从 0 开始机器学习 - 机器学习算法诊断
来自:登龙
今天跟大家分享下如何诊断一个算法是否存在偏差或者方差的问题,以及如何选择优化算法的方向。
一、如何确定下一步的计划?
当我们设计了一个机器学习算法,比如线性回归或逻辑回归,并且算法已经能够正常工作,只是效果还不是太好,那用什么方法来提高算法的性能或者准确度呢?或者说在想办法提升性能之前,有没有一种方法来告诉我们下一步对我们设计的机器学习算法该采取什么步骤,比如:
-
获得更多的训练样本 -
尝试减少特征的数量 -
尝试获得更多的特征 -
尝试增加多项式特征 -
尝试减少正则化程度 -
尝试增加正则化程度 -
...
上面 6 种思路都可以作为提升一个算法性能的选择,可是我们对一个算法到底该选择哪一种优化的思路呢?今天就跟大家分享下如何来评估一个机器学习算法,也称为机器学习诊断法,这个方法可以明确地告诉我们:要想进一步提升算法的性能,我们到底该采取什么方法是比较有效地,是增加训练集数量,还是增加或者减少特征数等。
使用这个方法的必要性是可以帮助我们节省时间,让我们可以更加明确优化算法的方向,不至于像无头苍蝇一样胡乱的选择优化思路,最终效果还不行。
二、训练集、交叉验证集,测试集
在学习诊断法之前,需要先对训练数据集进行处理,对于特征变量比较少的情况,我们可以直接画出假设函数在训练集上的拟合效果,比如:
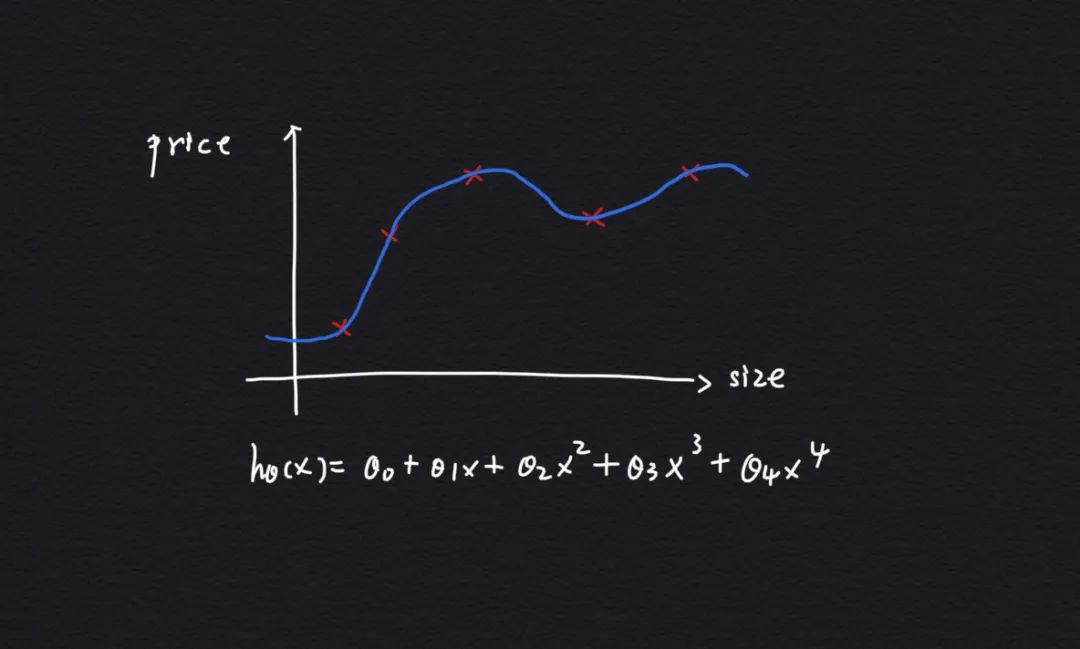
