医学知识图谱构建关键技术及研究进展
谭玲1, 鄂海红1, 匡泽民2, 宋美娜1, 刘毓1, 陈正宇1, 谢晓璇1, 李峻迪1, 范家伟1, 王晴川1, 康霄阳1
1 北京邮电大学
2 首都医科大学附属北京安贞医院
摘要:随着互联网技术的不断迭代更新,对海量数据的语义理解变得越来越重要。知识图谱是一种揭示实体之间关系的语义网络,医学是知识图谱应用较广的垂直领域之一,医学知识图谱的构建也是目前国内外人工智能领域研究的热点。从医学知识图谱本体构建出发,依次对命名实体识别、实体关系抽取、实体对齐、实体链接、知识图谱存储、知识图谱应用进行综述,详细介绍了近年来医学知识图谱构建过程中涉及的难点、现有技术、挑战及未来研究方向,并介绍了医学知识图谱应用,最后对未来发展方向进行了展望。
关键词:
医学知识图谱
;
构建
;
关键技术
;
研究进展

论文引用格式:
谭玲, 鄂海红, 匡泽民, 等. 医学知识图谱构建关键技术及研究进展[J]. 大数据, 2021, 7(4): 80-104.
TAN L,E H H, KUANG Z M, et al . Key technologies and research progress of medical knowledge graph construction[J]. Big Data Research, 2021, 7(4): 80-104.

1 引言
人工智能的发展已经进入快车道,作为新一轮科技革命和产业变革的重要驱动力量,人工智能技术正在深入各行各业,悄无声息地改变着人们日常生活的方方面面。知识图谱是由谷歌(Google)公司在2012年提出的一个概念,本质上是语义网的知识库。知识图谱由节点和边组成,节点表示实体,边表示实体与实体之间的关系,这是最直观、最易于理解的知识表示和实现知识推理的框架,奠定了第三代人工智能研究的基础。
目前,医学是知识图谱应用较广的垂直领域之一,也是目前国内外人工智能领域研究的热点。医学知识图谱在临床诊断、治疗、预后等方面均可发挥较大的作用。高效地将知识图谱应用于医学领域将给人类的医疗卫生带来革命性的变化。由于医学领域数据的特殊性,医学知识图谱的构建也面临不少机遇与挑战。
本文对医学知识图谱构建的关键技术及应用进行了全面的梳理,对各类公共数据集、处理医学问题的特异性难点及现有解决办法进行了综述。通过阅读本文,可以了解医学知识图谱的发展现状、未来发展方向以及面临的挑战,便于医学知识图谱研究者参照对比,加快医学知识图谱领域的研究及临床落地应用。
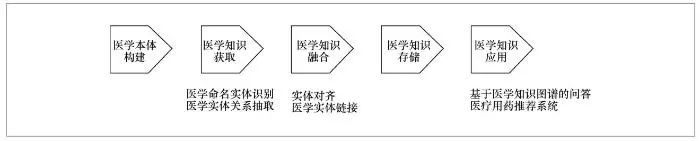
本文主要按照医学知识图谱构建的流程来阐述,主要框架如图1所示。
2 医学本体构建
网络上文本数据的爆炸式增长,以及对本体需求的增加,促进了语义网络的发展,使得基于文本的本体自动构建成为一个非常有前途的研究领域。文本本体学习是一种以机器可读形式(半)自动地从文本中提取和表示知识的过程。本体被认为是在语义网络上以更有意义的方式表示知识的主要基石之一。
3 医学命名实体识别
3.1 命名实体识别定义
命名实体识别(named entity recognition,NER)又称专名识别,指识别文本中具有特定意义的实体(主要包括人名、地名、机构名、专有名词等)。通常包括两部分:一是识别实体边界;二是确定实体类别(人名、地名、机构名或其他)。英语中的命名实体具有比较明显的形式标志(即实体中的每个词的第一个字母要大写),因此识别实体边界相对容易,任务的重点是确定实体的类别。和英语相比,汉语命名实体识别任务更加复杂,实体边界的识别更加困难。
3.2 医学命名实体识别难点及现有技术
与传统的命名实体识别相比,医学名词实体一般比较长,长实体名词常常包含多个名词实体,造成医学实体边界识别的难度较大。此外,医学名词存在大量的同义词替换、缩写以及一词多义现象,加大了确定实体类别的难度。
针对医学实体中大量同义词替换以及大量缩写的问题,2020年Kato T等人提出了一种共享和学习标签组件嵌入的方法,通过对英语和日语细粒度NER进行实验,证明了该方法比标准序列标记模型性能更好,特别是在低频标签情况下。
