有人要为ML定制编程语言,你的Python白学了?

任何机器学习系统复杂到一定程度之后,都会包含一个临时开发的、不合规范的、充满 Bug 的、运行速度很慢的、只有一半功能的 Common Lisp 实现 [1]。
—— 格林潘思第十定律
格林潘思第十定律告诉我们,机器学习发展得越完善,现有的编程语言就会越暴露出与之不协调的缺陷。那么,我们是应该在原有语言的基础上进行改进完善,还是专门为之设计一套语言来得更彻底一些呢?诚然,重新开创一种语言成本很高,但是考虑到机器学习在未来的广阔应用前景,为其在编程语言上花些功夫,磨刀不误砍柴工,未尝不是一个好的办法。如果这种语言真的被创建出来,你辛辛苦苦学的 Python 不是白学了?
更多干货文章请关微信公众号“AI 前线”,(ID:ai-front)
随着机器学习(ML)的发展,作为编程语言(PL)学习者和从业者,我们非常关注 ML 模型的复杂性,以及其建模框架的复杂性。最先进的模型看起来越来越象是程序,并开始支持诸如循环和递归等编程构造,引发了很多关于我们用来创建模型所用的工具,也就是编程语言,开始遇到很多有趣的问题。
虽然现在机器学习还没有一门专用语言,但是有人正在尝试通过 Python API 创造一种新语言(如 TensorFlow),而另外一些人将 Python 用作建模语言(如 PyTorch)。问题是,我们是否有必要为 ML 量身定制一套语言?如果是,原因何在?更重要的是,未来理想化的 ML 语言应该是什么样的?
即使是时下被有些人称为人工智能时代最好的语言——Python,也有一些不可忽视的缺陷:由于 Python 是动态语言,它的执行效率不如 Java;而且 Python 是弱类型语言,编译时需要逐个 check 类型,所消耗的时间很多,速度较慢。另外,与 Java 应用可以在任何可以运行 Java 虚拟机的电脑或者移动设备上运行相比,不管在哪里运行 Python 的程序都需要一个编译器来将 Python 代码转化为特定的操作系统可理解的代码,这一点 Python 的缺陷就更明显了。
因为 ML 模型开始需要编程语言的全部功能,Chainer 等人开始倡导一种“运行时定义(Define-by-run)”的方法,这种方法会将 Python 程序本身用作模型,并通过运行时自动微分(Automatic Differentiation,AD)的方式实现衍生。从可用性的角度来看,这非常难得:如果你想要创建一个在表达树上运行的递归模型,只需把它写下来,剩下的交给 AD 来做就行了!这样做的效果甚至难以用语言来描述,通过这种简洁顺畅的方式尝试各种新颖的想法,也为研究工作贡献了巨大的价值。
然而,让 Python 扩展到满足 ML 所需的庞大计算需求的规模,远比你想象的要困难得多。大量的工作消耗在复制优化的过程中,而 PL 的性能被高估,它根本不能让 Python 的速度快很多。 Python 的语义也使得这个语言难以进行模型级并行运算,或为小型设备提供编译模型。
MXNet、Gluon 等至少在某种程度上正在设法将两种方式的优势结合在一起,朝着这个目标方向努力。这个想法是将基本的动态 AD 与代码追踪方法结合在一起,获得可优化的“静态子图(Static sub-graph)”。然而,这就是一个不相干 API 大杂烩的方法,效果有限 ; MXNet 不仅将它的图形用于内核级别的优化,而且还用于高级图形调度,例如将模型分散到多个 GPU 上。这种“杂合”的方法如何解决这类问题还不明确,除非为节点可以进行动态计算的图容器添加另一个新的 API。
尽管有着诸多局限,TensorFlow(TF)和其同族技术 [2] 已经成为时下最流行编程语言之一。这种说法可能会让很多人吃惊,但毕竟人们会使用 Python 进行 TF 编程。但是,TF 需要编写 Python 代码,使用内部语言构建表达式树,随后进行评估。
实际上,我们可以用任何语言以“取巧”的方式进行类似 TensorFlow 那样的编程。例如下列 JavaScript 代码,就用这种方式实现了一个 Trivial 函数(add):

此时我们是在进行元编程(Metaprogramming) -——编写用来写代码的代码。在这种情况下,元语言和目标语言相同(JavaScript),但它们也可以是不同的语言(如 C 语言的 C 预处理器),或者可以使用数据结构(一个 AST)来代替字符串(原理不变)。在 TensorFlow 中,Python 可以作为用 TF 编写的图语言(Graph-based language)所用的元语言 [3]。TensorFlow 的图表甚至支持 Variable scoping 和 Control flow 等构造,我们可以通过 API,而不是 Python 语法操纵这些结构。
TensorFlow 和类似的工具以“纯粹的库”的形式存在,但它们实际上非常罕见。因为大多数库只是提供一套简单的函数和数据结构,而不是一个全新的编程系统和运行时。那我们为什么要用这么复杂的方法?