但是当特征数量很多以至于不能用曲线表示拟合效果时,就需要用另外一种代价函数误差指标的方法来衡量假设函数的拟合效果,为此需要把原始数据集进行拆分:
-
70% 作为训练集 training set -
30% 作为测试集 test set
这样我们就有了用来评估模型效果的测试数据集了,首先把模型在训练集上进行训练,然后用测试集计算模型的代价函数误差 ,但是在训练集上拟合较好的模型不一定能适应新的样本,为此我们再拆分一个 交叉验证集帮助我们选择训练集上训练的模型,为此再对数据集拆分:
-
60% 作为训练集 training set -
20% 作为交叉验证集 cross validation set -
20% 作为测试集 test set
之后使用这 3 个数据集对多个模型进行训练或者评估:
-
在训练集上训练个模型,并计算训练误差 -
在交叉验证集上计算代价函数的交叉验证误差 -
选择交叉验证误差最小的模型 -
在测试集上计算上一步选择的最小模型的代价函数推广误差
以上的 3 个误差均为平方误差代价函数,只是在不同的数据集上进行的计算:
接下来我们分别在训练集和交叉验证集上用曲线做对比分析,以此来分析当前算法存在高偏差问题还是高方差问题。
三、多项式次数与偏差和方差的曲线
通过之前博客的学习我们已经知道:
-
高偏差问题:模型欠拟合 (underfitting) -
高方差问题:模型过拟合(overfitting)
