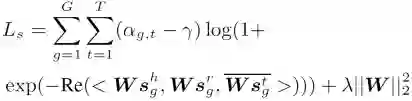人工智能顶级会议 AAAI 2020 将于 2 月 7 日-2 月 12 日在美国纽约举办,不久之前,AAAI 2020 公布论文介绍结果:今年最终收到 8800 篇提交论文,评审了 7737 篇,接收 1591 篇,接收率 20.6%。本文对北京理工大学、阿里文娱摩酷实验室合作的论文《Joint Commonsense and Relation Reasoning for Image and Video Captioning》进行解读。
![]()
论文链接:https://wuxinxiao.github.io/assets/papers/2020/C-R_reasoning.pdf
在此论文中,作者们提出了一种联合常识和关系推理的图像视频文本描述生成方法。该方法通过迭代学习算法实现,交替执行以下两种推理方式:(1) 常识推理,将视觉区域根据常识推理,嵌入到语义空间中从而构成语义图;(2) 关系推理,将语义图通过图神经网络编码,生成图像视频文字描述。
图像视频的文字描述本质上是视觉到语言 (Vision-to-Language,即 V2L) 的问题。作为视觉理解 (Visual Understanding) 的一个研究方向,连接着视觉与语言,模型需要在理解图像视频的基础上给出描述视觉内容的自然语言语句。该任务在人机交互或者素材检索中有着重要的应用前景。比如在图 1(a) 中,老师要求幼儿园或者低年级的小朋友们看图说故事,具备图像视频的文字描述技术的机器可以辅助教学,与小朋友形成互动。在图 1(b) 中,一个视频网站的编辑运营人员试图搜索「易烊千玺跳舞」或者「在海边散步的恋人」的视频片段。
![]()
![]()
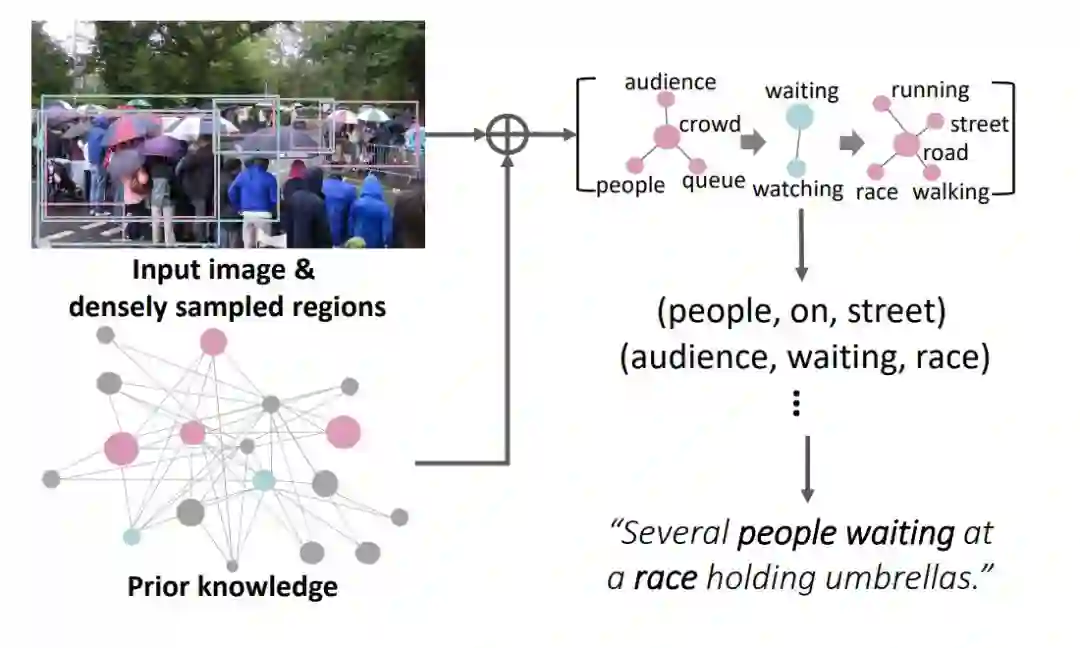
推理视觉关系有助于提高图像视频文字描述模型的性能。现有方法 [1-3] 通常使用预训练的物体或关系检测器来提取场景图,再推理图中各物体之间的关系。该类模型依赖鲁棒的物体或关系检测器,遇到遮挡、小物体等情况会导致检测结果不准确,进而影响文字描述的生成。