为了解决医学名词实体较长、识别边界困难的问题,2020年,Tan C Q等人提出了边界感知的神经网络模型来预测实体的类别信息。该模型可以先定位出实体的位置, 然后在对应的位置区间内进行实体类型的预测。在公开的嵌套NER数据集上,该模型取得了超越以往方法的效果,并在预测上取得了更快的速度。
另外,大多数NER系统只处理平面实体,忽略了内部嵌套实体,导致无法捕获底层文本中的细粒度语义信息。为了解决这个问题,2018年Ju M Z等人提出了一种新的神经模型,通过动态叠加平面NER层来识别嵌套的实体。模型将长短时记忆(long short term memory,LSTM)层的输出合并到当前的平面NER层中,为检测到的实体构建新的表示,并将它们提供给下一个平面NER层。模型动态地堆加平面NER层,直到没有提取任何外部实体。该模型针对特定数据集(具有多种类别和嵌套的实体)具有较好的实验效果。
对于医学实体中常见的一词多义现象,2019年Pham T H等人在细粒度NER任务中进行了多任务学习和语境化单词表征的有效性研究,并研究了多任务序列标记的不同参数共享方案、神经语言模型学习和不同单词表示设置下的学习。最终得到的最佳模型不需要任何额外的人工操作来创建数据和设计特征,F1分数达到83.35%。Luo Y等人提出了一个增加了上下文表示层次的模型:句子级表示和文档级表示。在句子级,考虑到单个句子中单词的不同贡献,通过标签嵌入注意机制来增强从独立的双向长短时记忆(bidirectional long short term memory,BiLSTM)学习到的句子表征。在文档级,采用键值存储网络记录对上下文信息相似度敏感的单个单词的文档感知信息。在基准测试的实验结果数据集(CoNLL-2003和Ontonnotes 5.0英语数据集,CoNLL-2002西班牙语数据集)上获得了最先进的结果。
4 医学实体关系抽取
4.1 实体关系抽取定义
实体关系抽取是指从一个句子中抽取出关系三元组,主要目的是从文本中识别实体并抽取实体之间的语义关系。实体关系抽取解决了原始文本中目标实体之间的关系分类问题,它也是构建复杂知识库系统的重要步骤,如文本摘要、自动问答、机器翻译、搜索引擎、知识图谱等。随着近年来信息抽取的兴起,实体关系抽取进一步得到广泛的关注和深入的研究。
4.2 医学实体关系抽取难点及现有技术
与一般的实体关系抽取相比,生物医学领域语料库的建设很复杂,且需要大量的人力、物力,对参与人员的专业背景要求高,因此使用仅有的医学知识来自动构建大规模的语料库对于医学实体关系的抽取十分重要。此外,医学实体之间普遍存在重叠关系,这给关系抽取的准确性带来较大的干扰。现有的医学关系抽取方法大多需要复杂的特征工程,越来越多的学者采用深度学习方法进行关系的抽取,但大多采用的是流水线的方法,没有充分利用实体信息,且容易导致错误的传递。最后,医学关系的跨度较大,句子级的抽取不能满足要求。
为了自动构建大规模的语料库,2019年Li Y等人提出了一种全新的轻量级神经网络框架来解决远程监督关系抽取问题,以弥补以往选择的不足,使用《纽约时报》(New York Times,NYT)数据集进行实验,结果表明该方法在AUC和Top-n精度指标方面都达到了较先进的性能。2020年He Z Q等人设计了一个新的状态表示形式,它考虑了句子嵌入、关系嵌入以及所选的正向实例的嵌入,该方法解决了远程监督方法中的错误标签问题,同时提升了词袋水平的关系提取效果。Chen D Y等人提出了通过多代理强化学习模型来重新标记噪声训练数据,并共同提取实体和关系的新方法。他们在两个真实的数据集上对该方法进行了评估,结果证明,该方法可以显著提高提取器的性能,并实现有效的学习。
