课程笔记:深度学习与人类语言处理 ——李宏毅,2020 (P5)
原创 · 作者 | 阿芒Aris
学校 | 北京理工大学
研究方向 | 自然语言处理
来自 | AINLP
语音辨识模型2、3、4、5:
CTC 、RNN-T(&RNA)、Neural Transducer、MoChA
李宏毅老师2020新课深度学习与人类语言处理课程主页:
http://speech.ee.ntu.edu.tw/~tlkagk/courses_DLHLP20.html
视频链接地址:
https://www.bilibili.com/video/BV1RE411g7rQ
课程视频及课件请关注AINLP公众号,回复'DLHLP'获取承接上文,LAS模型效果虽然足够出色且端到端保证了模型的大小足够小,但问题是无法进行online的语音辨识,在LAS中要进行整个数据的attention,只有在整个语音读完后才能进行辨识,而CTC便是解决这个问题的一种模型。
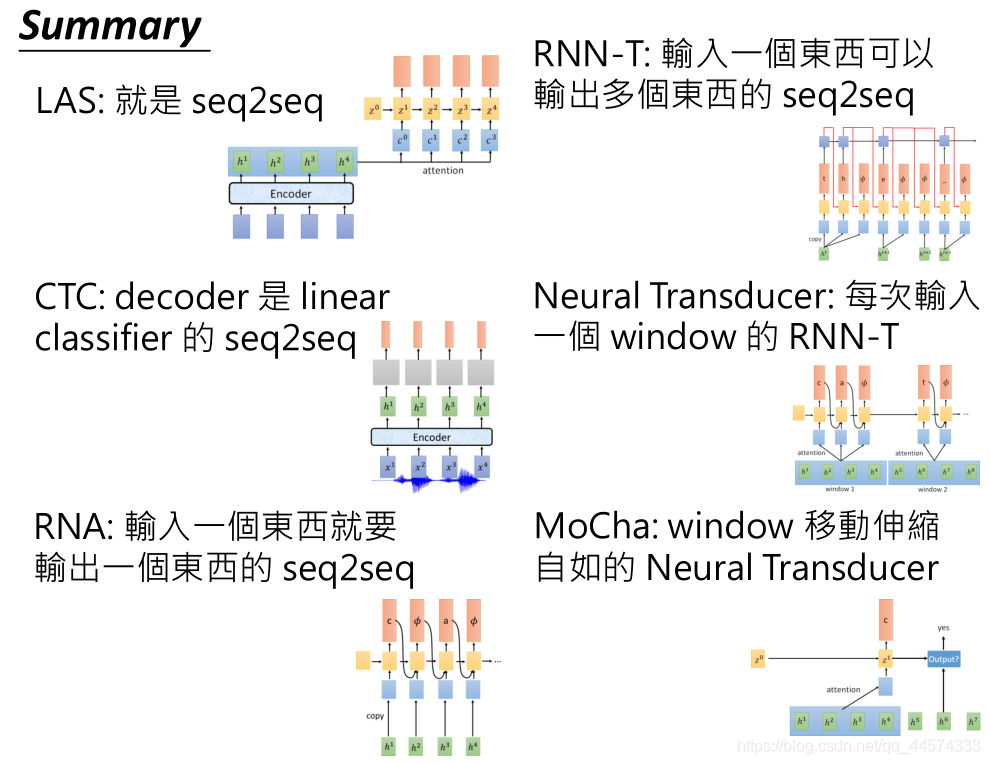
Model 2:CTC (Connectionist Temporal Classification)
[Graves, et al., ICML’06]
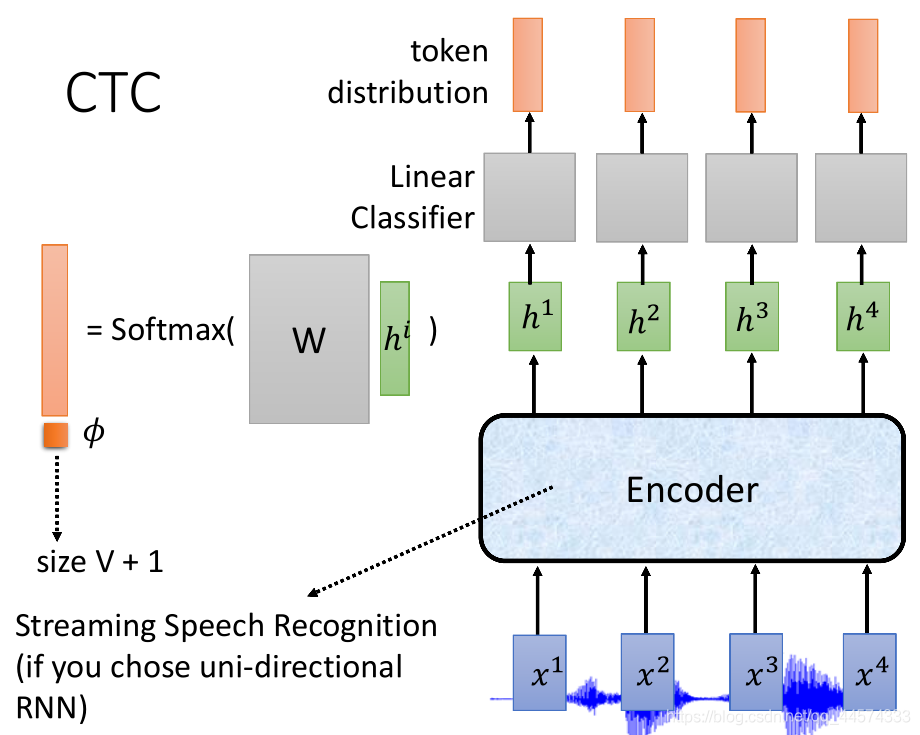
