高达99.5%准确率,火眼金睛的“鉴黄系统”背后技术大揭秘
悟空鉴黄系统在京东上线已一年多,在京东云上提供接口也有数月,同时服务于京东主图、晒单图及京东公有云网站的图片审核,并向外部提供通用鉴黄功能。
其中通用鉴黄算法在大于 99.5% 准确率下,可以节省 90% 以上的审核人工。主图和晒单图每日调用量超过千万次,京东云相关每日调用量达到了数百万次。

本篇将讲解鉴黄问题的特点和难点,并为大家揭秘悟空鉴黄系统背后的技术。
图像分类和鉴黄任务
图像分类是计算机视觉中的基础任务之一,悟空鉴黄系统背后的算法解决的就是一个分类问题,判断待审核的图像中包含的物体/内容属于哪一类:
色情:露点,明显性行为。
性感:非色情,但是暴露,或是带有性暗示的肢体挑逗画面。
-
其他:其他。
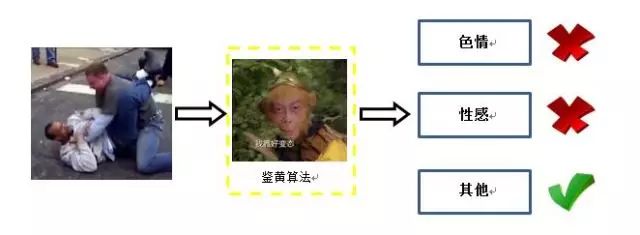
图1:鉴黄算法流程示意
注:这里的“性感”和描述女神男神时的“性感”含义并不完全重合。
01
鉴黄问题自身特有的难点
虽然看上去是个简单的三分类问题,但是和常见的 MNIST/CIFAR/ImageNet 等分类任务不同,鉴黄问题有自身特有的难点:
多标签数据
和 ImageNet 等单标签数据集不同,鉴黄模型面对的图片没有特定类型,画面中包含的物体也没有限制。
比如穿着暴露的人和全裸露点的人物同时出现在画面内,输出的最终结果不能是色情+性感,而是判定为色情图片。也就是说是个带优先级的分类任务:色情>性感>其他。
非符号化(Non-iconic)图像
在 ImageNet/CIFAR 等数据集中,图像内容往往是比较明确的,比如下图中第一行的狗和人物肖像,图像信息明确,主题占比通常较大。而鉴黄任务中,面向的是真实场景中的图像,包含大量的非符号化数据,比如下图中第二行的例子。
在这种图像中,哪怕是画面中不引人注意的位置上,很小的一部分画面出现了色情信息,也需要被判别为色情图片。

图2:Iconic 和 Non-iconic 图片示意
数据特殊性
鉴黄任务中,色情和性感图片在像素空间占据的只是很小的区域,其他类别占据了绝大部分像素空间。而在模型中,我们则是期望模型学习到的特征主要是和色情和性感图片相关的特征。
在用于分类的特征空间中,因为其他类别图片种类非常丰富,所以和色情/性感类别的分类边界是难以捉摸的,另一方面色情/性感类别图片因为常常很相似,所以分类边界的求解非常有难度。
针对鉴黄问题的特点和难点,我们进行了一系列技术上的尝试和探索,下面为大家一一道来。
02
卷积神经网络
在当前,卷积神经网络(Convolutional Neural Network,CNN)已经成为几乎所有图像分类任务的标配。
早在 1989 年,Yann LeCun 就发明了卷积神经网络,并且被广泛应用于美国的很多银行系统中,用来识别支票上的手写数字。
2012 年,一个加强版的卷积神经网络 AlexNet 在 ILSVRC 比赛中的图像分类指标超越了基于传统算法近 10 个百分点,自此卷积神经网络就逐渐成了识别相关的计算机视觉任务中的标配。
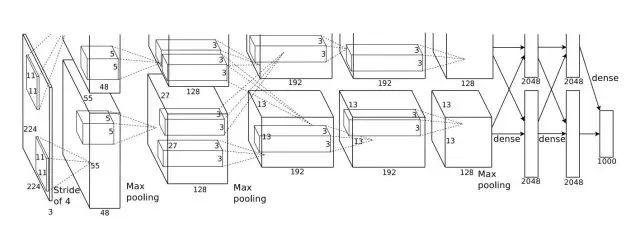
图3:AlexNet
2014 年,Network in Network 被提出,1x1 卷积和 Global Pooling 被广泛应用。
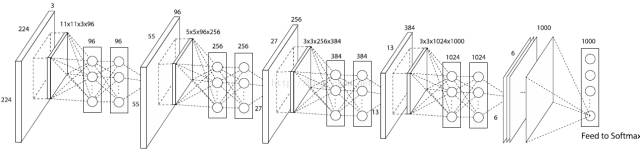
图4:NIN
同年的 GoogLeNet 开始把“并联”卷积路径的方式发扬光大,并在 ILSVRC 中拿下了分类指标的冠军。
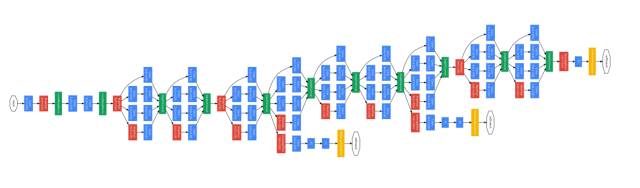
图5:GoogLeNet
2015 年,为了解决深度网络随着层数加深性能却退化的问题,当时还在 MSRA 的何恺明,提出了 Residual Block 并基于此和前人经验推出了 ResNet 这个大杀器,在 ISLVRC 和 COCO 上横扫了所有对手。
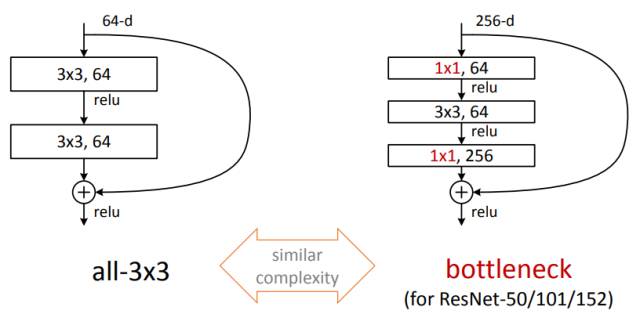
图6:Residual Block
ResNet 虽然看上去更深了,直观来理解其实是不同深度网络的一个 ensemble,Cornell 的 Serge Belongie 教授专门用一篇论文讨论了这个问题。
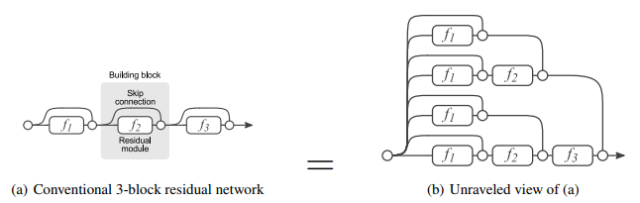
图7:Residual Block 的 Ensemble 解释
沿着这个思路,清华、Cornell 和 FAIR 在 2016 年合作提出了 DenseNet,并获得了 2017 年 CVPR 的最佳论文。
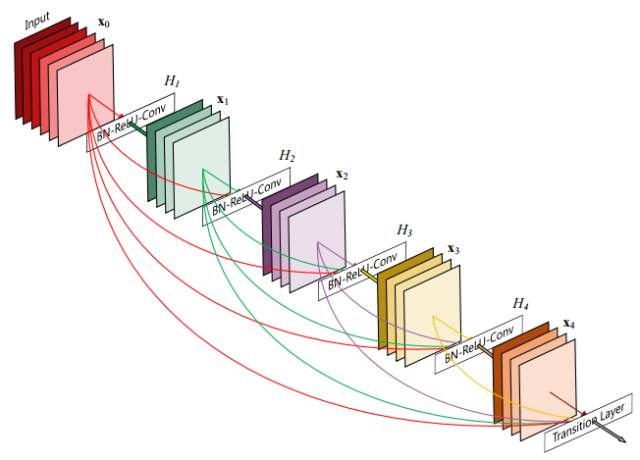
图8:DenseNet
也有沿着 GoogLeNet 继续把“并联”卷积研究到极致的,同样是发表在 CVPR2017 的 Xception。作者的观点是,卷积核的维度和学习难度也直接相关,让卷积响应图之间去掉关联,既能学习到没有相关性的特征,还能降低卷积核学习的难度。
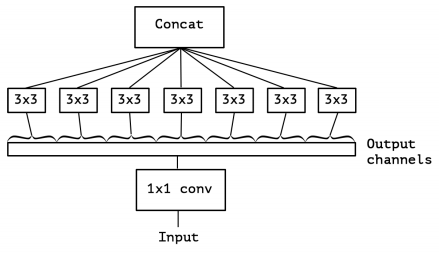
图9:Xeception Depthwise Convolutions
总之研究者们在优化网络结构的道路上还在继续,不过从实用的角度看,越是复杂的网络,训练的难度也常常越高。
在鉴黄模型研发的长时间摸索中,我们发现 ResNet 是在训练难度和模型性能上最平衡的一种结构。所以目前悟空鉴黄算法是在 ResNet 基础上进行了优化和改进的一种结构。
03
迁移学习
万事开头难,尽管网络上的十八禁资源到处都是,数据的积累却常常不是一蹴而就。在悟空系统的起步阶段,迁移学习是快速得到可用模型的法宝之一。
具体到鉴黄算法上,我们的方法是基于其他经过大量数据训练过的卷积神经网络模型基础上,利用有限的数据进行参数微调。