通过前面拆分的训练集合交叉验证集,我们可以画出一个模型的多项式次数 - 代价函数误差的曲线,以此通过曲线来帮助我们分析当前的模型是欠拟合还是过拟合,比如下面的曲线:
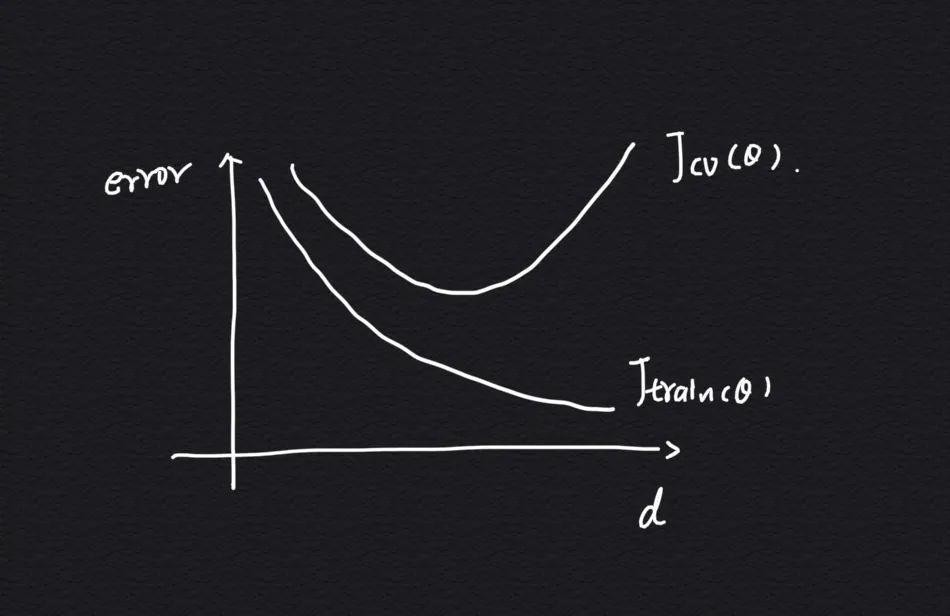
解释下:
-
横坐标代表假设函数(模型)的多项式次数 d -
纵坐标表示代价函数的误差 error -
表示模型在交叉验证集上的代价函数误差 -
表示模型在训练集上的代价函数误差
从上面的曲线中我们可以发现 3 个关键位置及其含义:
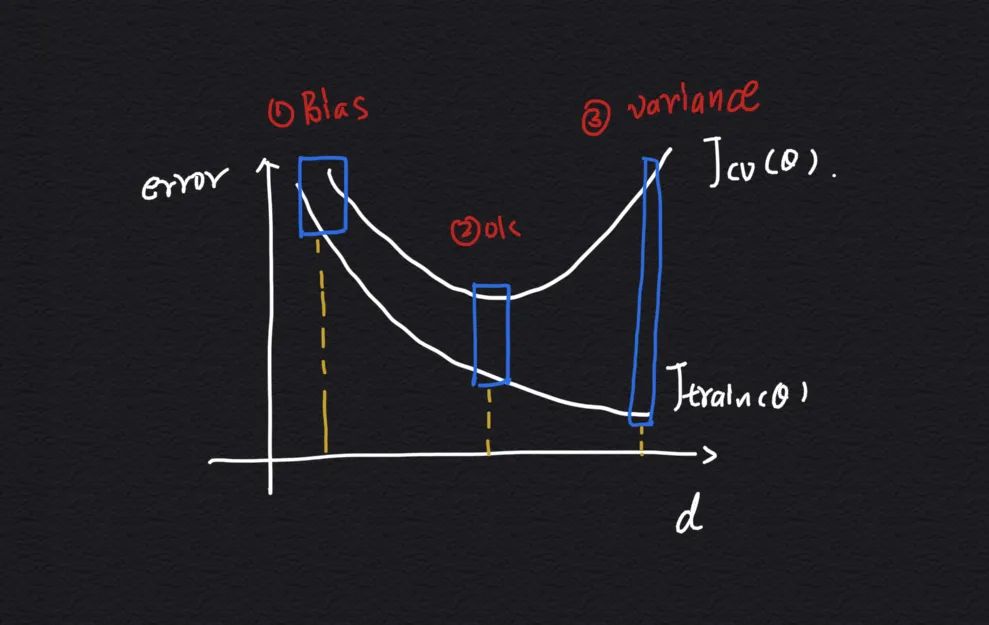
3.1 多项式次数 d 较小
因为模型的次数低,所以拟合训练集和交叉验证集的误差都比较大,从曲线上看 与 误差近似,都挺大的。
3.2 多项式次数 d 合适
当我们选择一个合适的模型时,训练集和交叉验证集的误差都比较小,并且交叉验证集的误差处于最低点,这说明当前多项式次数对应的模型拟合交叉验证集的效果最好。
3.3 多项式次数 d 较大
但是当我们继续增大模型的多项式次数后,会发现训练集误差继续减少,但是交叉验证误差却反而增大了,这是因为我们选择的多项式次数太高,模型在交叉验证集上产生了过拟合,也即方差太大。
通过以上 3 个关键的位置,可以得出以下的结论:
-
与 近似时:模型欠拟合,偏差(Bias)较大 -
远大于 时:模型过拟合,方差(Variance)较大