在现实生活中,人们可以通过常识(先验知识)来联想推理一些不易识别或不可见的事物。如图 2 所示,人们通常会用「Several people waiting at a race holding umbrellas(一些打着雨伞的人在等一场比赛)」来描述图中内容,但实际上并不能从图像中直接观测到「race(比赛)」这个语义。然而可以通过观测到的「人群围在马路两旁」来推断出这是一场比赛。而这个推断的依据就是「人群围观」和「比赛」之间的关联常识。受此启发,本文作者提出利用常识引导推断图像视频中的语义关系,进而生成文字语句的描述方法。该方法联合关系与常识推理,不依赖任何物体或关系检测器,并且在训练时也不需要场景图的标注,这样的好处是:(1) 通过额外知识的引导,探索获得难以从视觉信息中学到的物体或关系;(2) 通过端到端的学习,可以保持图像视频和文字描述的语义一致性。
![]()
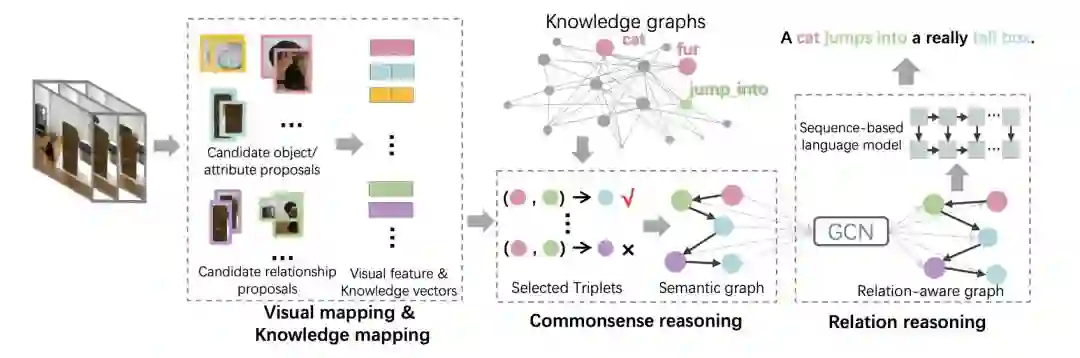
本文提出的联合推理方法,结合以下两种推理方式:(1) 常识推理,将图像视频区域根据常识推理,嵌入到语义空间中从而构成语义图;(2) 关系推理,将语义图通过图神经网络(graph convolutional network, GCN)编码,生成图像视频的文字描述。如图 3 所示,该方法包含三个模块:视觉映射与知识映射、常识推理、关系推理。在视觉映射与知识映射模块中,首先稠密采样图像或视频的局部区域,将这些区域根据表观特征聚类得到候选语义(即物体、属性和关系)。然后分别使用视觉映射与知识映射学习候选语义的视觉特征向量和知识向量。在常识推理模块中,根据知识图谱来挑选候选语义组成语义图。在关系推理模块中,使用图卷积网络和基于序列的语言模型将给定的语义图经过关系推理得到图像或视频的文字描述。
![]()
视觉映射是提取图像或视频的局部特征。首先稠密采样每个图像(视频)的 2D 图像块(3D 视频块),然后使用预训练的 CNN 提取特征,最后将这些特征聚类,用聚类中心表示候选语义的视觉特征向量。
