![]()
【新智元导读】Facebook人工智能实验室何恺明团队提出一种高效、高质量的目标和场景图像分割新方法。他们开发了一个独特的视角,将图像分割视为一个渲染问题,提出PointRend神经网络模块。建立在现有的最先进的模型之上,PointRend可以灵活地应用于实例分割和语义分割任务。
Facebook人工智能实验室Alexander Kirillov、吴育昕、何恺明、Ross Girshick等研究人员近日发表新论文,提出一种高效、高质量的目标和场景图像分割新方法。
通过将有效渲染的经典计算机图形学方法与像素标记任务中遇到的过采样和欠采样问题进行类比,他们开发了一个独特的视角,
将图像分割视为一个渲染问题
。
从这个角度出发,他们提出
PointRend (Point-based Rendering)神经网络模块
:该模块基于迭代细分算法,在自适应选择的位置执行基于点的分割预测。
建立在现有的最先进的模型之上,PointRend可以灵活地应用于实例分割和语义分割任务。
何恺明等人的研究表明,这个简单的设计已经取得了出色的结果。在定性上,PointRend输出清晰的对象边界,而先前的方法会出现过度平滑。在定量上,无论是实例分割还是语义分割,PointRend在COCO和Cityscapes两个数据集都获得了显著的结果。
图像分割任务涉及将在规则网格上采样的像素映射到同一网格上的标签映射或一组标签映射。在语义分割的情况下,标签映射表示每个像素处的预测类别。在实例分割的情况下,针对每个检测到的对象预测一个二元的前景和背景图。用于图像分割任务的现代工具是建立在卷积神经网络(CNN)上的。
用于图像分割的CNN通常在规则网格(regular grids)上操作:输入图像是由像素组成的规则网格,它们的隐藏表示是规则网格上的特征向量,它们的输出是规则网格上的标签映射。
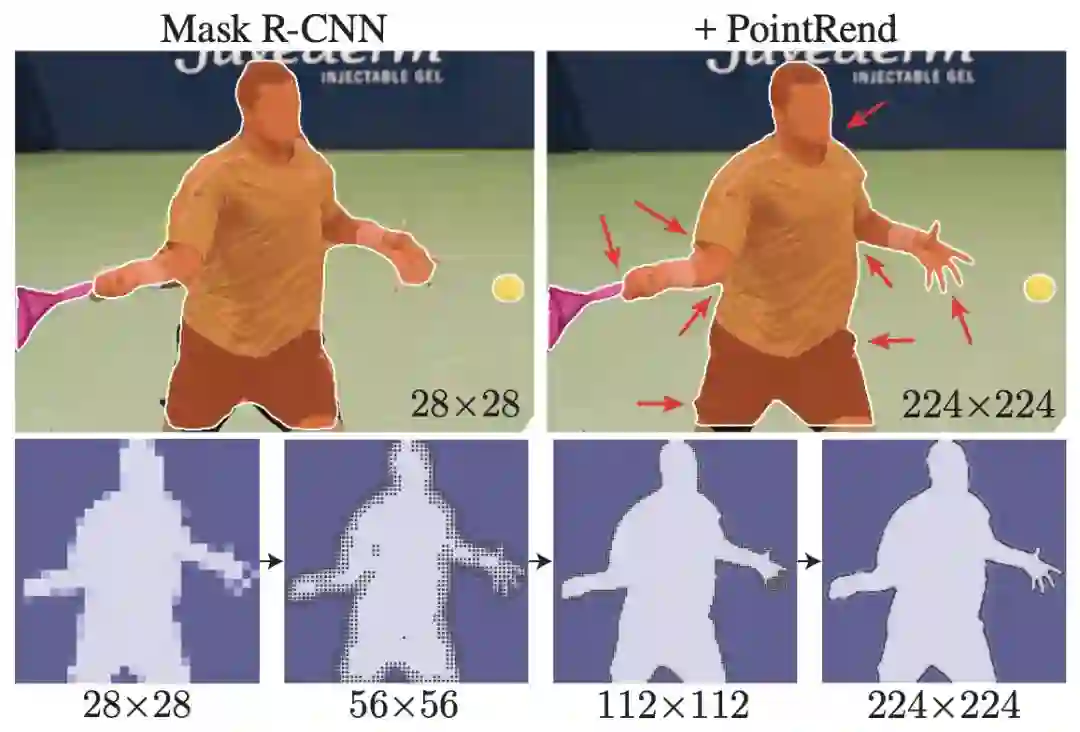
规则网格很方便,但不一定是理想的图像分割计算。这些网络所预测的标签映射应该基本上是平滑的,即由于高频区域被限制在对象之间的稀疏边界上,因此相邻像素常常采用相同的标签。一个规则的网格会不必要地对平滑区域进行过采样,同时对对象边界进行欠采样。结果导致在平滑区域和模糊轮廓上进行了多余的计算(图1,左上角)。图像分割方法在低分辨率规则网格上预测标签,例如输入的1/8用于语义分割,或28×28用于实例分割,作为欠采样和过采样之间的折衷。