构建新语言的核心原因很简单:ML 研究对计算的要求极高,简化建模语言使得添加特征和特征领域优化变得更加容易。训练模型需要大量的硬件支持、足够好的训练数据、较低的解释器开销,还要处理各种类型的并行问题。Python 这样的通用语言可以达到这些要求,TensorFlow 也可以无缝完成。
不过我们还会遇到其他困难。因为这种优化依赖于简化假设(ML 模型不能递归,或者需要自定义梯度,对吧?),因此我们可以更容易地进行优化,或部署到小型设备上。但对于工程师来说,模型的复杂性已经增加了,而研究人员也乐于违反这些假设。现在,模型需要条件分支(已经可以足够轻松地操作了)、重复循环(不太容易,但有可能),甚至是表达树递归(几乎不可能实现)。在 ML 的很多领域,包括神经网络和概率规划(Probabilistic programming,模型正变得越来越像程序,其中包括对其他程序进行推理的程序(例如程序生成器和解释程序),以及包含一些不可微分的组件,诸如蒙特卡洛树搜索(Monte Carlo Tree Search)。构建一个具有灵活性的同时,又能实现最佳性能的运行时非常具有挑战性,但越来越多功能强大的模型需要做到这两点。
(为机器学习使用复杂的树结构数据,例如 Stanford Sentiment Treebank,需要使用可微分的递归算法。)
这种方法暴露的另一个缺点,至少在目前的版本中,是需要使用上述元编程,而且构建和评估表达式树会给程序员和编译器带来额外的负担。因为代码现在有两个执行时间,每个执行时间都有不同的语言语义,单步调试以排除故障等因素,所以推理会变得非常棘手。这可以通过为新运行时创建一种句法语言(Syntactic language)来解决,但这意味着需创建一个全新的编程语言。但是我们有很多数值语言(Numerical language)可用,这么做是否值得呢?
很少有哪个领域像机器学习一样对语言级设计的问题要求如此之多。但是这也并非首例,在形式推理和验证、集群计算等领域,量身定制全新语言已经被证明是一个有效的解决方案。同样,我们也希望能看到针对 ML 领域数值的、可微分、可并行,甚至是概率性的计算要求产生新的语言,或让现有语言据此进行优化和完善。
ML 语言目前面临的一个较大的挑战,是如何在性能方面实现通用性,而早期的混合方法则有待完善。我们预计,未来的 ML 运行时可以支持任意的混合方法(计算图动中有静,静中有动......),并且需要能够更好地编译动态代码。理想情况下,只需要一个灵活的“图形格式”(或 AST)就够了,这样的 AST 应该有自己的语法,并且能以静态描述动态行为(例如可以写一个“for” 循环)。换句话说,它应该看起来更像一个标准的编程语言。
此外,这个可编程语义(Programmable semantic)的灵活性应该达到新的水平,并且可以通过类似于宏的特征来实现。通过指定代码应该具有纯数据流语义的位置(而不需要使用标准的命令式(Imperative),标准命令语义虽然更灵活,但可能会产生优化不安全的副作用),实现在核心系统之上构建多 GPU 训练等类似功能。它还可以执行概率编程语言所需的各种程序操作,或者 NLP 模型中通常需要手动添加 Vectorisation(批处理)传递。
与 PL 社区一样,ML 工程师也应该密切关注传统的自动微分(AD)社区。ML 的“定制”款语言也许可以从为真正的一流派生物而设计的语言中获得灵感。在不降低性能的前提下,这样的语言可以轻松地将符号与运行时技术结合在一起,混合正向和反向模式 AD(用于改进性能和内存使用),并且区分 GPU 内核 。
ML 研究将越来越需要更强大、用户定义类型和更多扩展方式的系统。用 NVIDIA®(英伟达™)GPU(图形处理器)Strided 数组提供硬编码支持就已经足够的时代已经过去了;稀疏机器学习(Sparse)等前端技术,TPU、Nervana 和 FPGA 等新硬件,以及 ARM 芯片或 iPhone 的 CoreML 芯片等多样化的部署目标,都需要更高的灵活性。
想象一下,在未来,用户可以很轻松地通过高级代码添加新的硬件支持(或新的数据表示类型),而不需要改变原来的系统。我们预测,ML 系统将从现有的数字计算语言中获得灵感,因为这类语言已经可以轻松地完成此类任务。
类型系统具有安全上的优势,但是当前的类型系统不适合包含大量大数组,并且数组维度有一定意义的代码(例如,图像中的空间、通道,以及批量维度)。这些差异完全出于习惯,而“潦草”的维度变换代码根本无法预防出错,这也导致我们需要更多可感知数组的类型系统。希望动态类型的发展势头能够继续,[4] 这主要是由于编码从业者偏好交互性和脚本,但我们希望能够看到更多的创新,如 CNTK 的可选动态维度等创新。
现在,ML 工程师对传统的软件工程问题越来越感兴趣,比如维护和扩展生产系统。ML 编程模型使得在组件之间创建抽象壁垒和接口更加困难,并且对模型的重新训练会很容易破坏向后兼容性。ML 语言将可能和常规语言一样,把这些问题的解决方案结合起来,但这仍然是一个围绕 shejiu 的开放问题。

(软件工程 2.0?XKCD)
图中对话,从上到下依次为:
这就是你的机器学习系统?