CTC可以说是只有Encoder,在做encoder时要选一些可以做online语音辨识的Encoder,比如说uni-directional RNN 单向RNN,而如果是双向的话要输入整个句子。而单方向的RNN可以输入x1 输出h1等等。在得到h后,将h输入到Linear Classifier,将h乘上一个矩阵再做softmax得到一个所有token的distribution。输入h1产生第一个结果,输入h2产生第二个结果,可以做online的,依此类推。
但注意,我们输入的x是acoustic features,它所代表的声音讯号非常小,仅10ms。这一小个feature不一定是一个token,故我们加入一个特别的token,𝜙 (拼音:nuo 四声),代表暂时不知道的。
对CTC而言,
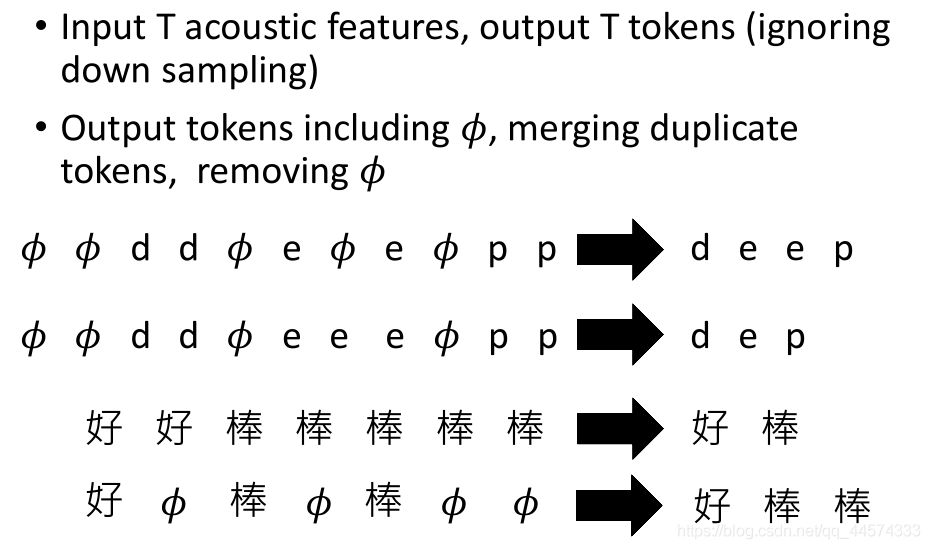
I 输入 输出
输入:T个acoustic features
输出:T个tokens(假设没有down sampling)
特别地,语音辨识中并没有nuo这个东西,在输出时,将这T个tokens做一下后处理,将相邻重复的tokens去重,再将nuo的部分空格,示例可见上图。
II Training时的问题
假设我们输入 “好棒”的语音讯号acoustic features的 4个tokens x1-x4, 但对应的y1-y4 tokens到底那里应该是nuo呢?哪里是重复的呢?