![]()
图1:PointRend的实例分割。我们引入了PointRend(基于点的渲染)模块,该模块使用一种新的基于点的特征表示对图像上的自适应采样点进行预测。当使用PointRend替换Mask R-CNN的默认Mask head(左上)时,会产生更精细的结果(右上)。
类似的采样问题在计算机图形学中已经研究几十年了。例如,一个渲染器将一个模型(例如,一个3D网格)映射到一个栅格化的图像,即一个规则的像素网格。当输出在规则网格上时,计算并不是均匀地分配到网格上的。相反,一种常见的图形策略是计算图像平面上自适应选择点的不规则子集上的像素值。以Turner Whitted提出的经典subdivision技术为例,生成一个类似四叉树的采样模式,该模式可以有效地渲染一个抗锯齿的高分辨率图像。
本研究的中心思想是
将图像分割看作一个渲染问题,并采用计算机图形学中的经典思想来有效地“渲染”高质量的标签图
(见图1,左下)。我们基于这个计算思想提出一个新的神经网络模块,称为PointRend,它使用subdivision策略自适应地选择一组非均匀的点来计算标签。
PointRend可以被合并到流行的元架构中,用于实例分割(如Mask R-CNN)和语义分割(如FCN)。它的subdivision策略使用的浮点运算比直接的密集计算要少一个数量级,从而可以有效地计算高分辨率分割图。
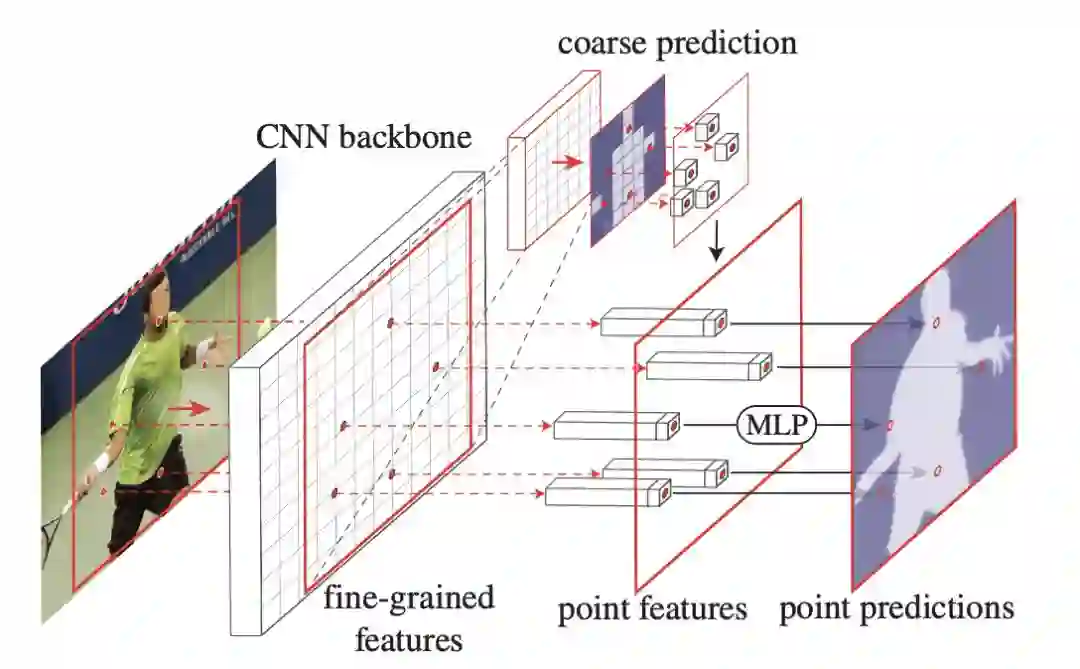
PointRend是一个通用模块,允许多种可能的实现。从抽象的角度来看,PointRend模块接受一个或多个定义在常规网格上的典型CNN特征图
![]() ,并在一个更细的网格上输出高分辨率预测
,并在一个更细的网格上输出高分辨率预测
![]() 。与对输出网格上的所有点进行过度预测不同,PointRend只对精心选择的点进行预测。为了进行这些预测,它通过对f进行插值来提取所选点的点向特征表示,并使用一个小的point head子网络来预测点向特征的输出标签。
我们将介绍一个简单而有效的PointRend实现。
。与对输出网格上的所有点进行过度预测不同,PointRend只对精心选择的点进行预测。为了进行这些预测,它通过对f进行插值来提取所选点的点向特征表示,并使用一个小的point head子网络来预测点向特征的输出标签。
