综述 | 推荐系统偏差与去偏总结
作者:一元
转自:炼丹笔记
Bias and Debias in Recommender System: A Survey and Future Directions

论文:https://arxiv.org/pdf/2010.03240
合集:https://github.com/jiawei-chen/RecDebiasing

在实践中,做推荐系统的很多朋友思考的问题是如何对数据进行挖掘,大多数论文致力于开发机器学习模型来更好地拟合用户行为数据。然而,用户行为数据是观察性的,而不是实验性的。这里面带来了非常多的偏差,典型的有:选择偏差、位置偏差、曝光偏差和流行度偏差等。如果不考虑固有的偏差,盲目地对数据进行拟合,会导致很多严重的问题,如线下评价与在线指标的不一致,损害用户对推荐服务的满意度和信任度等,本篇文章对推荐系统中的Bias问题进行了调研并总结了推荐中的七种偏差类型及其定义和特点。详细的细节可以参考引文。
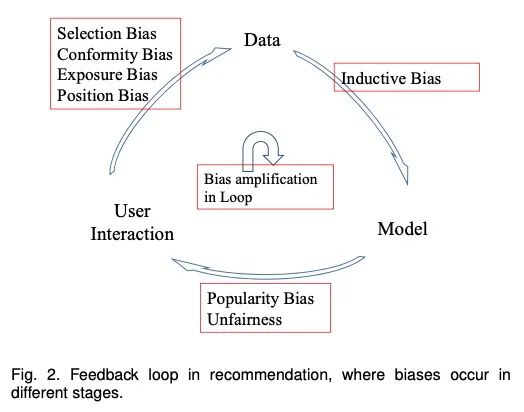
User -> Data
从用户处收集数据,包括用户和商品的交互以及其它的side信息(例如user profile,item attributes,上下文信息),我们将收集到的交互表示为用户集合
,商品集合
的反馈矩阵,一般会有两种不同的用户反馈。
-
隐式反馈: ,其中 表示用户 是否和商品 有交互,如果有交互则为1,否则为0; -
显式反馈: ,其中 表示用户 给商品 打的分(ratings);
Data -> Model
Model -> User
将推荐的结果返回给用户,以满足用户的信息需求。这一阶段将影响用户未来的行为和决策。
通过上面的循环,用户和推荐系统在交互的过程中,用户的行为通过推荐进行更新,这样土建系统可以通过利用更新的数据进行自我强化。
数据中的Bias
由于用户交互的数据是观察性的,而不是实验性的,因此很容易在数据中引入偏差。它们通常来自不同的数据分组,并使推荐模型捕捉到这些偏差,甚至对其进行缩放,从而导致系统性种族主义和次优决策。本文将数据偏差分为四类:外显反馈中的选择偏差和从众偏差,内隐反馈中的暴露偏差和位置偏差。
1. 显示反馈数据中的Bias
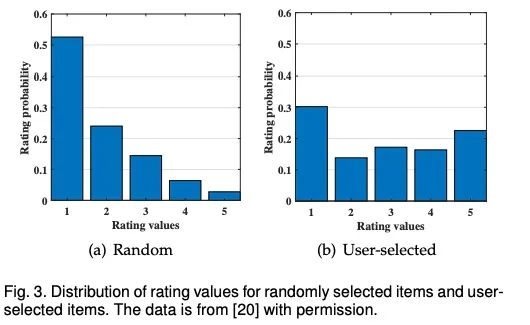
1.1 选择偏差(Selection Bias):当用户可以自由选择要评分的项目时,会出现选择偏差,因此观察到的评分并不是所有评分的代表性样本。换言之,评级数据往往是不随机缺失的(MNAR)。
在rating数据集上面, 用户并非是随机打分的.
-
用户会选择它们喜欢的商品进行打分; 用户更倾向于给特别好的商品和坏的商品打分;
1.2.一致性偏差(Conformity Bias):一致性偏差发生在用户倾向于与组中其他人的评分相似时,即使这样做违背了他们自己的判断,使得评分值并不总是表示用户真正的偏好。
这个最典型的例子就是:一个用户会受到诸多其它人的评分的影响,如果很多其他人都打了高分,他可能会改变自己的评分,避免过于严厉。这个问题主要是由于用户受社会影响导致,一个用户往往会受到他朋友的影响。所以我们观测到的评分是有偏的,有些是没法反映真实用户的喜好。
2. 隐式反馈数据的Bias
和显示反馈提供评分不一样,隐式反馈主要反映的是用户的自然行为, 例如购买,浏览,点击等。所以会有很多bias是从one-class的数据中带来的,例如曝光的bias和位置的bias等。
2.1.曝光Bias:暴露偏差的发生是因为用户只接触到特定项目的一部分,因此未观察到的交互并不总是代表消极偏好。
特殊地,用户和商品之间未被观察到的交互可以归因于两大原因:1)商品与用户兴趣不匹配;2)用户不知道该商品。因此,在解释未观察到的相互作用时会产生歧义。无法区分真正的消极互动(如暴露但不感兴趣)和潜在的积极互动(如未暴露)将导致严重的Bias。以前的研究已经调查了数据暴露的几个方面:
1)暴露受先前推荐系统的策略的影响,这些策略控制要显示哪些商品。
最近的一些工作也将这种“曝光偏差”(exposure bias)称为“前一模式偏差”(previous mode bias)。
2) 因为用户可以主动搜索和查找自己感兴趣的商品,这样会导致相关的商品更大概率的被曝光。在这种情况下,exposure bias也被称作为是selection bias;
3)用户的背景是商品曝光的另一个因素,例如社交朋友、他们所属的社区和地理位置等;
4)流行的商品有更大的概率被曝光(popularity bias)。我们认为流行度bias也是Exposure Bias的一种。
2.位置Bias:位置偏差是因为用户倾向于与位于推荐列表中较高位置的商品进行交互,而不管这些商品的实际相关性如何,因此交互的商品可能不是高度相关的;
模型中的Bias
模型中最典型的就是归纳Bias,
1.归纳偏差(Inductive Bias):归纳偏差是指模型为了更好地学习目标函数并将其推广到训练数据之外而做出的假设。
结果的Bias和Unfairness
1.流行度偏差(Popularity Bias):热门商品的推荐频率甚至超过了它们的受欢迎程度.
长尾现象在推荐数据中很常见:在大多数情况下,一小部分受欢迎的商品占了大多数用户交互的比例。当对这些长尾数据进行训练时,该模型通常会给热门项目的评分高于其理想值,而只是简单地将不受欢迎的商品预测为负值。因此,推荐热门商品的频率甚至比数据集中显示的原始受欢迎程度还要高。
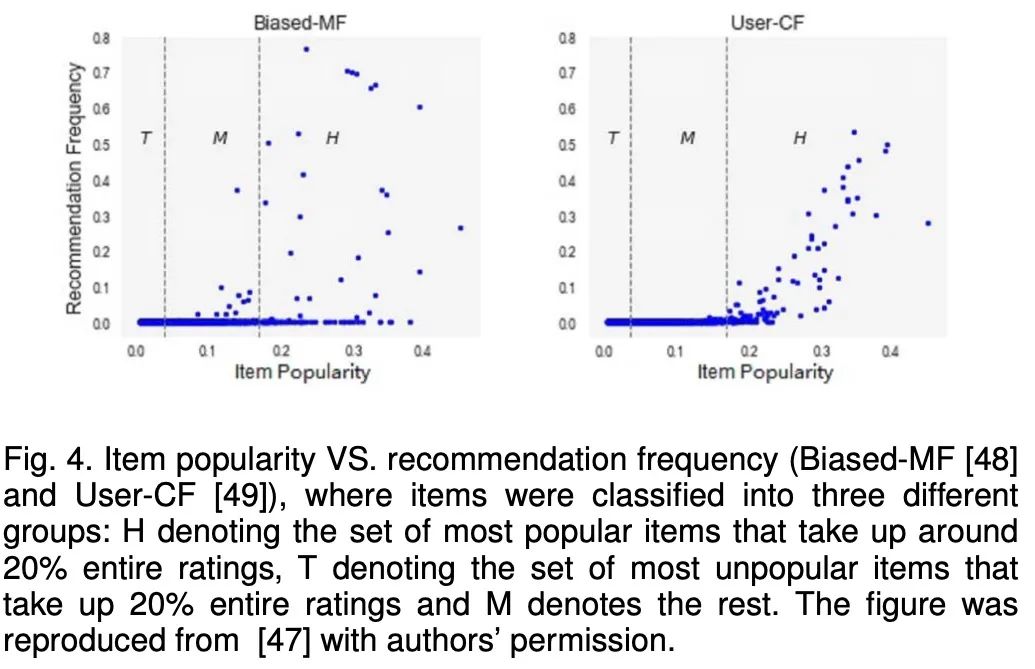
Himan等人对流行偏见进行了实证检验。如上图所示,项目流行度和推荐频率之间的关系。我们可以发现,大多数推荐的商品都位于高人气区(H)。事实上,他们被推荐的程度甚至超过了他们最初的受欢迎程度.
