ELK + Filebeat 搭建日志系统
Elasticsearch
分布式搜索和分析引擎。具有高可伸缩、高可靠和易管理等特点。基于 Apache Lucene 构建,能对大容量的数据进行接近实时的存储、搜索和分析操作。
Logstash
日志收集器。搜集各种数据源,并对数据进行过滤、分析、格式化等操作,然后存储到 Elasticsearch。
Kibana
数据分析和可视化平台。与 Elasticsearch 配合使用,对其中数据进行搜索、分析、图表展示。
Filebeat
一个轻量级开源日志文件数据搜集器,Filebeat 读取文件内容,发送到 Logstash 进行解析后进入 Elasticsearch,或直接发送到 Elasticsearch 进行集中式存储和分析。
架构介绍
基于ELK的使用方式,Logstash 作为日志搜集器,Elasticsearch 进行日志存储,Kibana作为日志呈现,大致以下几种架构。
架构一
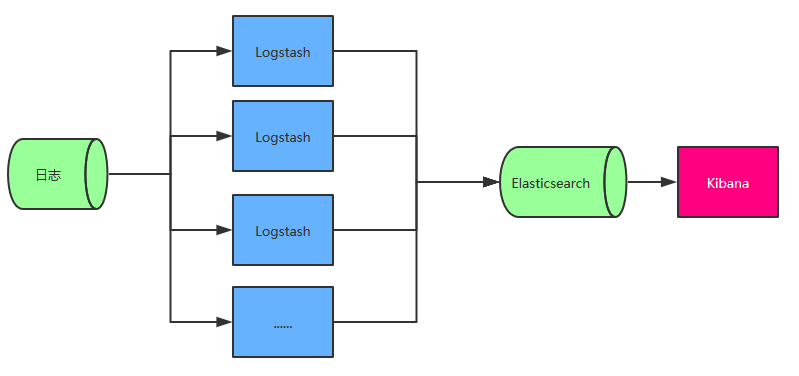
图中 Logstash 多个的原因是考虑到程序是分布式架构的情况,每台机器都需要部署一个 Logstash,如果确实是单服务器的情况部署一个 Logstash 即可。
前面提到 Logstash 会对数据进行分析、过滤、格式化等操作,这一系列操作对服务器的 CPU 和内存资源的消耗都是比较高的,所以这种架构会影响每台服务器的性能,所以并不推荐采用。
架构二
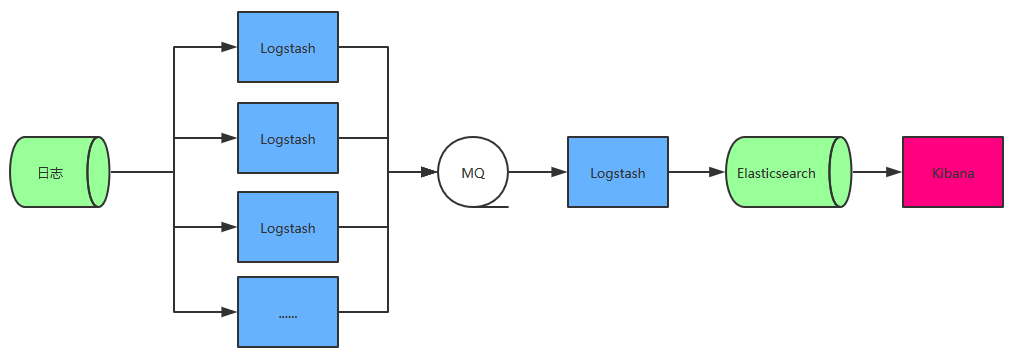
相比于架构一,增加了一个MQ 和 Logstash, Logstash 的输出和输入支持 Kafka、Redis、RabbitMQ 等常见消息队列, MQ 前的 Logstash 只作为日志收集和传输,并不解析和过滤,先将日志加入队列,由 MQ 后面的 Logstash 继续解析和过滤,这样就不至于每台服务器消耗资源都很多。
架构三

这种架构是基于架构二简化来的,实际在使用过程中也是可以采取的,日志直接进入 MQ,Logstash 消费 MQ 数据即可。
架构四
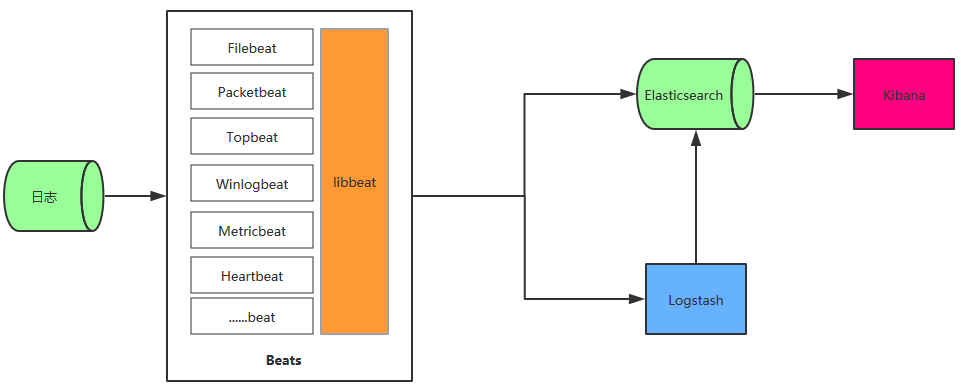
这种架构在日志数据源和 Logstash(或 Elasticsearch) 中增加了 Beats 。Beats 集合了多种单一用途数据采集器,每款采集器都是以用于转发数据的通用库 libbeat 为基石,beat 所占的系统CPU和内存几乎可以忽略不计,libbeat平台还提供了检测机制,当下游服务器负载高或网络拥堵时,会自动降低发生速率。下面的例子我们使用 Filebeat 来对文件日志的收集,其他的 beat 可以忽略。
架构四相比于架构二,如果将每台服务器上部署的 Logstash 都换成对应的 Beats ,那就是更理想的架构了。
不管怎么样,对于日志解析和过滤的 Logstash 资源消耗还是比较高的,所以如果需要,可以将 Logstash 的部署使用分布式,Elasticsearch 的部署使用集群来强化整个日志系统。
部署
部署之前需要安装好JDK,Java 8 版本。然后官方下载对应操作系统的安装包,如果采用Docker部署,直接使用提供的镜像即可。
下载包解压后就可以直接启动了。
Logstash
bin/logstash -f logstash.conf # logstash.conf是需要自己创建的日志处理配置文件
配置文件的基本格式如下:
# 输入
input {
}
# 分析、过滤
filter {
}
# 输出
output {