我们将介绍一个简单而有效的PointRend实现。
我们使用COCO和Cityscapes基准来评估PointRend在实例分割和语义分割任务上的性能。定性地说,PointRend可以有效地计算出对象之间的边界,如图2和图8所示。
我们也观察到定量上的改进。PointRend显著改进了Mask RCNN和DeepLabV3模型。
图2:使用带标准mask head的Mask R-CNN(左)与使用带PointRend的Mask R-CNN(右)的示例结果对比。可以看到,PointRend以更精细的细节来预测masks。
方法:用于推理和训练的Point Selection
PointRend架构可以应用于实例分割(如Mask R-CNN)和语义分割(如FCNs)任务。对于实例分割,对每个区域应用PointRend。它通过对一组选定的点进行预测,从粗到精地计算mask(如图3所示)。对于语义分割,可以将整个图像视为一个区域。
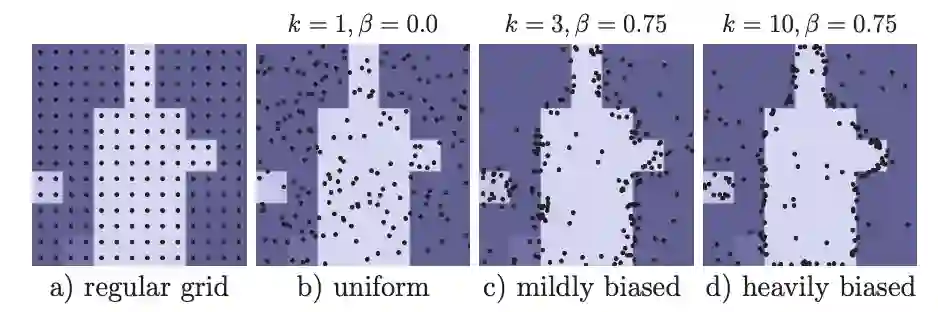
该方法的核心思想是在图像平面中灵活、自适应地选择点(points)来预测分割标签。直观上,这些点应该更密集地位于高频区域附近,例如对象边界,类似于光线追踪中的抗锯齿问题(anti-aliasing,也译为边缘柔化、消除混叠等)。我们推理和训练阶段应用了这一想法。
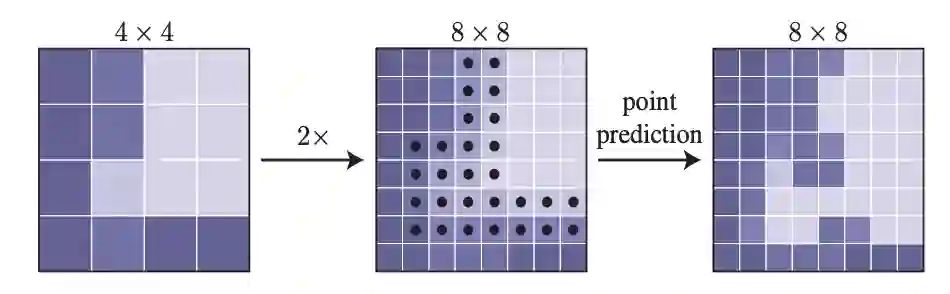
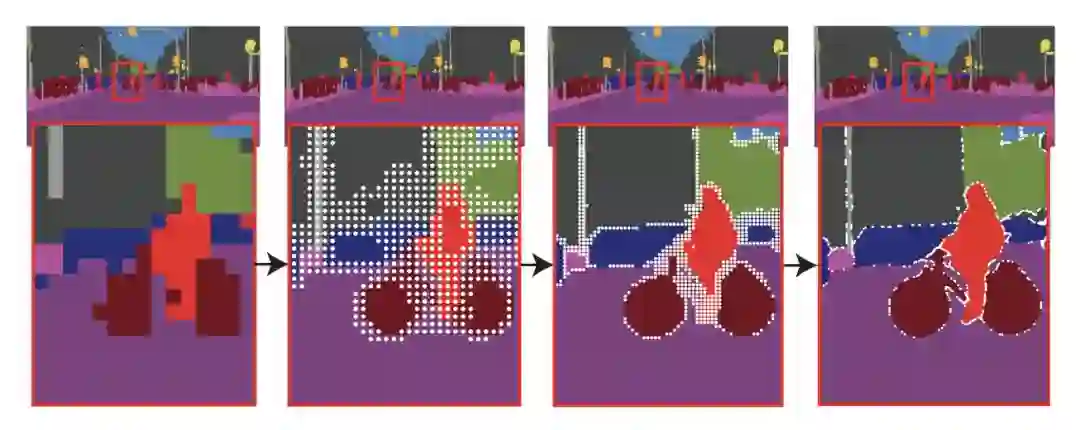
我们的推理选择策略是受到计算机图形学中经典的自适应细分技术(adaptive subdivision)的启发。该技术被用来有效地渲染高分辨率的图像(例如,通过光线追踪),只计算在该值与相邻值有显著差异的位置;对于所有其他位置,通过对已计算的输出值(从粗网格开始)进行插值来获得值。
图4:一个自适应细分步骤的示例。采用双线性插值的方法对4×4网格的预测进行2×上采样。然后,PointRend对N个最模糊的点(黑点)进行预测,以恢复更精细网格上的细节。重复此过程,直到达到所需的网格分辨率。