没错!把你的数据倾倒给这一大堆线性代数组成的东西,然后就可以在另一头收集答案了。
如果答案错误怎么办?
那就不停搅拌吧,直到获得看似正确的结果。
所有的新语言都有一个缺点,就是它需要一个新的数据库系统,因为只有为新运行时编写的代码才能从中获益。例如,如果不重复使用 Python,TensorFlow 开发人员就需要用图语言为文件 IO 等任务重新编写数据库,比如他们为 SciPy 等项目所做的大量工作全部白费。虽然这可能是唯一的方法,但 ML 从业者不应该脱离广博的数值型和 HPC 计算社区。一个理想的 ML 生态系统应该是一个数值型社区,反之亦然,这些社区之间的结合将把每个人的努力事半功倍。
我们预期,ML 在以下各方面将会有较大的进步。图形 IR 和 XLA、ONNX、NNVM 等格式将变得越来越复杂,它们可能从传统的语言设计中获得更多启发 [5],甚至通过增加表层语法(Surface syntax)发展成完全成熟的编程语言。TensorFlow 的 XLA 已经开始向专用编译器堆栈的方向发展,目前包括 TVM、DLVM、myelin 和其他正在进行的工程。同时,PyTorch JIT、Gluon 和 Tangent 正在排除万难,让 Python 本身可以成为更优秀的建模语言,不过这一过程还将面临很大的挑战。有人认为,ML 归根结底是一种数值编程语言问题,而 Julia 社区认为,ML 就是试验这些语言级别问题的理想土壤,并将继续推进 Knet、Flux、Cassette、CUDAnative、DataFlow.jl 等项目的进展。
2009 年左右,一群拥有各种语言丰富编程经验的 Matlab 高级用户,对现有计算编程工具感到不满——这些软件对自己专长的领域表现得非常棒,但在其它领域却非常糟糕,他们想要寻求一种能够满足他们所有要求的语言,于是他们开始创建一种全新的语言。这些人中有些是 Lisp 黑客,一些是 Python 狂热者,另外一些是 Ruby 主义者,还有一些是 Perl 黑客。用他们的话说,他们创造新语言的动因是因为他们“贪心”不足,想要创造出一种集复杂的编译器、分布式并行执行、数值准确性和广泛的数学函数库于一身的开源软件,它既要像 C 语言一般快速,同时也要拥有如同 Ruby 的动态性;要具有 Lisp 般真正的同像性(Homoiconicity)而又有 Matlab 般熟悉的数学记号;要像 Python 般通用、像 R 般在统计分析上得心应手、像 Perl 般自然地处理字符串、像 Matlab 般具有强大的线性代数运算能力、像 shell 般胶水语言的能力,易于学习而又不让真正的黑客感到无聊;还有,它应该是交互式的,同时又是编译型的。