}
Elasticsearch
bin/elasticsearch
启动的时候如果出现不允许root启动,那创建一个新用户:
1. 创建用户组
groupadd elsearch
2. 创建用户
useradd elsearch -g elsearch -p elsearch
3. 切到root用户,修改 elsearch 用户组下的 elsearch 用户对 elasticsearch 文件夹(解压出的的elasticsearch目录)的权限
chown -R elsearch:elsearch elasticsearch
4. 切到elsearch用户,重启 elasticsearch
Kibana
bin/kibana
Filebeat
filebeat -e -c filebeat.yml
filebeat.yml 关键配置,所有/var/log/的.log文件的日志都会输出到 Logstash 的 5044 端口
filebeat.prospectors:
- input_type: log
paths:
- /var/log/*.log
output.logstash:
hosts: ["localhost:5044"]
Logstash 例子:
配置文件内容:
input {
beats {
port => 5044
codec => "json"
}
}
filter{
if [logtype] {
mutate { replace => { type => "%{logtype}" }}
}else{
mutate { replace => { type => 'unknow' }}
}
date {
match => [ "createTime" , "yyyy-MM-dd HH:mm:ss" ]
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "logstash-%{type}-%{+YYYY.MM.dd}"
}
stdout { codec => rubydebug }
}
配置文件说明:
使用 Filebeat 作为 Logstash 的输入(输入输出可以有多种方式,不太了解的可以先写看看官方文档),Logstash 监听了 5044 端口。这个例子中对接收到的日志进行 json 格式化,如果 json 中包含 logtype,我们把日志的 type 设置成 logtype,如果不包含,设置成 unknow,然后把日志中的 createTime 格式化成 yyyy-MM-dd HH:mm:ss 的时间格式。最后输出到 elasticsearch,index 是 elasticsearch 的索引名称,我们根据不同的 type 创建不同的索引。
生产环境下 Kibana 使用效果图
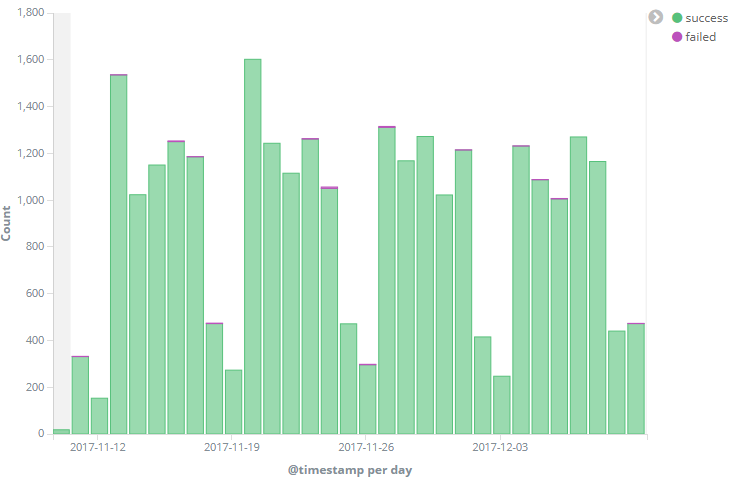
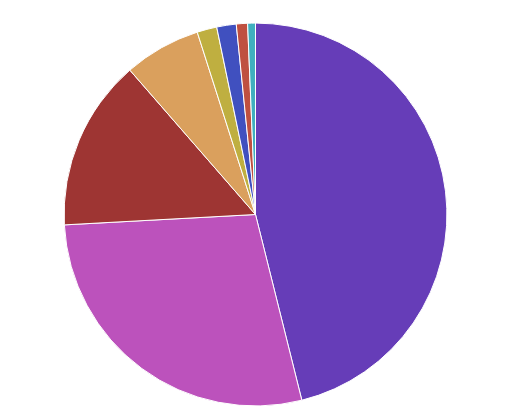
出处:http://beckjin.com/2017/12/10/elk/
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢。
-END-

优秀人才不缺工作机会,只缺适合自己的好机会。但是他们往往没有精力从海量机会中找到最适合的那个。
100offer 会对平台上的人才和企业进行严格筛选,让「最好的人才」和「最好的公司」相遇。
扫描下方二维码,注册 100offer,谈谈你对下一份工作的期待。一周内,收到 5-10 个满足你要求的好机会:






