【最新TensorFlow1.4.0教程01】TF1.4.0介绍与动态图机制 Eager Execution使用
点击上方“专知”关注获取更多AI知识!
【导读】主题链路知识是我们专知的核心功能之一,为用户提供AI领域系统性的知识学习服务,一站式学习人工智能的知识,包含人工智能( 机器学习、自然语言处理、计算机视觉等)、大数据、编程语言、系统架构。使用请访问专知 进行主题搜索查看 - 桌面电脑访问http://www.zhuanzhi.ai, 手机端访问http://www.zhuanzhi.ai 或关注微信公众号后台回复" 专知"进入专知,搜索主题查看。随着TensorFlow 1.4 Eager Execution的出现,TensorFlow的使用出现了革命性的变化。专知为大家推出TensorFlow 1.4系列教程:
01:动态图机制Eager Execution
02: 使用Eager Execution训练卷积神经网络
待定
简介
近期PyTorch比较火,并不是因为PyTorch轮子多或者生态圈庞大,而是因为PyTorch可以构建动态图,即可以像正常程序一样去编写或者调试深度学习模型。1.4版本之前的Tensorflow一直被人诟病的一个问题就是它不具备构建动态图的能力。Tensorflow 1.4的Eager Execution在兼容老版本的基础上,提供了动态图以及其它的一些新特性,通俗地来说有下面几个特点:
无需Placeholder和Feed,可以直接使用numpy作为输入
可以立即执行Operation,例如输入图像数据(numpy),立即输出卷积结果,并将结果转换为numpy。即可以将老版本中定义静态图的Operation直接当做函数来立即执行一个Operation。(老版本需要先利用Operation定义静态图,然后到Session中执行不可变的静态图,并且获取Operation的结果需要通过sess.run()和feed,非常麻烦)。
动态图特性使得Tensorflow可以使用python的if语句和循环语句来控制模型的结构,而不用通过
tf.cond这种难用的函数来控制模型的解构。动态图特性使得模型更便于调试,模型的运行过程与代码的运行过程一致。而在老版本的静态图中,网络的forward与backward都是黑箱操作,想加个print来输出过程中的变量都很难。
梯度的计算和更新也变成函数的调用,可由开发者自己调用。
上述的Eager Execution特性的实现,只需在代码顶部加上下面两行代码即可,其他的操作均兼容老版本的API:
import tensorflow.contrib.eager as tfetfe.enable_eager_execution()
安装
想体验1.4版Tensorflow的,可以用pip下载nightly build版本的Tensorflow:
CPU:
pip install tf-nightlyGPU:
pip install tf-nightly-gpu
注意,使用GPU版需要安装cuDNN 6以上的版本。在Windows上推荐使用conda(python3.5)+pip进行安装。
示例
下面用一些示例来展示Eager Execution为我们带来的礼物。
下面所有的示例都依赖下面的import:
import tensorflow as tfimport tensorflow.contrib.eager as tfeimport numpy as nptfe.enable_eager_execution()示例1,直接使用Operation进行卷积操作
# 随机生成2个图像(batch_size=2),每个图像的大小为 28 * 28 * 3images = np.random.randn(2, 28, 28, 3).astype(np.float32)# 卷积核参数filter = tf.get_variable("conv_w0", shape = [5,5,3,20], initializer = tf.truncated_normal_initializer)# 对生成的batch_size=2的数据进行卷积操作,立即获得结果conv = tf.nn.conv2d(input = images, filter = filter, strides = [1,2,2,1], padding = 'VALID')# 用结果的numpy()方法可获得结果的numpy表示,显示其shapeprint(conv.numpy().shape)运行结果如下,成功获得卷积后结果的大小。
(2, 12, 12, 20)示例2,自动计算梯度
为x*x + 40自动求导:
grad = tfe.gradients_function(lambda x: x * x + 4.0)print(grad(10))print(grad(5))计算结果:
[<tf.Tensor: id=11, shape=(), dtype=int32, numpy=20>]
[<tf.Tensor: id=22, shape=(), dtype=int32, numpy=10>]可以看到,输入为10和5时的导数为20和10。
示例3,使用Python的程序流程控制模型的流程
自己动手实现leaky relu激活函数:
def leaky_relu(x):
if x < 0:
return x * 0.1
else:
return xgrad = tfe.gradients_function(leaky_relu)print(grad(4.0))print(grad(-3.0))代码运行记结果如下:
[<tf.Tensor: id=9, shape=(), dtype=float32, numpy=1.0>]
[<tf.Tensor: id=21, shape=(), dtype=float32, numpy=0.1>]结果中的1.0和0.1分别是leaky relu对于输入4和-3的梯度。可以看出,leakly relu需要条件语句来控制流程,上面代码在老版本TensorFlow里是不可行的,因为条件语句的判断会发生在定义静态图的阶段,而定义静态图的阶段连输入数据是啥都不知道。
示例4,自动优化
w = tf.get_variable("w", initializer = 3.0)def loss(x):
return x * woptimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1)for i in range(5):
optimizer.minimize(lambda: loss(5))
print(w.numpy())运行结果如下,可以看出变量w的值在不断被更新,以减小loss的值
2.5
2.0
1.5
1.0
0.5分布式和多GPU
TensorFlow的Github上对于Eager Execution的描述如下:
This feature is in early stages and work remains to be done in terms of smooth support for distributed and multi-GPU training and CPU performance.
意思是说,Eager Execution仍然是一个新特性,对于分布式训练、多GPU训练和CPU的性能,仍有很多的工作可做。对于想使用分布式训练的朋友来说,还是老老实实先用TensorFlow的静态图吧。下面这段引用描述了TensorFlow的分布式运行方法:
TensorFlow是Google开源的基于神经网络的深度学习引擎,可以支持分布式运行。通常构建单一的包含了一系列参数的图, 并且创建多个模型的副本来映射到不同tasks。每个model的副本有一个不同的train_op,并且对于每个Worker service而言一个或者多个的客户端线程可以调用sess.run(train_ops[i])。这种方法只使用了单一的tf.Session,它的工作目标是集群中的某个workers。而另一种分布式训练器的方法使用多张图,一张图对应一个worker,并且每张图都包含了一系列的参数的集合和一份模型的赋值。而容器的机制就是在不同的图之间共享变量:一旦某个变量构造完成,可选的container参数会由图中每份复制的相同值来决定。对于较大的模型而言,这种方法会更加有效,毕竟整个图更小了一点。这种方法就需要使用多个tf.Session对象:每个worker过程都会包含一个,不过不同的Session会指向不同的目标worker。这个tf.Session对象即可以在单一的Python客户端中创建,也可以在多个客户端中创建。