微调的思想是,在神经网络中,特征是分层一步步组合的。低层参数学习的一般是线条,纹理,颜色等信息,再高一些的层学习到简单图案,形状等,最高层的参数学习到的是由底层特征组合成的语义信息。
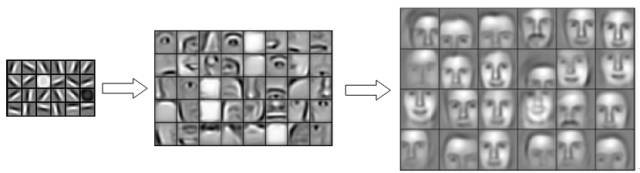
图10:CNN 特征的分层表达示意
所以在不同任务中,低层的特征往往是差不多的,那么只需要改变高层的参数就可以在不同任务间最大化共享信息,并达到很好的泛化。
直观来理解,色情图片的检测中,背景画面部分就是一般的图片,色情内容其实也是人,很多信息是和一般数据集,比如 ImageNet 数据共享的。
所以只需要学习到针对色情图片的高层语义信息就可以用少量数据训练一个良好泛化的模型。
为了实现微调,我们首先会找一个常见的基础模型,比如 ImageNet 预训练好的各种流行网络结构。然后冻结低层参数的学习率,只让模型高层和语义相关的参数在少量样本上进行学习。
那么,怎么知道哪些层需要冻结,哪些层需要学习呢?我们探索过两种基于可视化的办法,一种是 2013 年 ILSVRC 分类冠军 Matthew Zeiler 的 Deconvolution,通过从上至下的 Transposed Convolution 把响应图和特定图片中的相应区域关联在一起,可以观察响应图激活对应的区域。

图11:基于 Deconvolution 的卷积核可视化
不过这种方法实现较麻烦,而且需要对给定图片进行观察,有时候难以帮助发现模型本身的特点。
另一种方法是直接在图像空间上以最大化激活特定卷积核得到的响应图作为目标(Activation Maximization),对输入图像进行优化,看最后得到的图案,这种方法最早是 Bengio 组在 2009 年的一个 Tech report:《Visualizing Higher-Layer Features of a Deep Network》,后来被用到了很多地方,包括可视化、对抗样本生成和 DeepDream。
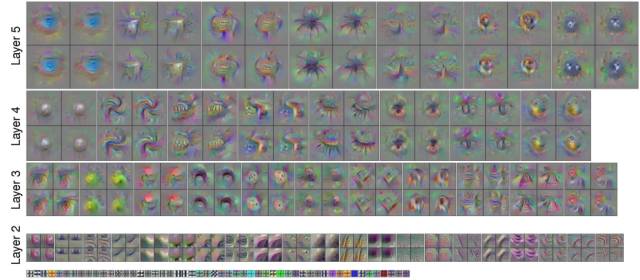
图12:基于激活最大化的卷积层可视化
这个方法的优点是简单易操作,缺点是图像常常看不出是什么,有时需要脑补。所以即使有了可视化手段的辅助,决定如何微调参数仍是个经验活,如果机器资源足够可以写个脚本自动训练所有可能情况进行暴力搜索。
除了基于图像分类模型,VOC 和 COCO 等数据集训练出的检测模型的网络也是很好的微调基础。
检测和分类虽然是不同的任务,但关系十分紧密,尤其是鉴黄应用中,露点是决定是否色情的关键标准之一,而露出的“点”是个位置属性很强的信息。
在悟空鉴黄研发的过程中,我们也基于迁移学习的思想,尝试了很多分类和检测结合的手段,对最终模型的效果也起到了很大的促进。
04
类别响应图可视化
当一个模型训练好之后,为了提升指标,我们会探索一些模型本身的特性,然后做针对性的改进,可视化是这一步骤中最常见的手段之一。