忽略流行度经常会带来非常多的问题:(1).降低个性化的程度影响,影响用户的体验; (2).降低了推荐系统的公平性, 流行的商品却不一定是高质量的, 对流行商品的推荐会降低其它商品的曝光,这是不公平的; (3).Popular Bias会增加流行商品的曝光率, 使得流行的商品越加流行,使模型训练更加不平衡;
另外一个不平衡的问题的原因是由于推荐结果的不公平带来的。
2.不平衡(Unfairness):系统地、不公平地歧视某些个人或个人群体而偏袒其他人是不公平的。
反馈回路放大了偏差
现实世界中的推荐系统通常会产生一个有害的反馈回路。前面的小节总结了在循环的不同阶段发生的偏差,随着时间的推移,这些偏差可能会进一步加剧。以位置偏差为例,排名靠前的项目通常会从更大的流量中受益,这反过来又会增加排名的显著性和它们所接收的流量,从而形成一个“富起来越富”的情景。许多研究者还研究了反馈回路对流行偏差的影响。他们的模拟结果显示,反馈回路会放大流行偏差,流行的商品变得更加流行,而非流行的商品变得更不受欢迎。这些放大的偏差也会降低用户的多样性,加剧用户的同质化,从而产生所谓的 “echo chambers”或“filter bubbles”。
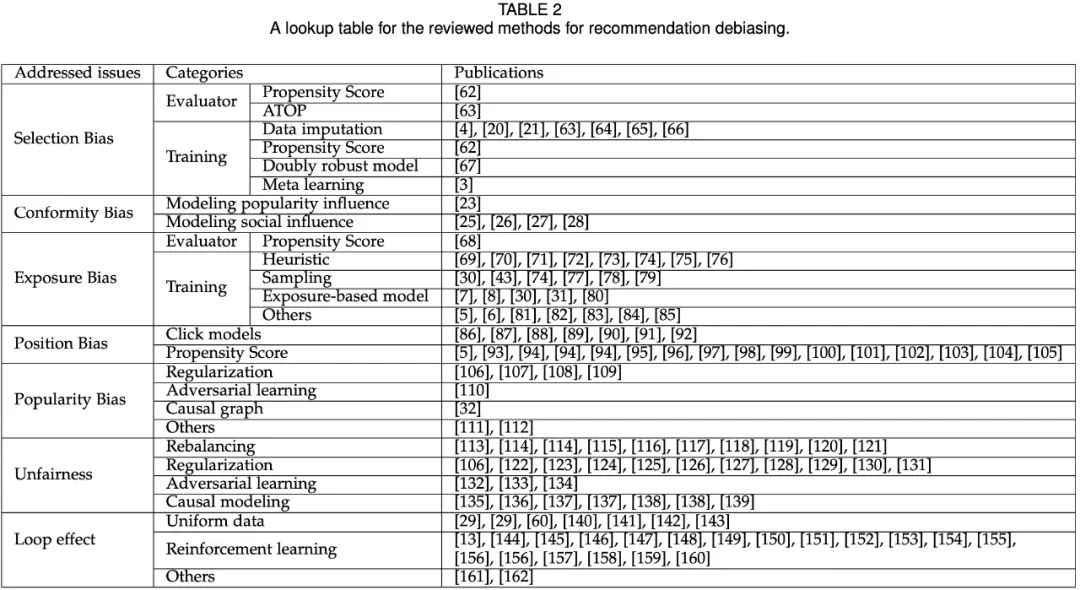
选择偏差的方案(Selection Bias)
1. 评估Debiasing(Debiasing in evaluation)
目前处理Selection Bias的方法主要有:
-
Propensity scores: 将推荐视为类似于用特定药物治疗患者的干预措施。在这两个任务中,我们只知道某些患者(User)从某些治疗(Item)中获益的程度,而大多数患者治疗(user-item)的结果却不被观察到。对于这两个任务,一个很有效的策略是用相反的倾向分数加权(inverse propensity scores)观察结果。 -
ATOP:Steck等人提出的无偏的metricATOP来评估推荐性能,它有两个假设:(1).相关(高)ratings值在观察数据中随机缺失;(2)对于其他rating值,我们允许任意缺失数据机制,只要它们以高于相关rating值的概率丢失。
Propensity scores和ATOP是弥补Selection Bias的两种策略,但它们仍然有两个弱点。基于IPS的估计器的无偏性只有在真实倾向可用的情况下才能得到保证。如果不正确地指定倾向性,IPS估计量仍然是有偏的。只有当这两个假设成立时,才能保证ATOP的无偏性。在实践中,缺失机制往往很复杂,假设并不总是有效的。开发一个强大而有效的系统仍然是一个挑战。
2. 模型训练的Debiasing(Debiasing in model trianing)
-
Data imputation:同时考虑rating预测任务以及缺失数据预测任务;因为联合训练缺失数据模型以及rating模型会导致非常复杂的方案。所以目前非常多的工作采用启发式的优化方案,例如直接对缺失值填充 等,然而,由于缺失数据模型或rating预估值是以启发式方式指定的,这类方法会因缺失数据模型的指定不当或估算的评级值不准确而出现经验误差。
-
Propensity score:另一种方法在训练推荐模型时,利用Propensity score来减轻选择偏差,它们直接以基于IPS的无偏估计量为目标并优化特定的loss。但是,制定准确的Propensity score是非常严格的,基于IPS的模型的性能依赖于propensities的准确性。此外, 基于Propensity score的方法会受到高方差的影响,最终导致非最有的结果。
-
Doubly rost model:将上述的两种方案通过某种方式结合, 使其具有期望的双重鲁棒性.尽管此类方法比单个模型更加鲁棒,但是它也需要准确的propensity score或者imputation数据。
-
