不需要借助GPU的力量,用树莓派也能实时训练agent玩Atari
机器之心报道
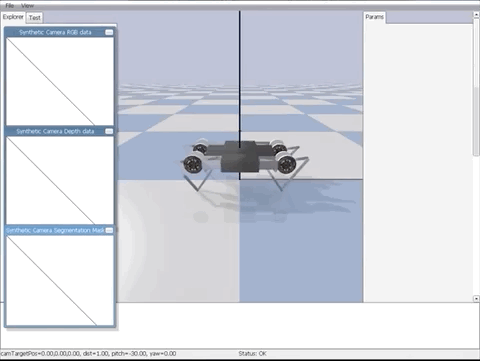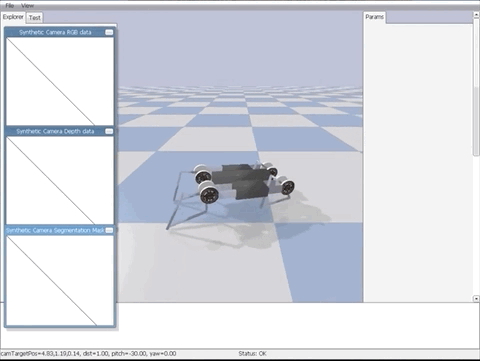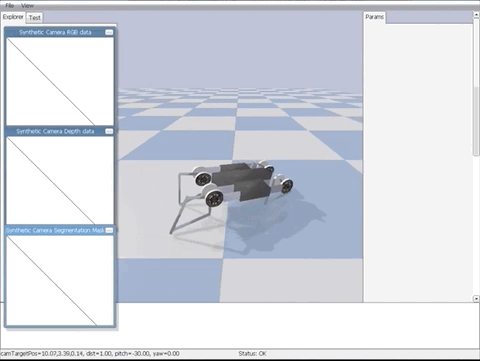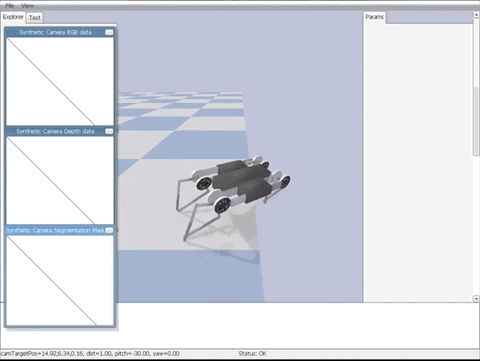
还是熟悉的树莓派!训练 RL agent 打 Atari 不再需要 GPU 集群,这个项目让你在边缘设备上也能进行实时训练。



!git clone https://github.com/ogmacorp/OgmaNeo2.git
import os
os.chdir('OgmaNeo2')
!mkdir build
os.chdir('build')
!cmake .. -DBUILD_SHARED_LIBS=ON
!make
!make install
!apt-get install swig3.0
os.chdir('/content')
!git clone https://github.com/ogmacorp/PyOgmaNeo2
os.chdir('PyOgmaNeo2')
!python3 setup.py install --user
import numpy as np
import pyogmaneo
import matplotlib.pyplot as plt
# Set the number of threads
pyogmaneo.ComputeSystem.setNumThreads(4)
# Create the compute system
cs = pyogmaneo.ComputeSystem()
# This defines the resolution of the input encoding - we are using a simple single column that represents a bounded scalar through a one-hot encoding. This value is the number of "bins"
inputColumnSize = 64
# The bounds of the scalar we are encoding (low, high)
bounds = (-1.0, 1.0)
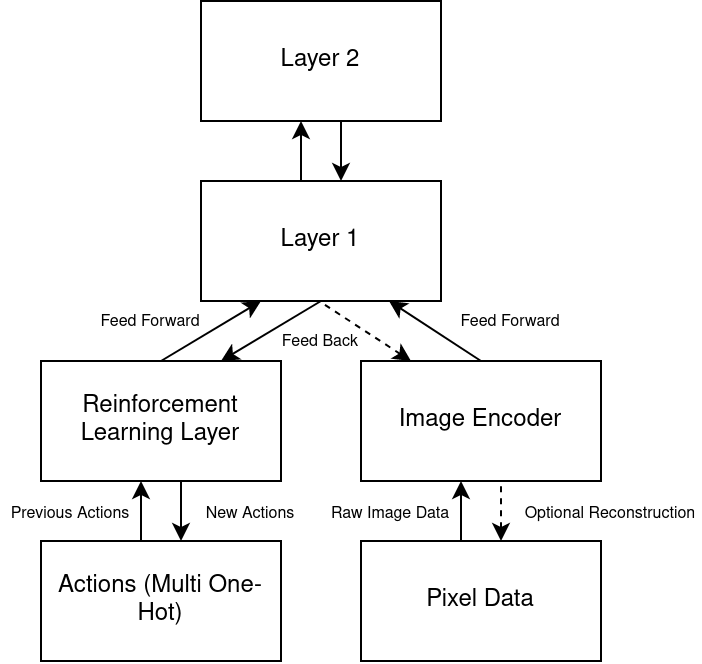
# Define layer descriptors: Parameters of each layer upon creation
lds = []
for i in range(5): # Layers with exponential memory
ld = pyogmaneo.LayerDesc()
# Set the hidden (encoder) layer size: width x height x columnSize
ld.hiddenSize = pyogmaneo.Int3(4, 4, 16)
ld.ffRadius = 2 # Sparse coder radius onto visible layers
ld.pRadius = 2 # Predictor radius onto sparse coder hidden layer (and feed back)
ld.ticksPerUpdate = 2 # How many ticks before a layer updates (compared to previous layer) - clock speed for exponential memory
ld.temporalHorizon = 2 # Memory horizon of the layer. Must be greater or equal to ticksPerUpdate, usually equal (minimum required)
lds.append(ld)
# Create the hierarchy: Provided with input layer sizes (a single column in this case), and input types (a single predicted layer)
h = pyogmaneo.Hierarchy(cs, [ pyogmaneo.Int3(1, 1, inputColumnSize) ], [ pyogmaneo.inputTypePrediction ], lds)
