以提供商品维度的信息,也可以提供用户行为的信息,是一个非常重要的图存储引擎,而BE则是推荐召回引擎。
图6中的TPP是将上述在线服务编排、处理、整合的一个平台。首先,TPP使用买家ID请求ABFS和IGraph,获取用户实时行为和离线行为特征;然后,将这些行为作为条件去请求BE,进行商品集合的召回;
最后,将商品集合、商品特征、用户特征一起请求RTP,对商品进行打分。在打分完成后,还会在TPP内部进行排序及翻页处理,然后再传出给调用方。
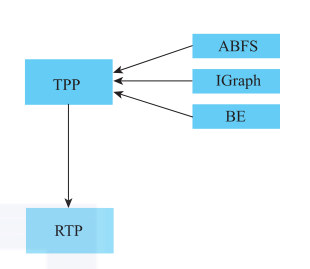
图6 推荐系统架构
上述典型的搜索和推荐业务是对批量的商品进行打分或者排序,除此之外,RTP还承接了其他类似的推荐业务,如对榜单、直播、短视频等进行打分。另外,RTP还承接了打分和排序以外的模型服务,例如1688的智能文案在线生成服务。
3. RTP模型和数据更新
原生的TensorFlow模型(如saved model)是不区分模型和数据的,只有模型的概念。这里的模型实际包含了两类信息:一类是图的结构,一类是参数的权重数据。在一个目录下存了多个文件,共同存储上述两类信息。RTP也支持saved model格式,不过这并不是RTP在生产环境的主流使用方式。
在生产环境的主流使用方式中,RTP出于对性能和数据容量的考虑,会将TensorFlow的原生模型按RTP的格式要求进行转换,分成两部分:一部分是抽取和转成网络结构,可以认为是模型的元数据,采用GRAPH.def的文件存放和使用;
另一部分是参数和对应的权重信息,采用KV表的形式进行分发和使用。RTP借助Suez框架将上述两部分信息进行分发并加载到内存中。上述网络结构的更新是非实时的,可以做到小时级别的更新,而参数和对应的权重支持实时更新,已应用在2019年的天猫“双11”大促中。
另外,RTP还有一部分信息可以做到实时更新,这就是内容表(item table)。在主流的应用场景中,内容表是一个超级大表,也是一个KV表,Key是商品ID,Value是商品维度的原始特征。
这么做是为了减小从请求串中传递的参数大小。大部分商品维度的特征可以从服务器本地的KV表中读取,而不是从请求串中解析。试想一下,如果数千个商品维度的特征都从请求串中传递,这个请求串会非常大,仅解析请求串、反序列化对象就会消耗不少时间。
4. RTP对外接口服务
一个系统想在竞争对手如林的环境中生存下来并推广开去,不断提升系统的用户体验很重要。在不同的业务场景和开发场景中,不同的使用者会要求不同的调用方式。RTP的对外接口支持用多种请求调用的方式来满足多种场景的需求,如图7所示。
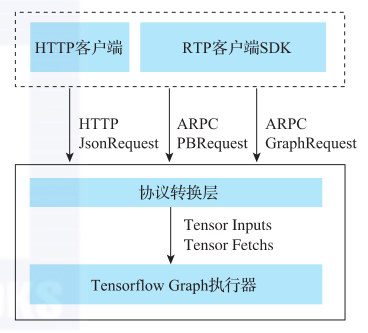
图7 RTP请求模式
RTP支持基于HTTP和ARPC两种协议的请求方式。其中,基于HTTP协议的请求方式与其他平台差别不大,整体过程就是在HTTP客户端将所有的输入拼装成JSON对象,按POST协议进行请求;
然后在RTP服务端将JSON对象解析为tensor input张量输入和tensor fetch张量读片以及其他的相关信息,调用TensorFlow Graph的执行器运行模型,得到fetch读片的具体内容;最后用同样的方式封装成JSON对象并返回给客户端。
对于基于ARPC协议的请求方式,其支持两种请求对象:一种是PBRequest,也就是JSON对象封装成了PB对象,其优点是对于单个请求附带了大量的商品id集合的场景,有比较大的性能提升;