上一部分中,已经提到了激活最大化的方法,在训练好的模型中,这也是非常有效的一个手段。
举个例子,对于 ImageNet 训练出的模型,如果我们对哑铃进行激活最大化的可视化,会看到下面的图像:

图13:ImageNet 预训练模型中哑铃类别的最大激活图像
除了哑铃,还会出现手,而手并不是目标的特征。在黄图中,比如某类数据中露点的部位 A(例:大长腿)常常伴随着一个其他特定图案 B(例:露点)出现,就会发生类似的情况。
这样的后果是一些没有包含露点部位 A 的正常图片,因为包含了特定图案 B,就会有被误判为色情图片的倾向。通过可视化的手段,如果发现了这样的情形,就可以在数据层面进行改进,让真正 A 的特征被学习到。
从直观角度讲,基于激活最大化的方法并不是很好,所以更常用的一个办法是类别激活响应图(Class Activation Map,CAM)。
CAM 自从 NIN 中提出 1x1 卷积和 Global Pooling 就被很多人使用过,不过第一次比较明确的探讨是在 MIT 的 Bolei Zhou 的论文《Learning Deep Features for Discriminative Localization》中。
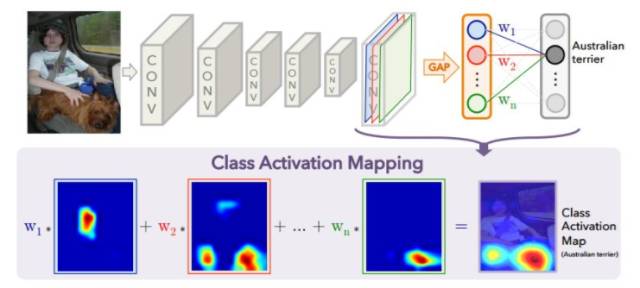
图14:类别激活响应图
这种方法的基本思想是把 Global Pooling 之后,特定类别的权重应用在 pooling 之前的 feature channel上,然后按照像素加权求和,得到该类别激活在不同位置上的响应。
这种方法非常直观地告诉我们,当前类别中图像的哪些部分是主要的激活图案。在分析模型的漏检和误检样本的时候,我们通过这种方法分析模型对图像中人一眼就能识别的图案是否敏感,决定改进模型时更新数据的策略。
05
Loss Function
一般来说,我们在进行机器学习任务时,使用的每一个算法都有一个目标函数,算法便是对这个目标函数进行优化,特别是在分类或者回归任务中,便是使用损失函数(Loss Function)作为其目标函数,又称为代价函数(Cost Function)。
损失函数是用来评价模型的预测值 Y^=f(X) 与真实值 Y 的不一致程度,它是一个非负实值函数。通常使用 L(Y,f(x)) 来表示,损失函数越小,模型的性能就越好。
设总有 N 个样本的样本集为 (X,Y)=(xi,yi),yi,i∈[1,N] 为样本i的真实值,yi^=f(xi),i∈[1,N] 为样本 i 的预测值,f 为分类或者回归函数。那么总的损失函数为:
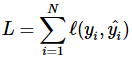
选择一个合适的损失函数,是成功训练一个深度学习模型的关键,也是机器学习从业者研究和专注改进的目标。