知识映射是将图像(视频)的候选语义映射到知识空间上。首先,将每个图像(视频)的视觉特征通过多头注意力机制(multi-head attention mechanism)映射到语义概念空间(每个图像视频的真值语义是直接由其真值句子通过词类标注工具自动得到),得到语义概念;然后学习这些语义概念的知识嵌入(knowledge embedding);最后将知识嵌入向量作为基,语义概念的概率作为权重系数,加权相加后得到图像(视频)候选语义的知识向量。
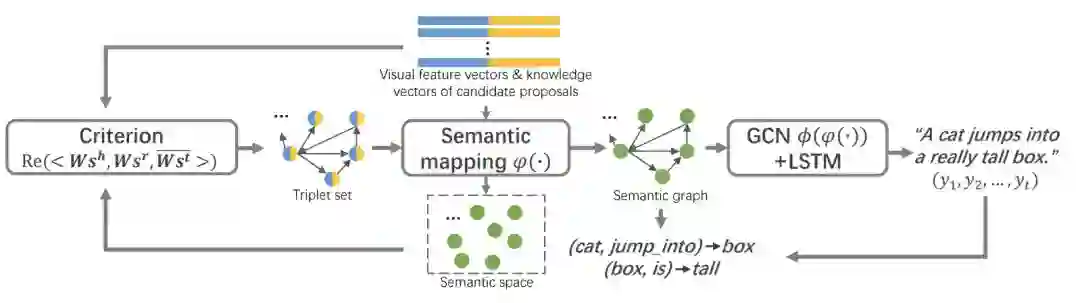
给定图像(视频)候选语义的视觉特征向量和知识向量,迭代执行常识和关系推理训练视频(图像)文字描述模型,如图 4 所示。
![]()
具体地,常识推理包含语义映射(semantic mapping)和准则(criterion)模块,语义映射将图像视频的视觉特征和知识向量表达为语义特征,而常识推理的准则根据 [4] 设置为:
![]()
其中 s^h,s^r 和 s^t 分别为头实体(物体语义),关系(关系语义)和尾实体(物体或属性语义)的语义特征,W 为权重矩阵,Re(·) 和 Im(·) 分别表示取实部和虚部。根据该准则来选取三元组构成图像(视频)的语义图。
关系推理由 GCN+LSTM 模块实现,使用 [5] 提出的 GCN 得到关系敏感(relation-aware)的三元组特征,将三元组的语义特征级联,输入到 top-down attention LSTM [6] 中得到文字描述。
通过过端到端的方式联合训练本文模型,设置目标函数为
![]() ,
其中,
,
其中,
![]() 为交叉熵损失,用于学习生成句子;
为交叉熵损失,用于学习生成句子;
![]() ,指导学习三元组的语义特征,由常识推理中的准则来度量。
,指导学习三元组的语义特征,由常识推理中的准则来度量。
由于使用常识推理准则来构建语义图是一个「硬分配」任务,直接反向求导优化效果不佳。本文提出迭代推理算法,交替执行基于常识推理的语义图生成以及利用常识和关系推理的文字描述生成来优化模型,从而使模型的端到端训练更加稳定,如算法 1 所示。
![]()
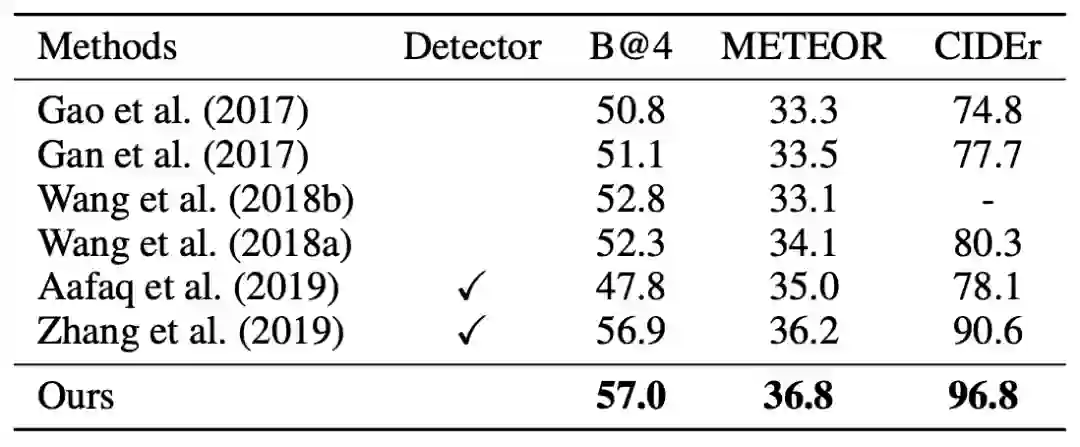
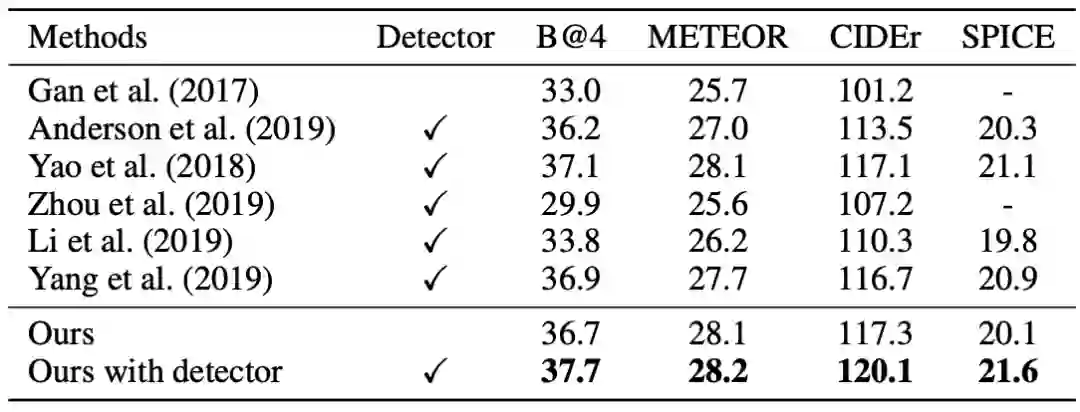