一种是GraphRequest,这种请求是通过RTP客户端的SDK封装好tensor的input、fetch以及其他信息,存储到GraphRequest对象中,通过ARPC调用RTP,在RTP协议转换层将这些tensor信息传递给Tensor-Flow图执行器运行模型,得到输出的fetch的tensor。
基于HTTP协议的请求格式主要用于开发过程中的调试,在生产环境中会使用基于ARPC协议的请求格式。
5. RTP内部实现原理
前面讲到,RTP将模型拆分成两部分:一部分是纯粹的图结构,一部分是参数和权重数据。RTP会对图进行转化,将Training Graph训练图转成Inference Graph推理图,并对某些节点进行替换改写,使之能够读取本地数据KV表。图8所示是对训练出来的模型图进行添加和裁剪的过程。
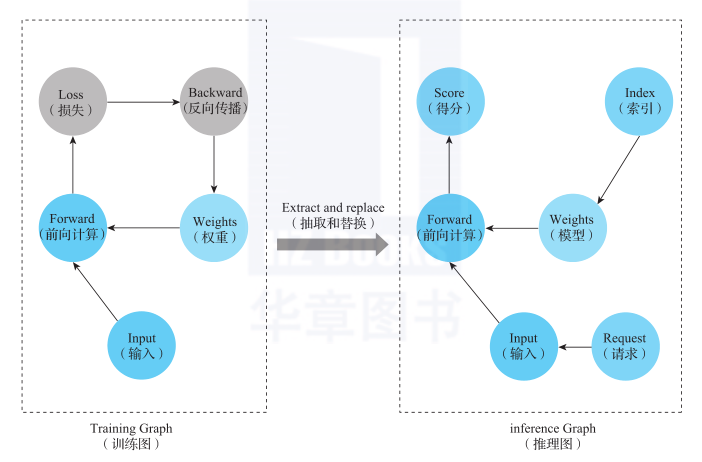
图8 模型加载
添加一些节点,如Placeholder,用于外部请求数据的输入;也会添加一些Feature Generator特征生成器相关的节点,用于对请求串中输入的数据进行特征生成。
这些特征生成节点如果涉及商品维度的特征生成,往往会和本地的内容表关联,在节点执行时,会检索本地内容表,获取商品维度的数据,然后进行特征生成。另外,会对某些节点(如Loss节点)进行删除,因为前向预测时,这些节点是用不上的。
RTP在阿里巴巴集团的搜索和推荐体系中占据了非常重要的位置,工程实现的管控系统对训练和上线流程的封装让整个过程非常顺畅,让算法工程师能专注于模型的优化,从而大大提高算法的生产效率。
RTP基于图化的内核设计思想,支持将各种原生的算法模型都转成图化模型的形式,具备极强的通用性,这也是RTP在集团内部如此受欢迎的原因之一。同时,RTP结合Suez框架提供的本地数据存储和查询机定制开发了一些图化操作算子,提升了模型预测的计算性能。
RTP服务端具备分布式存储数据和分片部署的能力,让数以亿计的商品维度的数据不再通过网络传输,减少了网络传输,极大提升了模型执行的性能。RTP依托Suez框架实现了模型和数据的实时更新能力,让模型能快速捕捉当前的变化,提升准确性。
本文摘编于《阿里巴巴B2B电商算法实战》经出版方授权发布。
#欢迎来留言#
你用过BE召回引擎和RTP算分服务吗?
对此你怎么看?
留言点赞数量最多的前三名
CSDN携手【机械工业出版社】送出
《阿里巴巴B2B电商算法实战》一本
截至7月30日12:00点

简介:本书是阿里巴巴CBU技术部(1688.com)深耕B2B电商15年的经验总结。阿里巴巴B2B在战略形态上经历了信息平台、交易平台和营销平台的升级迭代,本书聚焦营销平台商业形态背后的算法和技术能力,试图从技术和商业互为驱动的视角阐述技术如何赋能业务,并结合阿里巴巴集团在基础设域和算法创新上的沉淀,打造出智能B2B商业操作系统。

更多精彩推荐 ☞ 每个创始人都需要了解的来自 Y Combinator 的 13 个见解 ☞ 开发者批评苹果商店佣金过高,库克将面临立法者质疑;花呗接入央行征信;GitHub 发布更新| 极客头条 ☞ 那个从深圳流水线去了纽约做程序员的女工,最近失业了 ☞ 没想到!!Unicode 字符还能这样玩? ☞ 为什么说机器学习是预防欺诈的最佳工具? ☞ 区块链是工业4.0的领引者 ![]()
点分享 ![]()
点点赞 ![]()
点在看