性能
国外一些人在博客里公布了一些Eager Execution和PyTorch的对比,总的来说,就是目前TensorFlow的Eager Execution特性并不是特别理想,但正如上面所说,Eager正处于非常初级的阶段,相信Google可以很快地将Eager特性完善。
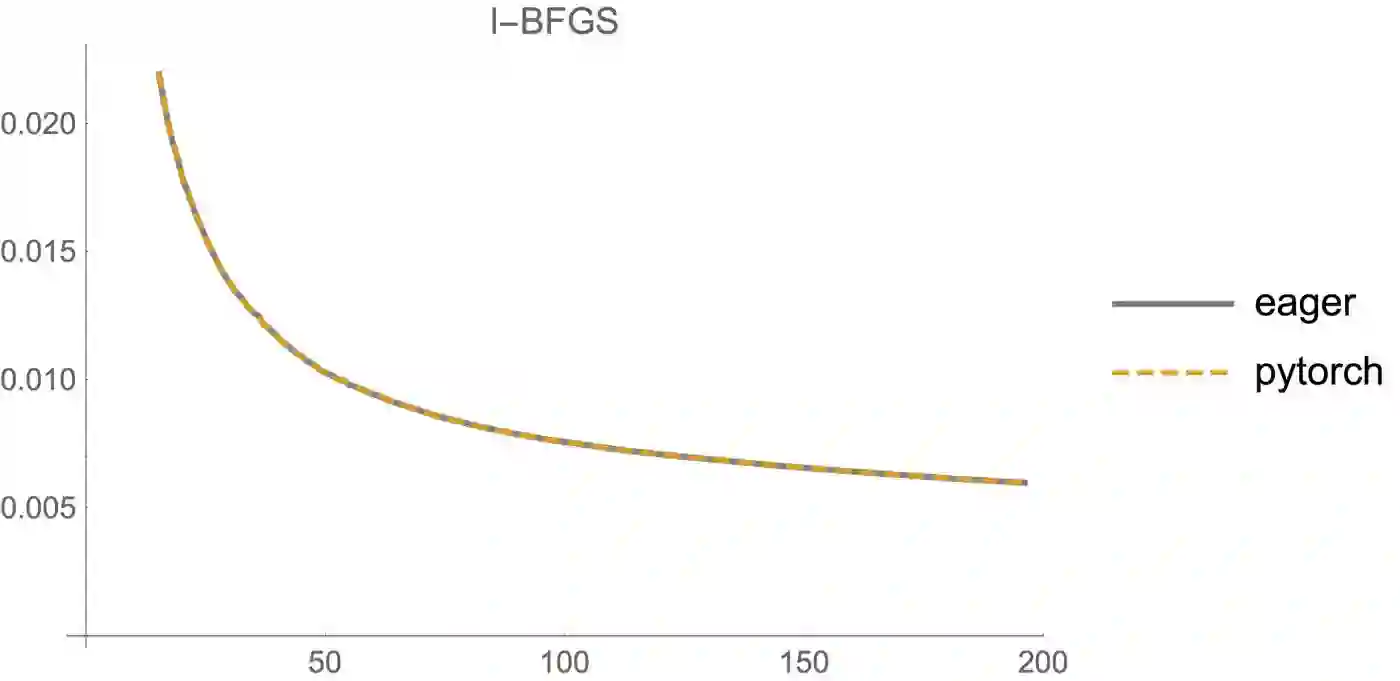
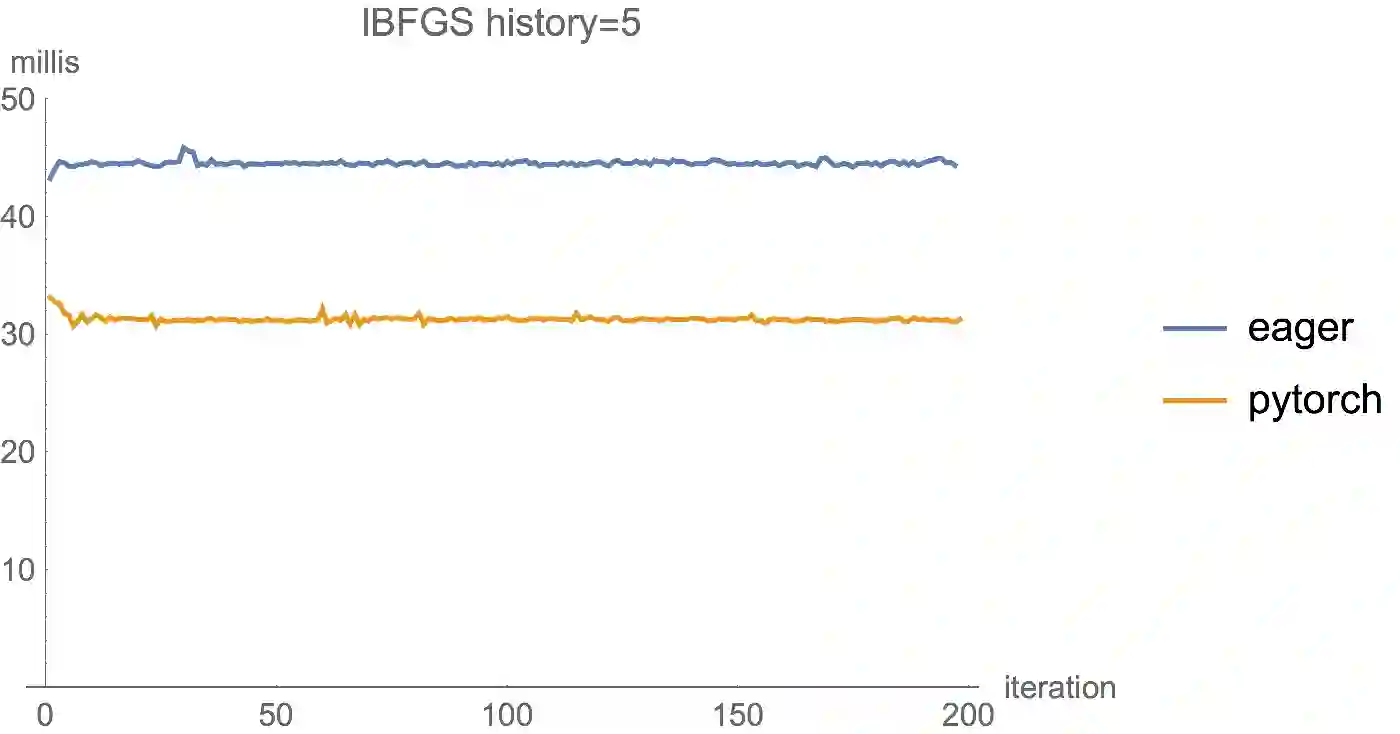
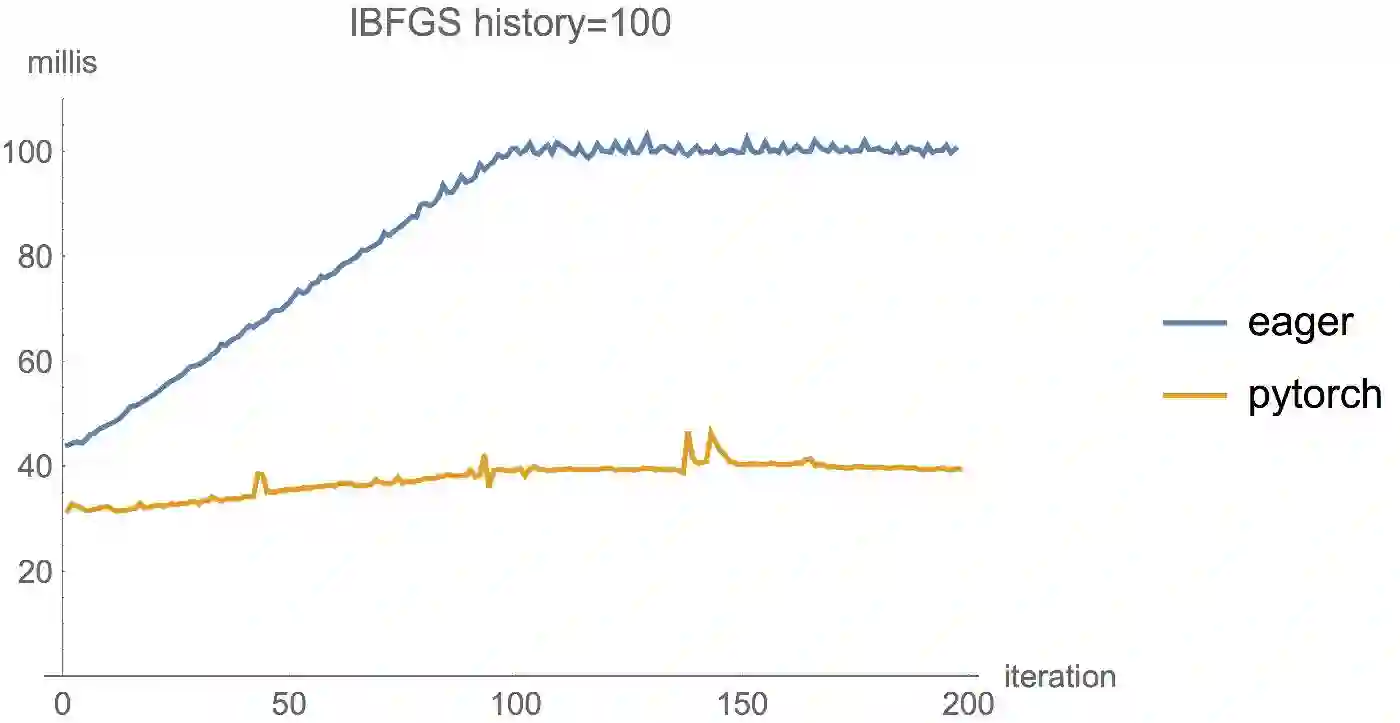
特注:
获取TensorFlow1.4.0代码最新更新,请登录www.zhuanzhi.ai或者点击阅读原文,顶端搜索“ TensorFlow” 主题,查看获得TensorFlow最新更新代码与知识等资料!如下图所示~
请加入TensorFlow学习群交流~

请扫描小助手,加入专知人工智能群,交流分享~

此外,请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),获取更多专知荟萃知识资料全集获取,请查看:
【专知荟萃01】深度学习知识资料大全集(入门/进阶/论文/代码/数据/综述/领域专家等)(附pdf下载)
【专知荟萃02】自然语言处理NLP知识资料大全集(入门/进阶/论文/Toolkit/数据/综述/专家等)(附pdf下载)
【专知荟萃03】知识图谱KG知识资料全集(入门/进阶/论文/代码/数据/综述/专家等)(附pdf下载)
【干货荟萃】机器学习&深度学习知识资料大全集(一)(论文/教程/代码/书籍/数据/课程等)
【GAN货】生成对抗网络知识资料全集(论文/代码/教程/视频/文章等)
【干货】Google GAN之父Ian Goodfellow ICCV2017演讲:解读生成对抗网络的原理与应用
【AlphaGoZero核心技术】深度强化学习知识资料全集(论文/代码/教程/视频/文章等)
欢迎转发到你的微信群和朋友圈,分享专业AI知识!
请扫描小助手,加入专知人工智能群,交流分享~
获取更多关于机器学习以及人工智能知识资料,请访问www.zhuanzhi.ai, 或者点击阅读原文,即可得到!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!