在 MSVD 视频数据集和 MSCOCO 图像数据集上进行了实验。结果如表 1 和表 2 所示。在 MSVD 数据集上的结果表明,即便与使用了检测器的方法比较,本文方法的性能也十分优越。在 MSCOCO 数据集上,由于检测器在 MSCOCO 目标检测集上预训练,所以检测结果比较准确。为了公平起见,本文加入了直接使用检测器提取局部图像块的实验,结果明显高于所有 state-of-the-art 方法。
![]()
![]()
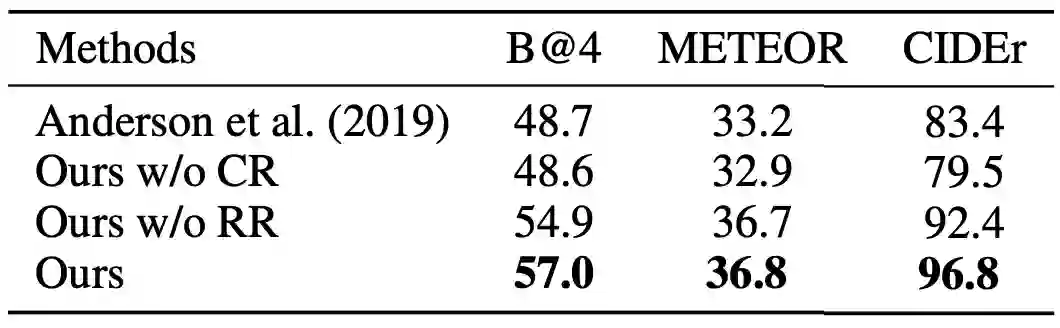
本文还在 MSVD 数据集上进行了消融实验,结果如表 3 所示。其中「Anderson et al. (2019)」是 baseline 方法,相当于本文方法去掉了常识和关系推理;「Ours w/o CR」方法直接使用预训练检测器,来代替常识推理生成语义图;「Ours w/o RR」方法是去掉了关系推理,即 GCN。实验结果表明了本方法各个模块的有效性,值得注意的是,「Ours w/o CR」方法的性能甚至低于「Anderson et al. (2019)」,可见在视频上使在图像域预训练的检测器得到的语义图直接进行关系推理会导致性能下降。
![]()
本文还展示了 MSVD 数据集和 Youku-VC 视频中文描述数据集的定性实验结果,如图 5 所,其中「o-r-o」和「o-r-a」分别表示语义图中的「物体-关系-物体」和「物体-关系-属性」。由图可见,本文方法可以推断识别出一些不易检测(遮挡,小尺寸)的物体,如图 (b) 中的「makeup」,(d) 中的「woman」,和 (f) 中的「话筒」。
![]()
图 5 MSVD 和 Youku-VC 数据集上的定性实验结果
本文提出了一种联合常识和关系推理的方法用于图像视频的文字描述生成。该方法利用先验知识交替迭代执行常识推理和关系推理,生成语义图来学习物体之间的语义关系,从而准确描述图像视频的内容。在图像和视频数据集上的实验表明,该方法优于其他最新方法。
[1]Li, X.; and Jiang, S. Know more say less: Image captioning based on scene graphs. IEEE TMM, 2019.