四、正则化系数与偏差和方差的曲线
除了分析模型的多项式次数与偏差方法的关系,我们还可以分析正则化系数,这可以帮助我们选择一个合适的正则化系数来防止过拟合,通过前面的学习我们知道:
-
正则化系数 太大:模型容易欠拟合,偏差较大 -
正则化系数 合适:模型拟合效果较好 -
正则化系数 太小:模型容易过拟合,方差较大
如:

为了分析正则化系数对模型的影响,我们同样可以在前面的 3 个数据集上进行多组不同正则化系数模型的误差计算:
-
在 training set上训练多组不同正则化系数的模型 -
分别在 cross validation set上计算每组的代价函数交叉验证误差 -
选择交叉验证误差最小的模型 -
将误差最小的模型在 test set上计算推广误差
在这个过程中,我们可以画出正则化系数与代价函数误差的关系:
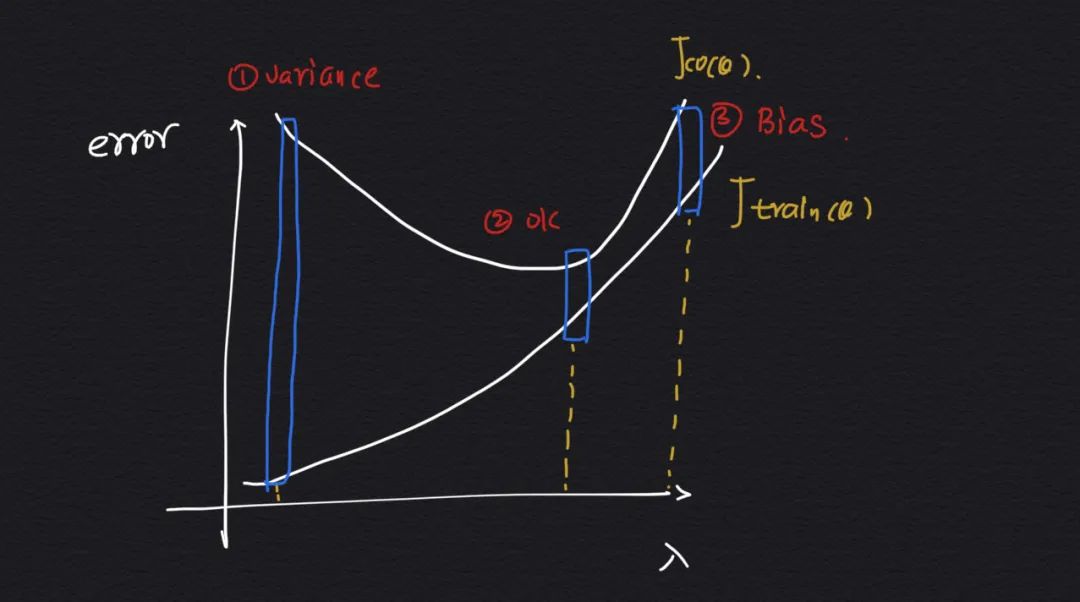
解释下曲线上关键的 3 个位置:
4.1 较小
因为正则化系数较小,模型在训练集上产生过拟合,虽然误差 比较小,但是在交叉验证集上的误差 很大,这是因为在训练集上过拟合的模型不能很好的适应未知的样本。
4.2 合适
当选择了一个合适的正则化系数时,模型在训练集和交叉验证集上的误差都比较小,这也是我们想要的情况。
4.3 较大
当正则化系数很大,模型在训练集上都不能很好地拟合数据(欠拟合),更别说在未知上交叉验证集上测试了,所以这两者的误差都很大。
