【ACL2020】最新效果显著的关系抽取框架了解一下?


导 语:
从非结构化文本中抽取三元组是构建大规模知识图谱的必备关键,然而现有的研究工作鲜有去解决三元组重叠的问题,针对此问题,本文从全新的视角提出一个新的关系抽取框架:CASREL,不同以往采用分类的视角解决问题,从实验结果来看,框架非常有效,加上 BERT 之后,更为惊人,在两份数据集上面,分别提升 17% 和 32%。
背景与思路
信息抽取是构建大规模知识图谱的必备关键,先来说一下图谱的三元组形式,在以往常常将三元组以 (head,relation, tail) 的形式表示,在这里以(subject, relation, object)的形式表示,即(S, R,O),为了方便描述,后文将以这种形式阐述。
信息抽取分为两大部分,一部分是命名实体识别,识别出文本中的实体,另外就是关系抽取,对识别出来的实体构建对应的关系,两者便是构建三元组的基本组成。在以往的研究工作中,早期两个任务以pipline的方式进行,先做命名实体识别,然后做关系抽取。但是pipline的流程可能造成实体的识别错误,也就造成关系构建的错误,所以后续的一些研究工作将两者采用联合学习的方式。
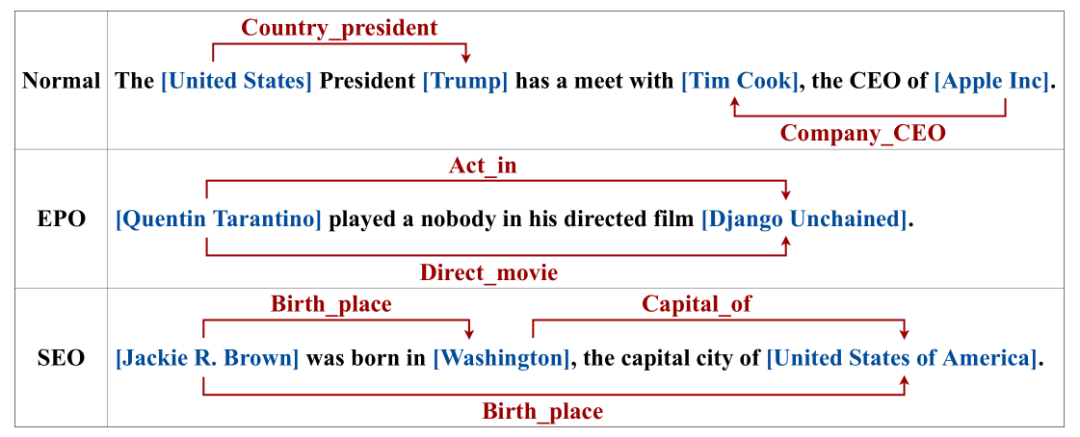
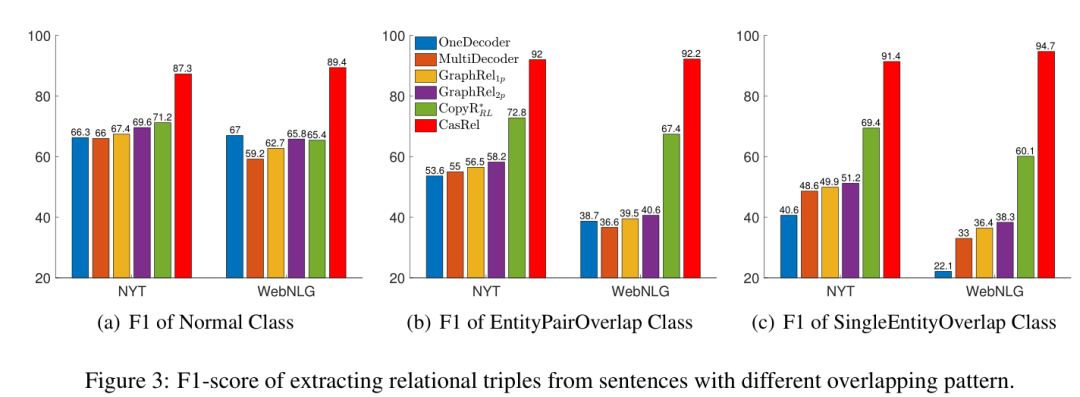
但是上述存在很少的研究工作解决三元组重叠的问题,本文以此为解决目标,提出新的模型框架,首先来看一下三元组重叠的问题具体指什么?看下图,列举了三种形式。
Normal: 代表没有重叠的部分。
EPO(EntityPairOverlap): 关系两端的实体都是一致的,例如 QT 既在电影 DU 中扮演角色,又是电影 DU 的执导。
SEO(SingleEntityOverlap): 关系两端只有单个实体共享,图中的例子,从小范围来说,JRB 出生在 Washington, 但是 Washington 是 USA 的首都,所以也可以说 JRB 出生在 USA。
以往工作的不足以及重叠三元组出现的挑战:
-
在实体对的组合之中,大多数实体对是没有关系链接的,这便存在很多的负例,也就造成了关系分类的不平衡。 -
重叠三元组的问题更是一个难点,因为其存在共享的实体,甚至两个实体存在多种关系,这便增加了难度,没有足够的训练数据,是难以学习或者根本无法学习这种关系的。
思想:采用全新的视角代替以往分类的视角,将关系建模为 S 到 O 的映射函数。提出一个全新的框架:CASREL。
框架详解
CASREL框架抽取三元组(subject, relation, object)主要包含两个步骤,三个部分。
两个步骤:
第一步要识别出句子中的 subject 。
第二部要根据识别出的 subject, 识别出所有有可能的 relation 以及对应的 object。
-
BERT-based encoder module: 可以替换为不同的编码框架,主要对句子中的词进行编码,论文最终以BERT为主,效果很强。 -
subject tagging module:目的是识别出句子中的 subject。 -
relation-specific object tagging module:根据 subject,寻找可能的 relation 和 object。 -
其中 a 是 Encoder, b 和 c 称为 Cascade Decoder。

Subject Tagger