而我们要自己制造这样的输出,这种方式就叫做alignment。
如 好棒 的输入 是 x1 x2 x3 x4的声音讯号,输出可以自己构造为 𝜙 好 𝜙 棒(那其他种,如 好𝜙棒棒等等也是可以的。alignment有很多种方式),那我们该选那一种alignment呢,全都要,穷尽所有的alignment下一节会讲。

III Result
表中数值是错误率,越小越好
单纯的CTC效果并不尽如人意,但加上后处理和语言模型后,效果超过了Encoder-Decoder的LAS

IV Issue
CTC的问题在于,如果输入的连续的ccc语音,如果第一个token产生的是c 第二个是𝜙,则之后无论怎样生成都是错误的,因为第二个生成的𝜙会直接变成两个或多个字
V Combination
LAS的结构中加入CTC,Encoder的部分同时做listen和CTC,做两个loss。
Model 3:RNN-T (RNN Transducer)
[Graves, ICML workshop’12]
I RNA (Recurrent Neural Aligner)
[Sak, et al., INTERSPEECH’17]
在将RNN-T之前,先了解一个RNN-T后续的模型RNA (Recurrent Neural Aligner)
在CTC的“decoder”是一个linear classifier,对每一个encoder生成的结果h都将直接输出一个token,各自独立。能不能不要独立,可以,将CTC的linear classifier换成RNN 、LSTM就可以,这就是RNA做的事请。到目前为止,我们看到的CTC或RNA都是吃一个输入。有没有可能,输入一个vector输出多个token,一种方法可以通过th当作一个token,可以自己加token。但对模型而言,我们是希望模型直接解决这个问题,另一种方法****RNN-T可以帮助我们解决这个问题。
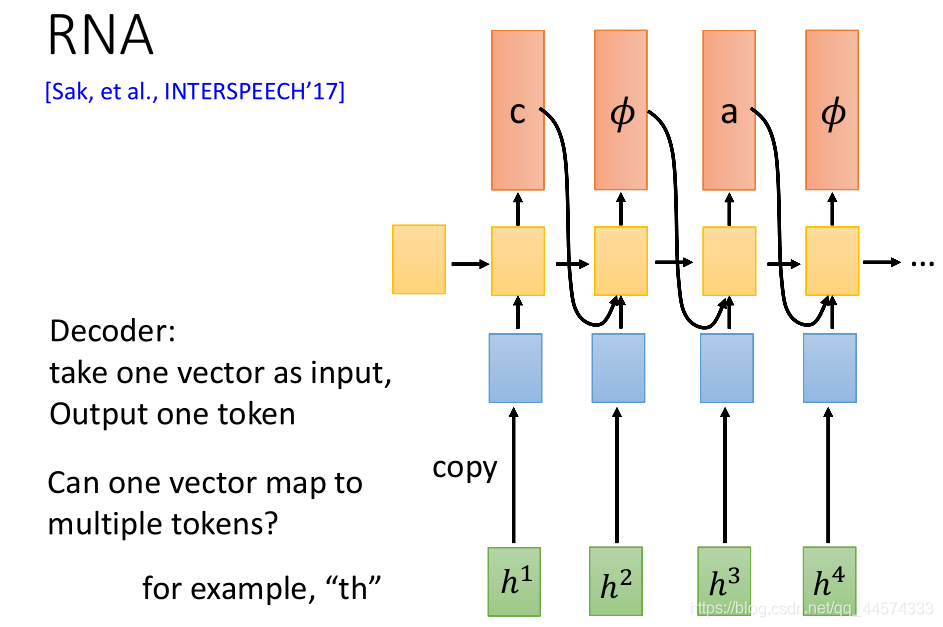
II RNN-T 一般结构
上图左侧是RNA的结构,而右侧便是RNN-T的结构。
RNN-T看到一个输入以后,一直输出直到输出𝜙为止。如图所示,输入一个ht,RNN-T可以先 生成一个t,再生成一个h,直到𝜙(give me next frame)。
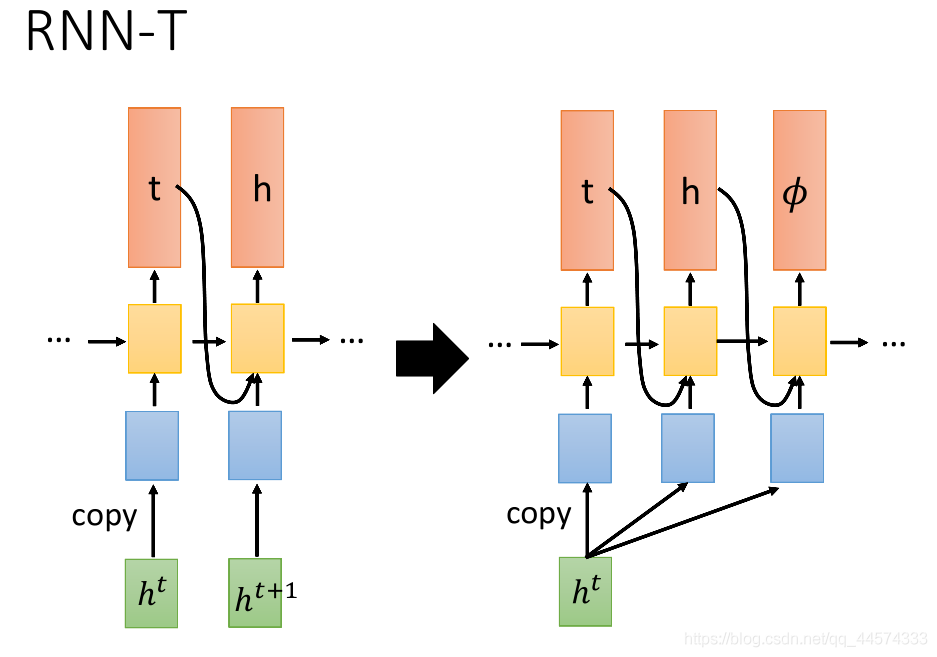
具体而言,我们先有一个来自Encoder的ht,丢给decoder,decoder先输出一个t,然后输出h,之后没有可生成的了,就输出 𝜙。Encoder就会再提供下一个ht+1,同样处理。
th 𝜙 e 𝜙 𝜙 _ 𝜙 = th e _
提问:在给RNN-T一共 T 个h,最终会生成多少个 𝜙 呢?(思考一下再看下面)
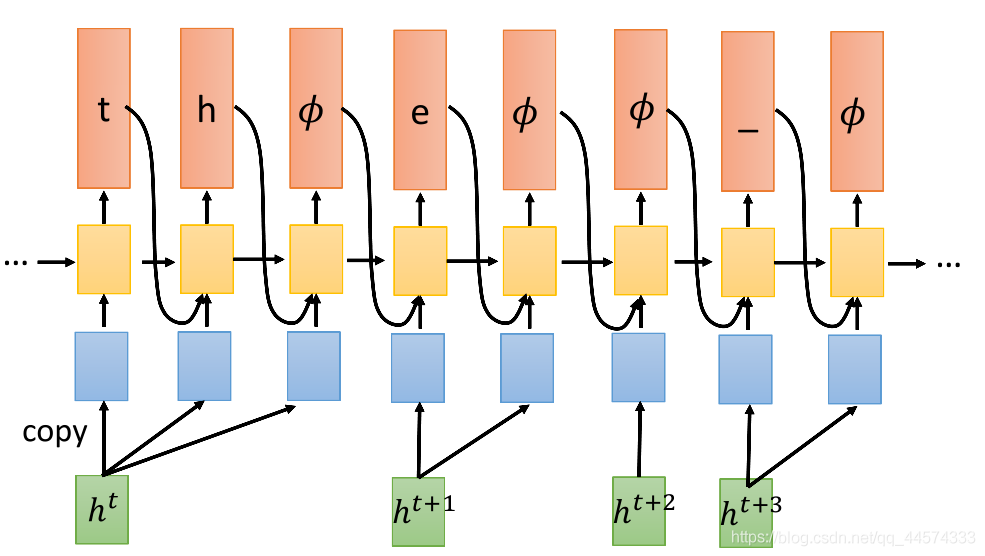
答案:T个 𝜙 ,因为每当生成一个 𝜙 就相当于告知模型 我们要处理下一个h了,故输入T个h,会依次输出T个𝜙。