也简单总结下这个曲线:
-
当 较小:训练集误差小,交叉验证集误差大 -
当 不断增大:训练集误差逐渐增大,而交叉验证集误差先减小再增大
五、学习曲线
除了以上的多项式次数、正则化系数与误差的关系之外,还有一种很重要的称为「学习曲线」的关系,它主要用来说明交叉验证误差和训练集误差随着样本数量变化的关系,可以用这个曲线帮助我们判断一个算法在给定样本规模的情况下是否存在偏差或者方差的问题。
我们还是分析以下 2 个代价函数误差:
我们把这 2 者和样本数量的关系画成学习曲线:
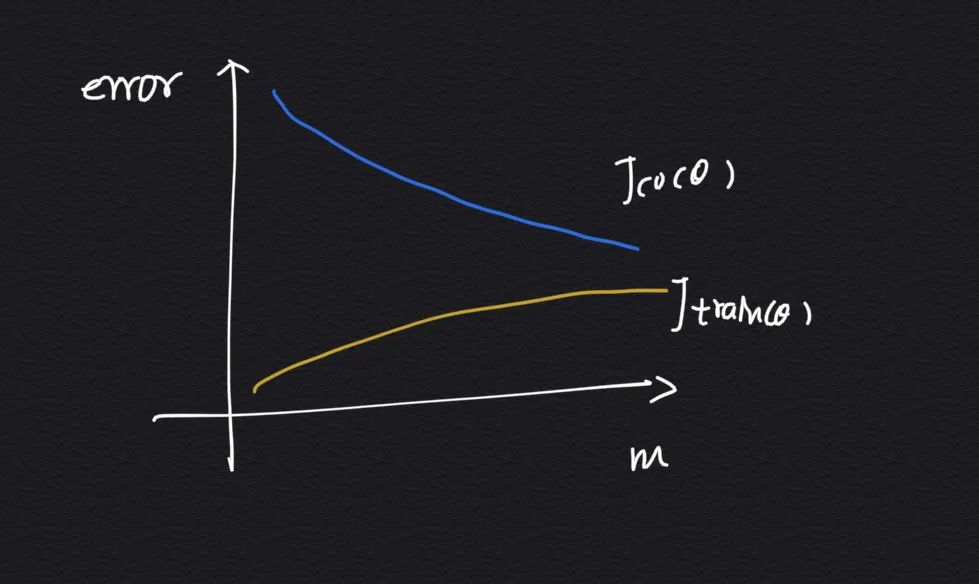
因为是分析样本数量与这 2 个误差的关系,所以我们分 2 种情况来讨论。
5.1 模型存在高偏差(欠拟合)问题
当模型欠拟合时,比如多项式次数太少(特征太少了),不管把样本数量增大到多少,训练集误差和交叉验证集误差都不会下降很多,这种情况就说明我们的模型存在高偏差问题,也就是欠拟合了:
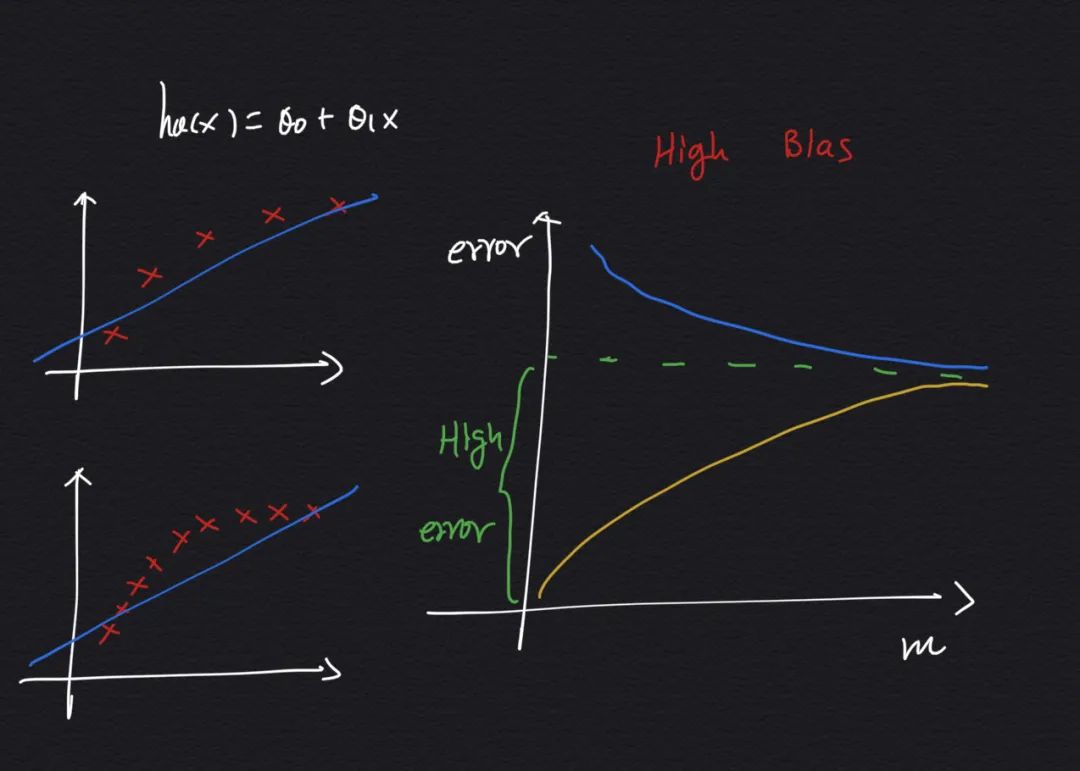
这种情况下,如果你不用学习曲线来分析,而是直接凭感觉出发觉得我应该多增加一些数据,这样模型的拟合效果应该会更好,那就选错了优化的方向,从曲线上来看,不管你增加多少样本,误差是不会降低的。
5.2 模型存在高方差(过拟合)问题