在训练期间,PointRend还需要选择训练点来构造 point-wise features,以训练point head。原则上,点的选择策略可以类似于推理中使用的细分策略。但是, subdivision 引入了顺序步骤,这对使用反向传播训练的神经网络不太友好。相反,对于训练,我们使用基于随机采样的非迭代策略。
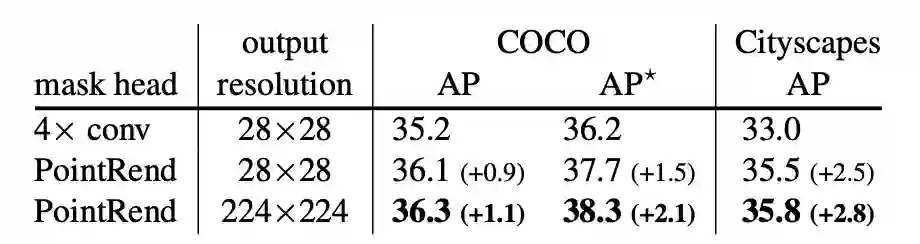
我们将PointRend与表1中Mask R-CNN中默认的4×conv head进行比较。
表1:PointRend与Mask R-CNN的默认4×conv mask head的对比。PointRend在数量和质量上都优于标准的4×conv mask head。
PointRend在两个数据集上的性能都优于默认的head。即使输出分辨率相同,PointRend的性能也优于baseline。从直观上看,边界质量也差异明显,如图6所示。
图6:具有不同输出分辨率的PointRend推理。高分辨率 masks 与对象边界更好地对齐了。
细分推理允许PointRend产生高分辨率的224×224预测,使用的计算(FLOPs)和内存是默认的4×conv head输出相同分辨率所需的30倍以上,见表2。
表2:224×224输出分辨率mask的FLOP(multiply-adds)和激活计数。
PointRend通过忽略一个对象的某些区域(例如,远离对象边界的区域)来实现Mask R-CNN框架下的高分辨率输出。
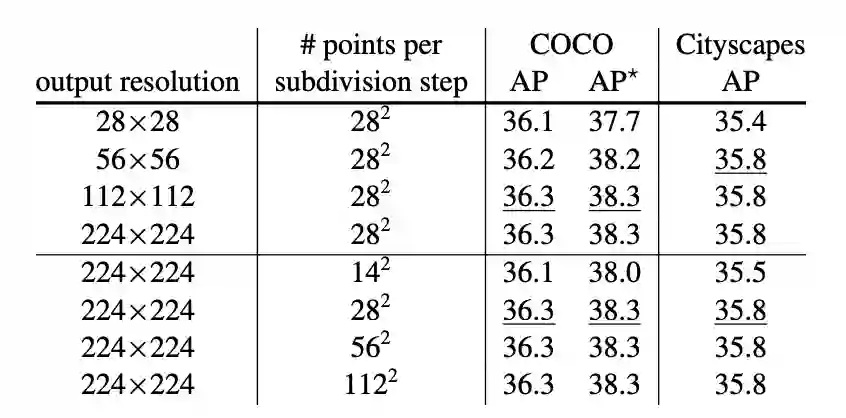
表3显示了不同输出分辨率和在每个细分步骤中选择的点数的PointRend细分推断。以更高的分辨率预测掩模可以改进结果。虽然AP饱和,但从较低(如56×56)分辨率输出到较高(如224×224)分辨率输出时,视觉效果仍有明显改善,见图7。
表3:细分推理参数。更高的输出分辨率提高了AP。虽然随着每个细分步骤中采样点的数量的增加,改进会很快达到饱和(在下划线处的值),但对于复杂的对象,定性结果可能会继续改进。
DeeplabV3。
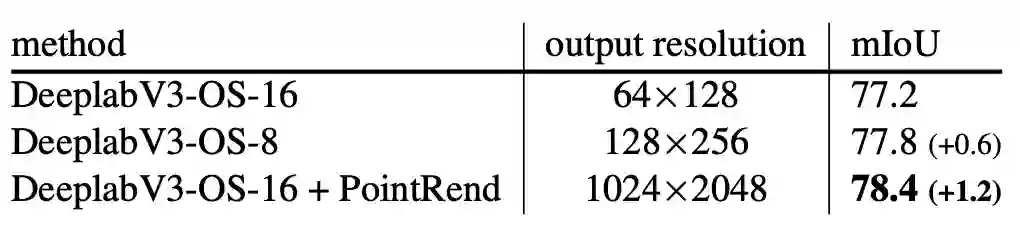
在表6中,我们将DeepLabV3与带有PointRend的DeepLabV3进行了比较。通过使用res4阶段的扩展卷积,推理阶段输出分辨率也可以提高2倍。相比两者,PointRend具有更高的mIoU。定性改进也很明显,见图8。