由此,我们在构造数据集的输出时,假设我们的输入经过Encoder会有T个h(hidden state) ,则我们构造的输出也应该有T个 𝜙 ,举例:输入语音 “好棒” Encoder后得到 h1 h2 h3 h4 的h后,我们要构造的生成结果可为 𝜙1好 𝜙2棒 𝜙3 𝜙4(一定要包含和h数量一样的𝜙,且后处理𝜙后的结果是我们的输入“好棒”),同样,RNN-T也就有和CTC一样的alignment问题,怎样构造所有可能的alignment?我们下一节会讲。
III RNN-T 再加 RNN
实际RNN-T会另外训练一个RNN,这个RNN很像一个Language Model,我们另外训练一个RNN,这个RNN会看,如果前面有输出token(注意,不包含𝜙),就把那些token丢到这个RNN里面去。
具体而言,现在丢入一个ht,decoder输出一个t,这个t就会输入到RNN里面来决定下一个decoder token的输出(上图红线)。这样,虽然我们在同样输入ht时,在生成t之后,再进行生成时是会受到生成t的影响,即使输入的都是同样的ht,但加了经过RNN的t后 生成h的输入部分便有所不同了。
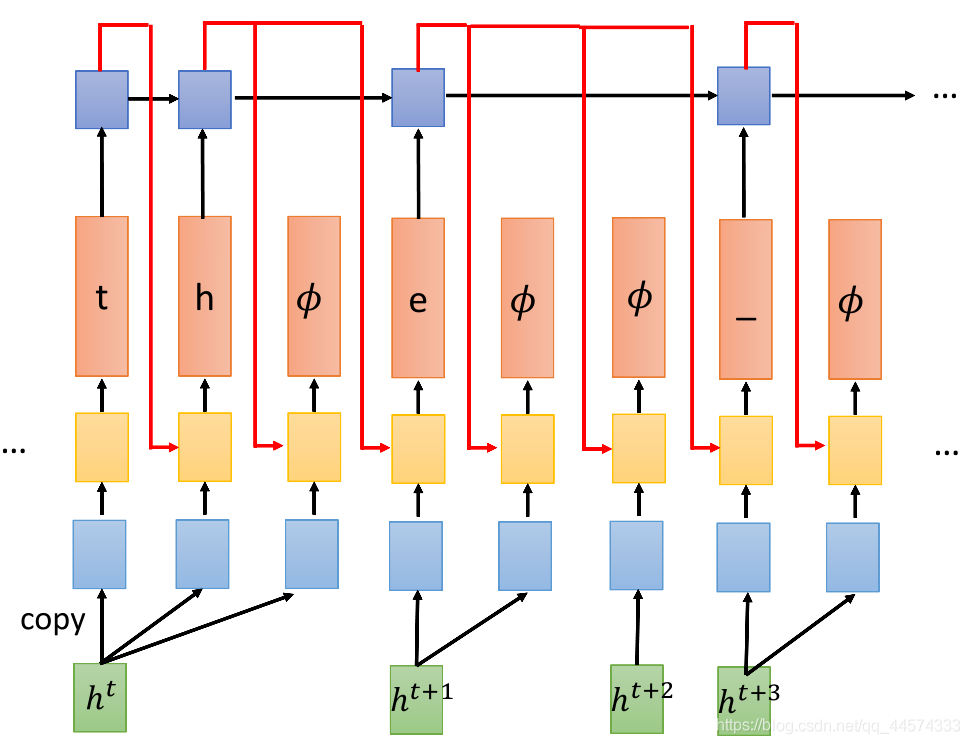
问题,1 我们为什么要新训练一个RNN,而不是像上面一般的RNN-T?。2 这个新的RNN会无视𝜙,而我们为什么要无视这个𝜙?