现在假设我们有一个非常高次的多项式模型(特征很多),并且正则化系数很小时,如果训练样本数很少,那么在训练集上会过拟合,导致在交叉验证集上误差较大(过拟合不能很好的适应新样本),而当增加样本数量的时候,因为我们模型有足够多的特征,所以不会轻易的过拟合,这样随着数量增多,训练集和交叉验证集的误差都会减小:
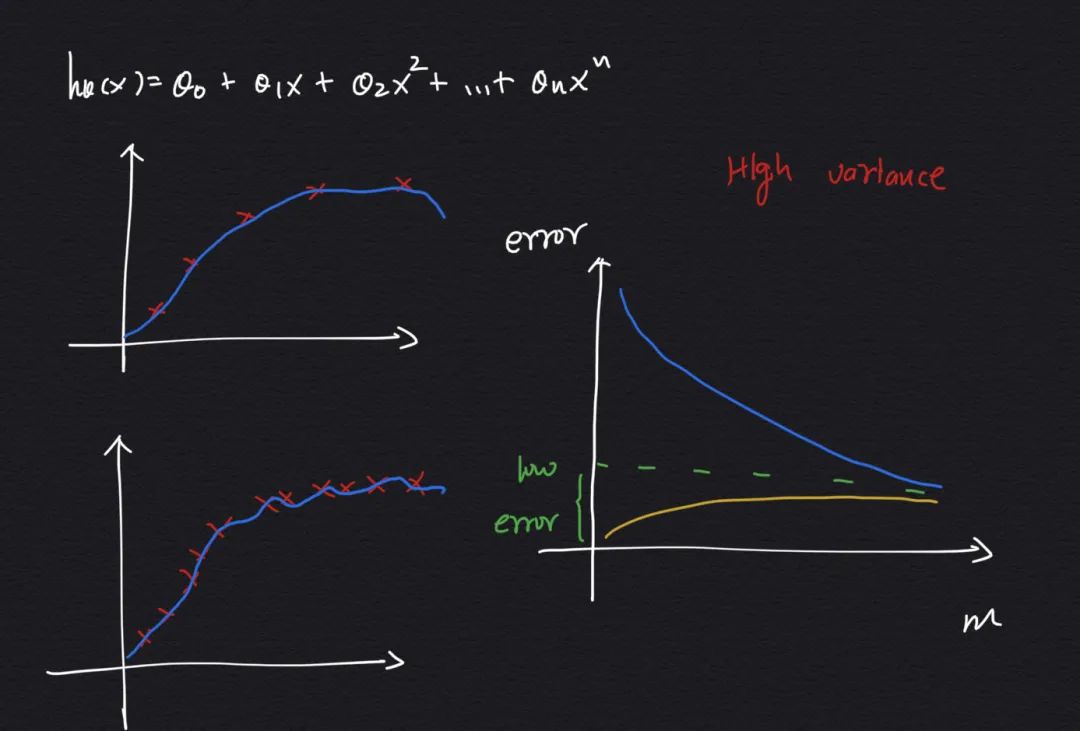
简单总结下就是:
-
高偏差(欠拟合)的模型,增大样本数量不一定对算法有帮助 -
高方差(过拟合)的模型,增大样本数量可能提升算法的效果
这里也只可能的情况,因为实际的模型可能很复杂,可能会存在一些特殊情况。
六、现在决定下一步的思路
学习完了如何诊断一个算法是否存在偏差或者方差问题后,我们就可以回答文章开头提出的问题了,到底如何选择优化方向:
-
获得更多的训练样本 - 适用于高方差的模型 -
尝试减少特征的数量 - 适用于高方差的模型 -
尝试获得更多的特征 - 适用于高偏差的模型 -
尝试增加多项式特征 - 适用于高偏差的模型 -
尝试减少正则化程度 - 适用于高偏差的模型 -
尝试增加正则化程度 - 适用于高方差的模型
知道如何诊断算法存在的问题后,就可以选择对应的优化方向进行针对性的工作,就不用盲目地选择优化方向,最后还可能是无用功。
OK!今天就到这,大家下期见:)
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记