表6:在Cityscapes数据集,带有PointRend的DeeplabV3语义分割的性能优于基线DeepLabV3。在推理过程中对res4阶段进行扩展会产生更大,更准确的预测,但计算和存储成本要高得多。仍然不如使用PointRend。
图8:Cityscapes上的实例分割和语义分割结果。在实例分割中,较大的对象更容易从PointRend能力中获得高分辨率的输出。而在语义分割方面,PointRend可以恢复小的对象和细节。
通过自适应采样点,仅对32k点进行预测, PointRend可以达到1024×2048分辨率(即2M点),如图9所示。
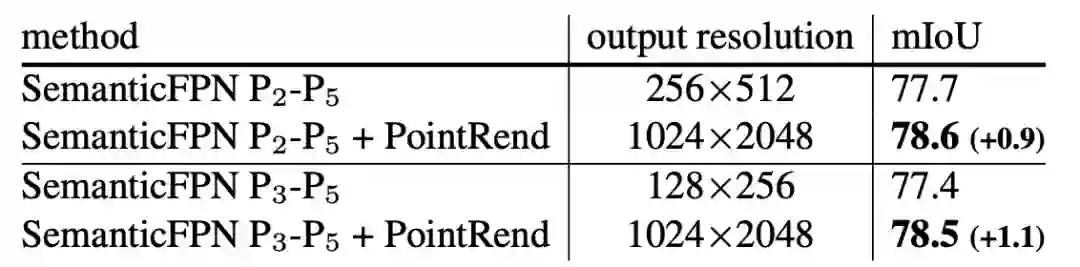
SemanticFPN。表7显示,具有PointRend的SemanticFPN优于没有PointRend的8×和4×输出步长变体。
表7:Cityscapes中,带有PointRend的SemanticFPN语义分割性能优于基线SemanticFPN。
参考链接:
https://arxiv.org/abs/1912.08193
https://www.zhuanzhi.ai/paper/b2a9c9f97c420a5dfa9cc855b6e52951
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取5000+AI主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!
点击“阅读原文”,了解使用专知,查看5000+AI主题知识资料


 ,并在一个更细的网格上输出高分辨率预测
,并在一个更细的网格上输出高分辨率预测
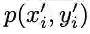 。与对输出网格上的所有点进行过度预测不同,PointRend只对精心选择的点进行预测。为了进行这些预测,它通过对f进行插值来提取所选点的点向特征表示,并使用一个小的point head子网络来预测点向特征的输出标签。
。与对输出网格上的所有点进行过度预测不同,PointRend只对精心选择的点进行预测。为了进行这些预测,它通过对f进行插值来提取所选点的点向特征表示,并使用一个小的point head子网络来预测点向特征的输出标签。