理由:首先,这个RNN是一个language model,它只看token当作输入,因此我们可以先通过大量的文字来预训练这个RNN,因为这些文字里没有𝜙这种东西。其次,更本质的,这一步是必要的,RNN-T在训练时要穷举所有的alignment,而要实现穷举所有的alignment的算法是需要模型内部有一个无视𝜙的,该算法下节会讲。为了训练而设计的。
Model 4: Neural Transducer
[Jaitly, et al., NIPS’16]
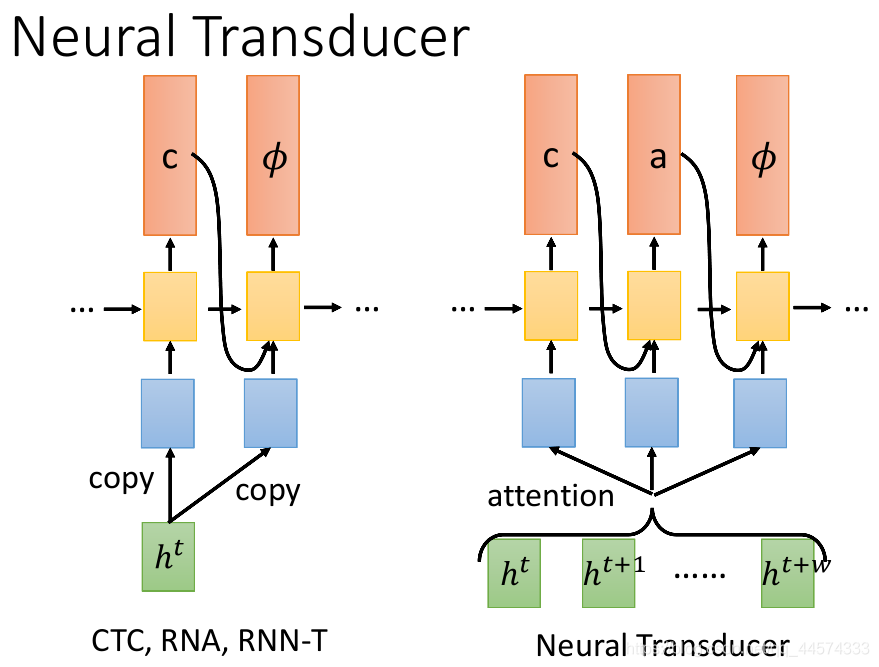
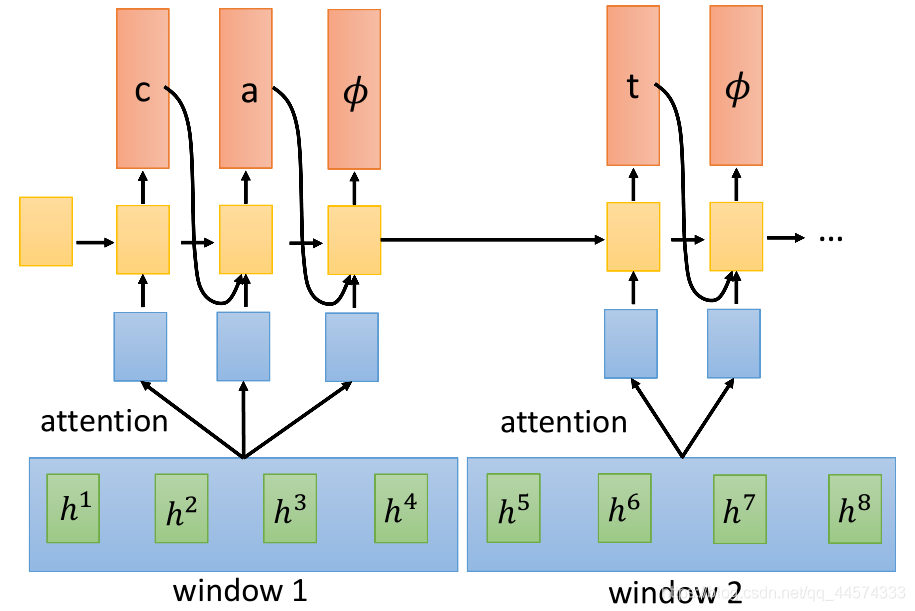
上面讲的CTC、RNA、RNN-T 都是只读一个h进来进行输出,感觉效率不高,而Neural Transducer一次读一段长度为W的h,之后在这个区域内做attention,由attention来决定选择读哪些进入RNN输出。
具体而言,请看下图
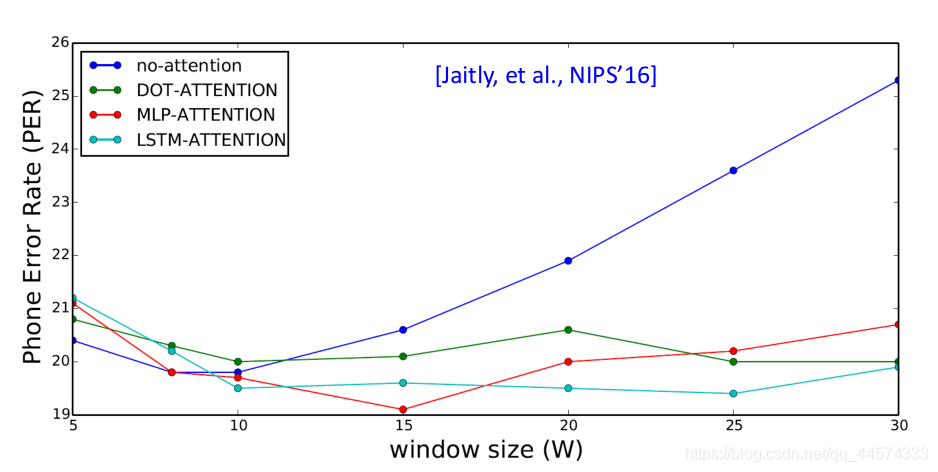
那这个window该多大呢,在Neural Transducder文献里作者给出了4种attention的window对错误率的影响。
no-attention
DOT-Attention
MLP-Attention
LSTM-Attention :也是一种Location-aware attention