[2]Yao, T.; Pan, Y.; Li, Y.; and Mei, T. Exploring visual relationship for image captioning. ECCV, 2018.
[3]Yang, X.; Tang, K.; Zhang, H,; and Cai, J. Auto-encoding scene graphs for image captioning. CVPR, 2019.
[4]Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; and Bouchard, G. Complex embeddings for simple link prediction. In ICML, 2018.
[5]Johnson, J.; Gupta, A.; and Fei-Fei, L. Image generation from scene graphs. CVPR, 2018.
[6]Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; and Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In CVPR, 2019.
12 月 28 日下午,阿里文娱技术发展部将联合北理工、机器之心共同举办 AAAI2020 论文解读会。
欢迎感兴趣的读者们点击阅读原文参与报名。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content
@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


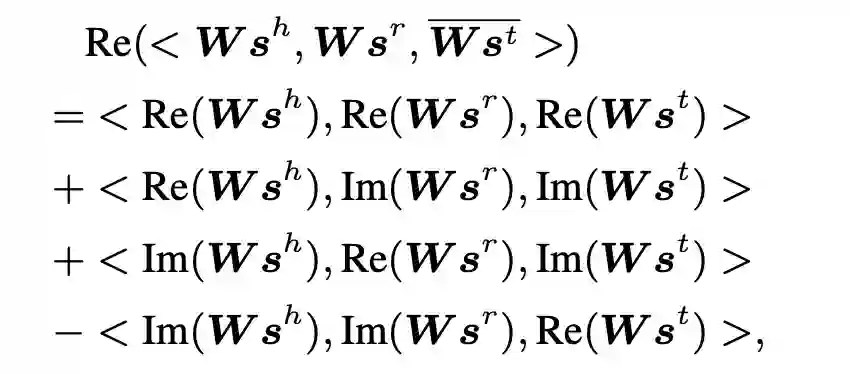
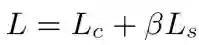 ,
,
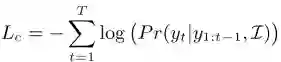 为交叉熵损失,用于学习生成句子;
为交叉熵损失,用于学习生成句子;