# Present the wave sequence for some timesteps
iters = 2000
for t in range(iters):
# The value to encode into the input column
valueToEncode = np.sin(t * 0.02 * 2.0 * np.pi) * np.sin(t * 0.035 * 2.0 * np.pi + 0.45) # Some wavy line
valueToEncodeBinned = int((valueToEncode - bounds[0]) / (bounds[1] - bounds[0]) * (inputColumnSize - 1) + 0.5)
# Step the hierarchy given the inputs (just one here)
h.step(cs, [ [ valueToEncodeBinned ] ], True) # True for enabling learning
# Print progress
if t % 100 == 0:
print(t)
# Recall the sequence
ts = [] # Time step
vs = [] # Predicted value
trgs = [] # True value
for t2 in range(300):
t = t2 + iters # Continue where previous sequence left off
# New, continued value for comparison to what the hierarchy predicts
valueToEncode = np.sin(t * 0.02 * 2.0 * np.pi) * np.sin(t * 0.035 * 2.0 * np.pi + 0.45) # Some wavy line
# Bin the value into the column and write into the input buffer. We are simply rounding to the nearest integer location to "bin" the scalar into the column
valueToEncodeBinned = int((valueToEncode - bounds[0]) / (bounds[1] - bounds[0]) * (inputColumnSize - 1) + 0.5)
# Run off of own predictions with learning disabled
h.step(cs, [ [ valueToEncodeBinned ] ], False) # Learning disabled
predIndex = h.getPredictionCs(0)[0] # First (only in this case) input layer prediction
# Decode value (de-bin)
value = predIndex / float(inputColumnSize - 1) * (bounds[1] - bounds[0]) + bounds[0]
# Append to plot data
ts.append(t2)
vs.append(value)
trgs.append(valueToEncode)
# Show predicted value
print(value)
# Show plot
plt.plot(ts, vs, ts, trgs)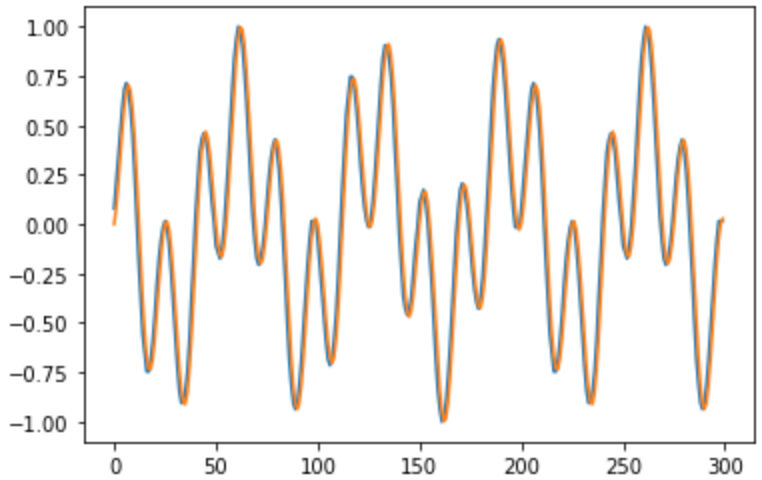
登录查看更多
相关内容
专知会员服务
87+阅读 · 2019年11月24日
专知会员服务
34+阅读 · 2019年3月21日
Arxiv
5+阅读 · 2020年4月2日
Arxiv
3+阅读 · 2018年9月27日



相关VIP内容
专知会员服务
87+阅读 · 2019年11月24日
专知会员服务
34+阅读 · 2019年3月21日
相关资讯
相关论文
Arxiv
5+阅读 · 2020年4月2日
Arxiv
3+阅读 · 2018年9月27日