Model 5: MoChA (Monotonic Chunkwise Attention)
[Chiu, et al., ICLR’18]
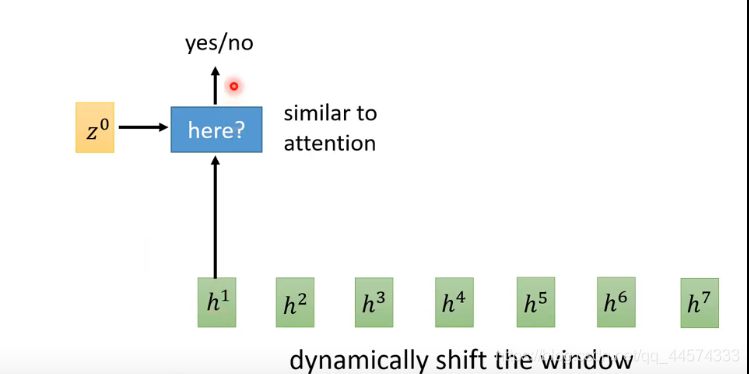
在Neural Transducer 模型中window大小是固定的,而在MoChA里面有一种方式,类似于attention,也是 给它两个vector:z0和h依次输出 yes/no,yes就是把window放在这里。
注意这是binary的,该怎么微分呢,请详见论文。
Summary
大家有任何问题,欢迎指正和讨论,共同学习。
本文由作者授权AINLP原创发布于公众号平台,欢迎投稿,AI、NLP均可。原文链接,点击"阅读原文"直达:
https://blog.csdn.net/qq_44574333/article/details/108056805
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! ![]()
![]()
![]()
后台回复【五件套】
下载二:南大模式识别PPT ![]()
后台回复【南大模式识别】
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。
记得备注呦
推荐两个专辑给大家: 专辑 | 李宏毅人类语言处理2020笔记 专辑 | NLP论文解读 专辑 | 情感分析
整理不易,还望给个在看!