各种各样的损失函数层出不穷,其中包括:适用于训练回归任务的欧式距离损失函数(Euclidean Loss),适用于 Siamese 网络的对比损失函数(Contrastive loss),适用于一对多分类任务的铰链损失函数(Hinge Loss),预测目标概率分布的 Sigmoid 交叉熵损失函数(Sigmoid Cross Entropy Loss),信息增益损失函数(InformationGain Loss),多项式逻辑损失函数(Multinomial Logistic Loss),Softmax损失函数 (SoftmaxWithLoss) 等等。
TripletLoss 是一种基于欧式距离的损失函数,自从 Google 提出后,在人脸识别等领域得到了广泛应用。
优化 TripletLoss 时,算法尽量减小正样例对的欧氏距离,增大负样例对的欧式距离。广为人知的是,基于欧式距离的分类,对锐化图像和模糊图像缺少区分能力。
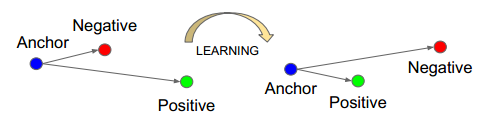
图15:Triplet 训练示意
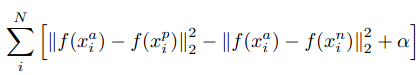
SoftmaxWithLoss 是深度学习分类任务中最常用的损失函数,softmax 采用了连续函数来进行函数的逼近,最后采用概率的形式进行输出,这样弱化了欧氏距离损失函数带来的问题。
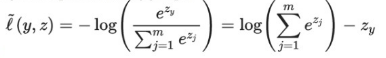
对抗样本及 GAN 在鉴黄算法中的应用
在鉴黄算法的研发过程中,我们也做了一些在学术界前沿和热门算法落地的尝试,主要包括对抗训练和生成式对抗网络。
01
对抗样本和对抗训练
对抗样本是指专门针对模型产生的让模型失败的样本。深度学习虽然在图像分类任务上大幅超越了其他各种算法,但是作为一种非局部泛化的参数模型,却是非常容易被攻击的模型。
比如一幅图,加上一个针对模型产生的攻击“噪声”之后,就会被以非常高的置信度分为错误的类别。

图16:攻击样本示意
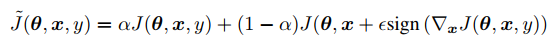
对抗样本实际上会对模型的分类边界进行改善,在悟空鉴黄算法的研发中,我们引入了对抗训练,来提高模型的泛化性。
02
生成式对抗网络(GAN)简介
生成式对抗网络是 2017 年视觉和机器学习领域的绝对热点。生成式对抗网络包含两部分,一个是用于生成样本的生成式模型 G,另一个是用于区分生成样本和真实样本的判别模型 D。
从思想上来说,生成模型的思路是让一个简单分布(比如多维高斯分布)经过模型的变换生成一个较为复杂的分布,这个分布要尽量逼近目标数据的分布,这样就可以利用生成模型得到目标数据的样本了。
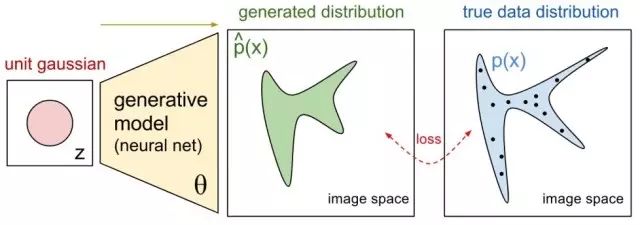
图17:生成式模型示意
所以目标是要让两个分布贴近,最基础的想法就是学习参数让样本似然最大,比如 MLE;或者变换另一个思路,让两个分布的差异尽量小,GAN 就属于这一类。