Meta Learning:解决上述方法高度依赖propensity和imputation,Saito等人提出了meta-learning的方案,但是这种方法依赖于预训练的predictor的质量,所以学习到满意的程度依然是非常具有挑战性。
一致性偏差(Conformity Bias)的方案
一致性的偏差主要由于用户经常被其它的观念或者其它的分数所影响。目前解决一致性偏差的方案主要有两类:
-
第一类认为用户的rating是符合公众意见; 将用户的评分只作为用户喜好和social影响的综合结果。很多工作直接利用base推荐模型的social因子来生成最终的预测结果,与此同时,引入特定的参数来控制一致性偏差的影响。
曝光偏差(Exposure Bias)的方案
曝光偏差会误导模型的训练和评估;
1. 评估的Debiasing
目前处理该问题的策略主要还是使用inverse propersity score。为了解决这个问题,类似于外显反馈数据中的选择偏差处理,Yang等人建议用隐式反馈数据倾向的倒数来加权每个观测值。intuition是把经常观察到的交互降权,而对少的样本进行升权;
2. 模型训练的Debiasing
为了解决曝光偏差的问题,传统的策略就是将所有被观测的交互作为负例并且明确它们的交互。confidence weight可以被分为三类:
1.Heuristic:典型的例子是加权的矩阵分解以及动态MF,未观测到的交互被赋予较低的权重。还有很多工作则基于用户的活跃度指定置信度等;但是赋予准确的置信权重是非常有挑战的,所以这块依然处理的不是非常好。
2.Sampling: 另一种解决曝光bias的方式就是采样,经常采用的采样策略有均匀的负采样,对于流行的负样本过采样,但是这些策略却较难捕捉到真实的负样本。
3.Exposure-based model:另外一个策略是开发基于曝光的模型,这样可以知道一个商品被曝光到某个用户的可能性等。
位置偏差的方法(Position Bias)
位置偏差表明,无论相关性如何,排名较高的项目更有可能被选中
1. 点击模型
目前有很多模型将position bias直接建模到模型中,在预测的时候则忽略这块分支。当然策略还有很多。不过大多数模型模型通常需要为每个查询项或用户项对进行大量的点击,这使得它们很难应用于点击数据高度稀疏的系统中。
2. Propensity score
流行度偏差(Popularity Bias)的方法
解决流行度偏差的方案有四类:
1.正则
合适的正则可以将模型推向平衡的推荐列表。
2. 对抗训练
基本思路在推荐G以及引入的adversary D进行min-max博弈,这样D可以给出提升推荐锡惠的信号。通过G和D之间的对抗学习,D学习流行项和利基项之间的隐式关联,G学习捕捉更多与用户历史相关的niche商品,从而为用户推荐更多长尾商品。
3. Causal graph
因果图是反事实推理的有力工具。Zheng等人利用因果推理解决流行偏差。他们假设用户对商品的点击行为取决于兴趣和流行程度,并构建了一个特定的因果图。为了解决用户兴趣和流行偏差的问题,作者考虑了两种嵌入方法:兴趣嵌入以捕获用户对商品的真实兴趣,以及流行度嵌入来捕获由流行度引起的伪兴趣。在多任务学习的框架下,可以利用特定原因的数据对这些嵌入进行训练。最后,兴趣嵌入将被用于最终推荐,在这里,受欢迎度偏差已经被消除。
4. 其它方法
不公平(Unfairness)的方案
fairness的定义有四种:
-
fairness through unawareness:如果在建模过程中没有显式地使用任何敏感属性A,那么模型是公平的; -
individual fairness:如果一个模型对相似的个体给出了相似的预测,那么它是公平的。形式上,如果个体i和j在某个度量下是相似的,那么他们的预测应该是相似的: -
group fairness:包括demographic parity, Equality of Opportunity; -