针对医学实体间普遍存在重叠关系这一问题,2019年Zeng D J等人重新研究了基于复制机制的关系抽取模型,提出了使用序列到序列(Seq2Seq)方法共同提取实体和关系的多任务学习复制模型(copy mechanism for multi-task learning,CopyMTL)。该模型利用多任务的学习框架来识别多词实体,通过提高实体识别精度来提升关系抽取的效果,从而达到了较理想的效果。2020年Nayak T等人提出了使用编码器-解码器体系结构共同提取实体和关系的方法。该方法使用一种用于关系元组的表示方案,使解码器能够像机器翻译模型那样一次生成一个单词,并且仍然可以找到句子中存在的所有元组,它们具有不同长度的完整实体名称,并且具有重叠的实体。对NYT数据集进行的实验表明,该方法明显优于所有以前的模型。
为了减少深度学习方法关系抽取中错误的传递,2019年Eberts M等人提出了一种混合模型,包括基于转换器的编码层、LSTM实体检测模块、基于强化学习的关系分类模块。实验结果表明,与基线方法相比,该混合模型在关系和实体提取方面表现更好。2019年Bansal T等人提出了一个新的模型——同时神经实体-关系连接器(simultaneous neural entityrelation linker,SNERL)。首先使用自注意力机制来捕获文本中每个实体提及的上下文表示;然后使用这些上下文表示来预测提及水平的实体分布和提及对水平的关系分布;最后针对每个提及对,将这些预测概率进行组合,并合并到文档级别,以获得预测关系三元组的最终概率。实验结果表明,SNERL模型在CDT和CDR这两个生物医学数据集上的表现达到了最优的效果,并且可以大大改善系统的整体召回率,同时避免了级联错误。
针对医学关系跨度大的问题,2020年Nan G S等人提出潜在结构优化(latent structure refinement,LSR)模型,以端到端的方式构造一个文档级图谱来推理句间关系,通过迭代优化策略,模型能够动态构建潜在结构,以改善整个文档中的信息聚合。该模型在生物医学领域的两个文档级关系抽取数据集上取得了较好的效果。
5 实体对齐
实体对齐是判断多源异构数据中的实体是否指向真实世界同一对象的过程。如果多个实体表征同一个对象,则在这些实体之间构建对齐关系,同时对实体包含的信息进行融合和聚集。由于目前将实体对齐应用于医学领域的研究文章较少,因此本节主要介绍实体对齐,而不是医学实体对齐。
6 医学实体链接
由于语言表达的多样性、歧义性以及上下文关联,语言理解面临巨大的挑战。语言理解主要包括语法解析、语义解析和特定的知识表示或其中的某个片段。而在知识图谱中主要涉及的技术即实体理解或实体链接技术,将现实世界中的知识映射到现有知识图谱中的实体,进而用现有知识图谱进行表示,达到理解的目的。在实体链接任务中输入的是实体的指代和上下文以及待链接的知识库,输出的是指代所对应的知识库中的实体。
实体链接(或实体规范化、实体消歧)指将文本中的短语(提及范围)映射到结构化源(如知识库)中的概念。提及范围通常是一个词或短语,描述一个单一的、连贯的概念。
7 医学知识图谱存储
7.1 知识图谱存储方式
现有知识图谱数据的存储方式主要分为两种:基于关系模型的存储方式和基于图模型的存储方式。
基于关系模型的知识图谱存储方式包括三元组表、水平表、属性表、垂直划分、六重索引和DB2RDF。
目前,基于图数据库的知识图谱存储方法是学术界研究的主流。图数据库的优点在于其天然能表示知识图谱结构,图中的节点表示知识图谱的对象,图中的边表示知识图谱的对象关系。其最大的优点是可以用来处理复杂的关系问题,提供完善的图查询语言,支持各种图挖掘算法。采用图数据库存储知识图谱,能有效利用图数据库中以关联数据为中心的数据表达、存储和查询。基于图模型的存储方式见表6。
![]()
知识图谱的存储方式应考虑其后续的使用效率,应根据自己的应用场景、数据情况来具体设计。可参考表7选择最适用的存储方式。
![]()
![]()
8 医学知识图谱应用
8.1 基于医学知识图谱的问答
医学知识图谱与问答系统的融合是目前极具挑战性的研究方向,同时也是典型的应用场景。基于知识图谱的医疗问答系统可以快速响应医患用户提出的问题,并给出准确、有效的解答。