这部分的主要作用是对 BERT Encoder 获取到的词的隐层表示解码,构建两个二分类分类器预测 subject 的 start 和 end 索引位置,对每一个词计算其作为 start 和 end 的一个概率,并根据某个阈值,大于则标记为1,否则标记为0。公式如下:
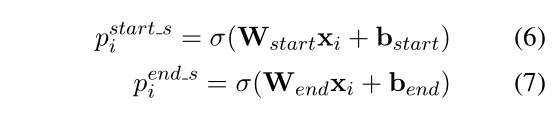
Relation-specific Object Taggers
这部分会同时识别出 subject 的 relation 和相关的 object。
解码的时候比 Subject Tagger 不仅仅考虑了 BERT 编码的隐层向量, 还考虑了识别出来的 subject 特征,即下图。v sub 代表 subject 特征向量,若存在多个词,将其取向量平均,h n 代表 BERT 编码向量。
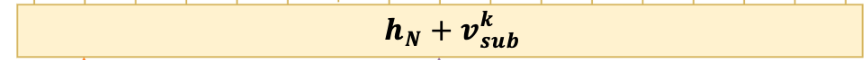
对于识别出来的每一个 subject, 对应的每一种关系会解码出其 object 的 start 和 end 索引位置,与 Subject Tagger 类似,公式如下:
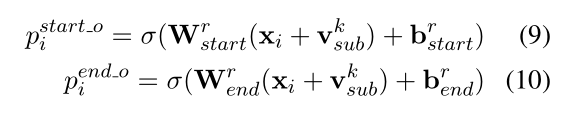
我们以图中的例子详细说明一下,图中的例子仅仅画出了第一个 subject 的过程,即 Jackie R. Brown,对于这个,在关系 Birth_place 中识别出了两个 object,即 Washington 和 United States Of America,而在其他的关系中未曾识别出相应的 object。当对 Washington 这个 subject 解码时,仅仅在 Capital_of 的关系中识别出 对应的 object: United States Of America。
以上我们便可以得到抽取到的三个三元组如下:
(Jackie R. Brown, Birth_place, Washington)
(Jackie R. Brown, Birth_place, United States Of America)
(Washington, Capital_of, United States Of America)
从以上抽取出来的三元组,确实解决了最开始提到的 SEO 和 EPO 的重叠问题。
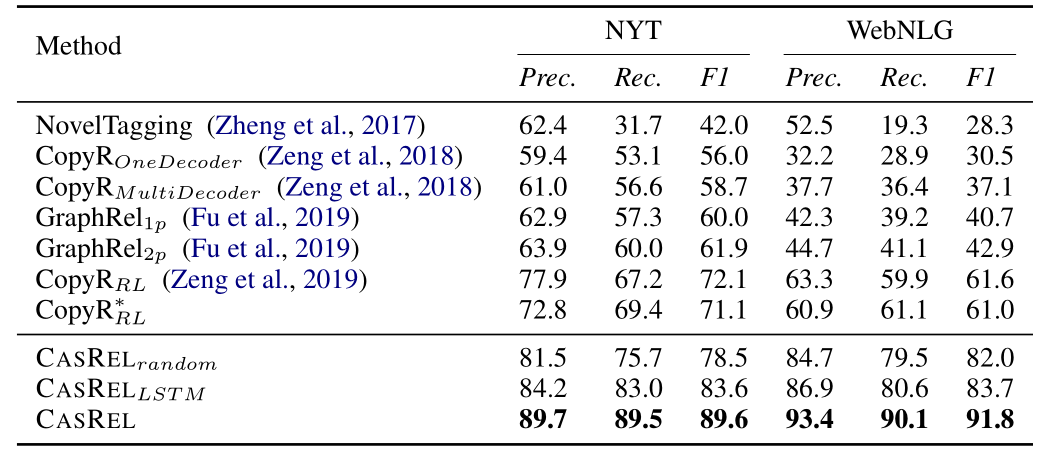
实验效果
-
CASREL 框架确实有效,三种编码结构的效果都是要远高于其他的模型性能。 -
采用预训练 BERT 之后,CASREL 框架更是逆天。
结束语
论文代码:https://github.com/weizhepei/CasRel
参考资料
A Novel Cascade Binary Tagging Framework for Relational Triple Extraction
相关注明
上述图片均来自于上述参考资料。
文章推荐阅读
【ACL2020论文尝鲜】如何以低成本的数据构建高效NER模型?
【ACL2020论文尝鲜】何时采用BERT更加有效?
知识表示学习Trans系列梳理(论文+代码)
论文解读|知识图谱最新研究综述
【图谱构建】图谱构建之知识抽取
知识抽取之NER(一) | 顶会论文解读
END
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,点个在看吧👇



