【CVPR2021】在类别不平衡的数据上施展半监督学习

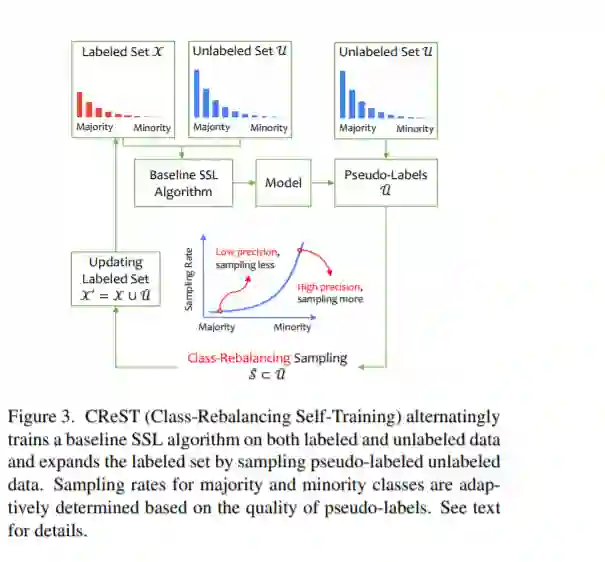
类不平衡数据的半监督学习虽然是一个现实的问题,但已经得到了研究。虽然现有的半监督学习(SSL)方法在少数类上表现不佳,但我们发现它们仍然在少数类上生成高精度的伪标签。通过利用这一特性,在这项工作中,我们提出了类再平衡自我训练(CReST),这是一个简单而有效的框架,用于改进现有的对类不平衡数据的SSL方法。CReST通过从一个未标记集中添加伪标记样本扩展了一个标记集,迭代地重新训练一个基线SSL模型,在该模型中,根据估计的类分布,从少数类中更频繁地选择伪标记样本。我们还提出了一种渐进式分布对齐,以适应调整CReST+的再平衡强度。我们展示了CReST和CReST+在各种类不平衡的数据集上改进了最先进的SSL算法,并始终优于其他流行的再平衡方法。
https://www.zhuanzhi.ai/paper/fdb3245caf8bded4d2ba340c2a9c64cc
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CREST” 就可以获取《【CVPR2021】在类别不平衡的数据上施展半监督学习》专知下载链接



登录查看更多
相关内容




相关VIP内容
相关资讯