8.2 医疗用药推荐系统
医学上的用药推荐与一般的推荐算法不同,一般的推荐算法是根据用户的历史记录,利用数学算法推测出用户可能的需求,已被广泛应用于电商等互联网场景。而用药推荐则是基于循证医学的原则,结合患者的具体患病情况以及医学专业知识,推荐适合的用药方案。一般的推荐算法的推荐结果对准确率的容忍度较高,即使部分推荐结果与用户需求不符,也能够接受。但用药推荐在实际应用中要求达到百分之百的准确率,即药品一定能够起到作用,且不能产生不良反应或药品间的相互作用。
知识图谱能够更加清晰准确地表达疾病与药品之间的适应关系以及药品间的相互作用,基于知识图谱的用药推荐与其他人工智能方法相比,能够取得更好的效果。目前基于知识图谱的用药推荐研究进展与其他基线水平相比有所提升,但还无法达到实际应用的要求。
9 医学知识图谱未来展望
构建医疗领域的知识图谱,可以从海量数据中提炼出医疗知识,并合理高效地对其进行管理、共享及应用,这对当今的医疗行业具有重要意义,也是很多企业和研究机构的研究热点。本文对医学知识图谱构建过程中的研究热点、现有技术、挑战及未来发展方向进行了综述,具体见表9。医学知识图谱将知识图谱与医学知识结合,定会推进医学数据的自动化与智能化处理,为医疗行业带来新的发展契机。医学知识图谱未来总的发展方向应该体现以下几个方面。
![]()
![]()
![]()
国内外医学知识的相互融合促进更有利于医学领域的发展,而实现不同国界医学知识的相互沟通和交流,多语言医学知识图谱技术是关键,这会成为未来医学知识图谱发展的一个重要趋势。
受到多方面因素的影响,现有的医学知识图谱规模大多有局限,表现方式也较为单一,大多以文本和图数据的形式呈现,但声音、影像、图片等也蕴含大量的医学信息,在医学临床中也存在大量的医疗影像、X光等多模态信息,医学知识的来源也可以来自书本、文献、网页、视频等。因此未来医学知识图谱研究的一个热点是构建大规模多模态多源的医学知识库。
研究基于深度学习与逻辑推理相互约束的大规模多粒度知识推理模型与方法,研制基于本体、规则与深度学习相结合的大规模知识推理系统,使其能够对包含10亿级RDF三元组的知识库和万级规则进行推理,平均响应时间在秒级,并具有良好的可伸缩性。在此基础上,研究基于时空特性的知识演化模型与预测方法,研制知识演化系统,使其能够实时地对知识库进行更新,平均响应时间为秒级。
作者简介
谭玲(1993-),女,北京邮电大学博士生,主要研究方向为知识图谱及自然语言处理、大数据及人工智能。
鄂海红(1982-),女,博士,北京邮电大学副教授,主要研究方向为大数据及人工智能、知识图谱及自然语言处理、大数据中台、分布式微服务架构。
匡泽民(1979-),男,博士,首都医科大学附属北京安贞医院高血压科主任医师,主要研究方向为高血压精准诊断与治疗、心血管临床药理、医学人工智能。
宋美娜(1974-),女,博士,北京邮电大学教授,主要研究方向为大数据、联邦学习及医疗健康、金融科技应用、大数据、联邦学习及医疗健康。
刘毓(1998-),女,北京邮电大学硕士生,主要研究方向为知识图谱。
陈正宇(1997-),男,北京邮电大学硕士生,主要研究方向为计算机视觉、知识图谱。
谢晓璇(1997-),女,北京邮电大学硕士生,主要研究方向为知识图谱。
李峻迪(1997-),男,北京邮电大学硕士生,主要研究方向为智能对话系统和Java开发。
范家伟(1998-),男,北京邮电大学硕士生,主要研究方向为深度学习。
王晴川(1997-),女,北京邮电大学硕士生,主要研究方向为自然语言处理。
康霄阳(1997-),男,北京邮电大学硕士生,主要研究方向为机器学习、计算机视觉。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取70000+AI(AI与军事、医药、公安等)主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
点击“阅读原文”,了解使用专知,查看获取70000+AI主题知识资料