使用深度学习提高移动设备的可用性(二)
评估模型
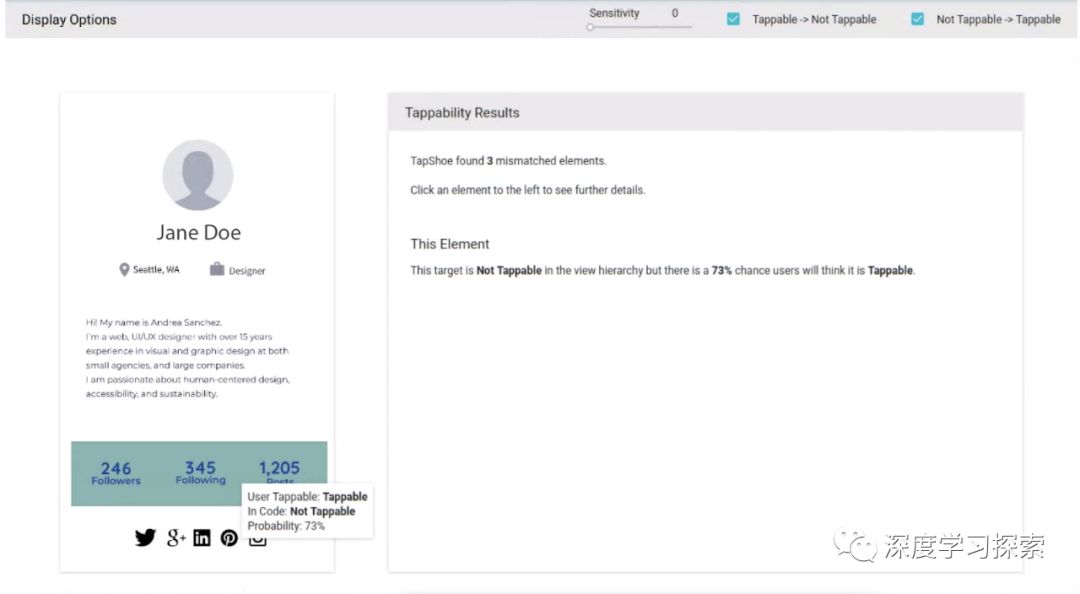
该模型允许我们自动诊断由我们的模型预测的用户所感知的每个界面元素的可触发性与开发者或设计者指定的元素的预期或实际可点击状态之间的不匹配。在下面的示例中,我们的模型预测用户会有73%的可能性认为诸如“Followers”或“Following”之类的标签是可插拔的,而这些界面元素实际上并未被编程为可点击的。
为了理解我们的模型与人类用户相比的行为方式,特别是在人类感知模糊不清的情况下,我们通过众包290名志愿者共同创建了第二个独立数据集,以便在其感知的适应性方面标记2,000个独特的界面元素。每个元素由五个不同的用户独立标记。我们发现样本中超过40%的元素被志愿者标记为不一致。我们的模型很好地匹配了人类感知中的这种不确定性,如下图所示。
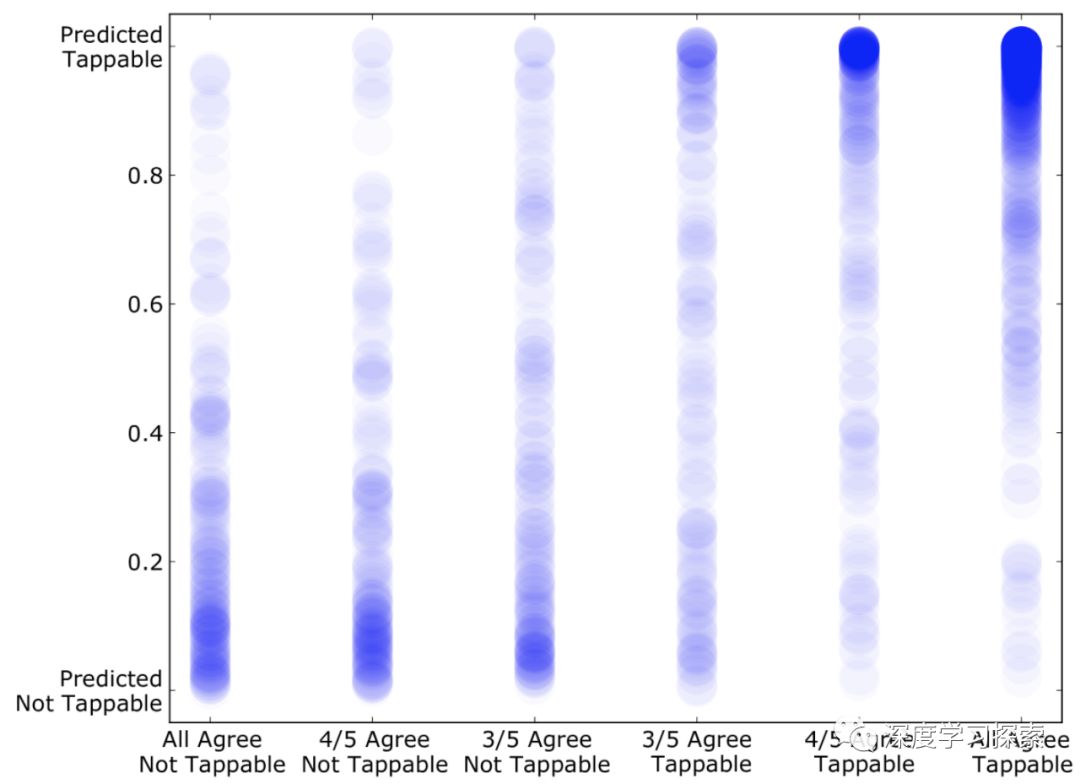
由一致性数据集中的每个元素的模型预测的可读性概率(Y轴)与人类用户标签(X轴)的一致性的散点图。
当用户同意元素的可适用性时,我们的模型倾向于给出更明确的答案 - 对于tappable而言接近1的概率和对于不可点击的接近0的概率。当工人在一个元素上不一致(朝向X轴的中间)时,我们的模型对决策也不太确定。总的来说,我们的模型在识别可触摸UI元素时达到了人类感知匹配的合理准确度,平均精度为90.2%,召回率为87.0%。
预测可点击性仅仅是我们可以用机器学习来解决用户界面中的可用性问题的一个例子。在交互设计和用户体验研究中还存在许多其他挑战,其中深度学习模型可以提供用于提取大型,多样化的用户体验数据集并推进关于交互行为的科学理解的工具。
致谢
这项研究是谷歌暑期实习生Amanda Swangson和深度学习与人机交互研究科学家杨力的共同研究。
如果你是一个喜欢关注技术脉搏的人,请在我们的下面留言
微信公众号在我们消遣娱乐之余,它是一个非常好的学习手段与途径,利用好它,必将有所裨益,祝福每个小白都能在AI的这条光明大路上爱(AI)上Ta!