(从左到右):Julia Computing 公司的几位联合创始人 Stefan Karpinski、Viral Shah、Jeff Bezanson、Alan Edelman、Deepak Vinchhi 和 Keno Fischer。于是,2009 年,Karpinski 与 Viral Shah、Alan Edelman 和 Jeff Bezanson 三人共同创办了 Julia 这个开源项目。由于市场反响极好,几位开发者联同 Deepak Vinchhi 和 Keno Fischer 在 2015 年创办了 Julia Computing 公司。Julia Computing 为客户提供收费的支持、培训和咨询服务,不过 Julia 本身仍可以免费使用。Julia 是 Jupyter 和 Julia 社区的合作项目,为 Julia 提供了一个强大的基于浏览器的图形化 notebook 界面,是一个面向数值计算(numerical computing)的高性能动态编程语言。其语法与其他科学计算语言相似,在许多情况下拥有能与编译型语言相媲美的性能。Julia 的基本库就主要用 Julia 语言编写的,并结合了成熟的开源 C 和用于线性代数、随机数生成、信号处理和字符串处理的公式翻译程式语言库(Fortran)。另外,Julia 开发者社区还正在通过 Julia 的内置包管理器提供一些外部包。
https://github.com/JuliaLang/julia
Julia Computing 联合创始人 Karpinski 说道:“Julia 是人工智能、机器学习、深度学习和并行计算这些应用的最佳选择,在印度的发展势头非常迅猛。”
此外,Julia 还用于美国航空航天局和劳伦斯伯克利国家实验室的研究,麻省理工学院也专门设有一个致力于研究和发展这种语言的 Julia 实验室,麻省理工学院林肯实验室的工程师们使用 Julia 来计算经过优化的逻辑表中的 65 亿个决策点,以便找出联邦航空管理局新的下一代飞机防撞系统的故障,以及用于为天空调查而设计的统计分析模型 Celeste 项目等,应用范围非常广阔。
既然 Julia 有这么多优点,按道理说应该有很多人用。实时上也是这样,虽然开源有限,但 Julia 变得越来越受欢迎,成了热门编程语言,Tiobe 排名也逐渐上升。最新数据显示,12 月,Julia 在编程语言中的排名为 Top47。
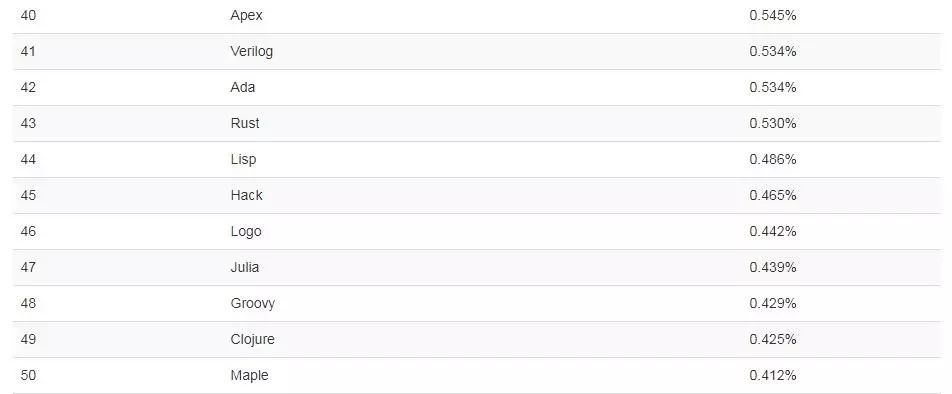
(Tiobe)
虽然与 C 语言、Python 等热门编程语言相比还是有很大差距,绘图接口及常用工具包缺失等问题也是阻止用户使用这种语言的原因,但用过 Julia 的编程人员认为,Julia 在速度和语言性能等方面具有优势,作为语言本身比 MATLAB 的脚本更为优雅有趣。