counterfactual fairness
关于不公平的方案有四种处理策略:
-
Rebalancing -
Regularization:将fairness的criteria作为正则来引导模型的优化; -
Adversarial Learning:基本的想法是在预测模型和adversary模型之间进行min-max博弈; Causal Modeling:公平性被定义为敏感属性的因果效应,通过在因果图上应用反事实干预来评估。
缓和回路效应(Mitigating Loop Effect)的方案
处理该问题的方案目前主要有下面三种:
-
Uniform data; -
Reinforcement learning; -
Others:
1. Propensity Scores的评估
Propensity Scores是一种传统的debias策略。然而,只有当倾向性得分被正确地指定时,IPS策略的有效性和公正性才得到保证。
如何获得正确的Propensity Score仍是一个重要的研究课题。现有的方法通常假设给定了Propensities。虽然在一些简单的情境中,例如对于位置偏差,Propensity Score的评估已经被探索过,但是对于更复杂的情境,例如选择偏差或曝光偏差,Propensity Score的评估仍然是一个开放的问题,值得进一步探索。
2. 通用的Debiasing框架
我们可以发现,现有的方法通常只针对一个或两个特定的偏差而设计。然而,在现实世界中,各种Bias通常同时发生。例如,用户通常对自己喜欢的商品进行评分,他们的评分值受公众意见的影响,在收集的数据中混合了conformity偏差和选择偏差。此外,被评价的用户商品对的分布通常倾向于热门商品或特定的用户组,这使得推荐结果容易受到受欢迎度偏差和不公平的影响。推荐系统需要一个通用的借记框架来处理混合的偏差。这是一个很有前途的领域,但在很大程度上还没有得到充分的研究。尽管具有挑战性,但简单的案例——仅仅是两到三种偏见的混合体——值得首先探讨。IPS或其变体,已经成功地应用于各种偏差,是解决这一问题的一个有希望的解决方案。探索一种新的基于IPS的学习框架,总结IPS在不同偏差下的应用,并提供一种通用的倾向评分学习算法。
3. 知识加强的Debiasing
如何更好地利用这些辅助信息,因为属性不是孤立的,而是相互连接形成知识图的。知识图捕捉到更丰富的信息,这可能有助于理解数据偏差;知识图谱可能会成为开发featue-enhanced通用的debiasing框架的强有力工具;
4. 使用归因图来解释和推理
降低Bias的关键是对推荐模型或数据的发生、原因和影响进行推理。大多数Bias可以通过原因假设和因果图中的其他混淆因素来理解;Bias的理解还可以通过图中的因果路径来推理。所以设计一个更好的合适的因果图,它可以推理、debiasing和解释。
5. 动态Bias
实践中,bias通常是动态的而不是静态的, 因素或bias往往会随着时间的推移而演变。探讨bias是如何演变的,分析动态bias是如何影响推荐系统的,这将是一个有趣而有价值的研究课题。
6. Fairness-Accuracy的平衡
现有的方法主要假设用户(或商品、组)的敏感属性作为输入的一部分提供。这种假设在某些实际情况下可能不成立。例如,在协同过滤中,包含诸如年龄和性别等敏感属性的用户配置文件会导致他们的行为模式不同;然而,这些配置文件是不被观察到的,但却隐含地影响了推荐性能。一个研究方向是了解在causality,设计公平性感知的协同过滤算法目前还没有。
-
Bias and Debias in Recommender System: A Survey and Future Directions:https://arxiv.org/pdf/2010.03240.pdf
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。