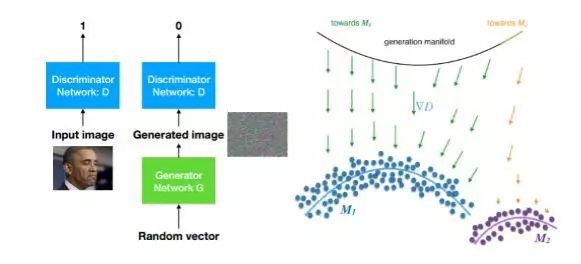
图18:GAN 示意
GAN 中由 G 产生的样本会尽量朝着数据所在的流形贴近,目标是让 D 分不出来,而 D 也会在每次训练中让自身能力提升,尽量区分哪些样本是真实的、哪些是 G 产生的,相当于一个零和博弈,这就是对抗的由来。
理想情况下,最后 D 再也无法提升,G 学习到真实的数据分布,并且和输入分布所在空间建立一种对应。
03
半监督学习
具体到鉴黄算法中,GAN 的作用主要体现在通过改善数据的分类边界,对少量类型数据的提升。
吴恩达提到过,深度学习中,算法是引擎,数据是燃料。虽然现在悟空鉴黄系统已经达到千万级海量数据,但是数据总是越多越好,并且对于有些特定类型的数据,数量未必高到可以单纯训练就达到很好效果。这种情况下,半监督学习是改善模型性能的一个选项。
2016 年,在鉴黄算法研发初期,我们就尝试过用 GAN 学习特定类别的数据,并生成数据,作为伪色情和伪性感类别加入到模型当中进行更多类别的半监督模型训练,使用的时候再抛弃伪类别。
定性来看,在数据很少的时候,每个类别之间的分类边界会非常粗糙,倾向于“原理”数据所在的流形,而用 GAN 生成的数据中,和真实数据有一定的相似性(纹理,局部图案),肉眼却一眼就能分辨不同于真实数据(因为目前非条件 GAN 只能生成一些简单数据比如人脸、火山、星球等)。
这相当于产生了一批更靠近真实数据的伪数据,让判别器学习真实数据和这种数据之间的分类边界就可以让边界离真实数据靠的更近。数据量少的时候,这种方法能带来非常大的泛化性能提高。
不过需要注意的是这种方法有个假设:G 网络不能生成很完美的图像,否则 G 网络就相当于一个数据发生器,会导致分类网络崩溃。后来和我们做法类似的方法开始出现在论文里,比如NVIDIA的《Semi-Supervised Learning with Generative Adversarial Networks》。
04
数据的模拟和生成
在鉴黄算法的研发中,我们也尝试了一些看上去比较超前的算法,比如 Image-to-Image Translation。
鉴黄问题中色情和性感类别因为有很高的相似性是非常难区分的,比如一个险些露点的图片就是性感类别,而一旦露点了,即使画面其他部分几乎一样,也是色情类别。
为了针对这种情况提高准确率,我们的思路如果能生成图片对,一幅是色情一幅是性感,就可以针对这样的图片对进行训练,达到对色情/性感类别更强的分类能力。
沿着这个思路,我们尝试了 UC Berkeley 发表的 Pix2Pix:《Image-to-Image Translation with Conditional Adversarial Networks》和 Cycle-GAN:《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks》。