多派遣:提供跨多种参数类型组合定义函数行为的能力
动态类型系统:用于文件编制、优化和调度的类型系统
高性能,接近于静态编译型语言,如 C 语言,包括用户自定义类型等
有类似 Lisp 的宏以及其它元编程工具
调用 Python 函数:使用 Pycall 包
可直接调用 C 函数(不需要包装或是借助特殊的 API)
有类似 shell 的进程管理能力
为并行计算和分布式计算而设计
轻量级协程
调用许多其它成熟的高性能基础代码。如线性代数、随机数生成、快速傅里叶变换、字符串处理。(还在增加中……)
丰富的用于创建或描述对象的类型语法
用户自定义类型和内置函数一样快速简洁
优雅的可扩展的类型转换 / 提升
支持 Unicode,包括但不限于 UTF-8
MIT 许可:免费和开源
Julia 基于 LLVM 的即时(JIT)编译器结合语言的设计,使其性能接近 C 语言。为了让 Julia 能够像其他语言一样进行数值计算和科学计算,Julia 社区用多种语言编写了一套微型 benchmark 测试程序数值:C 语言、Fortran、Julia、Python、Matlab / Octave、R、JavaScript、Java、Lua、Mathematica。
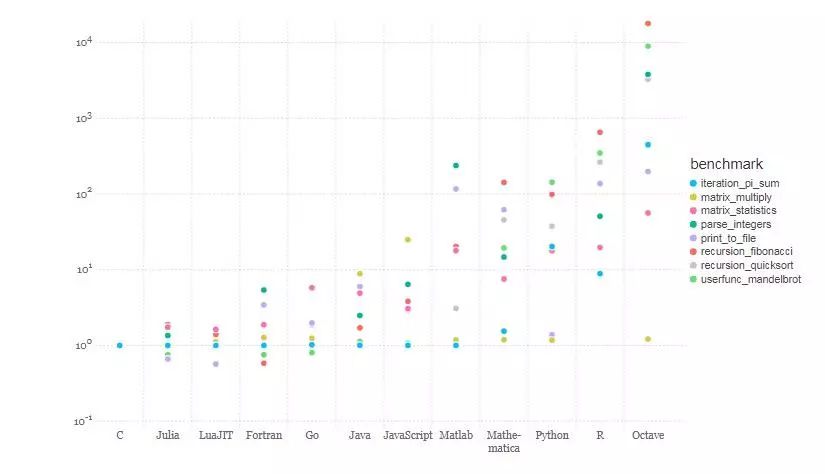
(图:相对于 C 语言的 benchmark 时间(越小越好,C 语言性能 = 1.0))
Julia 不会在用户上强加任何特殊的并行性。相反,它为分布式计算提供了许多关键的构建块,使其足够灵活以支持多种并行方式,并允许用户自主添加。下图示例演示了 Julia 如何计算大量并行投币实验中正面朝上的数量:

这个计算是自动分布在所有可用的计算节点上的,在调用节点处得出总和(+)减少的结果。
以下是使用基于网页的交互式 IJulia Notebook 会话截图,JuliaBox 提供了一种在浏览器上按需配置 Docker 沙盒容器来运行 IJulia notebook 的方法。
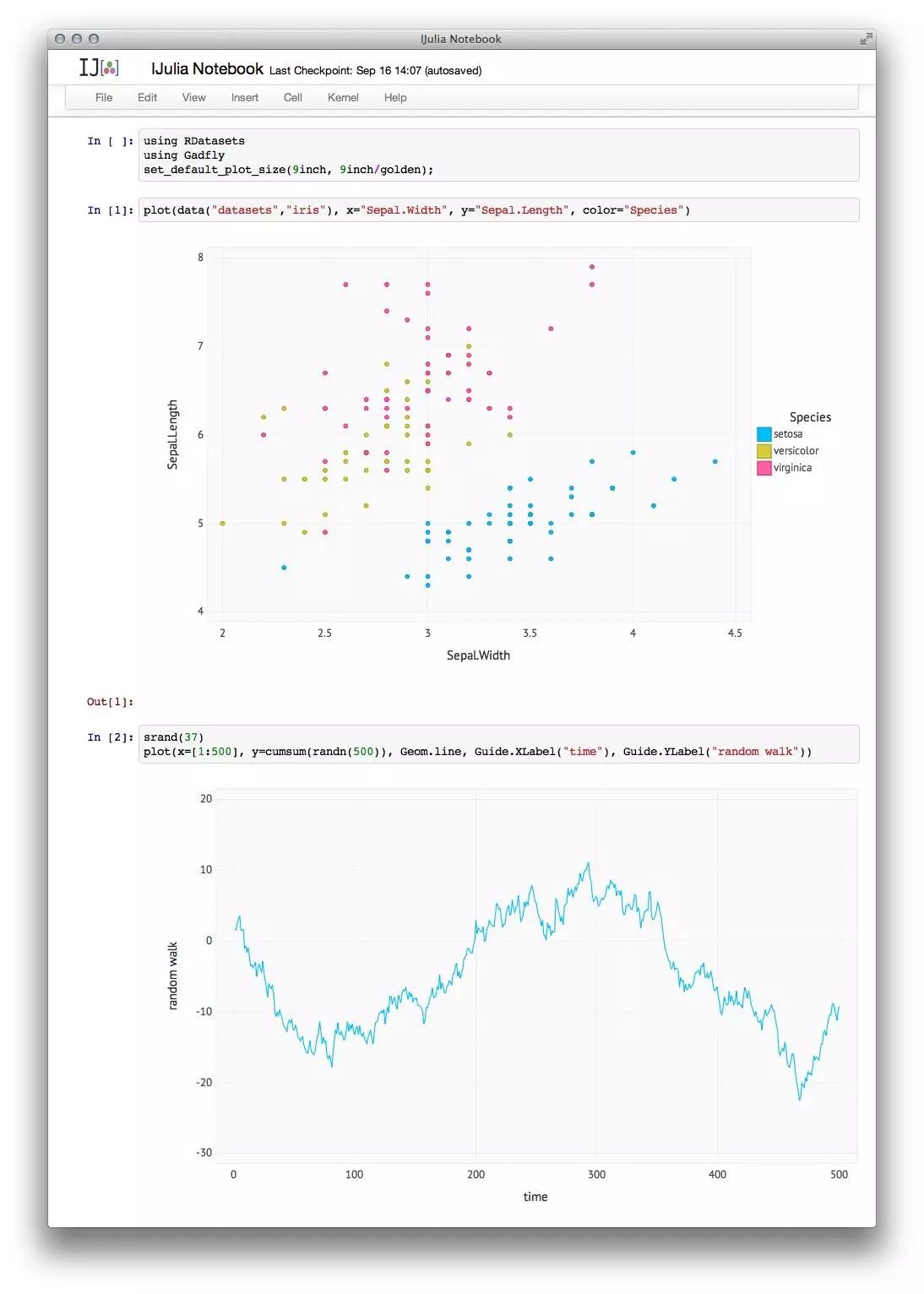
这为完全基于云的操作铺平了道路,包括数据管理、代码编辑和共享、执行、调试、协作、分析、数据探索和可视化。Julia 的最终目标是让人们不再担心管理机器和管理数据,而是直接解决现实问题。
Gadfly 可以在浏览器中生成各种渲染后端的图形(SVG、PDF、PNG 和其他各种后端)。我们可以通过为图形和图表添加 Interact.jl 包来增强交互性。下面介绍一下 Gadfly 的一小部分功能:
Julia 应用已经得到 MIT 的许可授权,其核心语言是免费开源的,Julia 环境使用的各种库包括本身的许可,例如 GPL、LGPL 和 BSD。该语言可以作为一个共享库使用,因此用户可以将 Julia 与他们自己的 C / Fortran 代码或专有的第三方库结合起来使用。此外,Juli 让在 C 和 Fortran 共享库中调用外部函数变得非常简单,无需编写任何包装代码,甚至不需要重新编译现有代码。
为了快速了解 Julia,以下是 Mandelbrot 和随机矩阵统计 benchmark 中使用的代码

机器学习模型已经成为构建更高层次和更复杂抽象的通用信息处理系统 ; 重现、递归、高阶模型,甚至堆栈机器((Stack machine))和语言解释器,所有这一切都是通过基本组件相互组合实现的。机器学习已成为一种全新编程范式,只不过因为其数值型、可微分、并行等特性而显得较为陌生。在所有工程领域,这种可用的工具都将对未来工作的范畴产生深远的影响。
所有这些都要求 ML 系统的设计人员面临着巨大的挑战。尽管如此,还是有一些激动人心的好消息:在过去的几十年中,即使没有被完全解决,语言研究人员已经对这些问题做了深入的研究。为了真正把这个新领域的潜力发挥到极致,机器学习和编程语言必须联合起来,而真正的挑战是如何将两者的专业知识整合在一起。
我们能否建立一套将数值、派生物和并行功能视为第一类特性的系统,而不牺牲传统的编程思想和智慧?这是未来十年,语言编程领域必须回答的基本问题。
[1] 援引格林潘思第十定律(Philip Greenspun)
[2] 此处使用 TensorFlow 作为例子,其实也可以替换为其他“运行前定义(Define-before-run)”的框架,例如 CNTK 或 MXNet。
[3] TensorFlow 的图实际上是一种基于数据流的 AST(抽象语法树)。
[4] 话虽如此,但从内部来说,目前的系统已横跨从完全动态(PyTorch 及其 Aten 后端)到非常静态(TensorFlow 的 XLA 和 MXNet,在图实际运行前所有维度都是已知的)的完整范围。
[5] Google Brain 正在招募编程语言专家,例如 Chris Lattner 目前正在从事相关开发。
文章来源:
https://julialang.org/blog/2017/12/ml&pl#fnref:tf
https://www.tiobe.com/tiobe-index/
https://julialang.org/blog/2012/02/why-we-created-julia
https://julialang.org/