利用 Pix2Pix,我们可以把带马赛克的图片(标注为性感)中的马赛克去掉(标注为色情)。Pix2Pix 其实就是一种单纯的对图像进行变换的 CNN 结构,模型的训练上就是把图片配好对,训练输入图片尽量生成和输出差不多的图片。
传统的类似结构中,都是用重建误差来作为训练目标,不过基于重建误差的目标往往会导致重建的图片非常模糊,而 GAN 中的 Adversarial loss 正好可以解决模糊问题,所以被广泛应用于需要生成丰富细节的图像的应用,Pix2Pix 是其中之一。
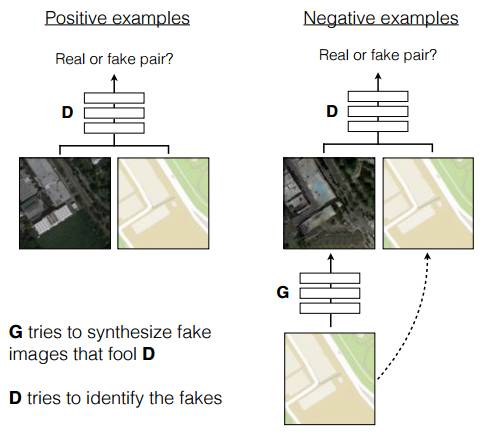
图19:Pix2Pix
Pix2Pix 去除马赛克的效果大致贴出来大家感受一下(左边是马赛克图片,右边是 Ground Truth,中间是模型生成图片):

图20:Pix2Pix 去除马赛克效果展示
带马赛克的图片算是比较小众的一种图像,在实际场景中未必会对模型有很大帮助,如果能有穿衣服-不穿衣服的图像对,对泛化能力的提升应该会更有意义,所以我们又尝试了 Cycle-GAN。
Cycle-GAN 其实也只是用到了 Adversarial loss,和生成模型没什么关系,主要的贡献还是把对偶学习结合 Adversarial loss 用到了图像翻译上。
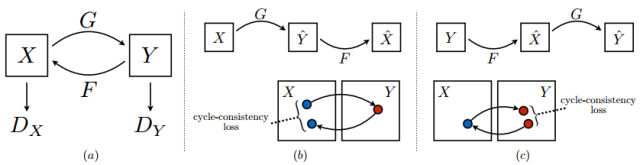
在 Cycle-GAN 中,每一次训练会把一个 domain 中的图像翻译到另一个 domain,然后在翻译回来,并检查一致性,同时每次被翻译的图像是否和该 domain 真实样本可区分,通过 adversarial loss 实现:
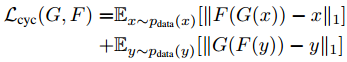
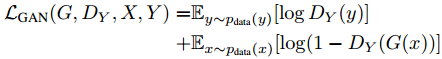
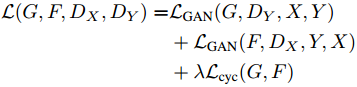
最后穿衣服的效果如下(左图马赛克为手动加上):

图21:Cycle-GAN 穿衣服效果展示
因为生成图片的成功率较低,最后并没有应用到实际的训练中。不过随着整个 AI 领域技术的不断进步,各种开脑洞的办法会越来越多,我们也会持续探索和改进,让我们的鉴黄算法更加准确、高效和可靠,成为真正的“火眼金睛”。
作者:叶韵、张爱喜
叶韵:美国亚利桑那州立大学(Arizona State University)电机系博士,京东 AI 与大数据部资深算法工程师。研究兴趣包括 CNN 可视化和可解释性,生成式模型等。负责悟空鉴黄系统、图书入库封面比对、多模态资讯推荐及部分摄像头/监控相关项目。
张爱喜:香港科技大学研究型硕士(MPhil),京东 AI 与大数据部算法工程师。研究兴趣包括生成式模型、身份再识别和强化学习等。作为主力参与多模态资讯商品推荐,悟空鉴黄系统和店铺科技相关等项目。
编辑:陶家龙、孙淑娟
来源:JDTech微信公众号

精彩文章推荐:


